







项目地址How Does a Database Work? | Let’s Build a Simple Database (cstack.github.io)
我们要写个像sqlite的轻量级数据库,先得看看它长什么样。(真正的sqlite:呵呵,我13万行代码,你来写呀。本次项目将完成其1%的工程量。他们比我们多了写什么?他们有回滚,有锁,而且类型判断及错误判断比我们多,分层比我们多,甚至他们的shell都有万行以上。)
为什么它这么长呢?(至少对于我来说挺长的,虽然它在业界中是轻量级小型数据库。)我们来看看。
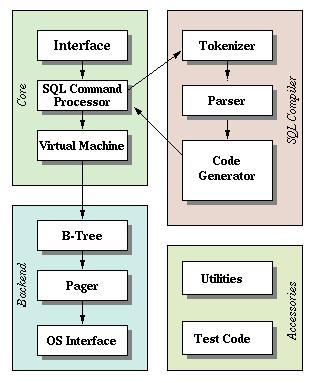
这里我们介绍介绍功能。
(一)公共接口(Interface)
SQLite库的大部分公共接口由main.c, legacy.c和vdbeapi.c源文件中的函数来实现,这些函数依赖于分散在其他文件中的一些程序,因为在这些文件中它们可以访问有文件作用域的数据结构。
(二)词法分析器(Tokenizer)
当执行一个包含SQL语句的字符串时,接口程序要把这个字符串传递给tokenizer。Tokenizer的任务是把原有字符串分割成一个个标识符(token),并把这些标识符传递给解析器。Tokenizer是用手工编写的,在C文件tokenize.c中。
(三)语法分析器(Parser)
语法分析器的工作是在指定的上下文中赋予标识符具体的含义。SQLite的语法分析器使用Lemon LALR(1)分析程序生成器来产生,Lemon做的工作与YACC/BISON相同,但它使用不同的输入句法,这种句法更不易出错。Lemon还产生可重入的并且线程安全的语法分析器。Lemon定义了非终结析构器的概念,当遇到语法错误时它不会泄露内存。驱动Lemon的源文件可在parse.y中找到。
(四)代码生成器(Code Generator)
语法分析器在把标识符组装成完整的SQL语句后,就调用代码生成器产生虚拟机代码,以执行SQL语句请求的工作。代码生成器包含许多文件:attach.c, auth.c, build.c, delete.c, expr.c, insert.c,pragma.c, select.c, trigger.c, update.c, vacuum.c和where.c。这些文件涵盖了大部分最重要、最有意义的事情。expr.c处理SQL中表达式的代码生成。where.c处理SELECT、UPDATE和DELETE语句中WHERE子句的代码生成。文件attach.c, delete.c, insert.c, select.c, trigger.c, update.c和vacuum.c处理同名SQL语句的代码生成(这些文件在必要时都调用expr.c和where.c中的例程)。所有其他SQL语句的代码由build.c生成。文件auth.c实现sqlite3_set_authorizer()的功能。
(五)虚拟机(Virtual Machine)
代码生成器生成的代码由虚拟机来执行。总的来说,虚拟机实现一个专为操作数据库文件而设计的抽象计算引擎。它有一个存储中间数据的存储栈,每条指令包含一个操作码和不超过三个额外的操作数。
(六)B-树(B-Tree)
一个SQLite数据库使用B-树的形式存储在磁盘上,B-树的实现位于源文件btree.c中。数据库中的每个表和索引使用一棵单独的B-树,所有的B-树存放在同一个磁盘文件中。文件格式的细节被记录在btree.c开头的备注里。B-树子系统的接口在头文件btree.h中定义。
(七)页面高速缓存(Page Cache)
B-树模块以固定大小的数据块形式从磁盘上请求信息,默认的块大小是1024个字节,但是可以在512和65536个字节之间变化。页面高速缓存负责读、写和缓存这些数据块。页面高速缓存还提供回滚和原子提交的抽象,并且管理数据文件的锁定。B-树驱动模块从页面高速缓存中请求特定的页,当它想修改页面、想提交或回滚当前修改时,它也会通知页面高速缓存。页面高速缓存处理所有麻烦的细节,以确保请求能够快速、安全而有效地被处理。
页面高速缓存的代码实现被包含在单一的C源文件pager.c中。页面高速缓存子系统的接口在头文件pager.h中定义。
(八) OS接口
为了在POSIX和Win32操作系统之间提供移植性,SQLite使用一个抽象层来提供操作系统接口。OS抽象层的接口在os.h中定义,每种支持的操作系统有各自的实现:Unix使用os_unix.c,Windows使用os_win.c,等等。每个特定操作系统的实现通常都有自己的头文件,如os_unix.h, os_win.h等。
(九)实用工具(Utilities)
内存分配和字符串比较函数位于util.c中。语法分析器使用的符号表用Hash表来维护,其实现位于hash.c中。源文件utf.c包含Unicode转换子程序。SQLite有自己的printf()实现(带一些扩展功能),在printf.c中,还有自己的随机数生成器,在random.c中。
(十)测试代码(Test Code)
如果你计算回归测试脚本,超过一半的SQLite代码将被测试。主要代码文件中有许多assert()语句。另外,源文件test1.c通过test5.c和md5.c实现只用于测试目的的一些扩展。os_test.c后端接口用来模拟断电,以验证页面高速缓存的崩溃恢复机制。
SQLite 由以下几个主要模块组成:SQL 编译器、内核、后端。
- 接口:接口由SQLite C API组成,程序可以通过API与SQLite数据库进行交互。
- 编译器:分词器(Tokenizer)和分析器(Parser)对执行的SQL语句进行语法检查,然后生成语法树方便VDBE代码生成器使用,然后把语法树传给VDBE代码生成器(Code Generator)处理。代码生成器根据语法树生成VDBE的类汇编语言操作码。
- 后端:由B-树(B-tree),页缓存管理(pager)和操作系统接口构成。B-tree和Pager共同对数据进行管理。B-tree用与对数据建立索引,它维护着各个页面之间的复杂的关系,便于快速找到所需数据。Pager的主要作用就是通过OS接口在B-tree和硬盘之间传递页面。
以下我们将体验写数据库的感觉,虽然和真的sqlite差很多,但能实现增删改查功能。

首先,在我们输入之前,它会打印sqlite> ,然后接受输入进行判断,在输入不为.exit时程序会一直进行下去。所以程序应该有个while(1),它先输出sqlite>,然后接受输入,并对输入进行判断。如果是.exit就退出,如果不是就输出未知命令并继续。所以我们建立InputBuffer结构体,记录长度,指针,并进行初始化。
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}然后编写主函数
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}完善函数并做一些字符读取的判断
void print_prompt() { printf("sqlite>"); }size_t getline(char **lineptr, size_t *n, FILE *stream);
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// 忽略换行符
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}lineptr:指向我们用来指向包含读取行的缓冲区的变量的指针。如果将其设置为“被 mallocatted”,因此应由用户释放,即使命令失败也是如此。
n:指向我们用于保存已分配缓冲区大小的变量的指针。
stream:要从中读取的输入流。我们将从标准输入中读取。
return value:读取的字节数,可能小于缓冲区的大小。
前面malloc了,就得有释放
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}再在主函数加上close_input_buffer
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}好了,最简单的没有实装任何功能的数据库就完成了。我们运行一下。

以下是全部源代码
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("sqlite>"); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// Ignore trailing newline
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
printf("Good Bye.\n");
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}















 330
330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











