







1 背景
- 假设一个中型电商公司工作,UI设计师设计了最新的产品页想通过页面更新提高转化率。
- 目前的转化率全年平均在13%左右
- 目标转化率达到15%
- 在新的页面上线之前,我们要通过一小部分用户上测试页面效果,所以要进行AB测试
2 设计实验
2.1 提出假设
-
首先,我们要确保在项目开始时就制定了一个假设
-
鉴于我们不知道新设计的性能是否会比我们当前的设计更好或更差(或相同? ),我们将选择双尾测试:
-
H 0 H_0 H0原假设老的设计比较好新版设计没有用
-
H 1 H_1 H1备选假设新的设计比较好
-
2.2 选择变量
-
对照组:看到旧的设计(这组人查看旧的设计)
-
实验组:看到新的设计(这组人查看新的设计)
- 虽然我们已经知道了旧的设计的转化率(13%左右),但是我们依然要需要设计两组,原因是为了避免其他因素带来的误差,比如季节因素、促销因素。
- 这两组人在其它条件都相同的只是页面设计不同的情况下进行实验,这样 能保证两组间的差异是由于设计导致的
-
我们的设计的目标KPI是转化率,所以,我们会添加一个字段来记录用户的购买情况:
- 购买了产品的用户值为1
- 未购买产品的用户值为0
2.3 确定实验人数
-
AB测试只会选择一小部分用户来参与实验,用小部分的实验结果来估计整体的结果,每组的人数越多,我们得到的结果就越精准,但同时我们付出的成本就越大,通过功效分析我们可以计算出满足实验条件的最小人群
-
检验功效( 1 − β 1-\beta 1−β):一般设置为0.8
-
α \alpha α:在设计实验的时候我们设置为0.05
-
-
效果大小:旧的页面转化率为13%,新页面我们希望转化率能提升2%,所以我们可以用13%和15%来计算预期效果大小。
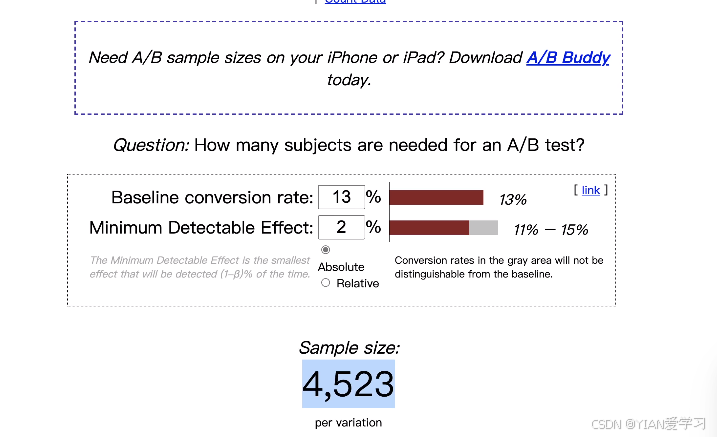
-
确定实验人数的计算过程可以通过Python代码实现
import numpy as np
import pandas as pd
import scipy.stats as stats # 科学计算库中的统计学库
import statsmodels.stats.api as sms
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
from math import ceil # 向上取整函数
# Effect size for a test comparing two proportion
effect_size = sms.proportion_effectsize(0.13, 0.15)
required_n = sms.NormalIndPower().solve_power(
effect_size, # 传入上面计算的 effect_size
power=0.8, # 设置 1-β = 80%
alpha=0.05, # 设置 α 为5%
ratio=1 # 对照组和测试组人一样, 这里的ratio 比例就是1
)
#对结果向上取整
required_n = ceil(required_n)
print(required_n) # 4720
2.4 收集准备数据
- 读取数据
# 读取数据
df = pd.read_csv('./ab_data.csv')
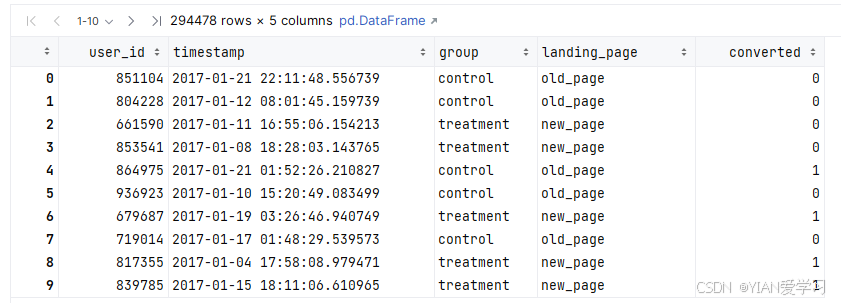
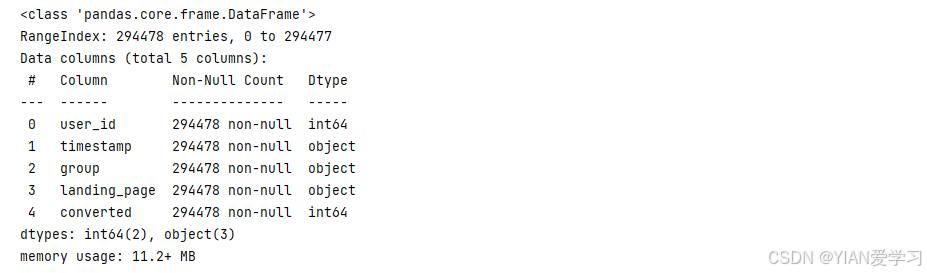
- 查看数据信息
- 一共294478条数据
- 没有缺失值
- 当前数据已经对用户进行了分组,并且进行了组别标记,control组还是treatment组
df.info()
- group - 该用户被分到哪一组(control对照、treatment实验组)
- landing_page - 该用户看到的是哪一种落地页(old_page 老页面,new_page新页面)
- converted - 该次访问是不是有转化(binary,0=无转化,1=转化)
- 后续主要使用的字段
group和converted这两个字段
- 通过透视表,查看是不是对照组中查看的都是老页面
- 对照组中,不全部都是老页面,说明,对照组中的用户有的操作了两次
pd.pivot_table(df, index='group', columns='landing_page', values='user_id', aggfunc='count')

- 在进行后续处理之前,查看用户是否进行了多次操作
# 产看是否用户进行了多次操作
# 根据user_id进行计数,user_id出现多次表示用户进行多次操作
session_counts = df['user_id'].value_counts(ascending=False)
session_counts[session_counts>1].count() # 计算大于1的user_id的和,表示有多少用户多次操作
users = session_counts[session_counts<2].index # 选择没有多次操作的用户,获取到用户的index
# 从原始数据中,得到选择出对应的数据
# series1.isin(series2) - 每一行进行判断,在series2中返回True,不在就返回False
df = df[df['user_id'].isin(users)]

- 数据采样
# 对照组和测试组中各自取出相应的人数
# 开始计算得到的对照组和实验组的人数
required_n = 4720
control_sample = df[df['group'] == 'control'].sample(n=required_n, random_state=22)
treatment_sample = df[df['group'] == 'treatment'].sample(n=required_n, random_state=22)
# 采样完成之后,将两个组合并到一起
# concat() - 默认上下堆叠,axis=0
# axis = 1 左右堆叠
ab_test = pd.concat([control_sample, treatment_sample], axis=0)
# 拼接之后,索引混乱,所以重置索引
ab_test.reset_index(inplace=True, drop=True)
- 查看两组的数据情况
ab_test.groupby('group')['landing_page'].value_counts()

对照组中的用户看到的都是老页面,测试组用户看到的都是新页面
2.5 分析实验
2.5.1 计算两组的转化率和标准差
- 转化率:转化的人数/总人数
- 在这里使用converted列的数据,由于数据取值是0或1,所以转化率 = 当前组的converted的和/当前组的人数 = converted的平均值
conversion_rates = ab_test.groupby('group')['converted'].mean().to_frame()
conversion_rates.style.format('{:.3f}')
conversion_rates

- 从上面的统计数据来看,旧页面和新页面的转化率非常相似
- 从对照结果来看,转化率相比于之前已知的整体13%转化率要差一些,可能与采样的人群的差异有关。
- 这个结果是否具有统计意义?是否是准确的? - 通过假设检验进行检查。
2.5 假设检验
- 样本数据量比较大,可以使用z检验来计算P值,如果P值<0.05,说明原假设错误。
- Z检验一般用于大样本(即样本容量大于30)平均值差异性检验方法,它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数的差异是否显著。
- 我们可以使用statsmodels.stats.proportion 模块来计算P值和置信区间
from statsmodels.stats.proportion import proportions_ztest, proportion_confint
# 1. 获取两个组中对照组和测试组是否转化的数据,也就是converted列
control_results = ab_test[ab_test['group'] == 'control']['converted'] #获取对照组是否转化的数据
treatment_results = ab_test[ab_test['group'] == 'treatment']['converted'] #获取实验组是否转化的数据
# 对照组和测试组人数组成的列表,n_required = 4720
nobs = [n_required,n_required]
# 对照组和测试组转化人数组成的列表,[561,558]
successes = [control_results.sum(), treatment_results.sum()]
- 计算P值
# 返回P值
z_stat, pval = proportions_ztest(successes, nobs=nobs) #计算P值

- value表是 H 0 H_0 H0假设的值,是一个比例、合格率或者概率;
- 计算置信区间
(lower_con, lower_treat), (upper_con, upper_treat) = proportion_confint(successes, nobs=nobs, alpha=0.05) #计算置信区间
# 计算P值和置信区间的代码
z_stat, pval = proportions_ztest(successes, nobs=nobs) #计算P值
(lower_con, lower_treat), (upper_con, upper_treat) = proportion_confint(successes, nobs=nobs, alpha=0.05) #计算置信区间
print(f'z statistic: {z_stat:.2f}')
print(f'p-value: {pval:.3f}')
print(f'ci 95% for control group: [{lower_con:.3f}, {upper_con:.3f}]')
print(f'ci 95% for treatment group: [{lower_treat:.3f}, {upper_treat:.3f}]')
z statistic: 0.10
p-value: 0.924
ci 95% for control group: [0.110, 0.128]
ci 95% for treatment group: [0.109, 0.127]
- 最终计算出的P=0.924远大于 α \alpha α,不能推翻原假设,原假设成立,旧页面更好。
2.6 统计函数
statsmodels.stats.proportion.proportions_ztest(count,nobs,value = None,Alternative =‘two-side’,prop_var = False)
参数:
- count : {int, array_like},试验成功的次数。如果是array_like,则假设此值代表每个独立样本的成功次数
- nobs : {int, array_like},试验或观察值的数量,其长度与count参数相同。
- value : float, array_like or None, optional,这是零假设的值,等于一个样本检验的比例。在两样本检验的情况下,原假设为prop [0]-prop [1] =值,其中prop是两个样本中的比例。如果未提供,则值= 0,并且null为prop [0] = prop [1]
- alternative : str in [‘two-sided’, ‘smaller’, ‘larger’],假设验证可以是双向检验,也可以是单面检验之一,smaller的意味着左侧检验prop < value, 而larger的意味着右侧检验prop > value。在两个样本检验中,smaller意味着替代假设p1 < p2成立,而larger意味着 p1 > p2。
- prop_var : False or float in (0, 1),如果prop_var为false,则根据样本比例计算比例估计的方差。或者,可以指定比例来计算此方差。常见用例是使用Null假设下的比例来指定比例估计的方差。
- 返回值:zstat:float;p-value: float
proportion_confint(count, nobs, alpha: float = 0.05, method=‘normal’)
参数:
- count : {int or float, array_like},试验成功次数。可以是Pandas Series或DataFrame。如果method参数的取值为"binom_test",则这些数组必须包含整数值。
- nobs : {int or float, array_like}
试验总次数。如果method参数的取值为"binom_test",则这些数组必须包含整数值。 - alpha : float,显著性水平,默认为0.05,范围必须在(0,1)之间
- method : {“normal”, “agresti_coull”, “beta”, “wilson”, “binom_test”},默认: “normal”
- 置信区间的计算方法。支持以下方法:
- normal:渐近正态近似
- agresti_coull:Agresti-Coull区间
- beta:基于Beta分布的Clopper-Pearson区间
- wilson:Wilson得分区间
- jeffreys:Jeffreys贝叶斯区间
- binom_test:binom_test数值反演法
- 返回值:ci_low, ci_upp : {float, ndarray, Series DataFrame},以(近似)1-alpha的置信度的下限和上限置信区间。当返回Pandas对象时,取“count”的索引值。

















 5770
5770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









