







目录
二、roc曲线(Receiver Operating Characteristic Curve)


一、混淆矩阵(Confusion Matrix)
1.1 简介
混淆矩阵(Confusion Matrix)是评估分类模型性能的工具,主要用于展示预测结果与实际标签的对比情况。它特别适用于二分类和多分类问题。
1.2 结构
混淆矩阵是一个N×N的矩阵(N为类别数),矩阵的行代表实际类别,列代表预测类别。
以二分类为例:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | TP(真正例) | FN(假反例) |
| 实际为负类 | FP(假正例) | TN(真反例) |
其中
-
TP(True Positive):实际为正类,预测也为正类。
-
FN(False Negative):实际为正类,但预测为负类。
-
FP(False Positive):实际为负类,但预测为正类。
-
TN(True Negative):实际为负类,预测也为负类。
再具体点,比如我们有一个疾病检测模型,用于判断一个人是否患有某种疾病。我们有一个包含 100 人的测试集,其中:
-
实际患病(正类):20 人
-
实际健康(负类):80 人
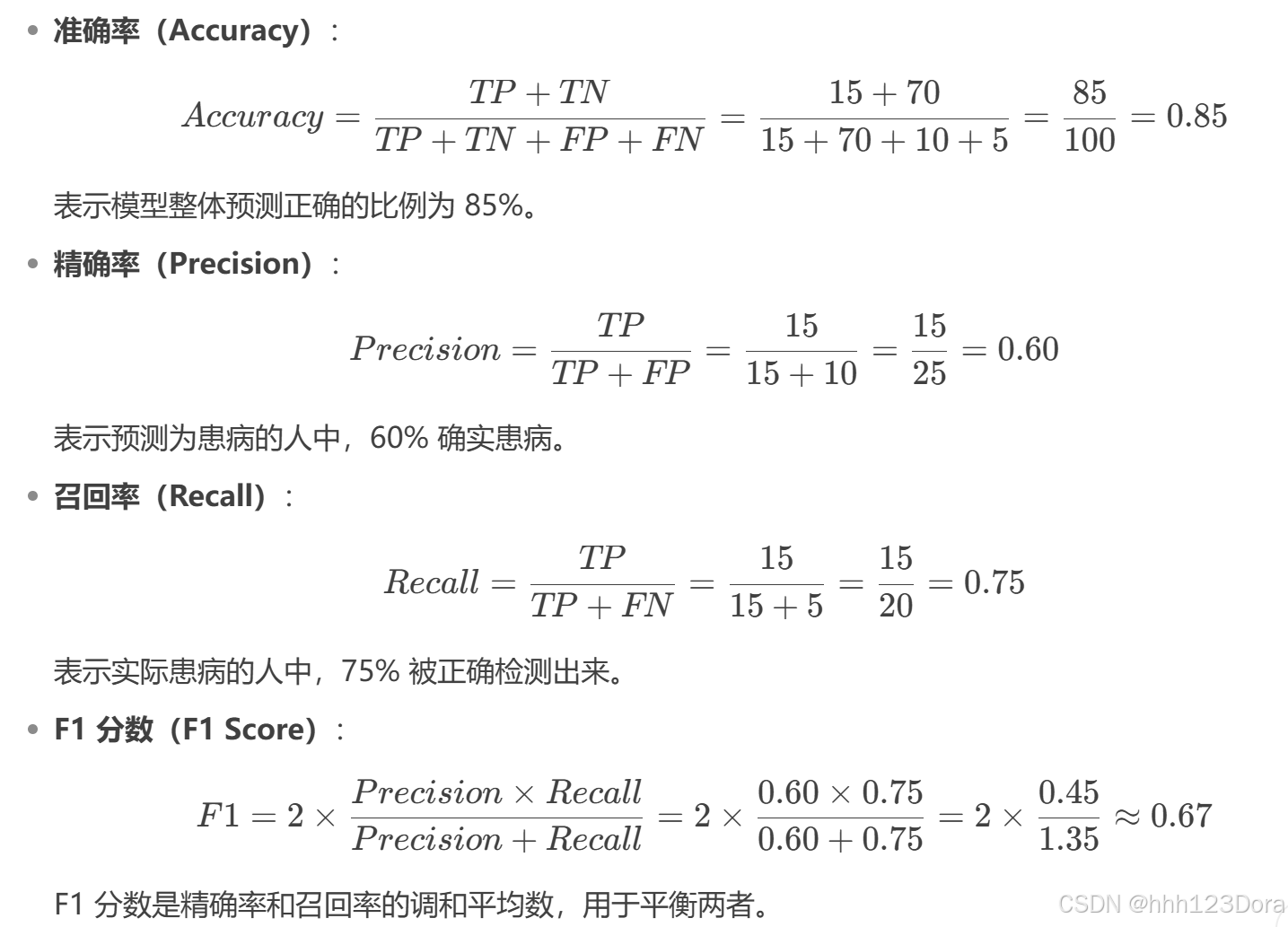
模型对这些人进行预测后,结果如下:
| 预测为患病 | 预测为健康 | |
|---|---|---|
| 实际患病 | 15 | 5 |
| 实际健康 | 10 | 70 |
根据表格,我们可以直接得到以下值:
-
TP(真正例):实际患病且预测为患病的人数 = 15
-
FN(假反例):实际患病但预测为健康的人数 = 5
-
FP(假正例):实际健康但预测为患病的人数 = 10
-
TN(真反例):实际健康且预测为健康的人数 = 70
1.3 作用(计算准确率、精确率、召回率、F1分数)
混淆矩阵用于计算以下指标:
-
准确率(Accuracy):正确预测的比例,公式为 (TP+TN)/(TP+TN+FP+FN)
-
精确率(Precision):预测为正类的样本中实际为正类的比例,公式为 TP/(TP+FP)
-
召回率(Recall):实际为正类的样本中被正确预测的比例,公式为 TP/(TP+FN)
-
F1分数(F1 Score):精确率和召回率的调和平均数,公式为 2×(Precision×Recall)/(Precision+Recall)
根据疾病模型可以计算
精确率与召回率的区别
| 指标 | 关注点 | 公式 | 适用场景 |
|---|---|---|---|
| 精确率 | 预测为正类的样本中,有多少是真正的正类 | TP/(TP+FP) | 假正例(FP)代价高的场景(如垃圾邮件检测) |
| 召回率 | 实际为正类的样本中,有多少被正确预测为正类 | TP/(TP+FN) | 假反例(FN)代价高的场景(如疾病检测) |
再形象一点,我们可以假设一个捕鱼的场景
假设你是一个渔夫,正在用渔网捕鱼。你的目标是尽可能多地捕到鱼(正类),但同时可能会捞到一些垃圾(负类)。
-
渔网的大小:代表模型的分类阈值。网越大,捞到的东西越多(包括鱼和垃圾);网越小,捞到的东西越少(可能漏掉一些鱼,但垃圾也更少)。
-
鱼:正类(你想要的)。
-
垃圾:负类(你不想要的)。
那么,
召回率衡量的就是,你捞到了多少真正的鱼🐟,占所有鱼的比重。
Recall = 捞到的鱼 / 所有的鱼
它关注的是你是否漏掉了鱼,如果召回率高,说明你捞到了大部分鱼,即使捞到了一些垃圾也没关系。如果你不想漏掉任何鱼(比如捕鱼是为了生存),召回率更重要。
例子,有一片海域,里面有100条鱼,你用一张大网,捞到了90条鱼,但也捞到了10个垃圾,召回率 = 90 / 100 = 90%
精确率衡量的就是,你捞到的东西里,有多少是真正的鱼。
Precision = 捞到的鱼 / (捞到的鱼 + 捞到的垃圾)
他关注的是你捞到的东西中有多少是你真正想要的,如果精确率高,说明你捞到的大部分是鱼,垃圾很少。如果你不想捞到垃圾(比如垃圾处理成本很高),精确率更重要。
例子,你用一张小网,捞到了50条鱼,但没有捞到任何垃圾,精确率 = 50 / (50 + 0) = 100%。
| 指标 | 关注点 | 捕鱼例子 | 适合场景 |
|---|---|---|---|
| 召回率 | 是否漏掉了鱼 | 你捞到了多少鱼,占所有鱼的比重 | 不想漏掉任何鱼(如疾病检测) |
| 精确率 | 捞到的东西中有多少是鱼 | 你捞到的东西中,鱼的比例是多少 | 不想捞到垃圾(如垃圾邮件检测) |
矛盾
-
大网:捞到更多的鱼(高召回率),但也会捞到更多垃圾(低精确率)。
-
小网:捞到更少的垃圾(高精确率),但可能会漏掉一些鱼(低召回率)。
总结为一句话就是:召回率高体现的是宁可错杀,不能放过,精确率高则是宁可放过,不能错杀。
1.4 代码
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix
import matplotlib.font_manager as fm
# 指定字体路径
font_path = r"d:\Users\z3322\Desktop\simhei.ttf" # 替换为你的字体文件路径
font_prop = fm.FontProperties(fname=font_path)
# 设置全局字体
plt.rcParams['font.sans-serif'] = [font_prop.get_name()]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 实际标签和预测标签
y_true = [1] * 20 + [0] * 80 # 1表示患病,0表示健康
y_pred = [1] * 15 + [0] * 5 + [1] * 10 + [0] * 70 # 模型预测结果
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
# 绘制混淆矩阵
plt.figure(figsize=(6, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False,
xticklabels=['预测健康', '预测患病'],
yticklabels=['实际健康', '实际患病'])
plt.xlabel('预测标签')
plt.ylabel('实际标签')
plt.title('混淆矩阵')
plt.tight_layout() # 自动调整布局
plt.show()运行结果如下
二、roc曲线(Receiver Operating Characteristic Curve)
2.1 简介
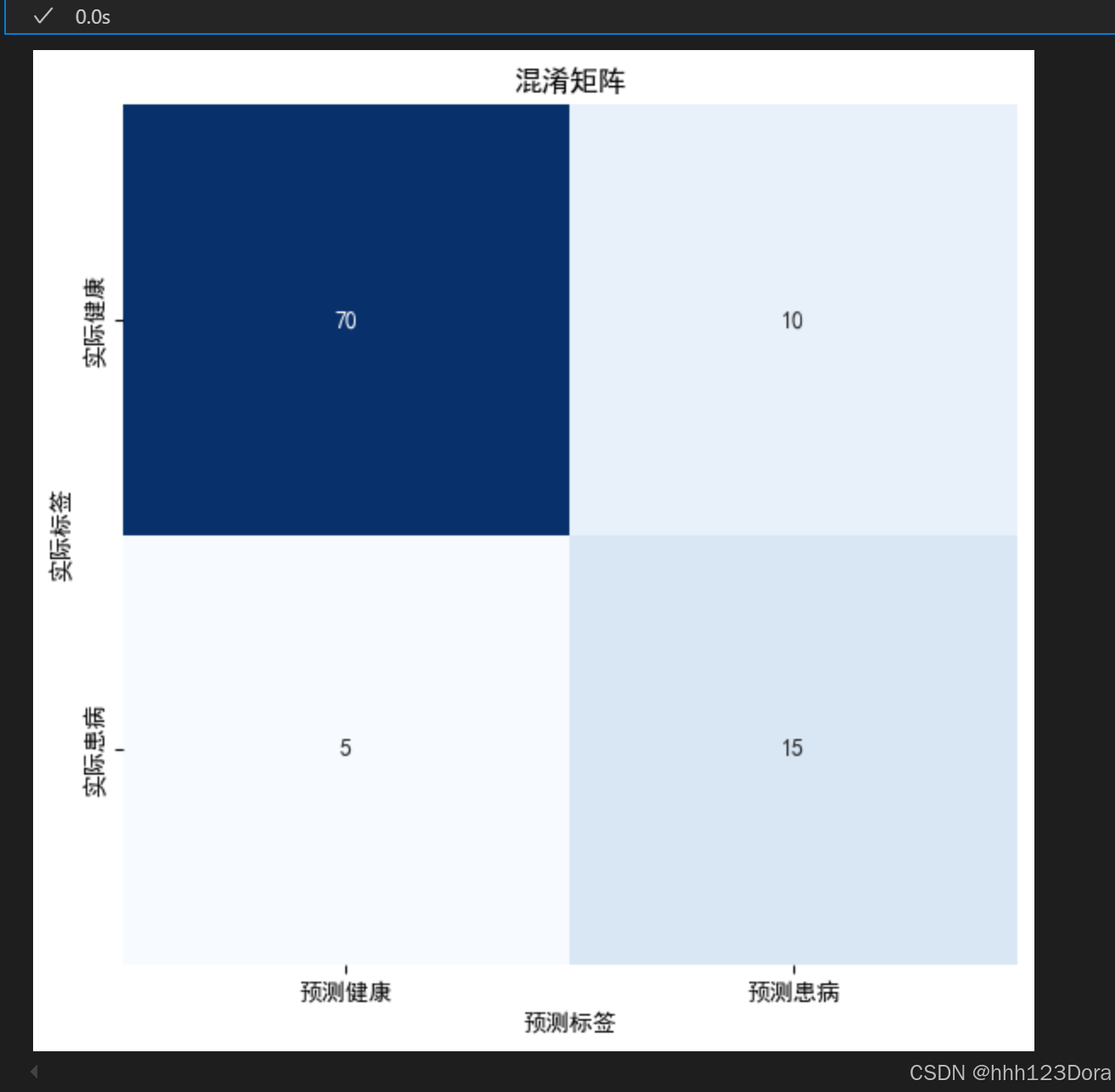
ROC曲线(Receiver Operating Characteristic Curve)是用于评估二分类模型性能的工具,特别适用于研究模型在不同阈值下的表现。它通过绘制真正例率(TPR)和假正例率(FPR)的关系图,直观展示模型的分类能力。
2.2 构成
-
横轴(X轴):假正例率(False Positive Rate, FPR),公式为:
FPR=FP/(FP+TN)表示实际为负类的样本中被错误预测为正类的比例。
-
纵轴(Y轴):真正例率(True Positive Rate, TPR,也称为召回率),公式为:
TPR=TP/(TP+FN)表示实际为正类的样本中被正确预测为正类的比例。
-
曲线:通过调整分类阈值(从0到1),计算不同阈值下的TPR和FPR,连接这些点形成ROC曲线。
2.3 作用
-
理想情况:曲线越靠近左上角,模型性能越好。理想情况下,TPR为1,FPR为0,表示模型完美分类。
-
随机猜测:对角线(从左下到右上的直线)表示模型的性能等同于随机猜测。
-
曲线下面积(AUC):ROC曲线下的面积(AUC, Area Under Curve)用于量化模型性能。AUC的取值范围是0到1:
-
AUC = 1:完美模型。
-
AUC = 0.5:随机猜测。
-
AUC > 0.5:模型优于随机猜测。
-
根据例子可以算出
-
TPR = 15 / (15 + 5) = 0.75,表明模型能够正确识别 75% 的实际患病者。
-
FPR = 10 / (10 + 70) = 0.125,表明模型将 12.5% 的实际健康者错误地预测为患病。
2.4 代码
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
import numpy as np
# 实际标签和预测概率
y_true = [1] * 20 + [0] * 80 # 1表示患病,0表示健康
y_scores = [0.9] * 15 + [0.4] * 5 + [0.6] * 10 + [0.1] * 70 # 模型的预测概率
# 计算 ROC 曲线的 FPR, TPR 和阈值
fpr, tpr, thresholds = roc_curve(y_true, y_scores)
# 计算 AUC 值
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='Random Guess')
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR)')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.show()运行结果如下
三、发生比(Odds Ratio)
发生比(Odds Ratio)是逻辑回归模型中用于解释特征对结果影响的重要指标。它表示某个特征增加一个单位时,结果发生的概率与不发生的概率之比。
3.1 简介
发生比是指某个事件发生的概率与不发生的概率之比。不同的模型使用不同的发生比计算公式,主要是因为它们的目标、假设和应用场景不同。理解这些差异有助于选择合适的模型进行数据分析和预测。

3.2 意义
-
发生比大于 1:事件发生的概率大于不发生的概率。
-
发生比等于 1:事件发生的概率等于不发生的概率。
-
发生比小于 1:事件发生的概率小于不发生的概率。
3.3 应用
-
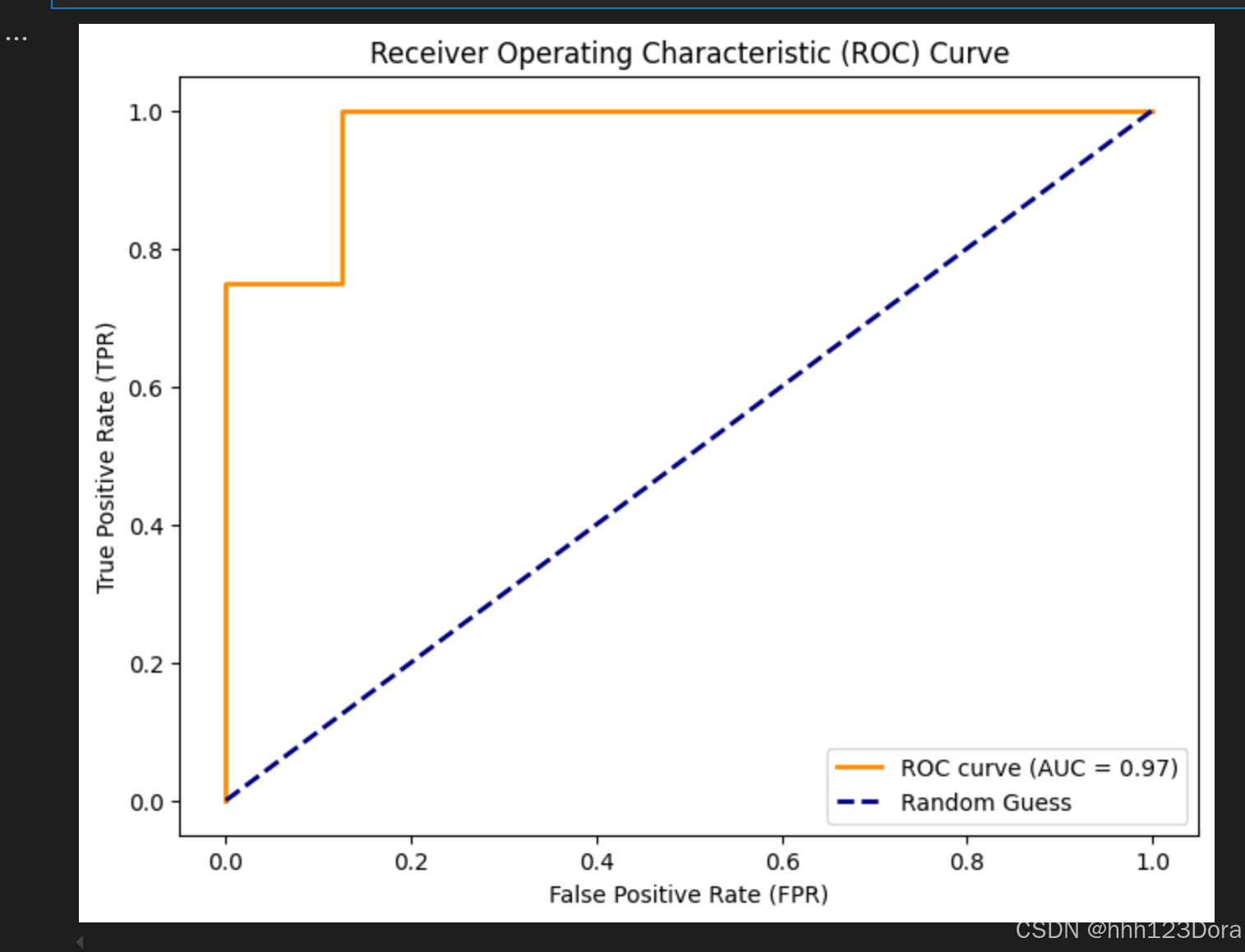
Logistic回归:用于二分类问题,目标是预测事件发生的概率。其发生比公式为:
Odds=P/(1−P)其中 P 是事件发生的概率。
应用场景:适用于预测二分类结果,如是否患病、是否购买等。
例子:
-
泊松回归:用于计数数据,目标是预测事件发生的次数。其发生比公式为:
Odds=λ其中 λ 是事件发生的平均次数。
应用场景:适用于预测计数数据,如某时间段内的事件发生次数。
例子:
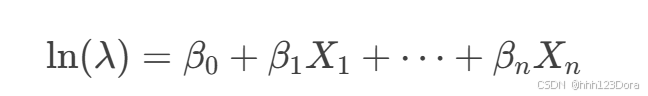
-
Cox比例风险模型:用于生存分析,目标是评估风险因素对生存时间的影响。其发生比公式为:
Hazard Ratio=h1(t)/h0(t)其中 h1(t) 和 h0(t) 分别是暴露组和对照组的风险函数。

应用场景:适用于生存分析,如评估某种治疗对患者生存时间的影响。
本文所举的例子就是:

3.4 代码
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 设置支持中文的字体
font_path = r"d:\Users\z3322\Desktop\simhei.ttf" # 替换为你的字体文件路径
font_prop = fm.FontProperties(fname=font_path)
plt.rcParams['font.sans-serif'] = [font_prop.get_name()]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 混淆矩阵数据
TP = 15 # 真正例
FN = 5 # 假反例
FP = 10 # 假正例
TN = 70 # 真反例
# 计算发生比
odds_ratio = (TP / FN) / (FP / TN)
# 数据
labels = ['患病组 (TP/FN)', '健康组 (FP/TN)']
values = [TP / FN, FP / TN]
# 绘制条形图
plt.figure(figsize=(6, 4))
plt.bar(labels, values, color=['blue', 'orange'])
plt.ylabel('暴露比')
plt.title('发生比 (Odds Ratio) 可视化')
plt.text(0, TP / FN + 0.1, f'{TP/FN:.2f}', ha='center')
plt.text(1, FP / TN + 0.1, f'{FP/TN:.2f}', ha='center')
plt.show()
# 显示发生比
print(f"发生比 (Odds Ratio) = {odds_ratio:.2f}")运行结果如下
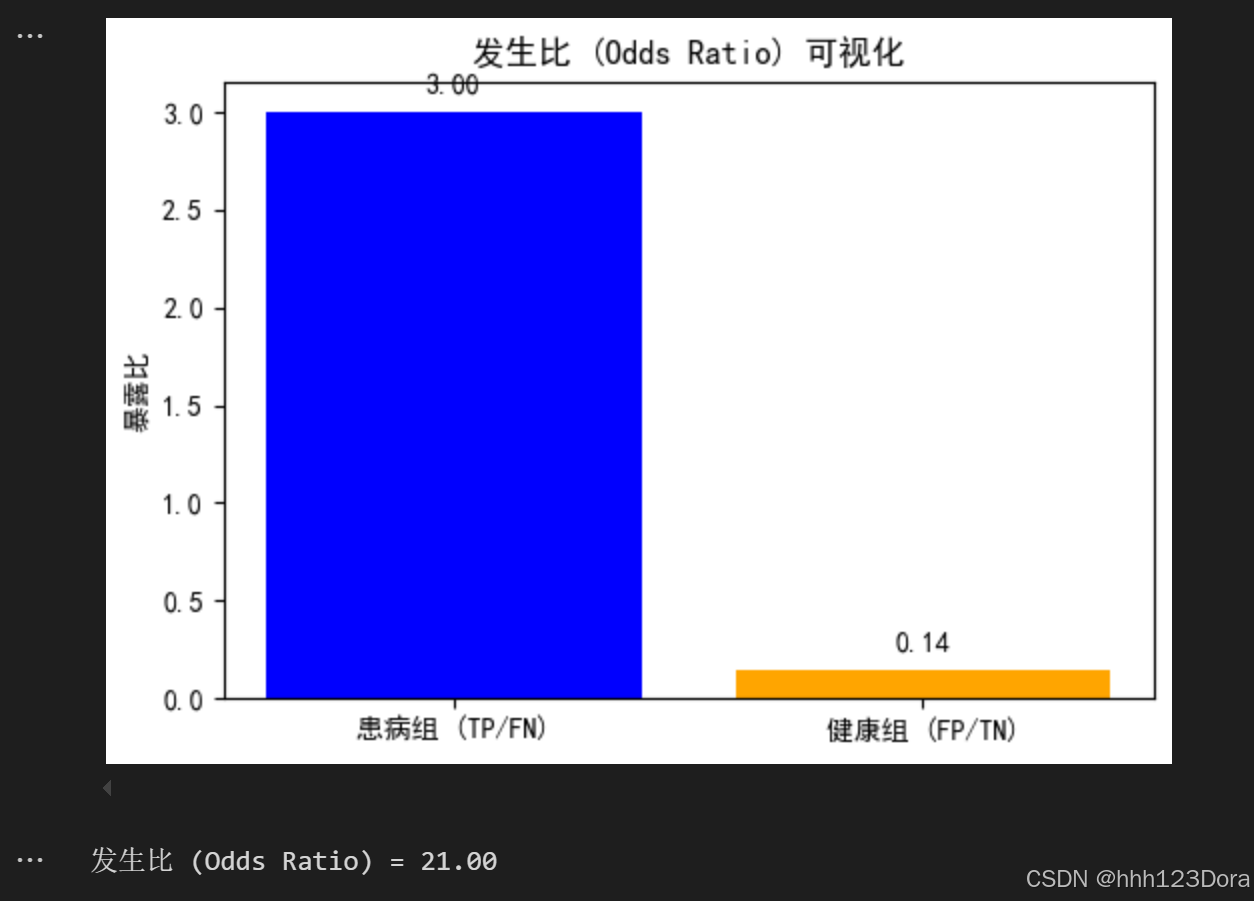
发生比为 21,表示患病组的暴露比是健康组的 21 倍。

















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









