






知识蒸馏
每日一诗:
《次郭羲仲韵柬玉山人》
明·张居正
故人一隔红云岛,相见银屏七夕前。
花近小山当鹤广,溪深嘉树覆书船。
参差清吹流银汉,餮殄文彝散玉烟。
更拟此君亭子上,醉欹纱帽会群贤。
1.概述:
本文简单介绍知识蒸馏提出背景、定义以及其与联邦知识蒸馏(后续会进一步补充)。
高性能的深度学习网络通常是计算型和参数密集型的,难以应用于资源受限的边缘设备. 为了能够在低资源设备上运行深度学习模型,需要研发高效的小规模网络.
知识蒸馏是获取高效小规模网络的一种新兴方法, 其主要思想是将学习能力强的复杂教师模型中的“知识”迁移到简单的学生模型中. 同时,它通过神经网络的互学习、自学习等优化策略和无标签、跨模态等数据资源对模型的性能增强也具有显著的效果。
2.背景
对高效的(Efficient)深度学习模型展开研究,其目的是使具有高性能 的模型能够满足低资源设备的低功耗和实时性等要求,同时尽可能地不降低模型的性能.
主要有 5 种方法可以获得高效的深度学习模型:直接手工设计轻量级网络模型、剪枝、量化、基于神经架构搜索(Neural Architecture Search,NAS)的网络自 动化设计以及知识蒸馏。
知识蒸馏(Knowledge Distillation)
是一种教师-学生(Teacher-Student)训练结构,通常是已训练好的教师模型提供知识,学生模型通过蒸馏训练来获取教师的知识. 它可以以 轻微的性能损失为代价将复杂教师模型的知识迁移 到简单的学生模型中。分出基于知识蒸馏的模型压缩和模型增 强这两个技术方向。其中的教师模型都是提前训练好的复杂网络. 模型压缩和模型增强都是将教师模型的知 识迁移到学生模型中. 所不同的是,
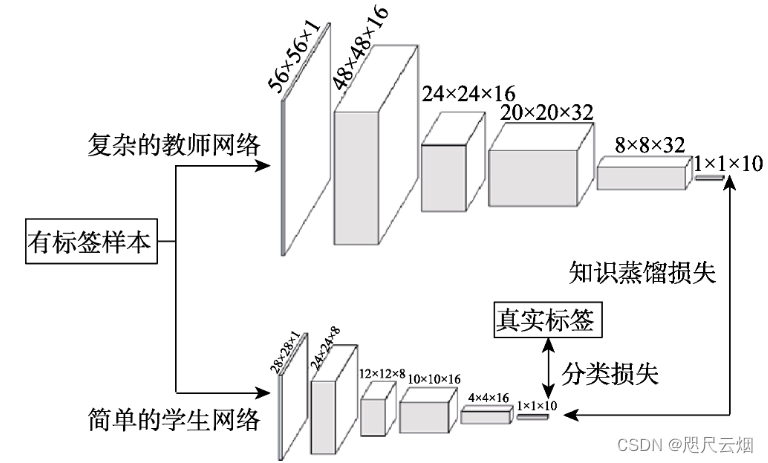
模型压缩
教师网络在相同的带标签的数据集上指导学生网络的 训练来获得简单而高效的网络模型,如左图的学生 是高效的小规模网络.
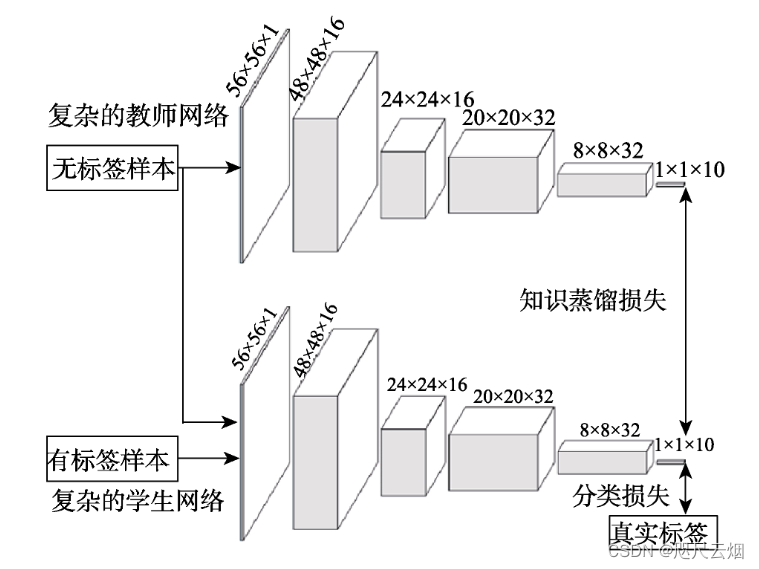
模型增强
强调利用其它资 源(如无标签或跨模态的数据)或知识蒸馏的优化策 略(如相互学习和自学习)来提高一个复杂学生模型 的性能. 如右图中,一个无标签的样本同时作为教 师和学生网络的输入,性能强大的教师网络通常能 预测出该样本的标签,然后利用该标签去指导复杂 的学生网络训练.
3.知识蒸馏与迁移学习的差异:
知识蒸馏与迁移学习的思想较为相似。然而它们有以下四点的不同:
(1)数据域不同.
知识蒸馏中的知识通常是在同 一个目标数据集上进行迁移,而迁移学习中的知识 往往是在不同目标的数据集上进行转移.
(2)网络结构不同.
知识蒸馏的两个网络可以是 同构或者异构的,而迁移学习通常是在单个网络上 利用其它领域的数据知识.
(3)学习方式不同.
迁移学习使用其它领域的丰 富数据的权重来帮助目标数据的学习,而知识蒸馏 不会直接使用学到的权重.
(4)目的不同.
知识蒸馏通常是训练一个轻量级 的网络来逼近复杂网络的性能,而迁移学习是将已 经学习到相关任务模型的权重来解决目标数据集的 样本不足问题.
4.知识蒸馏与联邦学习:
知识蒸馏可用于减少分布式的联邦学习训练时所占用的带宽,它在联邦学习的各个阶段,通过减少部分参数或者样本的传输的方式实现成本压缩.
一些工作通过只传输模型的预测信息而不是整个模型参数,各个参与者利用知识蒸馏,学习服务器聚 合全局模型的预测信息来提高性能. 知识蒸馏和联 邦学习通过只传输各个局部模型和全局模型的预测值,可以减少网络带宽、允许模型异构和保护数据 的隐私.
例如,Sui 等人从多个参与者的预测信 息中学习一个紧凑的全局模型.
Sattler 等人提出 量化、无损编码和双蒸馏的方法来进一步地节约传输软目标所占用的带宽.
各个参与者的数据可以通过数据蒸馏的方式,压缩为少量的伪样本, 传输并聚合这些伪样本来训练全局模型也能减少带 宽的使用.
不同于只传输网络的预测,另有工作关注于利用知识蒸馏高效地融合各个参与者的异构局部模型知识. 例如,Shen 等人[128]使用相互蒸馏,在联邦学习本地更新的过程中训练不同架构的模型.
Lin等人利用未标记的数据或伪样本聚合所 有异构参与者的模型知识.
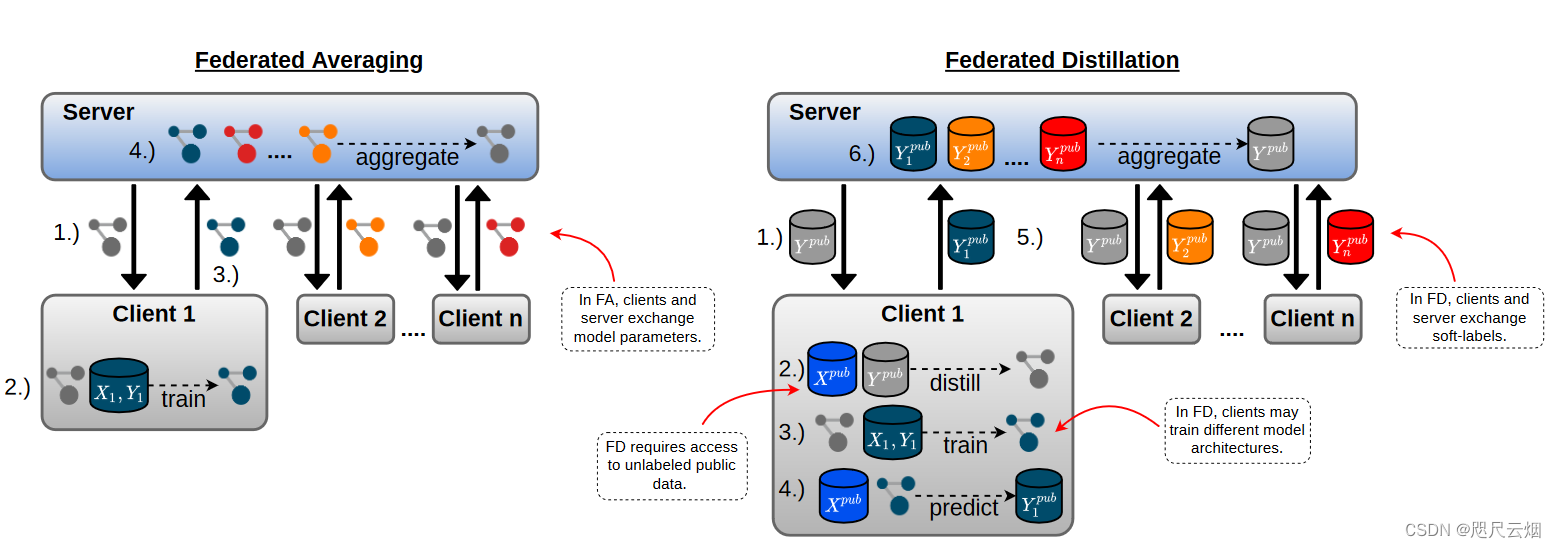
知识蒸馏和联邦平均的基础方法(FedAvg)结合算法可见下图,相比于联邦平均直接将模型的参数合并,联邦知识蒸馏则是将各个参与者模型在相同的公共数据集上计算得到的软目标合并,作为下一轮新的软目标,仍然是迭代更新模型。
reference:
Sattler, Felix, et al. “Communication-efficient federated distillation.” arXiv preprint arXiv:2012.00632 (2020).
https://zhuanlan.zhihu.com/p/337132669
https://zhuanlan.zhihu.com/p/81467832

















 1431
1431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









