






在机器学习模型开发中,评价指标是衡量模型性能的重要依据,不同的指标反映了模型在不同任务中的优劣势。以下是常见的机器学习评价指标的定义、意义和计算公式,通过简单示例和图表进行说明。
混淆矩阵
混淆矩阵(Confusion Matrix) 是一种可视化的工具,用来评估分类模型的性能。它以矩阵形式展示了模型预测结果的分布情况,按真实类别和预测类别进行划分,尤其适用于分类任务。
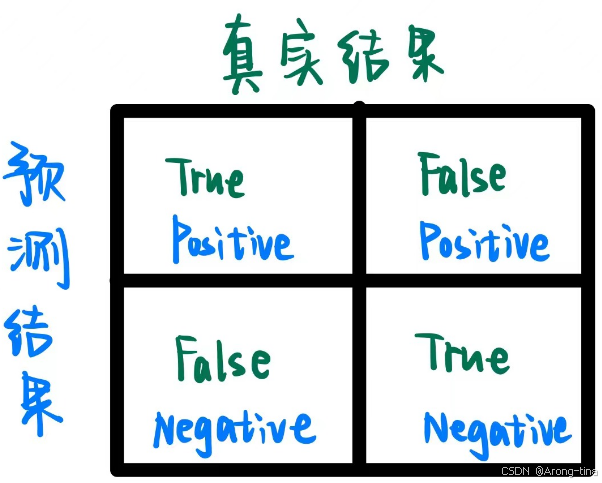
- 真负例 (True Negative, TN):模型正确预测为负类的样本数。
- 假正例 (False Positive, FP):模型错误预测为正类的负类样本数。
- 假负例 (False Negative, FN):模型错误预测为负类的正类样本数。
- 真正例 (True Positive, TP):模型正确预测为正类的样本数。
下面是一个二分类的混淆矩阵示意图:
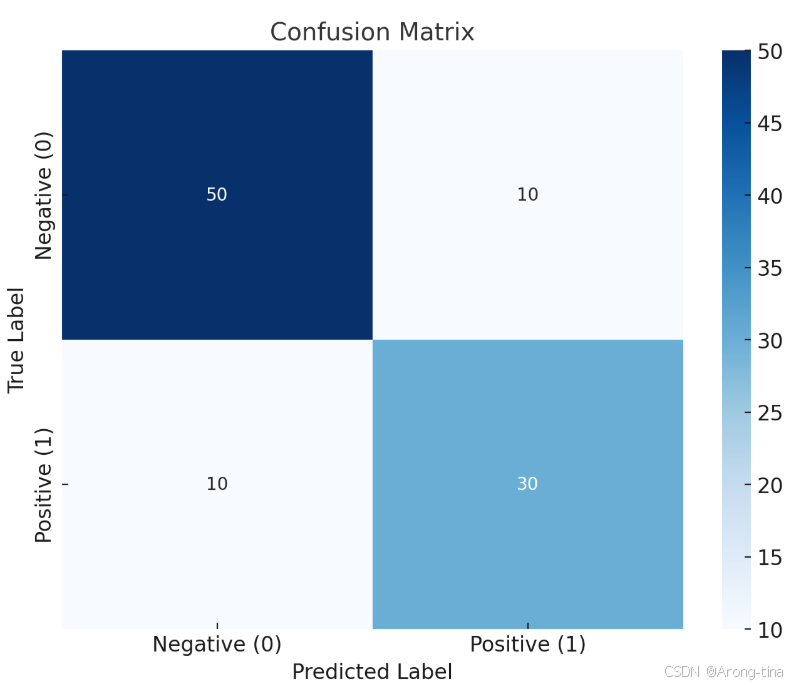
混淆矩阵可以清晰地展示模型再不同类别上的预测表现,如哪些类别容易被误判。接下来的各个评价指标也是基于混淆矩阵来进行计算的。
准确率(Accuracy)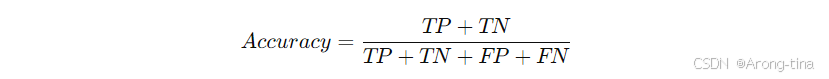
定义:模型预测正确的样本数占总体样本数量的比例(也就是混淆矩阵从左上到右下对角线上的样本数量作为分子,即:预测真/总量)。
意义:衡量模型总体正确率,适用于类别均衡的数据集(常见于传统机器学习的分类任务)。
缺点:在类别不均衡的时候(比如正样本数量远远少于负样本),准确率可能无法真实反映模型性能(这种情况下效果会过于乐观)。
代码示例:
def eval(net, dataloader, device, criterion, num_samples):
# Evaluate the model on the validation set
val_loss = 0.0
val_acc = 0.0
net.eval()
with tqdm(total=len(dataloader), desc='Validation round', unit=' img') as pbar:
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = net(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item() * inputs.size(0)
_, preds = torch.max(outputs, 1)
val_acc += torch.sum(preds == labels.data) #分子是预测为真的数量
pbar.update(inputs.shape[0])
val_loss /= num_samples
val_acc /= num_samples #准确率=预测为真/总量
net.train()
return val_loss, val_acc精确率(Precision)
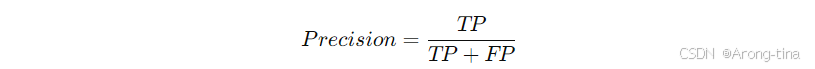
定义:预测为正样本中实际为正样本的比例。
意义:衡量模型在正例预测中的准确性,适用于需要降低假正例影响的场景(如垃圾邮件分类)。
缺点:对假反例(FN)不敏感。
代码示例:
from sklearn.metrics import precision_score # 必须导入的包
def eval_precision(net, dataloader, device):
all_labels = [] # 存储所有真实标签
all_preds = [] # 存储所有预测标签
net.eval()
with tqdm(total=len(dataloader), desc='Validation round', unit=' img') as pbar:
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = net(inputs)
_, preds = torch.max(outputs, 1) # 获取预测的类别
all_labels.extend(labels.cpu().numpy()) # 收集真实标签
all_preds.extend(preds.cpu().numpy()) # 收集预测标签
pbar.update(inputs.size(0))
# 精确率公式:TP / (TP + FP)
# TP: 预测为正且实际为正的样本数
# FP: 预测为正但实际为负的样本数
precision = precision_score(all_labels, all_preds, average='binary') # 调用precision_score函数
net.train()
return precision召回率(Recall)
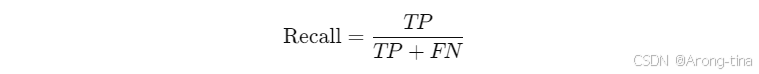
定义:实际为正例的样本中,被正确预测为正例的比例。
意义:衡量模型对正例的敏感性,适用于需要尽可能减少漏检的场景(如疾病检测)。
缺点:对假正例(FP)不敏感。
代码示例:
from sklearn.metrics import recall_score # 需要导入的包
def eval_recall(net, dataloader, device):
all_labels = [] # 存储所有真实标签
all_preds = [] # 存储所有预测标签
net.eval()
with tqdm(total=len(dataloader), desc='Validation round', unit=' img') as pbar:
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = net(inputs)
_, preds = torch.max(outputs, 1) # 获取预测的类别
all_labels.extend(labels.cpu().numpy()) # 收集真实标签
all_preds.extend(preds.cpu().numpy()) # 收集预测标签
pbar.update(inputs.size(0))
# 召回率公式:TP / (TP + FN)
# TP: 预测为正且实际为正的样本数
# FN: 实际为正但预测为负的样本数
recall = recall_score(all_labels, all_preds, average='binary') # 调用召回率计算函数
net.train()
return recall
F1分数(F1 Score)
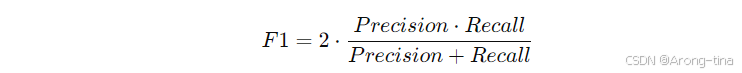
定义:之前给出的精确率和召回率分别会导致对假负例和假正例不敏感,F1分数综合考虑两者,是精确率和召回率的调和平均值。
意义:平衡精确率和召回率,适用于正负样本不均衡的场景。
缺点:可能无法反映业务需求的优先级。
例如,在医疗诊断中,某些疾病的漏诊(召回率低)可能会比误诊(精确率低)更加严重。在这种情况下,业务可能更偏向于提高召回率,而不是追求F1分数的平衡。
代码示例:
from sklearn.metrics import f1_score
def eval_f1(net, dataloader, device):
all_labels = [] # 存储所有真实标签
all_preds = [] # 存储所有预测标签
net.eval()
with tqdm(total=len(dataloader), desc='Validation round', unit=' img') as pbar:
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = net(inputs)
_, preds = torch.max(outputs, 1) # 获取预测的类别
all_labels.extend(labels.cpu().numpy()) # 收集真实标签
all_preds.extend(preds.cpu().numpy()) # 收集预测标签
pbar.update(inputs.size(0))
# F1分数公式:2 * (Precision * Recall) / (Precision + Recall)
# Precision: 精确率
# Recall: 召回率
f1 = f1_score(all_labels, all_preds, average='binary') #直接调用函数
net.train()
return f1
ROC曲线和AUC
这是一个比较抽象也相对难理解的概念,下面我将详细说明一下。
什么是ROC曲线
ROC曲线用于展示分类模型在不同阈值下的性能,主要反映模型灵敏度(Sensitivity)与特异性(Specificity)之间的权衡。AUC(Area Under the Curve)是ROC曲线下的面积,反映了模型区分正负类的能力。举个例子来说:

如果最后绘制出来的ROC曲线长这样,那么曲线和横坐标轴围成的面积就是AUC的数值,其中AUC曲线必然过(0,0)和(1,1),ROC曲线越靠近左上角说明模型预测效果越好(图中绿色这条线)。
理解案例
假设1表示患者患病,0表示患者健康。
| 真实类别 | |||
| 1 | 0 | ||
| 预测类别 | 1 | TP | FP |
| 0 | FN | TN | |
真阳性率(TPR):即召回率,表示在所有实际为正类的样本中,模型正确预测为正类的比例。
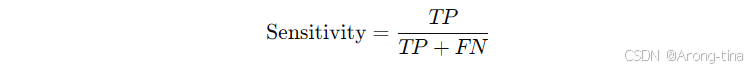
假阳性率(FPR):表示在所有实际为负类的样本中,模型正确预测为负类的比例。
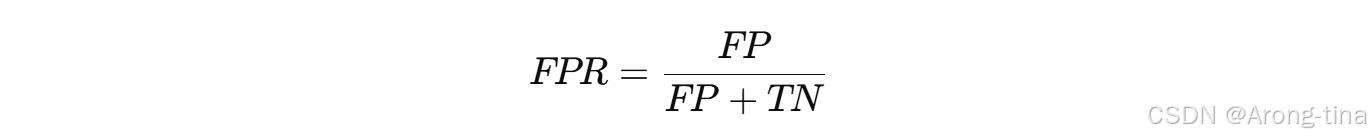
假设总共有10个患者,其中5个患者真实情况下是患病(1),5个患者真实情况下是正常(0),模型对于这几个患者的预测结果(这里的概率值指的是模型预测为“1”的概率)如下:
| 患者 | 类别 | 模型预测概率 |
| P1 | 1 | 0.9 |
| P2 | 1 | 0.8 |
| P3 | 1 | 0.3 |
| P4 | 1 | 0.7 |
| P5 | 1 | 0.5 |
| P6 | 0 | 0.6 |
| P7 | 0 | 0.4 |
| P8 | 0 | 0.3 |
| P9 | 0 | 0.1 |
| P10 | 0 | 0.2 |
那么比如我们设定概率阈值为0.9,得到的混淆矩阵就是:
| 真实类别 | |||
| 1 | 0 | ||
| 预测类别 | 1 | 1 | 0 |
| 0 | 4 | 5 | |
解释:
- 这个时候只有P1患者的概率符合要求,他真实为患病预测也是患病,所以TP=1;
- 剩下四个真实也患病的患者(P2/P3/P4/P5),没有被检测出患病,所以FN=4;
- 因为健康的患者模型预测为“1”概率都小于0.9,没有患者满足阈值要求,也就是说没有健康的患者被预测为患病,所以FP=0;
- 相应的健康的患者无法超过阈值被预测为患病,自然就全部归为健康,所以TN=5。
根据不同的阈值进行划分,就能得到各个阈值下面的混淆矩阵,也就能根据混淆矩阵计算灵敏度和特异性,绘制成表格如下:
| 划分阈值 | 灵敏度 | 特异性 |
| ≥0.9 | 1/5 | 0/5 |
| ≥0.8 | 2/5 | 0/5 |
| ≥0.7 | 3/5 | 0/5 |
| ≥0.6 | 3/5 | 1/5 |
| ≥0.5 | 4/5 | 1/5 |
| ≥0.4 | 4/5 | 2/5 |
| ≥0.3 | 5/5 | 3/5 |
| ≥0.2 | 5/5 | 4/5 |
| ≥0.1 | 5/5 | 5/5 |
把这些点绘制到图上就得到了对应的ROC曲线:
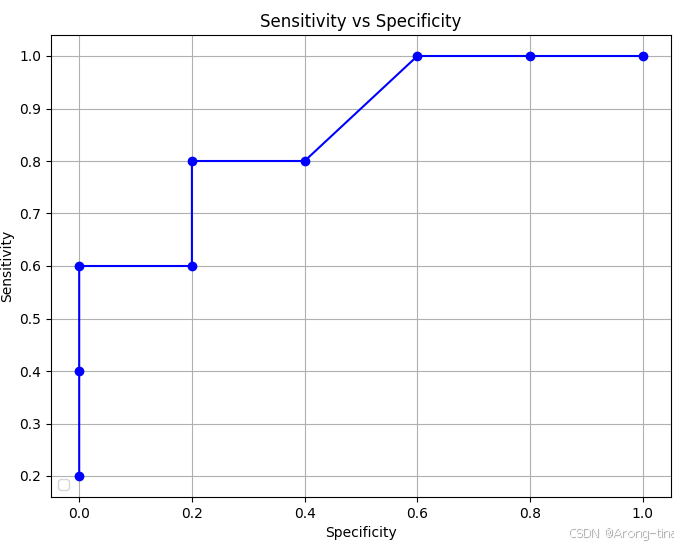
其中:
- 横坐标:表示假阳性率,即数据点的横坐标是每个阈值对应的特异性值。
- 纵坐标:表示真阳性率,即数据点的纵坐标是每个阈值对应的灵敏度值。
- 点的顺序:点是按照阈值从大到小的顺序排列的。即,阈值为 0.9 的点对应的特异性为 0/5,灵敏度为 1/5,依此类推。
ROC曲线展示了在不同阈值下的FPR与TPR的变化情况。随着阈值的不同,模型对正类的判定标准会发生变化,从而影响预测的TP和FP数量。
ROC曲线的统计学意义
从几何学角度看,ROC曲线实际上是一条反映假阳性率(FPR)和真正率(TPR)之间关系的曲线。我们可以将ROC曲线视为一个二维平面,其中横轴是FPR,纵轴是TPR。不同的点代表在不同阈值下,模型的TPR和FPR值。
- ROC曲线的上升:当TPR(召回率)增加时,ROC曲线向上移动,而FPR(误报率)通常会增加。
- ROC曲线的左上角:理想的模型应该尽可能靠近左上角,意味着高TPR和低FPR。
如果ROC曲线接近对角线(即FPR接近TPR),则表明模型的区分能力较差。
AUC的统计学意义
在理解了ROC曲线的由来之后,AUC(Area Under the Curve,ROC曲线下的面积)也就容易理解了,它反映了模型区分正负类的能力。AUC值的范围是[0, 1],其中:
- AUC = 1:表示模型完全正确地将所有正类与负类分开(即模型的性能非常好)。
- AUC = 0.5:表示模型没有区分能力,相当于随机猜测(即模型的性能很差)。
- AUC < 0.5:表示模型的预测效果比随机猜测还差,通常说明模型是倒错的。
这个面积和曲线的移动息息相关,曲线向左上角移动(高TPR和低FPR)我们认为是最好的,那这个时候曲线下面积也就跟着增大,也就越接近1。
ROC曲线和AUC计算的代码示例
ROC和AUC只针对二分类任务,所以多分类的话要先转化成多个二分类任务,基于之前的准确率代码进行修改添加:
def eval(net, dataloader, device, criterion, num_samples, num_classes):
"""
Evaluate the model on the validation set, computing loss, accuracy, and AUC for each class.
Args:
net: PyTorch model.
dataloader: DataLoader for the validation dataset.
device: Device to run the evaluation on.
criterion: Loss function.
num_samples: Total number of samples in the validation dataset.
num_classes: Number of classes.
Returns:
val_loss: Average validation loss.
val_acc: Overall validation accuracy.
per_class_acc: Per-class accuracy.
per_class_auc: Per-class AUC.
"""
val_loss = 0.0
val_acc = 0.0
class_correct = [0] * num_classes
class_total = [0] * num_classes
# Store true labels and predicted probabilities for AUC calculation
all_labels = []
all_probs = [[] for _ in range(num_classes)]
net.eval()
with tqdm(total=len(dataloader), desc='Validation round', unit=' img') as pbar:
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = net(inputs) # Raw logits
probs = torch.softmax(outputs, dim=1) # Probabilities for each class
loss = criterion(outputs, labels)
val_loss += loss.item() * inputs.size(0)
_, preds = torch.max(outputs, 1)
# Update overall accuracy
val_acc += torch.sum(preds == labels.data)
# Update per-class accuracy and collect data for AUC
for i in range(len(labels)):
label = labels[i].item()
pred = preds[i].item()
class_total[label] += 1
if label == pred:
class_correct[label] += 1
# Collect probabilities and true labels
all_labels.append(label)
for c in range(num_classes):
all_probs[c].append(probs[i, c].item())
pbar.update(inputs.shape[0])
val_loss /= num_samples
val_acc /= num_samples
net.train()
# Calculate per-class accuracy
per_class_acc = [class_correct[i] / class_total[i] if class_total[i] > 0 else 0 for i in range(num_classes)]
# Calculate per-class AUC
per_class_auc = []
for c in range(num_classes):
try:
auc = roc_auc_score([1 if label == c else 0 for label in all_labels], all_probs[c])
except ValueError:
auc = None # Handle case with no positive samples for a class
per_class_auc.append(auc)
return val_loss, val_acc, per_class_acc, per_class_aucROC曲线的绘制案例:
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
import numpy as np
# 假设 y_true 是真实标签,y_score 是模型的预测概率(通常是正类的概率)
y_true = np.array([0, 1, 1, 0, 1, 0, 1, 0, 0, 1]) # 真实标签
y_score = np.array([0.1, 0.4, 0.35, 0.8, 0.6, 0.2, 0.9, 0.7, 0.05, 0.95]) # 预测概率
# 计算假阳性率 (FPR)、真正率 (TPR) 和阈值
fpr, tpr, thresholds = roc_curve(y_true, y_score)
# 计算 AUC(曲线下面积)
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='b', label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', linestyle='--') # 对角线,表示随机猜测
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR)')
plt.legend(loc='lower right')
plt.grid(True)
# 显示图表
plt.show()


















 1501
1501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











