







1 K近邻算法原理
KNN(K-Nearest Neighbor)是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻近值来代表。算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。可以通俗的理解为“物以类聚人以群分和近朱者赤近墨者黑”。
1.1 KNN算法示例

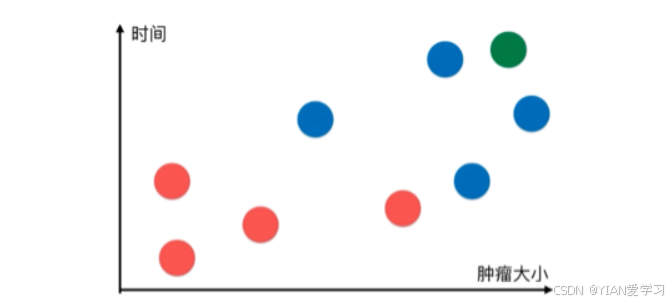
上图中每一个数据点代表一个肿瘤病历:
- 横轴表示肿瘤大小,纵轴表示发现时间
- 恶性肿瘤用蓝色表示,良性肿瘤用红色表示
疑问:新来了一个病人(下图绿色的点),如何判断新来的病人(即绿色点)是良性肿瘤还是恶性肿瘤?
解决方法:k-近邻算法的做法如下:
(1)取一个值k=3(k值后面介绍,现在可以理解为算法的使用者根据经验取的最优值)
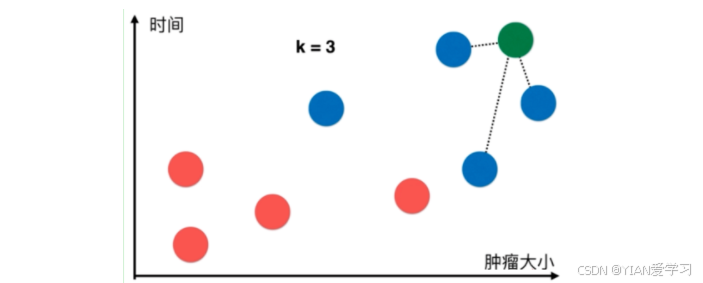
(2)在所有的点中找到距离绿色点最近的三个点
(3)让最近的点所属的类别进行投票
(4)最近的三个点都是蓝色的,所以该病人对应的应该也是蓝色,即恶性肿瘤。
总结:
K-近邻算法属于哪类算法?可以用来解决监督学习中的分类问题和回归问题
算法的思想:通过K个最近的已知分类的样本来判断未知样本的类别
1.2 KNN算法原理
KNN算法描述
输入:训练数据集T = {(x1,y1),(x2,y2),(x356/,y3)…(xn,yn),},xi为实例的特征向量,yi={C1,c2…Ck}为实例类别。
输出:实例x所属的类别y
步骤:
(1)选择参数K
(2)计算未知实例与所有已知实例的距离(多种方式计算距离)
(3)选择最近K个已知实例
(4)根据少数服从多数的原则进行投票,让未知实例归类为K个最近邻中最多数的类别。
总结:KNN算法没有明显的特征训练过程,它的训练阶段仅仅将样本保存起来,训练开销为0,等到收到测试样本后在进行处理(如K值取值和距离计算)。因此,对应于训练阶段的学习该算法是一种懒惰学习(lazy learning)。
KNN三要素:
- 距离度量
- K值选择
- 分类决策准则
1.3 KNN算法实例
预测《唐人街探案》的分类
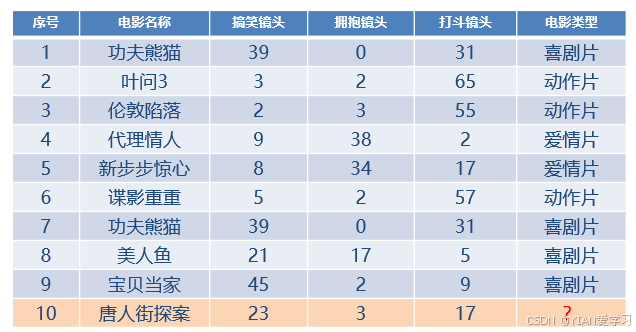
- 求解当前样本到其他样本之间的距离,将样本的特征抽象为一个多维空间中的点
- 将距离进行排序,取距离最近的前K个。K是人工设置的参数,所以K是一个超参数。
- 对K个最近的样本的种类进行统计,统计之后大部分属于哪个种类,当前样本就属于哪一个种类
1.4 分类任务和回归任务流程
1.4.1 分类流程
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小进行排序
- 取出距离最近的K个训练样本
- 进行多数表决,统计K个样本中哪个类别的样本数量最多
- 将未知样本归属到出现次数最多的类别
1.5.1 回归流程
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小进行排序
- 取出距离最近的K个训练样本
- 将K个样本的目标值计算其平均值
- 作为将未知的样本的值
2 距离的度量方法
2.1 机器学习中为什么要度量距离?
机器学习算法中,经常需要 判断两个样本之间是否相似 ,比如KNN,K-means,推荐算法中的协同过滤等等,常用的套路是 将相似的判断转换成距离的计算 ,距离近的样本相似程度高,距离远的相似程度低。所以度量距离是很多算法中的关键步骤。
KNN算法中要求数据的所有特征都用数值表示。若在数据特征中存在非数值类型,必须采用手段将其进行量化为数值。
- 比如样本特征中包含有颜色(红、绿、蓝)一项,颜色之间没有距离可言,可通过将颜色转化为 灰度值来实现距离计算 。
- 每个特征都用数值表示,样本之间就可以计算出彼此的距离来
接下来介绍几种距离度量方法
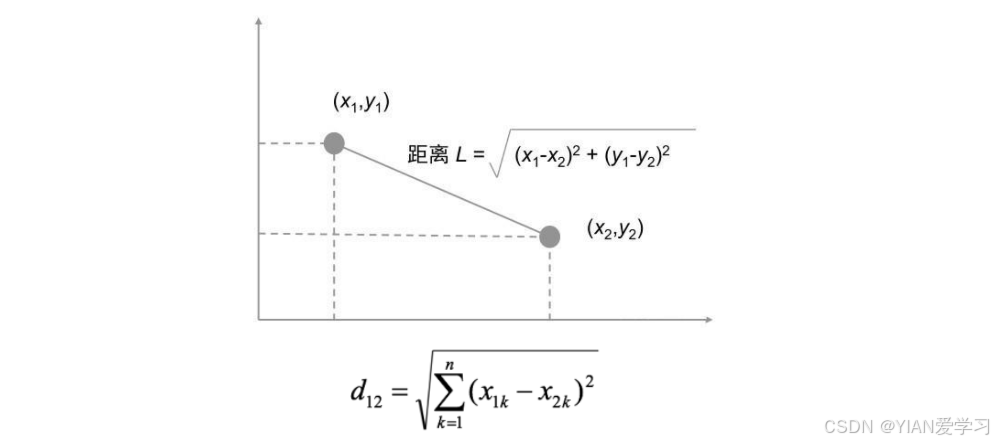
2.2 欧式距离
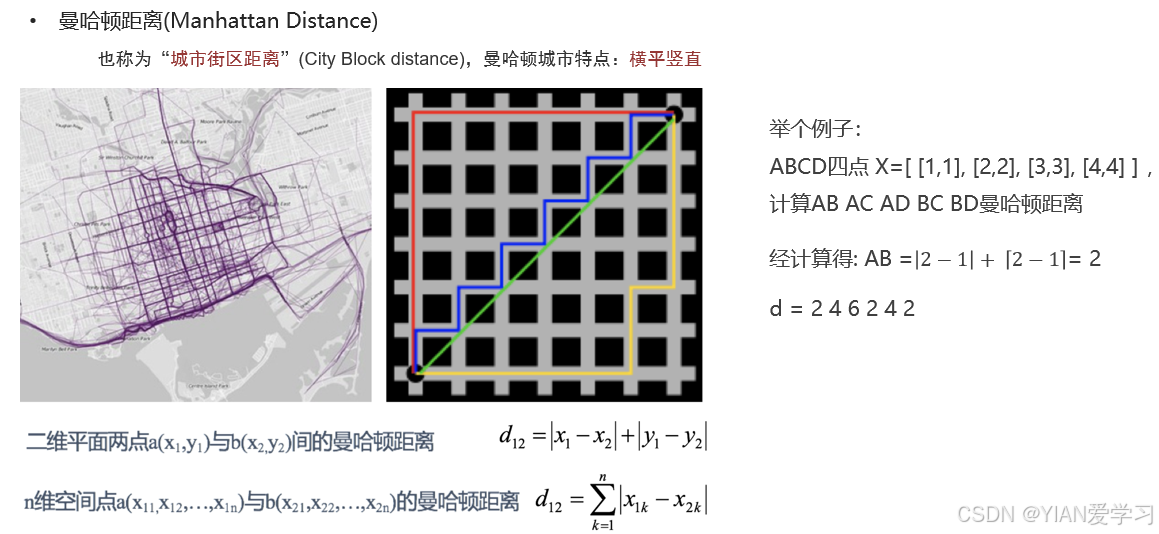
2.3 曼哈顿距离
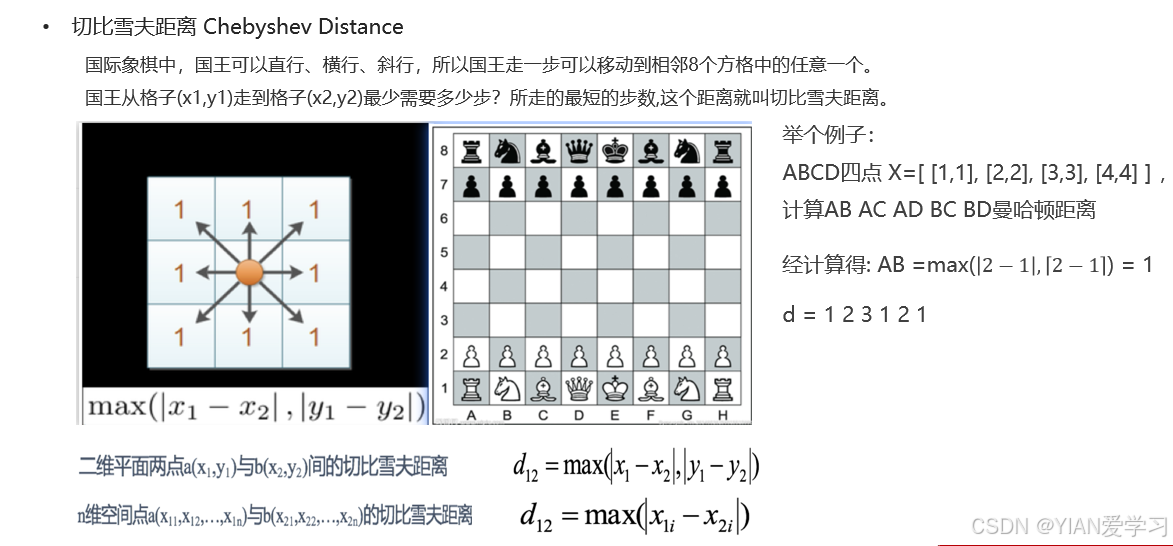
2.4 切比雪夫距离(了解)
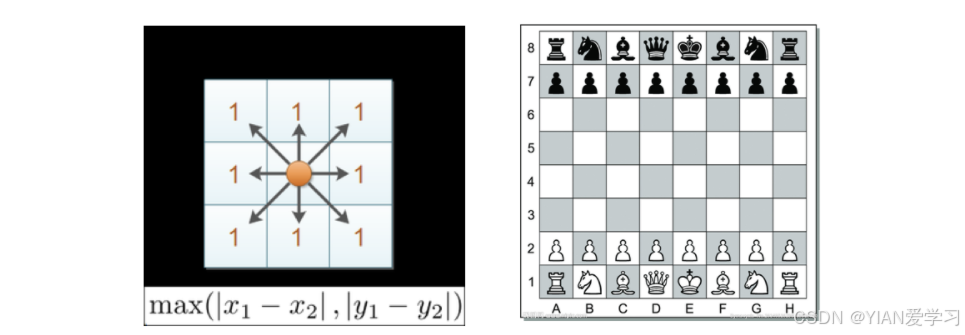
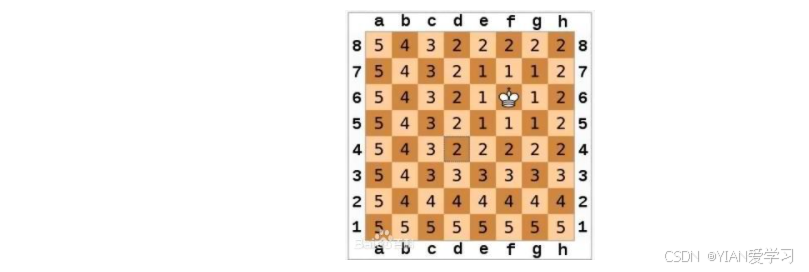
国际象棋棋盘上二个位置间的切比雪夫距离是指王要从一个位置移至另一个位置需要走的步数。(王可以往斜前或斜后方向移动一格)
2.5 闵式距离
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
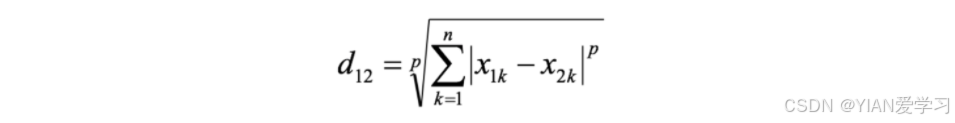
其中p是一个变参数:
- 当 p=1 时,就是曼哈顿距离;
- 当 p=2 时,就是欧氏距离;
- 当 p→∞ 时,就是切比雪夫距离。
根据 p 的不同,闵氏距离可以表示某一类/种的距离。
2.6 小结
- 欧式距离、曼哈顿距离、切比雪夫距离是最常用的距离
- 闵式距离是一组距离的度量,当 p = 1 时代表曼哈顿距离,当 p = 2 时代表欧式距离,当 p = ∞ 时代表切比雪夫距离
3 归一化和标准化(特征预处理)
3.1 为什么做归一化和标准化
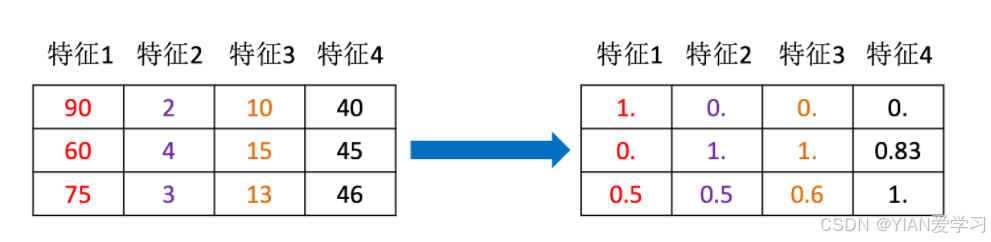
样本中有多个特征,每一个特征都有自己的定义域和取值范围,他们对距离计算也是不同的,如取值较大的影响力会盖过取值较小的参数。因此,为了公平,样本参数必须做一些归一化处理,将不同的特征都缩放到相同的区间或者分布内。
特征的单位或大小相差较大,或者某特征的方差相比其他特征的要大出几个数量级,容易影响(支配)目标结果,使得一些模型(算法)无法学习到其他的特征。
示例:
如果不进行特征处理,在使用KNN算法进行计算距离的时候,体重的数量级较高,对于计算的影响较大;为了让所有特征对于计算结果的贡献一样,需要进行数据处理。
3.2 归一化
通过对原始数据进行变换,把数据映射到mi,mx之间。
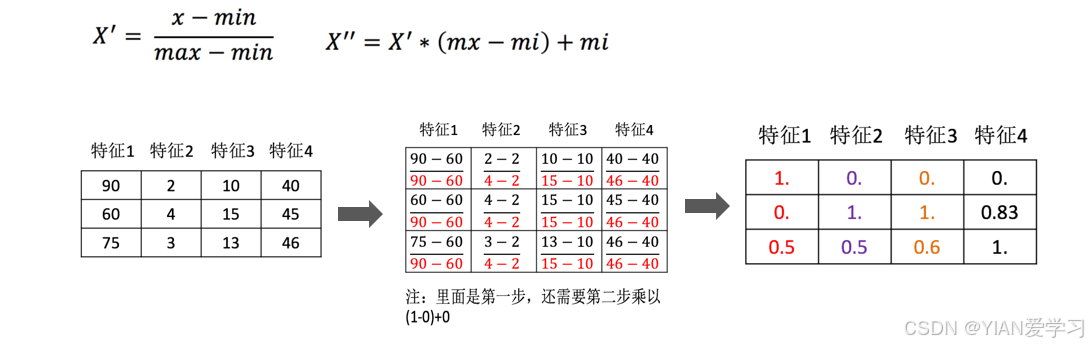
- 归一化收到异常值的影响,比如,如果年龄有一个异常值为200,归一化的时候,最大值需要使用200,结果不准确
- 归一化不适合大规模数据
- 图片的像素取值在0-255之间,适合使用归一化
3.3 scikit-learn 中实现归一化的 API:
from sklearn.preprocessing import MinMaxScaler
def test():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
# data - 特征数据传入之后,transformer对象会学习到data中的最大最小值
# 然后利用最大最小值进行归一化
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响, 鲁棒性较差,适合传统精确小数据场景
3.4 标准化
数据标准化:通过对原始数据进行标准化,转换为均值为0,标准差为1的正态分布的数据
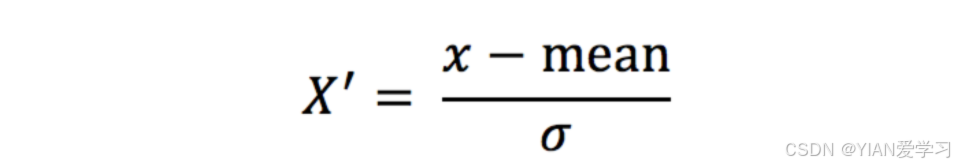
- mean 为特征的平均值
- σ 为特征的标准差
- 自然界中的数据分布很多都符合正态分布
- 绝大多数数据都集中在3σ之间
3.5 scikit-learn 中实现标准化的 API:
from sklearn.preprocessing import StandardScaler
def test():
# 1. 准备数据
# 特征进行归一化
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化标准化对象
transformer = StandardScaler()
# 3. 对原始特征进行变换
# 学习到数据中的均值和标准差
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大
3.6 小结
- 归一化和标准化都能够将量纲不同的数据集缩放到相同范围内
- 归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响, 鲁棒性较差,适合传统精确小数据场景
- 对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,鲁棒性更好
4 K近邻算法API
4.1 分类问题API
# 1.导入工具包
from sklearn.neighbors import KNeighborsClassifier
# 2.创建数据集
# 5个样本,每个样本有三个特征值,样本输入是一个二维数组,每一个一维都表示一个样本的特征向量
# 5个样本有5个标签,2个分类,y表示标签向量
x = [[0,2,3],[1,3,4],[3,5,6],[4,7,8],[2,3,4]]
y = [0,0,1,1,0]
# 3.实例化模型
# 二分类,n_neighbors不指定偶数,这里设置为3
model = KNeighborsClassifier(n_neighbors=3)
# 4.训练模型
model.fit(x,y)
# 5.预测模型
# 输入的是一个样本,二维数组
print(model.predict([[5,6,7]])) # 预测结果 [1]
4.2 回归问题API
# 1.导入工具包
from sklearn.neighbors import KNeighborsRegressor
# 2. 准备数据
# 回归数据,标签值是连续的,y向量的值是连续的
# 有多少个样本就有多少个标签值
x = [[0,0,1],[1,1,0],[3,10,10],[4,11,12],[2,3,4]]
y = [0.1,0.2,0.3,0.4,0.5]
# 3. model实例化
estimator = KNeighborsRegressor(n_neighbors=3)
# 4. 进行模型训练
estimator.fit(x,y)
# 5. 进行目标值预测
# 预测的时候,传入的样本的特征数和训练样本的特征数一致
# print(estimator.predict([[1,2,4]]))
print(estimator.predict([[1,2,4],[3,5,6]])) # [0.3 0.3] , 采用最近的三个值的平局值作为预测值
5 K值选择问题(网格搜索与交叉验证)
5.1 K取不同值时带来的影响
举例:
- 有两类不同的样本数据,分别用蓝颜色的小正方形和红色的小三角形表示,而图正中间有一个绿色的待判样本。
-
问题:如何给这个绿色的圆分类?是判断为蓝色的小正方形还是红色的小三角形?
-
方法:应用KNN找绿色的邻居,但一次性看多少个邻居呢(K取几合适)?
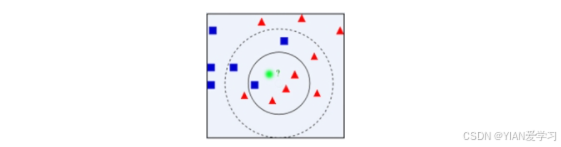
解决方案:
-
K=4,绿色圆圈最近的4个邻居,3红色和1个蓝,按少数服从多数,判定绿色样本与红色三角形属于同一类别
-
K=9,绿色圆圈最近的9个邻居,6红和3个蓝,判定绿色属于红色的三角形一类。
有时候出现K值选择困难的问题
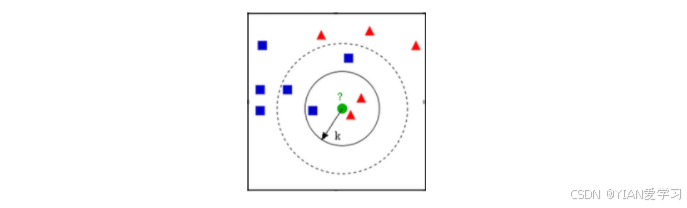
KNN算法的关键是什么?
答案一定是K值的选择,下图中K=3,属于红色三角形,K=5属于蓝色的正方形。这个时候就是K选择困难的时候。
5.2 如何确定合适的K值
K值过小(用较小邻域中的训练实例进行预测):
- 容易受到异常点的影响
- K值减小就意味着模型变得复杂,容易发生过拟合
k值过大(用较大邻域中得训练实例进行预测):
-
受到样本均衡的问题
-
且K值得增大就意味着整体模型变得简单,容易发生欠拟合
-
K=N(N为训练样本个数):结果只取决于数据集中不同类别数量占比,得到的结果一定是占比高的类别,此时模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K一般取一个较小的数值。
目标值有两个类别,K值不要取偶数, 如果目标值有三个类别,K不要取3的倍数。
我们可以采用交叉验证法(把训练数据再分成:训练集和验证集)来选择最优的K值。
5.3 GridSearchCV 的用法
使用 scikit-learn 提供的 GridSearchCV 工具, 配合交叉验证法可以搜索参数组合.
# 1. 加载数据集
x, y = load_iris(return_X_y=True)
# 2. 分割数据集
x_train, x_test, y_train, y_test = \
train_test_split(x, y, test_size=0.2, stratify=y, random_state=0)
# 3. 创建网格搜索对象
estimator = KNeighborsClassifier()
param_grid = {'n_neighbors': [1, 3, 5, 7]}
"""
GridSearchCV(模型,param_grid=超参数字典,cv=交叉验证次数)
返回一个最优参数组合的模型
"""
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5, verbose=0)
estimator.fit(x_train, y_train)
# 4. 打印最优参数
# 模型.best_params_ 得到模型的最优参数
# 模型.best_score_ 得到模型的最优得分
print('最优参数组合:', estimator.best_params_, '最好得分:', estimator.best_score_)
# 4. 测试集评估模型
print('测试集准确率:', estimator.score(x_test, y_test))
5.4 KNN案例 - 鸢尾花分类
# 1. 导入包
# 进行数据可视化的包
import seaborn as sns
import matplotlib.pyplot as plt
# 导入pandas
import pandas as pd
#导入sklearn自带的数据包
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 2. 加载数据集
# load_iris()返回一个字典,其中包含了数据集中的信息
my_data_set = load_iris()
# 转换为dataframe
iris_data = pd.DataFrame(my_data_set['data'],columns=my_data_set.feature_names)
# 添加标签列
iris_data['Species'] = my_data_set.target
"""
sepal length (cm) sepal width (cm) ... petal width (cm) Species
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
"""
# 选择两列标签
col1 = 'sepal width (cm)'
col2 = 'petal width (cm)'
# 2.1 进行数据可视化
# 通过数据可视化进行特征选择
sns.lmplot(x=col1,y=col2,data=iris_data,hue='Species',fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('iris')
plt.show()
# 2.2 进行数据集和训练集的划分
# 调用方法,传入特征数据和标签数据
x_train,x_test,y_train,y_test = train_test_split(my_data_set.data,my_data_set.target,test_size=0.3,random_state=22)
# print(len(my_data_set.data))
# print(len(x_train))
# print(len(x_test))
# print(len(y_train))
# 2.3 进行数据标准化
# 创建标准化对象
transfer = StandardScaler()
# 调用标准化对象的fit_transfer方法进行数据标准化
# 根据数据学习到平均值和方差
# 测试集进行标准化的时候,直接使用训练集训练好的模型,进行标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 2.4 模型训练
# 创建KNN分类对象
estimator = KNeighborsClassifier(n_neighbors=3)
# 训练模型
estimator.fit(x_train,y_train)
# 2.5 模型评估
# 方式1 通过准确率,查看测试集中预测正确的个数,返回准确率
acc = estimator.score(x_test,y_test)
print(acc)
# 方式2 利用sklearn.metrics包中的 accuracy_score 方法
y_predict = estimator.predict(x_test)
my_result = accuracy_score(y_test, y_predict)
print('my_result-->', my_result)
# 2.6 模型预测
print('通过模型查看分类类别-->', estimator.classes_)
# 准备待预测数据
mydata = [[5.1, 3.5, 1.4, 0.2],[4.6, 3.1, 1.5, 0.2]]
# 进行预测数据的标准化
# 直接使用训练集的模型
mydata = transfer.transform(mydata)
print('mydata-->', mydata)
# 进行预测
mypred = estimator.predict(mydata)
print('mypred-->\n', mypred)
# 返回每个每个样本是每个类别的预测可能性
mypred = estimator.predict_proba(mydata)
print('mypred-->\n', mypred)
6 分类模型评估方法
6.1 数据集划分
6.1.1 为什么要划分数据集?
思考:我们有以下场景:
-
将所有的数据都作为训练数据,训练出一个模型直接上线预测
-
每当得到一个新的数据,则计算新数据到训练数据的距离,预测得到新数据的类别
存在问题:
-
上线之前,如何评估模型的好坏?
-
模型使用所有数据训练,使用哪些数据来进行模型评估?
结论:不能将所有数据集全部用于训练
为了能够评估模型的泛化能力,可以通过实验测试对学习器的泛化能力进行评估,进而做出选择。因此需要使用一个 “测试集” 来测试学习器对新样本的判别能力,以测试集上的 “测试误差” 作为泛化误差的近似。
一般测试集满足:
- 能代表整个数据集(测试集中数据分布与训练集中数据(分类)一致)
- 测试集与训练集互斥
- 测试集与训练集建议比例: 2比8、3比7 等
6.1.2 数据集划分的方法
留出法:将数据集划分成两个互斥的集合:训练集,测试集
- 训练集用于模型训练
- 测试集用于模型验证
- 也称之为简单交叉验证
交叉验证:将数据集划分为训练集,验证集,测试集。
交叉验证是一种数据集的分割方法,将训练集划分为n份,拿其中的一份做为验证集,剩余n-1份作为训练集,n取几就为几折交叉验证
- 训练集用于模型训练
- 验证集用于参数调整
- 测试集用于模型验证
留一法:每次从训练数据中抽取一条数据作为测试集
自助法:以自助采样(可重复采样、有放回采样)为基础
- 在数据集D中随机抽取m个样本作为训练集
- 没被随机抽取到的D-m条数据作为测试集
6.1.3 留出法(简单交叉验证)
留出法 (hold-out) 将数据集 D 划分为两个互斥的集合,其中一个集合作为训练集 S,另一个作为测试集 T。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import ShuffleSplit
from collections import Counter
from sklearn.datasets import load_iris
def test01():
# 1. 加载数据集
x, y = load_iris(return_X_y=True)
print('原始类别比例:', Counter(y))
# 2. 留出法(随机分割)
# 每个类别的计数,类似于pandas中的value_counts(),Counter()是对于标签进行计数
# test_size - 用于指定测试集的比例
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
print('随机类别分割:', Counter(y_train), Counter(y_test))
# 3. 留出法(分层分割)
# stratify = y 保证训练集和测试集中的类别的比例一致
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)
print('分层类别分割:', Counter(y_train), Counter(y_test))
def test02():
# 1. 加载数据集
x, y = load_iris(return_X_y=True)
print('原始类别比例:', Counter(y))
print('*' * 40)
# 2. 多次划分(随机分割)
# 将训练集划分为5份,每一份数据中训练集和测试集的比例都是0.8:0.2
# 在进行划分之前,会先对原始数据集进行乱序,产生一个伪随机数
# random_state - 指定随机数种子
spliter = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
# ShuffleSplit返回一个数据分割对象
# spliter.split(x,y) - 返回x,y划分之后的生成器
for train, test in spliter.split(x, y):
# train - 每一份数据中训练集的索引值
# test - 每一份数据中测试集的索引值
print('随机多次分割:', Counter(y[test]))
print('*' * 40)
# 3. 多次划分(分层分割)
# 将训练集划分为5份,每一份数据中训练集和测试集的比例都是0.8:0.2
spliter = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
for train, test in spliter.split(x, y):
print('分层多次分割:', Counter(y[test]))
if __name__ == '__main__':
test01()
test02()
6.1.4 交叉验证法
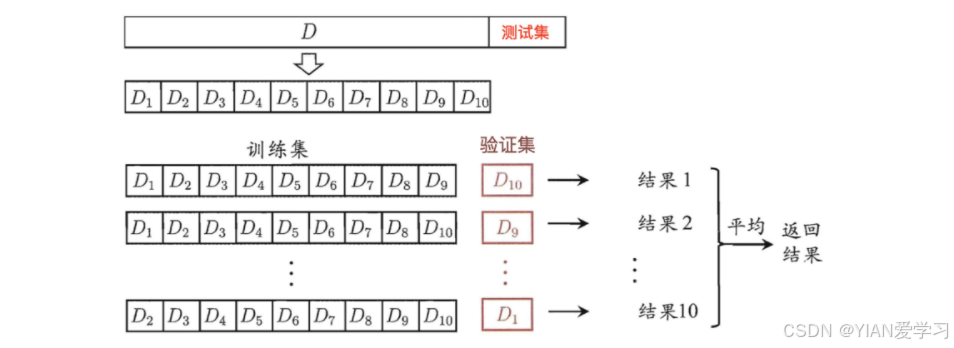
K-Fold交叉验证,将数据随机且均匀地分成k分,如上图所示(k为10),假设每份数据的标号为0-9
- 第一次使用标号为0-8的共9份数据来做训练,而使用标号为9的这一份数据来进行测试,得到一个准确率
- 第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行测试,得到第二个准确率
- 以此类推,每次使用9份数据作为训练,而使用剩下的一份数据进行测试
- 共进行10次训练,最后模型的准确率为10次准确率的平均值
- 这样可以避免了数据划分而造成的评估不准确的问题。
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from collections import Counter
from sklearn.datasets import load_iris
def test():
# 1. 加载数据集
x, y = load_iris(return_X_y=True)
print('原始类别比例:', Counter(y))
print('*' * 40)
# 2. 随机交叉验证
spliter = KFold(n_splits=5, shuffle=True, random_state=0)
for train, test in spliter.split(x, y):
print('随机交叉验证:', Counter(y[test]))
print('*' * 40)
# 3. 分层交叉验证
spliter = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
for train, test in spliter.split(x, y):
print('分层交叉验证:', Counter(y[test]))
if __name__ == '__main__':
test()
6.1.5 留一法
留一法( Leave-One-Out,简称LOO),即每次抽取一个样本做为测试集。
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import LeavePOut
from sklearn.datasets import load_iris
from collections import Counter
def test01():
# 1. 加载数据集
x, y = load_iris(return_X_y=True)
print('原始类别比例:', Counter(y))
print('*' * 40)
# 2. 留一法
spliter = LeaveOneOut()
for train, test in spliter.split(x, y):
print('训练集:', len(train), '测试集:', len(test), test)
print('*' * 40)
# 3. 留P法
spliter = LeavePOut(p=3)
for train, test in spliter.split(x, y):
print('训练集:', len(train), '测试集:', len(test), test)
if __name__ == '__main__':
test01()
6.1.6 自助法
每次随机从D中抽出一个样本,将其拷贝放入D,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被抽到;
这个过程重复执行m次后,我们就得到了包含m个样本的数据集D′,这就是自助采样的结果。
import pandas as pd
# 自助法
# # 进行有放回的抽样
if __name__ == '__main__':
# 1. 构造数据集
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46],
[78, 2, 64, 22]]
data = pd.DataFrame(data)
print('数据集:\n',data)
print('*' * 30)
# 2. 产生训练集
# replace = True 表示允许有重复,有放回的采样
train = data.sample(frac=1, replace=True)
print('训练集:\n', train)
print('*' * 30)
# 3. 产生测试集
test = data.loc[data.index.difference(train.index)]
print('测试集:\n', test)
6.2 分类算法的评估标准
6.2.1 分类算法的评估
如何评估分类算法?
-
利用训练好的模型使用测试集的特征值进行预测
-
将预测结果和测试集的目标值比较,计算预测正确的百分比
-
这个百分比就是准确率 accuracy, 准确率越高说明模型效果越好
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#加载鸢尾花数据
X,y = datasets.load_iris(return_X_y = True)
#训练集 测试集划分
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
# 创建KNN分类器对象 近邻数为6
knn_clf = KNeighborsClassifier(n_neighbors=6)
#训练集训练模型
knn_clf.fit(X_train,y_train)
#使用训练好的模型进行预测
y_predict = knn_clf.predict(X_test)
计算准确率:
sum(y_predict==y_test)/y_test.shape[0]
6.2.2 SKlearn中模型评估API介绍
sklearn封装了计算准确率的相关API:
- sklearn.metrics包中的accuracy_score方法: 传入预测结果和测试集的标签, 返回预测准去率
- 分类模型对象的 score 方法:传入测试集特征值,测试集目标值
#计算准确率
from sklearn.metrics import accuracy_score
#方式1:
accuracy_score(y_test,y_predict)
#方式2:
knn_classifier.score(X_test,y_test)
6.3 小结
- 留出法每次从数据集中选择一部分作为测试集、一部分作为训练集
- 交叉验证法将数据集等份为 N 份,其中一部分做验证集,其他做训练集
- 留一法每次选择一个样本做验证集,其他数据集做训练集
- 自助法通过有放回的抽样产生训练集、验证集
- 通过accuracy_score方法 或者分类模型对象的score方法可以计算分类模型的预测准确率用于模型评估

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









