







本次教程是依据个人学习心得与学习记录所做,见证的是我们的成长。
什么是网络爬虫?
定义:
- Web Crawler:网络爬虫。顾名思义,可以把网络理解成一张网,爬虫就是每天在网上爬来爬去的蜘蛛,因为我们所访问的网页都是互通的,通过跳转,可以访问其他的网络资源,这样,爬虫就可以在网络中爬取我们想要的资源。(所以网络爬虫又被称为网页蜘蛛,网络机器人,在某一社区中。被称为网页追逐者)它可以按照指定的规则即网络爬虫的算法自动地在互联网,网页中抓取网络的信息。
应用:
- 网络爬虫到处可见,例如浏览器的搜索引擎就附带着爬虫,依靠爬虫,可以快速的在庞大的互联网信息中获取指定的信息。算法对于网络爬虫来说十分重要,不同的算法,所爬取的信息的工作效率和结果也有所不同。
- 随着互联网的发展,到了信息量爆炸的时代,爬虫所扮演的角色愈加重要。为了提高爬行的工作效率,爬虫需要在单位时间内尽可能多的获取高质量页面,成为了它面临的难题之一。
原理:
1.正如爬虫的名字那样,我们所访问的每个网站网页都属于一个节点,而这些节点都是相互联系的,爬虫便可以借助这种关系,从一个网页扩展到很多网页,以此从中抓取我们所需要的数据内容。
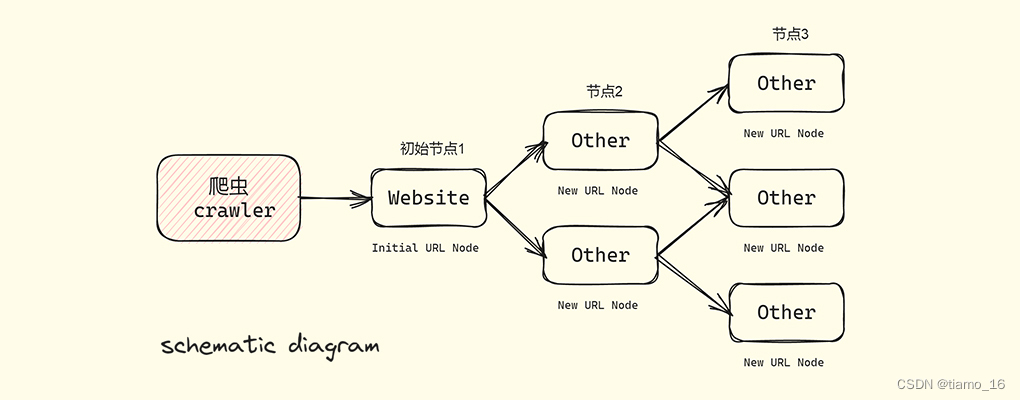
基本原理:
- 指定初始的URL(该URL地址是我们需要爬取的初始URL网页地址)
- 爬取对应的初始URL时,从中获取新的URL地址
- 将新的URL地址列入URL列队中(URL管理器)
- 从URL列队中读取新的的URL,依据该URL爬取网页,提同时获取新的URL,并不断重复该过程
- 若在爬取前设置了条件,满足某特定条件即可停止爬取;若未设置条件,爬虫将一直干下去直到无法获取到新的URL地址。
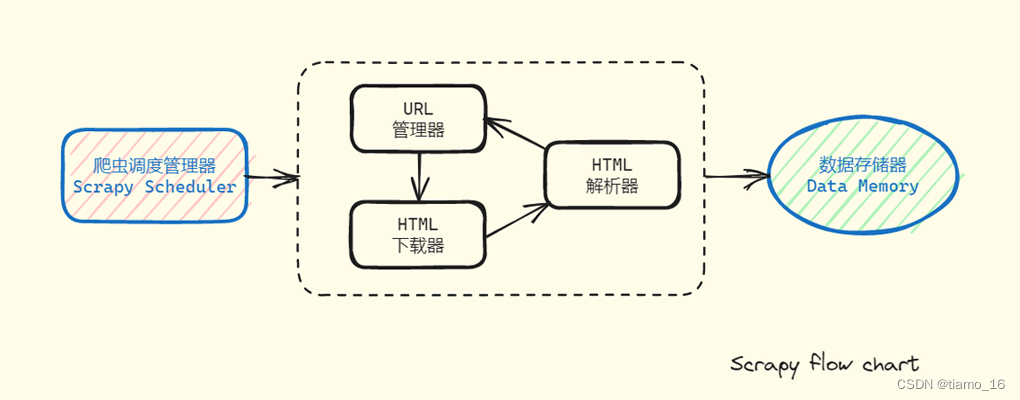
- 爬虫调度管理器会将抓取的数据通过下载器保存到数据存储器中。它将会以音频;文本;视频,图片等形式保持在本地。
利弊:
1.网络爬虫是把双刃剑,在享受爬虫带来的数据便捷的同时还存在着严重的隐私问题。有人会故意利用爬虫来爬取他人的隐私信息。
2.使用网络爬虫就相当于使用浏览器,但它是个高频的程序,长期高频率的爬取一个网站,可能会导致服务器资源殆尽,给服务器带来很大的负担,严重影响性能,这就相当于一个DDoS攻击。
首选语言
1.Python是编写网络爬虫的首选语言,为什么呢?
- 得益于Python的语法简明,通俗易懂,哪怕是零基础也能够快速上手,并且活。
- Python内置了丰富的爬虫相关模块和第三方库及其框架,如Requests、mechanize,Beautiful Soup、Scrapy让网络爬虫有了更多的选择和方法。
- Python支持多线程,开启多线程能够使得爬取更多的网页,工作效率大大提高,事半功倍。
- Python有着强大的数据分析和处理能力,对于抓取数据更加智能与灵活。
2.当然了,像Java,C/C++,PHP同样是可以编写爬虫的,就看你能不能接受了。
总结:
1.编写网络爬虫程序是一个长期的过程,往后的学习之路还很长。希望通过介绍,能对爬虫有个简单而深刻的认识。
















 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











