






实验原理:
该搜索引擎的实现主要分为四个部分。
第一部分:从能源学院主页https://nyxy.cumtb.edu.cn/开始爬取,使用BeautifulSoup库来解析HTML,使用双端队列存储未访问的链接,并使用集合存储已访问的链接,以避免重复访问同一链接,同时过滤掉一些不感兴趣的链接。
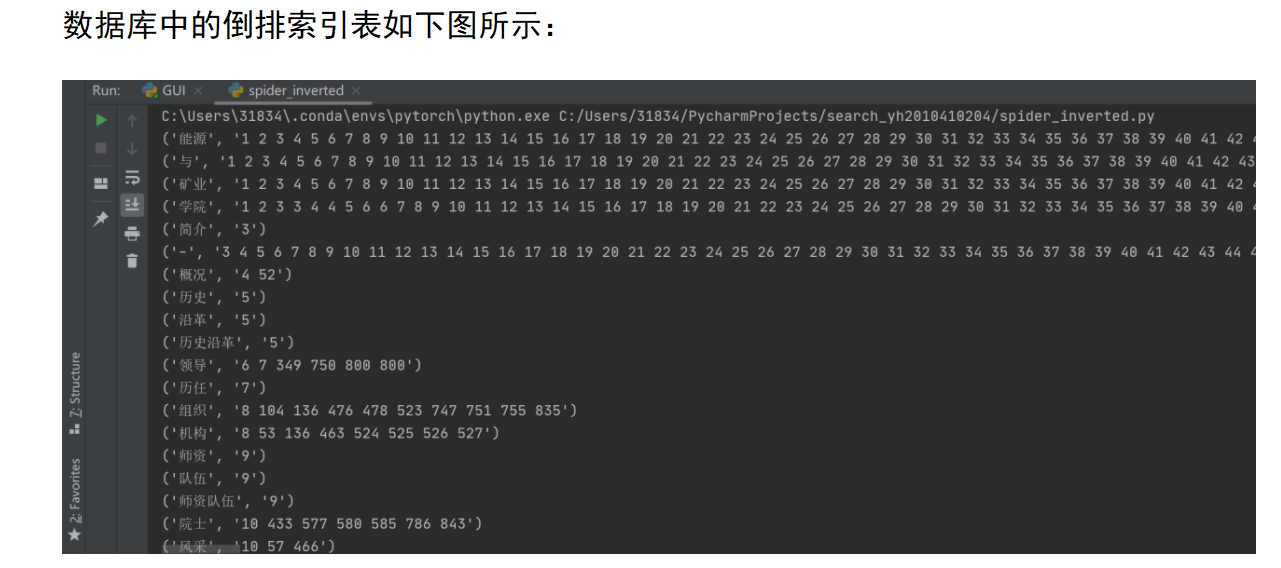
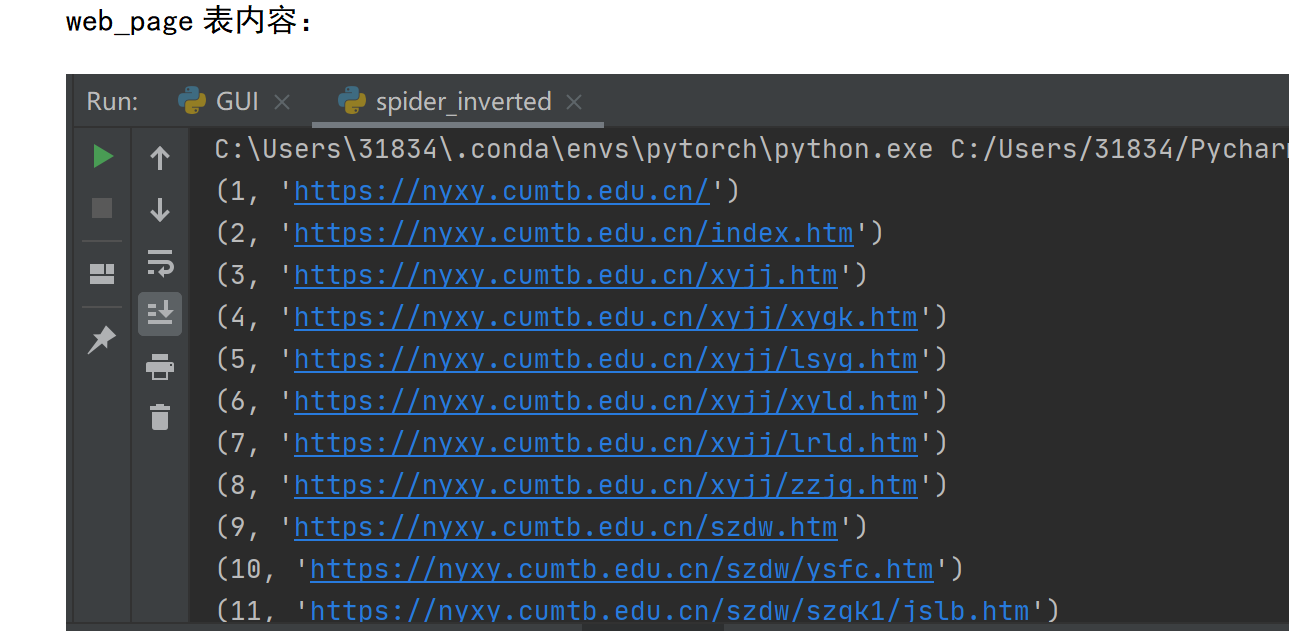
第二部分:将网页编号和对应的url以存入SQLite数据库,使用jieba库对每一个网页进行中文分词,然后建立倒排索引。第一部分和第二部分的实现都放在spider_inverted.py这个文件中。
第三部分:对用户的查询进行分词,根据词在文档中的TF-IDF得分,为页面计算得分,然后进行排序。获取每个符合查询的页面的URL和标题。
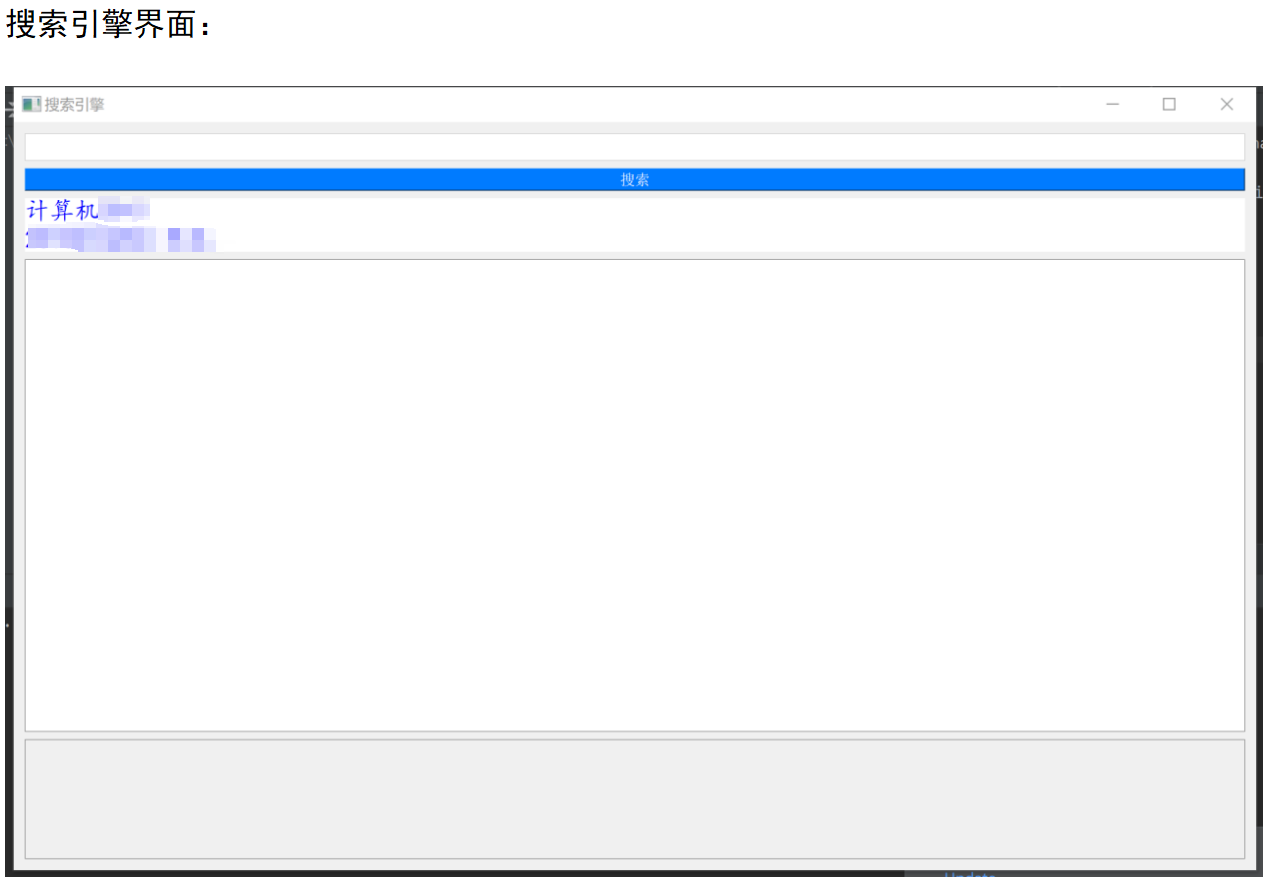
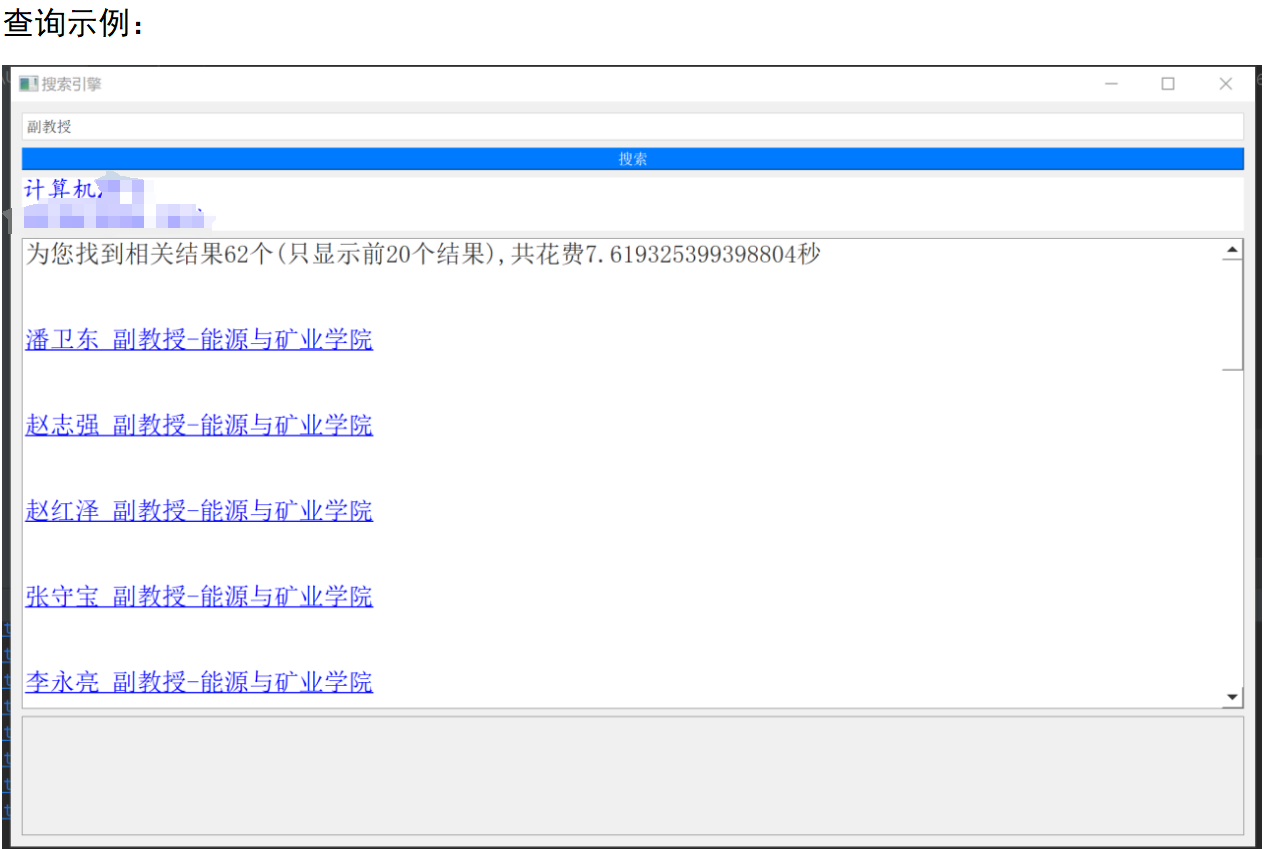
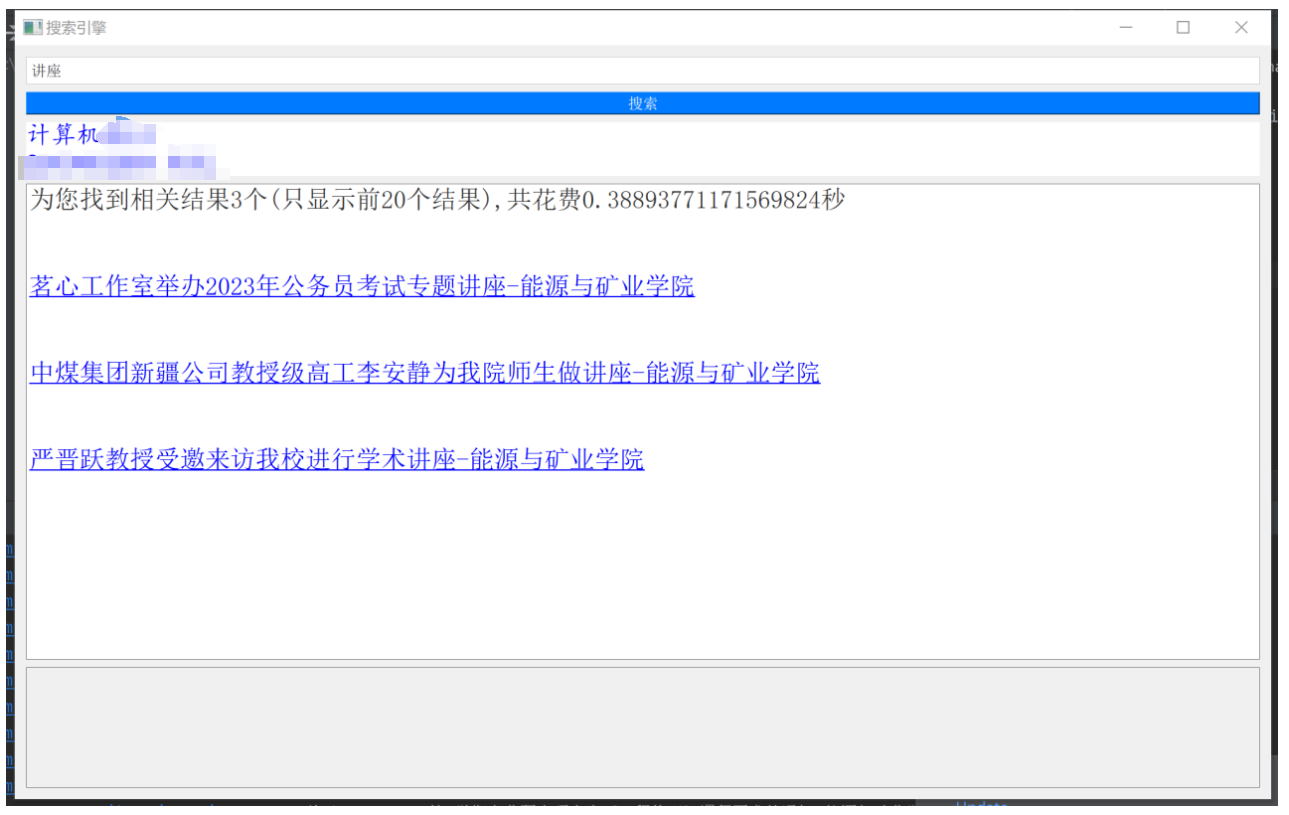
第四部分:利用pyqt5构建了一个简洁的搜索引擎界面,当在输入框输入查询词并点击搜索按钮后,会在此界面显示排名前20的搜索结果。鼠标单击某结果后浏览器即可直接跳转到相应页面。
spider_inverted.py:
import re
import sqlite3
import time
from collections import deque
import jieba
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
class WebSpider:
def __init__(self, start_url, db_name):
self.start_url = start_url # 初始url https://nyxy.cumtb.edu.cn/
self.db_name = db_name
self.unvisited_links = deque([start_url])
self.visited_links = set()
self.page_id = 0
# 初始化数据库
def init_database(self):
connection = sqlite3.connect(self.db_name)
cursor = connection.cursor()
cursor.execute('drop table web_page')
cursor.execute('create table if not exists web_page(id int primary key, link text)')
cursor.execute('drop table word_inverted')
cursor.execute('create table if not exists word_inverted(word varchar(25) primary key, list text)')
cursor.close()
connection.commit()
connection.close()
# 自动转换为绝对URL
def parse_link(self, link):
base_url = 'https://nyxy.cumtb.edu.cn/'
return urljoin(base_url, link)
# 获取并过滤url 同时返回对应的标题
def fetch_links(self, response):
soup = BeautifulSoup(response.text, 'lxml')
all_a_tags = soup.find_all('a')
for a in all_a_tags:
try:
href_content = a['href']
except:
continue
if href_content == '#' or re.search(r'/__local|javascript:|mailto:|system', href_content):
continue
# 以http开头 但不是cumtb的相关网站
if not re.findall(r'https://nyxy.cumtb.edu.cn/', href_content) and re.findall(r'http', href_content):
continue
link = self.parse_link(href_content)
if (link not in self.visited_links) and (link not in self.unvisited_links):
self.unvisited_links.append(link)
print(link)
return soup.title
def record_data(self, words, current_link):
conn = sqlite3.connect(self.db_name)
cur = conn.cursor()
cur.execute('insert into web_page values(?,?)', (self.page_id, current_link))
for word in words:
cur.execute('select list from word_inverted where word=?', (word,))
result = cur.fetchall()
if len(result) == 0: # 先前不存在
cur.execute('insert into word_inverted values(?,?)', (word, str(self.page_id)))
else: # 已存在
existing_ids = result[0][0]
new_ids = existing_ids + ' ' + str(self.page_id)
cur.execute('update word_inverted set list=? where word=?', (new_ids, word))
conn.commit()
conn.close()
def start(self):
self.init_database()
while self.unvisited_links:
self.current_link = self.unvisited_links.popleft()
try:
response = requests.get(self.current_link)
response.encoding = 'UTF-8-SIG'
except:
continue
self.visited_links.add(self.current_link)
title = self.fetch_links(response)
if title is None:
continue
try:
title = re.findall(r'<title>(.*?)</title>', str(title))[0]
except:
continue
self.page_id += 1
# 分词
words = list(jieba.cut_for_search(title))
self.record_data(words, self.current_link)
time.sleep(0.2)
print(str(self.page_id))
print('词表建立完毕')
def database_check(self):
conn = sqlite3.connect('yh_2010410204.db')
cur = conn.cursor()
cur.execute("select * from word_inverted")
for html in cur.fetchall():
print(html)
if __name__ == '__main__':
spider = WebSpider('https://nyxy.cumtb.edu.cn/', 'yh_2010410204.db')
#spider.start()
spider.database_check()
代码的主要功能和步骤如下:
1.初始化:在__init__()方法中,定义了初始URL、数据库名称、未访问链接队列、已访问链接集合和页面ID。
2.数据库初始化:在init_database()方法中,创建了一个连接到SQLite数据库的连接,并创建了两个表:web_page和word_inverted。
3.链接解析:parse_link()方法将相对URL转换为绝对URL。
4.获取并过滤链接:fetch_links()方法从HTML响应中提取所有的< a >标签,并过滤出合适的链接,同时返回页面的标题。
5.记录数据:record_data()方法将页面信息(包括分词后的标题和链接)存储到数据库中。同时,使用了倒排索引的方法,让每个词对应的是包含这个词的页面ID列表。
6.爬虫启动:在start()方法中,首先初始化数据库,然后开始主循环,从未访问链接队列中取出链接,获取响应,并提取和记录链接和页面信息。如果页面的标题存在,就对标题进行分词,然后记录数据,最后将链接添加到已访问链接集合中。
7.数据库检查:database_check()方法中,提供了一个检查数据库内容的功能,可以打印出word_inverted表中的所有内容。
8.执行:在程序的最后,创建了WebSpider的实例,并调用了start()方法来启动爬虫。可选地,也可以调用database_check()方法来检查数据库内容。
get_results.py
import re
import requests
from bs4 import BeautifulSoup
import jieba
import sqlite3
import math
def get_sum(database_name):
# 连接数据库
db_connection = sqlite3.connect(database_name)
# 创建游标
cursor = db_connection.cursor()
# 查询文档总数并加1
cursor.execute('select count(*) from web_page')
total_count = 1 + cursor.fetchone()[0]
# 关闭连接
cursor.close()
db_connection.close()
return total_count
def calculate_score(word, N, cursor):
# 初始化得分字典
score_dict = {}
# 查询当前词对应的序列
cursor.execute('select list from word_inverted where word =?', (word,))
result = cursor.fetchall()
# 如果存在当前词
if result:
doc_list = [int(x) for x in result[0][0].split(' ')] # 得到该词对应的文档id
idf = math.log(N/len(set(doc_list))) # 计算 IDF 包含该词的文档总数
tf_dict = {num: doc_list.count(num) for num in doc_list} # 计算TF 该词在对应文档出现的次数
for num, tf in tf_dict.items():
score_dict[num] = score_dict.get(num, 0) + tf * idf # 计算得分
return score_dict
def search(target, N, database_name='yh_2010410204.db'):
db_connection = sqlite3.connect(database_name)
cursor = db_connection.cursor()
# 将搜索词进行分词
words = list(jieba.cut_for_search(target))
# 初始化总得分字典
total_score = {}
# 遍历每个词,计算得分并累加
for word in words:
score_dict = calculate_score(word, N, cursor)
for num, score in score_dict.items():
total_score[num] = total_score.get(num, 0) + score
# 对结果按得分排序
sorted_score = sorted(total_score.items(), key=lambda x: x[1], reverse=True)
# 存储查询结果
results = []
for num, score in sorted_score:
cursor.execute('select link from web_page where id=?', (num,))
url = cursor.fetchone()[0]
try:
html = requests.get(url)
html.encoding = 'UTF-8-SIG'
soup = BeautifulSoup(html.text, 'lxml')
title = re.findall(r'<title>(.*?)</title>', str(soup.title))[0]
results.append([url, title])
print(url + ' ' + title)
except:
continue
return results
def main():
N = get_sum('yh_2010410204.db')
print(f'Total words: {N}')
results = search('葛世荣', N)
for result in results:
print(f'URL: {result[0]}, Title: {result[1]}')
if __name__ == '__main__':
main()
该代码的主要功能和步骤如下:
1.获取文档总数:在get_sum()函数中,首先建立与SQLite数据库的连接,然后查询表web_page以计算总的文档数并返回。
2.计算单词得分:在calculate_score()函数中,接收单词和文档总数作为输入,然后连接数据库,查询词语对应的页面ID。计算每个文档的TF-IDF得分,然后返回得分字典,这个字典的key是文档ID,value是得分。
3.搜索:在search()函数中,首先对用户输入的查询进行分词,然后对每一个词,计算其在每个文档中的得分,并累加到总得分字典中。然后对总得分进行排序,最后对每个符合查询的页面,获取其URL和标题,将它们存入结果列表。
4.执行主函数:最后在main()中,首先获取文档总数,然后开始搜索,并打印出搜索结果。
GUI.py
import sys
from PyQt5.QtCore import Qt
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QLineEdit, QPushButton, QTextBrowser, QTextEdit, QVBoxLayout, QWidget
from PyQt5.QtGui import QFont
from get_results import search, get_sum
import time
class SearchEngine(QMainWindow):
def __init__(self, parent=None):
super(SearchEngine, self).__init__(parent)
self.setWindowTitle('搜索引擎')
self.setGeometry(100, 100, 2000, 1200)
self.setStyleSheet("background-color: #f0f0f0; color: #333333;")
self.central_widget = QWidget(self)
self.setCentralWidget(self.central_widget)
self.layout = QVBoxLayout(self.central_widget)
self.label = QLabel("计算机\n kaka_羊", self)
self.label.setStyleSheet("background-color: white; color: blue;")
self.label.setFont(QFont('楷体', 15))
self.enter = QLineEdit(self)
self.enter.setStyleSheet("background-color: white; border: 1px solid #cccccc; padding: 5px;")
self.button = QPushButton('搜索', self)
self.button.setStyleSheet("background-color: #007bff; color: white; padding: 5px;")
self.button.clicked.connect(self.click_button)
self.text_0 = QTextBrowser(self)
self.text_0.setFont(QFont("宋体", 15, QFont.StyleNormal))
self.text_0.setReadOnly(True)
self.text_0.setOpenExternalLinks(True)
self.text_0.setStyleSheet("background-color: white; color: #333333;")
self.scroll = QTextEdit(self)
self.scroll.setVerticalScrollBarPolicy(Qt.ScrollBarAlwaysOn)
self.text_0.setVerticalScrollBar(self.scroll.verticalScrollBar())
self.layout.addWidget(self.enter)
self.layout.addWidget(self.button)
self.layout.addWidget(self.label)
self.layout.addWidget(self.text_0, stretch=1) # 使用 stretch 参数来增大中间部分的大小
self.layout.addWidget(self.scroll)
def click_button(self):
self.text_0.clear()
N = get_sum('yh_2010410204.db')
first = time.time()
results = search(str(self.enter.text()), N)
end = time.time()
self.text_0.insertPlainText('为您找到相关结果{}个(只显示前20个结果),共花费{}秒\n\n'.format(len(results), (end - first)))
try:
for result in results[:20]:
self.text_0.append('<a href="{}">{}</a><br><br>'.format(result[0], result[1]))
except:
pass
if __name__ == '__main__':
app = QApplication(sys.argv)
window = SearchEngine()
window.show()
sys.exit(app.exec_())
代码的主要功能和步骤如下:
1.初始化界面:使用 QMainWindow 创建主窗口,并设置窗口标题和初始大小。设置背景颜色和字体样式。
2.布局设置:创建一个垂直布局,并将各个部件加入布局中,包括标签、输入框、搜索按钮、文本浏览器和垂直滚动条。设置各个部件的样式,包括背景颜色、边框等。
3.按钮点击事件:click_button 方法响应搜索按钮的点击事件,首先清空文本浏览器中的内容,然后调用 get_sum 函数获取数据库中的总记录数,并调用 search 函数进行搜索,最后将搜索结果显示在文本浏览器中。
4.启动界面:在主程序中创建 QApplication 实例和 SearchEngine 窗口实例,显示窗口并运行应用。















 2058
2058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









