









1.了解了URL封装和XPath解析后,也掌握了许多爬虫知识,是时候做个实战演练了。
2.本期内容会讲到如何利用爬虫制作一个简易的翻译小程序。
制作翻译小程序
一. 实战对象
- 先声明一下:本次实战案例是以学习为目的,不会有其他恶意行为,文章仅供参考。
- 这次是利用爬虫制作小程序,那当然离不开网站了,本次我们会以,金山词霸为实战素材。
二. 制作流程
1. 英文翻译
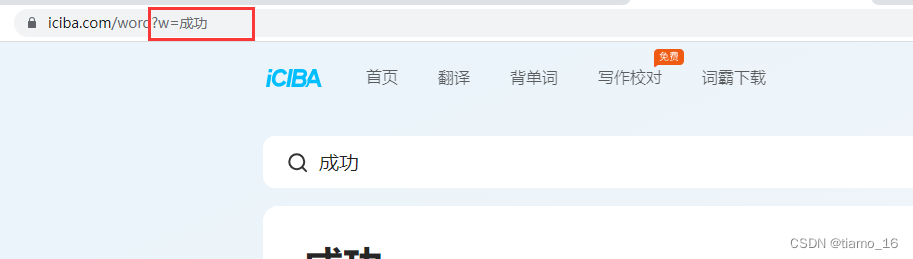
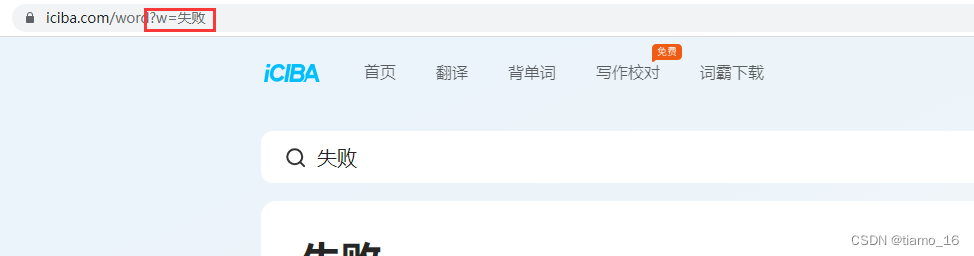
- 首先我们先打开金山词霸的官网页面。
- 我们直接翻译两个单词,注意一下URL地址的变化,可以发现,,w=后面的就是我们要翻译的中文,连续两次翻译都是只是改变了这一小部分,所以,我们就可以利用到这一发现。
- 我们打开编辑器,开始编写代码。
- 我们新建一个Python文件,并导入必要的模块,requests和lxml。
- 定义一个请求对象,并将链接复制到get方法内。注意,因为我们要利用到URL中的w=,所以我们在这里面写个格式。为了能够得到服务器的响应,我们还需要写一个反爬虫,就是定义一下请求头的User-Agent,将参数传入到请求对象中。
- 定义一个input用于word接收要查的单词。
- 这样请求对象就定义好了。
import requests
from lxml import etree
tou = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
} # 伪装成浏览器
word = input('请输入你想翻译的单词:')
respon = requests.get(f'https://www.iciba.com/word?w={word}', headers=tou) # 定义一个请求对象
respon_text = respon.text # 将请求到的源码储存到容器中
-
随后我们定义一下XPath解析对象。
- 我们定义一个解析对象,因为是HTML源码,所以我们采用HTML()方法,对象就是respon_text,将它传入方法内。
- 接着我们回到页面,打开检查F12分析一下。利用检查工具,我们可以发现,我们翻译出了两种形态的单词,而这就是我们想要的数据,要想将他提取出来,就需要看右边的源码标签,可以看到,他们虽然不在一个标签内,但是却同属一个属性,利用这一点,我们就可以利用XPath定位到。
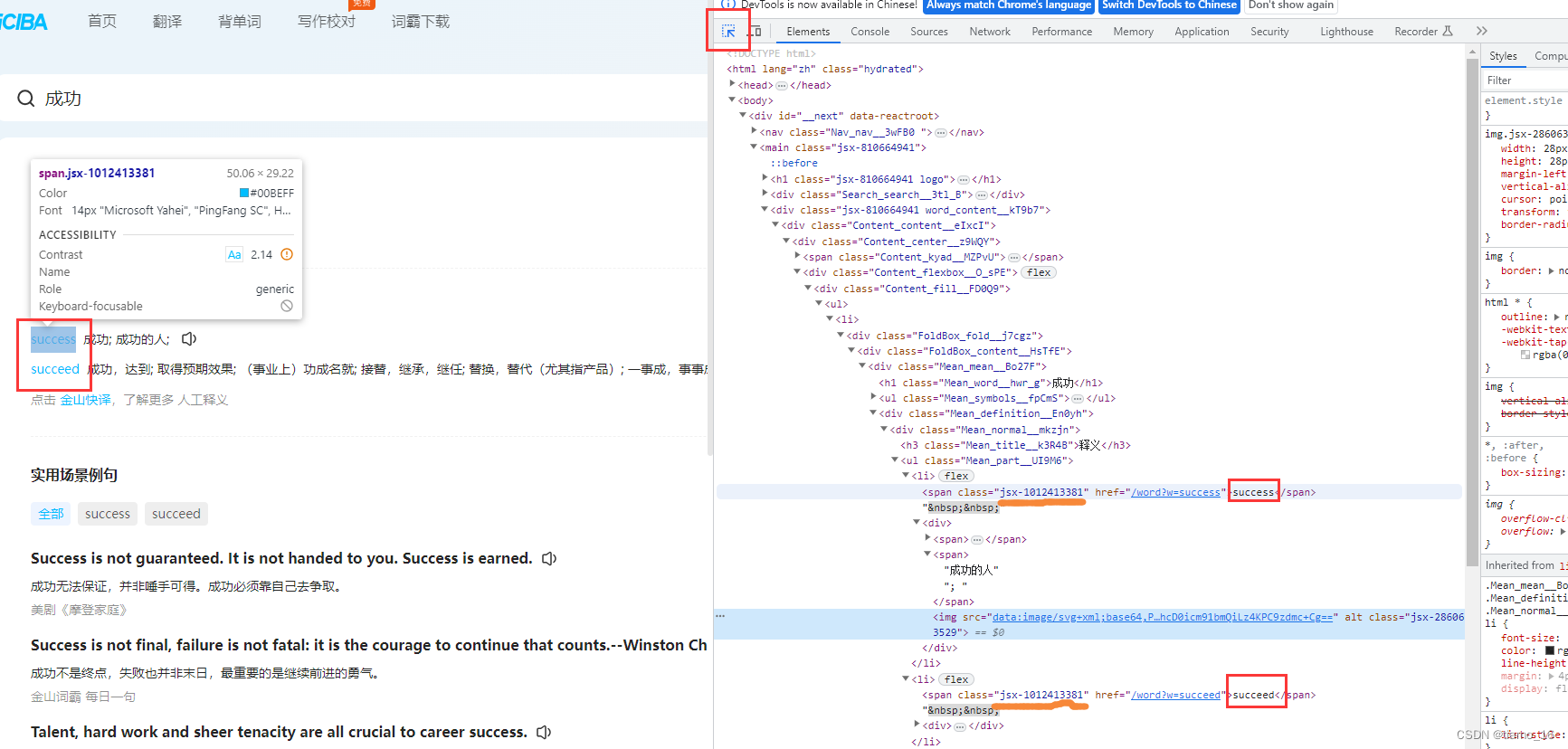
-
提取
- 分析完,我们就可以利于XPath进行精确提取了,最后将提取到的数据传入到一个容器中。
- 最后直接打印。
analyze = etree.HTML(respon_text) # 定义解析对象
analyze_xpath = analyze.xpath('ul[@class="Mean_part__UI9M6"]/span[@class="jsx-1012413381"]/text()') # 提取数据
print(analyze_xpath) # 输出翻译后的单词
- 我们运行一下,可以看到,效果还是蛮不错的

2. 中文翻译
- 我们目前只能中文翻译英文,要想英文翻译中文,还需要继续完善。
- 我们继续分析一下源码,先翻译一下中文,检查一下。
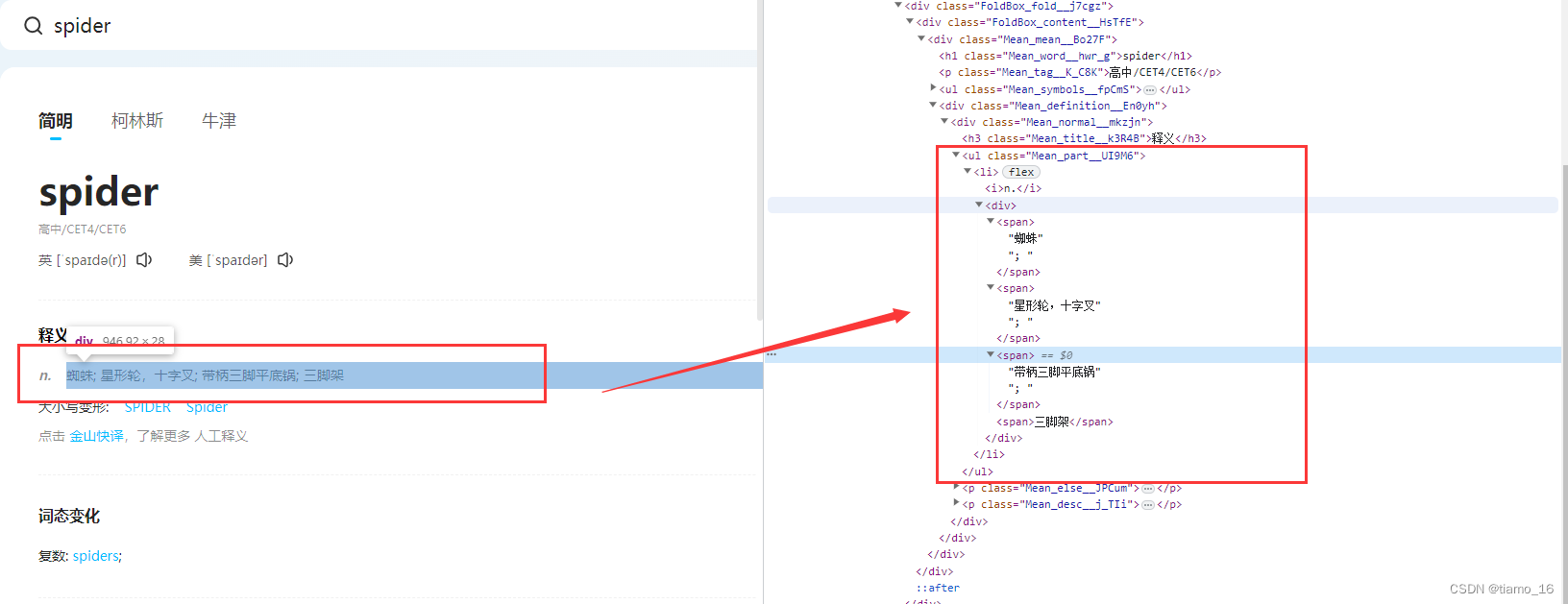
- 分析一下标签的层级结构,利用这种结构,我们可以精确的提取出里面的数据。再次写一个容器。由于储存翻译的中文
analyze = etree.HTML(respon_text) # 定义解析对象
analyze_xpath = analyze.xpath('//ul[@class="Mean_part__UI9M6"]/li/span[@class="jsx-1012413381"]/text()') # 提取英文数据
analyze_xpath_cn = analyze.xpath('//ul[@class="Mean_part__UI9M6"]/li/div/span/text()') # 提取中文数据
print(analyze_xpath) # 输出翻译后的英文单词
print(analyze_xpath_cn) # 输出翻译后的中文词语
- 我们运行一下,可以看到,如果是中译英,它不仅会翻译英文,同时还加上了中文更多形式;而英译中它并不会翻译英文,只会翻译中文,这也正好符合需求。

美化界面
-
最后我们再做最后的处理,美化一下。
-
首先,这个程序只会执行一次,翻译完后,只能重新启动,所以我们可以加个循环,让它翻译完一次还可以继续翻译;不仅如此为了防止爬虫频繁爬取网页信息,我们还要加个结束功能停止访问。
- 直接在input的上面加个无条件循环即可
- 最后在脚下加个if判断,如果输入了”-quit-“则停止执行。
-
这是最终的执行效果,也是非常的Nice!
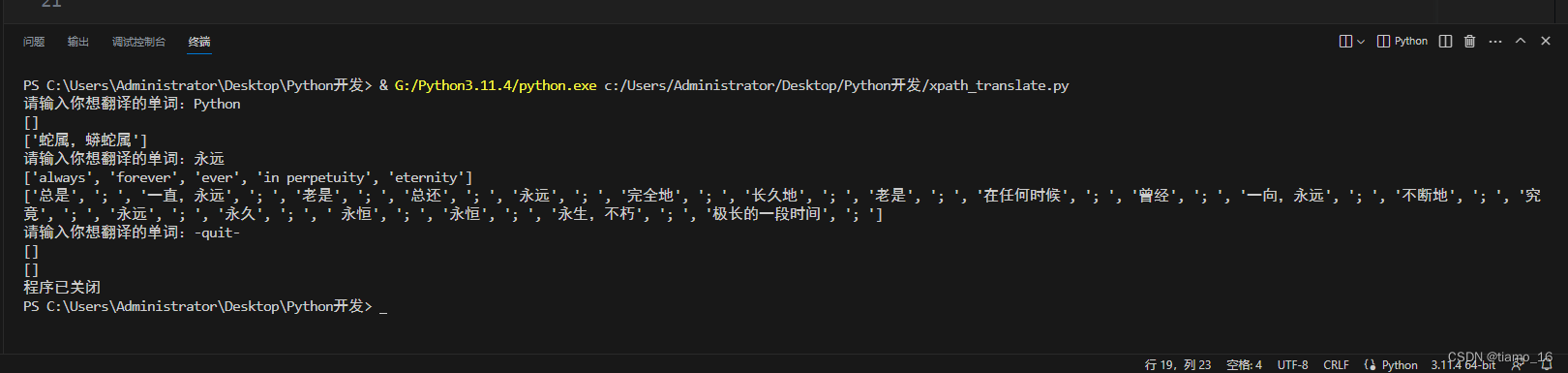
最终代码
import requests
from lxml import etree
tou = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
} # 伪装成浏览器
while True:
word = input('请输入你想翻译的单词:')
respon = requests.get(f'https://www.iciba.com/word?w={word}', headers=tou) # 定义一个请求对象
respon_text = respon.text # 将请求到的源码储存到容器中
analyze = etree.HTML(respon_text) # 定义解析对象
analyze_xpath = analyze.xpath('//ul[@class="Mean_part__UI9M6"]/li/span[@class="jsx-1012413381"]/text()') # 提取英文数据
analyze_xpath_cn = analyze.xpath('//ul[@class="Mean_part__UI9M6"]/li/div/span/text()') # 提取中文数据
print(analyze_xpath) # 输出翻译后的英文单词
print(analyze_xpath_cn) # 输出翻译后的中文词语
if word == '-quit-': # 判断是否关闭
print('程序已关闭')
respon.close() # 关闭请求
break # 跳出循环
总结
- 最后再次声明一下:本次实战案例是以学习为目的,不会有其他恶意行为,文章仅供参考
- 虽然我也觉得经常爬别人的网站是不对的,不过,我们也是抱着学习的态度去做,只要没有恶意,或者频繁使用爬虫,都是可以的。
- 本次制作的翻译小程序我们只是利用到了金山词霸内的信息,目前只能翻译单词或词语,无法翻译语句,若想实现这一功能,同样可以按照上面的方法,添加一些代码即可。
- 内容为本人学习笔记,难免有不足之处,恳请大家批评指正。
















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











