







1 文本数据分析
文本数据分析作用
- 文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 指导模型训练过程中一些超参数的选择
- 比如:关于标签Y:分类问题查看标签是否均匀;关于数据X:数据有没有脏数据 数据长度分布等等
常用的几种文本数据分析方法:
- 标签数量分析
- 句子长度分布
- 词频统计与关键词词云
1.1 数据集说明
- 基于中文酒店评论语料讲解常用的几种文本数据分析方法
- 属于二分类的中文情感分析语料
- 其中train.tsv代表训练集, dev.tsv代表验证集, 二者数据样式相同

- train.tsv中的数据内容共分为两列
- 第一列数据代表具有感情色彩的评论文本
- 第二列数据,0或1,代表每条文本数据是积极或者是消极的评论,0表示消极,1表示积极
1.2 标签数量分布
思路分析 : 获取标签数量分布
- 什么标签数量分布:求标签0有多少个 标签1有多少个 标签2有多少个
- 设置显示风格
plt.style.use(‘fivethirtyeight’)
- 读训练集 验证集数据
pd.read_csv(path, sep=‘\t’)
- 统计label标签的0、1分组数量
sns.countplot(data,x=‘label’)
- 画图展示
plt.title() plt.show()
注意1:sns.countplot()相当于select * from tab1 group by
data表示数据来源 x='label’表示按照这个字段进行分组
def dm01_label_sns_countplot():
# 1 设置显示风格plt.style.use('fivethirtyeight')
plt.style.use('fivethirtyeight')
# 2 读训练集 验证集数据 pd.read_csv(path, sep='\t')
# data表示数据来源 x='label'表示按照这个字段进行分组
train_df = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t')
dev_df = pd.read_csv(filepath_or_buffer='./cn_data/dev.tsv', sep='\t')
# 3 统计label标签的0、1分组数量 sns.countplot()
# data - 指定数据
# x - 指定按照哪一组的指进行绘制图像
sns.countplot(x ='label', data=train_df)
# 4 画图展示 plt.title() plt.show()
plt.title('train')
plt.show()
# 5 验证集
sns.countplot(x='label', data=dev_df)
plt.title('dev')
plt.show()
pass
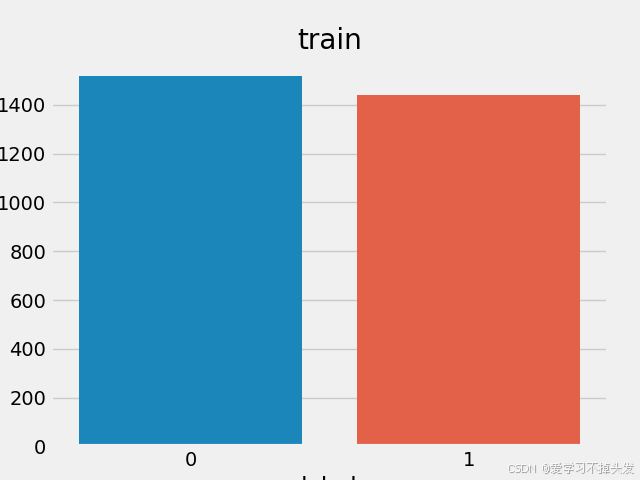
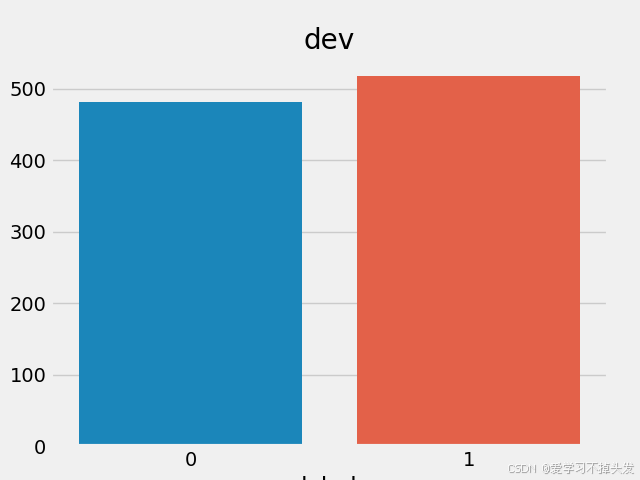
- 训练深度学习模型比如分类问题,一般需要将正负样本比例维持在1:1左右
- 不符合1:1比例,需进行数据增强或删减。上图中训练和验证集正负样本都稍有不均衡, 可进行数据比例调整
1.3 数据长度分布
思路分析 : 获取句子长度分布 -绘制句子长度分布-柱状图 句子长度分布-密度曲线图
- 什么是句子长度分布:求长度为50的有多少个 长度51的有多少个 长度为52的有多少个
- 设置显示风格plt.style.use(‘fivethirtyeight’)
- 读训练集train_data / pd.read_csv(path, sep=‘\t’)
- 新增数据长度列:train_data[‘sentence_length’] = list(map(lambda x:len(x) , …))
- 4-1 绘制数据长度分布图-柱状图
sns.countplot(x=‘sentence_length’, data=train_data)
画图展示
plt.xticks([]) plt.show()
- 4-2 绘制数据长度分布图-曲线图
sns.displot(x=‘sentence_length’, data=train_data)
画图展示 plt.yticks([]) plt.show()
def dm02_len_sns_countplot_distplot():
# 1 设置显示风格plt.style.use('fivethirtyeight')
plt.style.use('fivethirtyeight')
# 2 读训练集 验证集数据 pd.read_csv(path, sep='\t')
# data表示数据来源 x='label'表示按照这个字段进行分组
train_df = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t')
dev_df = pd.read_csv(filepath_or_buffer='./cn_data/dev.tsv', sep='\t')
# 3 新增数据长度列:train_data['sentence_length'] = list(map(lambda x:len(x) , ...))
# 直接调用map函数,将series中的每个值应用函数,然后获取到对应的文本长度,然后转为列表,增加新得列
train_df['sentence_length'] = list(map(lambda x:len(x), train_df['sentence']))
# 4-1 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=train_data)
# 画图展示 plt.xticks([]) plt.show()
sns.countplot(x='sentence_length', data=train_df)
plt.xticks([])
plt.show()
# 4-2 绘制数据长度分布图- 绘制直方图
# sns.displot(x='sentence_length', data=train_data)
sns.displot(x='sentence_length', data=train_df)
plt.yticks([])
plt.show()
pass
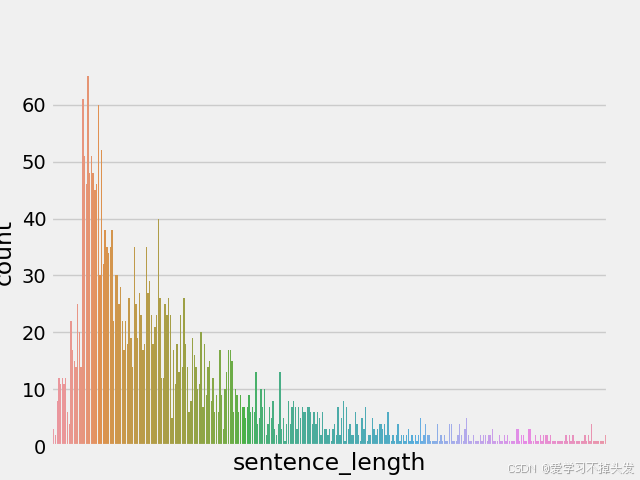
- count_plot - 绘制句子长度的柱状图
- displot-绘制
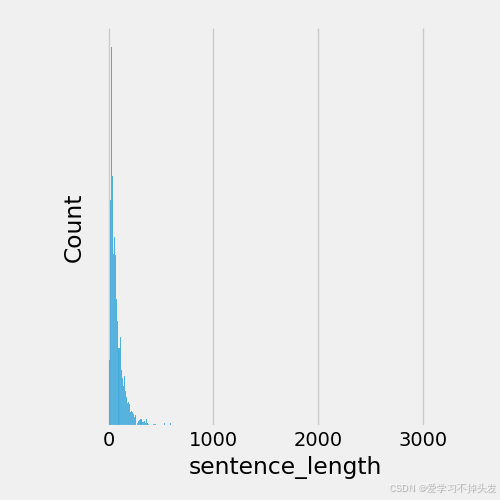
- 从训练集和验证集句子长度分布图来看:长度范围大部分处于20~250之间
- 若模型对输入的数据长度有要求,可以对句子进行截断或补齐操作;(规范长度)起到关键的指导作用,一般选择句子长度可以设置为可以覆盖90%语料的句子长度。
1.4 获取正负样本长度的散点图
概念:按照x正负样本进行分组 再按照y长度进行散点图
def dm03_sns_stripplot():
# 1 设置显示风格plt.style.use('fivethirtyeight')
plt.style.use('fivethirtyeight')
# 2 读训练集 验证集数据 pd.read_csv(path, sep='\t')
# data表示数据来源 x='label'表示按照这个字段进行分组
train_df = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t')
# 3 新增数据长度列:train_data['sentence_length'] = list(map(lambda x:len(x) , ...))
train_df['sentence_length'] = list(map(lambda x: len(x), train_df['sentence']))
# 4 画散点图
# x轴 - 用label标签列的值进行分组
# y轴 - 用sentence_length
sns.stripplot(y='sentence_length', x='label', data=train_df )
plt.show()
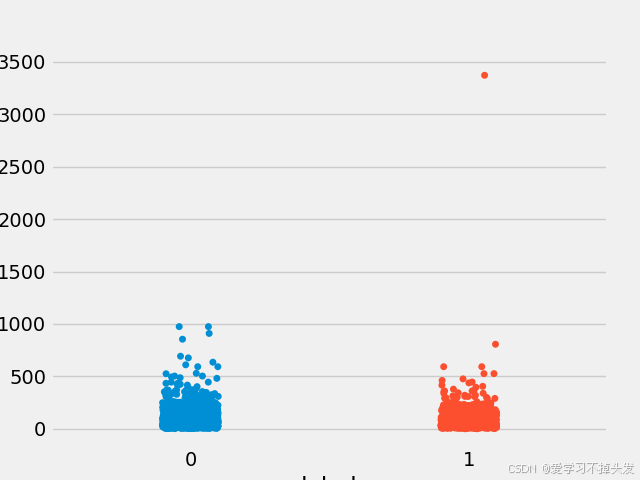
- 通过查看正负样本长度散点图, 可有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查
- 上图中在训练集正样本中出现了异常点, 它的句子长度近3500左右, 需要我们人工审查
1.5 获取训练集和测试集词汇总数
- 获取不同数据集词汇总数统计 train_vocab
1 pd.read_csv 读训练集 验证集数据
2 train_vocab / set (chain( * map(lambda x:jieba.lcut(x), train_data[‘sentence’] ) ) )
- map(lambda x : jieba.lcut(x),train_df[“sentence”]) - 获取到每个句子的列表,保存到map中
- *map() - 解包,获取到map中所有的列表 [list_1] [list_2] …
chain(*map()) - 将所有列表值取出,组成chain对象
set(chain(*map())) - 将chain转换为set,并进行去重
def dm04_cal_wordcount():
# 1 读训练集
train_df = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t')
dev_df = pd.read_csv(filepath_or_buffer="./cn_data/dev.tsv",sep="\t")
# 2 求单词个数
# chain进行扁平化列表
# 训练集的句子进行分词,并统计出不同的词汇的总数
# 返回map对象
# print(map(lambda x:jieba.lcut(x),train_df['sentence']))
# 取出map中的数据,其中是每个句子对应的分词列表
# print(*map(lambda x:jieba.lcut(x),train_df['sentence']))
# 用chain函数之后,得到一个chain对象
# print(chain(*map(lambda x:jieba.lcut(x),train_df['sentence'])))
# 将chain对象转换为列表,chain的作用是将list进行拼接
# print(list(chain(*map(lambda x:jieba.lcut(x),train_df['sentence']))))
train_vocab = set( chain( *map(lambda x:jieba.lcut(x), train_df['sentence']) ) )
dev_vocab = set(chain(*map(lambda x:jieba.lcut(x),dev_df["sentence"])))
print('训练集单词总数', len(train_vocab))
print('训练集单词总数', len(dev_vocab))

1.6 获取训练集上正负样本的高频形容其词云
-
词云作用:根据高频形容词词云显示,对语料质量评估,对违反语料标签含义的词汇进行人工审查和修正,来保大多数语料符合训练标准。
-
借助wordcloud实现词云的绘制
- 导入词云模型
from wordcloud import WordCloud- 示例化词云对象
font_path:指定字体路径、max_words:指定显示的词云的数量
、background_color:设置背景颜色
wordcloud = WordCloud(font_path=“./data/SimHei.ttf”,max_font_size=100,background_color=‘white’)- 生成词云,传入词汇组成字符串,中间用空格分隔,“a1 a2 a3 …”
wordcloud.generate(keywords_string)- 绘图
plt.figure()
plt.imshow(wordcloud,interpolation=“bilinear”)
plt.axis(“off”)
plt.show()
完整代码
# 导入必备工具包
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from itertools import chain
import jieba
import jieba.posseg as pseg
from wordcloud import WordCloud
# 传入一个句子,获取到句子中的形容词列表
# 根据posseg进行分词,得到词性分词
# 词性为a的放到列表中
def get_a_list(s):
r = [] # 保存形容词
for g in pseg.lcut(s): # 分词并标注词性
if g.flag == 'a': # 获取词性等于a的词,加入到列表中返回
r.append(g.word)
return r
def get_word_cloud(keywords_list):
# 实例化词云对象
# font_path:指定字体路径
# max_words:指定显示的词云的数量
# background_color:设置背景颜色
wordcloud = WordCloud(font_path="./data/SimHei.ttf",max_font_size=100,background_color='white')
# 将传入的列表转化为字符串形式,因为词云对象的参数要求是字符串类型
keywords_string = " ".join(keywords_list)
# 生成词云
wordcloud.generate(keywords_string)
# 绘图
plt.figure()
plt.imshow(wordcloud,interpolation="bilinear")
plt.axis("off")
plt.show()
def dm05_get_word_cloud():
train_df = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t')
# 1.先获取训练集上的正样本
p_train_data = train_df[train_df['label'] == 1]['sentence']
# 对正样本的每个句子提取形容词
train_p_a_vocab = chain(*map(lambda x:get_a_list(x),p_train_data))
# 获取负样本形容词
n_train_data = train_df[train_df['label'] == 0]['sentence']
train_n_a_vocab = chain(*map(lambda x: get_a_list(x), n_train_data))
# 调用获取词云的函数
get_word_cloud(train_p_a_vocab)
get_word_cloud(train_n_a_vocab)
- 训练集正例词云

- 训练集负例词云

- 测试集正例词云

- 测试集负例词云

- 根据高频形容词词云显示,对当前语料质量进行简单评估,同时对违反语料标签含义的词汇进行人工审查和修正,来保证绝大多数语料符合训练标准。
- 上图中的正样本大多数是褒义词,而负样本大多数是贬义词,基本符合要求,但是负样本词云中也存在“豪华”这样的褒义词,因此可人工进行审查。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









