






 文章探讨了在多接入边缘计算(MEC)场景下的多任务联邦学习(FMTL),提出FedICT框架,通过联邦先验知识蒸馏(FPKD)和本地知识调整(LKA)解决个性化模型训练、通信负担和模型异构问题,同时避免依赖公共数据集。作者强调了在无公共数据集情况下处理客户端漂移的挑战。
文章探讨了在多接入边缘计算(MEC)场景下的多任务联邦学习(FMTL),提出FedICT框架,通过联邦先验知识蒸馏(FPKD)和本地知识调整(LKA)解决个性化模型训练、通信负担和模型异构问题,同时避免依赖公共数据集。作者强调了在无公共数据集情况下处理客户端漂移的挑战。
FedICT: Federated Multi-task Distillation for Multi-access Edge Computing
每日一诗:
《浣溪沙·谁念西风独自凉》
清·纳兰性德
谁念西风独自凉,萧萧黄叶闭疏窗,沉思往事立残阳。
被酒莫惊春睡重,赌书消得泼茶香,当时只道是寻常。
做人,本质上是修心。
文章目录
这是我follow中科院计算所Zhiyuan的第二篇文章,投递于IEEE Transactions on Parallel and Distributed Systems (TPDS). 2023. (CCF-A),聚焦于多接入边缘计算场景下多任务联邦蒸馏。
下文是对相关工作的解读并融入了个人的一些思考,希望能给您带来帮助。同时,不足之初希望大家多多指出。
1.Abstraction
边缘智能场景下:需要为每个客户端提供用户个性化服务,模型多样性强,多任务联邦学习(FMTL)呼之欲出。——个性化模型训练
先前关于FMTL的研究存在: 通信负载大、模型异构 两大问题——通信负载、模型异构
引入知识蒸馏KD实现通信压缩并使能异构模型训练(此处模型行异构指的是神经网络的Size和架构)
先前的基于KD的FMTL方法大多依赖于公共数据集合(公共数据集合的数据分布要求与Client端相似才能有比较好的结果),FL场景下要保障用户数据安全。——不依赖于公共数据集合
| 存在问题 | 解决方案 |
|---|---|
| 个性化模型需求(每个客户端任务目标不一致,在实验上面体现为各个客户端的模型size和表征不同;每个客户端在不同分布的测试集上测试) | FMTL |
| FMTL 通信负载和模型异构问题 | KD+FL |
| KD依赖于公共数据集合 | FedICT |

为了在不依赖代理数据集的前提下解决MEC场景下普遍同时存在的个性化模型训练(多任务)、通信负载大、模型不能异质等问题,提出联邦多任务蒸馏框架 FedICT。
FedICT旨在支持多任务客户端,同时减轻由于客户端本地模型优化方向不同而产生的客户端漂移。由两部分组成,用于个性化客户端蒸馏的联邦先验知识蒸馏(FPKD)和用于纠正服务器端蒸馏的本地知识调整(LKA)。
前者基于局部数据分布的先验知识来增强客户端的多任务能力,并通过在局部蒸馏过程中控制类注意力来增强局部模型与其局部数据的拟合程度(保持差异性)。
后者被提出来纠正服务器上全局蒸馏的损失,从而防止全局优化方向因本地更新而倾斜。
具体来说,FedICT包括联邦先验知识蒸馏(FPKD)和本地知识调整(LKA)。
提出 FPKD 通过引入本地数据分布的先验知识来加强客户端对本地数据的拟合。
提出LKA纠正服务器的蒸馏损失,使得转移的局部知识更好地匹配泛化表征。
2.Contribution
支持多任务联邦学习的蒸馏方法,都是依赖于公共数据集合,尽管很少有FD方法可以在没有公共数据集的情况下实现客户端-服务器共蒸馏,但由于忽略了客户端之间的数据差异,它们仅适用于单任务设置。当基于多任务时,在没有公共数据集的FD方法中直接对局部模型进行个性化参数更新通常是无效的,因为它加剧了局部优化方向偏离全局模型的方向,即客户端漂移,这导致不尽如人意的全局聚合,进而极大地限制了客户的个性化。如何在没有公共数据集帮助的情况下克服客户漂移的不利影响并很好地实现局部蒸馏差异化成为基于FD的FMTL的首要问题。

FedICT基于联邦蒸馏实现个性化本地模型的同时减轻客户端漂移对模型收敛的影响。
1.提出了基于 FD 的 FMTL 框架(即 FedICT),它可以在没有公共数据集的情况下,从(疏远局部全局)知识的新角度实现对客户端的基于蒸馏的个性化优化,同时减少客户端漂移的影响。
2.提出 FPKD 通过引入本地数据分布的先验知识来增强客户端本地模型对不一致数据的拟合程度。此外,LKA被提出来纠正服务器端全局模型的蒸馏损失,旨在减轻由于客户端和服务器之间的知识不适配(不一致DL散度偏大)而导致的客户端漂移。
3.Introduction
3.1 个性化模型训练
由于个体行为的多样化,跨设备的本地数据分布通常在 MEC 中表现出不同的特征和明显的偏差 (数据分布偏差)
数据分布不同,每个客户端训练任务的优化目标不同,为了协同训练具有不同更新目标的单独模型,联邦多任务学习(FMTL)将每个设备上的本地模型训练视为学习任务,以满足个性化需求。
FedICT方案引入FMTL实现个性化模型训练
3.2 通信负担&模型异构
现有的FMTL面临: 通信负担和模型异构(网络架构不同)
需要大规模的参数传输,并且仅支持在服务器和客户端上采用相同的模型架构,
Knowledge Distillation (KD)应运而生, 它减少通信负担 允许模型异构
FedICT引入KD实现通信压缩与支持异构模型训练
3.3 不依赖于公共数据集的影响
支持多任务联邦学习的蒸馏方法,都是依赖于公共数据集合(数据分布与客户端分布大致相同)
(在实践中,收集或生成许多未标记的样本并不困难。然而,收集或生成与私有标记数据集具有相同数据分布的公共数据集是很困难的。在FD作品的实证模拟中,公共数据集分布问题常常被忽略。为了研究蒸馏数据集分布的影响,我们使用两个蒸馏数据集进行了实验,即 CIFAR-10(分布完全相同的数据集)和 STL-10(分布相似但更广泛的数据集)。)
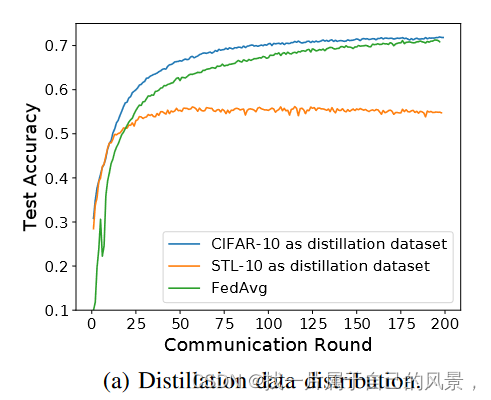
由于收集的公共数据需要与客户端的私有数据进行数据分布的比较,所有依赖于公共数据集的FD方法无疑会导致客户端的隐私泄露(数据分布泄露),并且在MEC中是不切实际。
3.4 Superiority of FD for FMTL
FD的整个过程可以分为多轮。每轮由两个阶段组成:
本地蒸馏,客户端根据从服务器传回的全局知识更新本地模型;
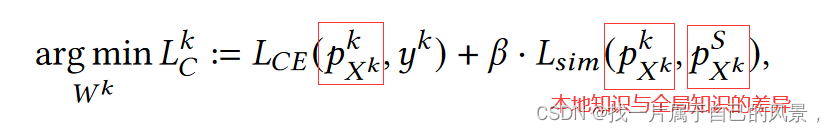
W
k
=
W
e
k
+
W
p
k
前者为表征层将输入映射为
H
k
特征向量、后者为分类层将输入映射为本地
l
o
g
i
t
s
(知识)
p
X
k
k
,
全局知识
p
X
k
S
可由
W
S
得到
W^k=W^k_e+W^k_p \\前者为表征层将输入映射为H^k特征向量、后者为分类层将输入映射为本地logits(知识) p^k_{X^k}, \\ 全局知识p^S_{X^k}可由W^S得到
Wk=Wek+Wpk前者为表征层将输入映射为Hk特征向量、后者为分类层将输入映射为本地logits(知识)pXkk,全局知识pXkS可由WS得到
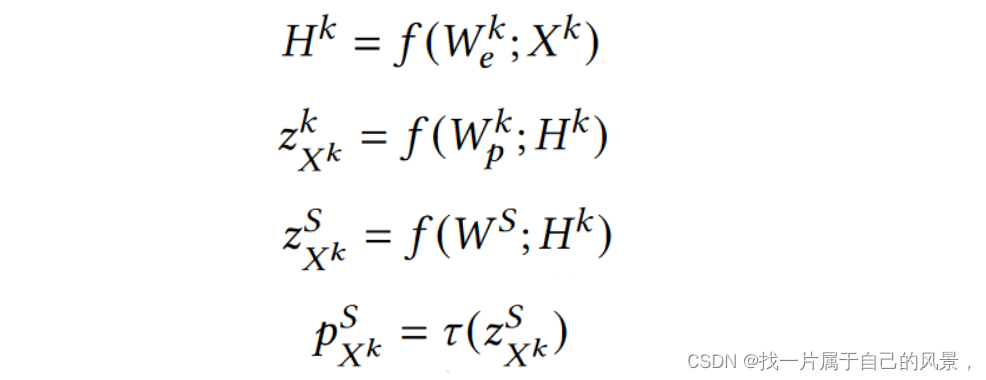
全局蒸馏,服务器上的全局模型根据客户端上传的本地知识进行知识蒸馏。
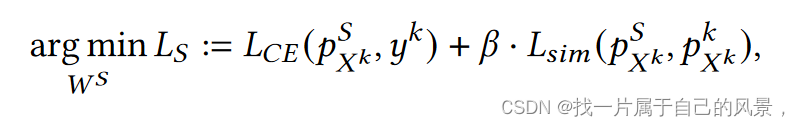
通信交互:提取的特征 H k H^k Hk和local-global knowledge z X k k , z X k S {z^k_{X^k} , z^S_{X^k}} zXkk,zXkS,远小于模型参数parameter
那么如何在融合FD和FTML(解决前三个问题)的情况下,不依赖于公共数据集合进行训练?
下面解释不依赖公共数据集合会产生的影响。
3.5 Aloof Local-Global Knowledge
客户之间的知识不一致影响服务器端蒸馏、收敛:
客户端之间数据异质性,每个客户端上的局部模型倾向于学习本地样本以提高局部拟合程度。
而全局模型需要根据客户端和服务器之间的知识相似性进行优化。

如果直接从客户端学习不一致的知识,服务器将学习到有偏差的表示,并且很容易无法顺利收敛,从而无法获得近似最优的全局知识,进而影响客户端的训练准确性。
如图所示,来自单个客户端的局部知识将有助于全局模型的优化方向。然而,异构客户端之间的知识不一致会导致优化偏差和收敛方向的频繁波动。这些负面影响导致实际结果偏离最佳结果。

在没有公共数据集的FD方法中直接对局部模型进行个性化参数更新通常是无效的,因为它加剧了局部优化方向偏离全局模型的方向,即客户端漂移,这导致模型收敛慢、客户端模型个性化能力弱。
如何在没有公共数据集帮助的情况下克服由于客户漂移对全局模型更新造成的不利影响并很好地实现局部蒸馏差异化(保证个性化)成为基于FD的FMTL的首要问题。(如何在没有公共数据集帮助的情况下,有Aloof Local-Global Knowledge的好处(差异化),同时规避Aloof Local-Global Knowledge的弊端(防止客户漂移))
3.6 KD&FMTL “悖论”
FD需要局部模型部分模仿全局模型,因此局部模型倾向于学习全局模型的同构表示,这在一定程度上抑制了客户端适应多个任务的能力。
FMTL 期望训练具有高度个性化的局部模型,异构客户端之间的这种知识不一致会导致优化偏差和收敛方向的频繁波动。
高度偏差的局部知识影响全局知识偏离优化方向,两者相互矛盾。
4.系统架构
与以前的方法不依赖公共数据集的框架不同,我们在局部和全局蒸馏阶段执行知识适应过程。具体来说,引入局部数据分布的先验知识,以在局部蒸馏过程中个性化局部模型;全局与局部数据分布的不一致被认为可以减少全局蒸馏过程中的全局-局部知识分歧。
4.1 局部蒸馏
FPKD:基于局部数据分布的先验知识来增强客户端的多任务训练能力,学习局部数据的分布增强局部模型与其局部数据的拟合程度。
在FMTL中,局部模型的训练任务与局部数据分布高度相关,为了更偏向于局部表示,可以利用本地数据分布来优化客户端本地模型,并专注于高频的类以适应倾斜的本地数据。
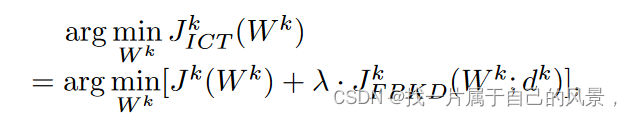
基于数据分布的加权值:
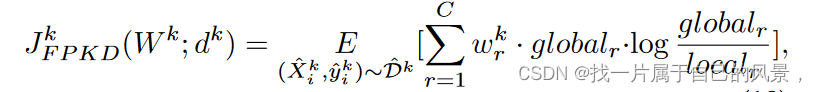
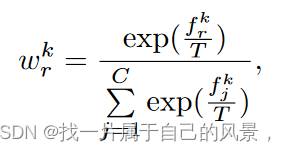
4.2 全局蒸馏
LKA:纠正服务器上全局蒸馏的损失,从而防止全局优化方向因本地更新而倾斜。
在 FMTL 的全局蒸馏过程中,需要解决局部模型之间bias大的问题,该问题源于数据异构性和个性化局部蒸馏(例如,第 4.3 节中讨论的 FPKD)
局部分歧对整体 FL 训练是有害的,因为客户端局部模型往往会逐渐忘记全局模型的表示并偏向其局部目标 。
当聚合高度差异化的本地模型时,这种现象不可避免地会造成更新不一致和收敛不稳定,即客户端漂移。为此,我们希望通过重视局部知识来解决上述问题。具体来说,我们考虑两个层面:
客户层面:全局模型优化更关注来自局部数据分布与整体数据分布相似的客户端的局部知识。
类别水平:全局蒸馏中的类重要性与全局-局部类频率的残差正相关。
全局蒸馏目标公式:
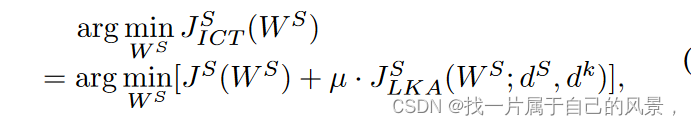
基于上述两个见解,我们分别提出了基于相似性的LKA和类平衡的LKA。
Similarity-based Local Knowledge Adjustment
FD的训练性能可以通过具有相似数据分布的客户端之间的知识协作来提高。可以通过数据分布与整体数据分布相似的客户的协作来增强全局蒸馏。
因此,我们设计了局部知识的分布权重,旨在减少不一致知识对全局模型的负面影响。
准确地说,全局知识和局部知识之间的相似度差异是通过全局和局部数据分布向量的余弦相似度来衡量的。
然后,来自客户的局部知识的权重与全局蒸馏过程中产生的知识相似度成正比。
基于数据分布相似性的全局蒸馏目标定义如下:
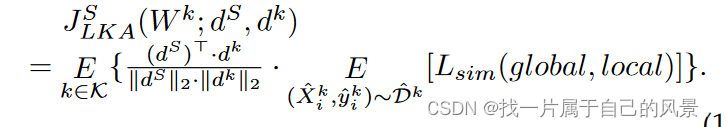
Class-balanced Local Knowledge Adjustment
由于不同的用户行为,本地数据在 FL 场景中通常是类别不平衡的。
因此,每个客户端的局部模型训练与局部类别分布强相关,自然会更加关注高频类别。不仅因为高频类别被分配更高的概率以减少局部损失,还因为FPKD增强了局部模型的局部数据拟合程度。
这种现象阻碍了全局蒸馏并减慢了模型收敛速度。为此,我们提出了一种基于类频率残差的软标签加权技术,该技术为全局蒸馏期间客户端的本地类频率高于全局类频率的类分配较低的权重。该技术可以通过平衡类之间转移的局部知识来缩小全局-局部知识差异,防止全局模型学习倾斜的局部类表示。
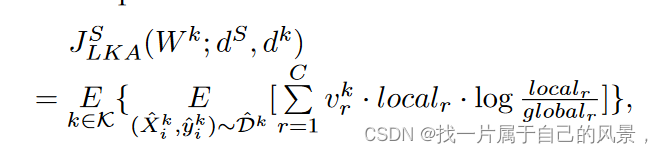
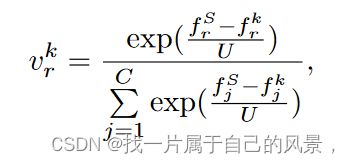
从全局和局部模型转移的知识将偏向与各自目标模型相关的数据分布,即 诱导疏远的局部-全局知识。(各个数据分布是不同的)
达到的目的是 局部个性化(偏向于自己的分布),全局在有较大的偏差的情况下实现快速收敛拟合
双向蒸馏过程中的这种归纳使局部模型能够充分适应局部任务,同时促进全局模型集成个性化的局部知识以实现更快的收敛。
具体来说,我们提出联合先验知识蒸馏(FPKD,与 J F P K D k J^k_{FPKD} JFPKDk 相关)和局部知识调整(LKA,与 J L K A S J^S_{LKA} JLKAS相关)来共同实现(超然局部全局知识)。
4.3 算法框架


5. 问题与讨论
1.多任务学习相关解释可以完善一些,只给出客户端本地训练目标函数,没能体现任务间的相关和差异关系。
多任务是客户端模型预期的优化目标不同-这样的解释更明确
这里牵扯到两个相互概念:
a.系统异构-客户端模型架构(size)不同
b.任务异构-客户端模型优化目标(task)不同
我们常说的personalized federated learning(根据杨强教授的权威综述)既可以指a又可以指b
2.本质上,FPKD,LKA 从目标优化损失函数着手,加入约束项,从宏观大方向上确定优化方向,FPKD使得客户端拟合本地数据分布、LKA弱化某些参数的影响,防止泛化模型偏离最优,这部分的实验证明效果很好。

















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









