







文章目录
1. 认识RNN模型
1.1 RNN模型
循环神经网络RNN(Recurrent Neural Network,简称RNN)
一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出
- RNN循环神经网络,可以用于捕捉序列特征
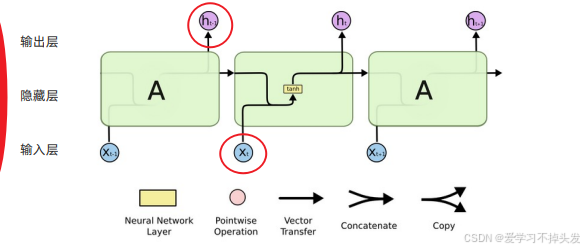
RNN模型的网络结构:
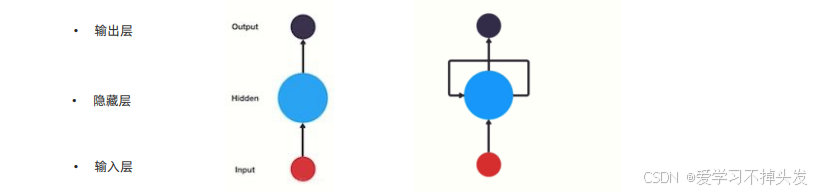
RNN为什么称作循环神经网络:
上一时间步的隐藏层输出作为下一个时间步的隐藏层输入
- 以时间步对RNN进行展开后的单层网络结构
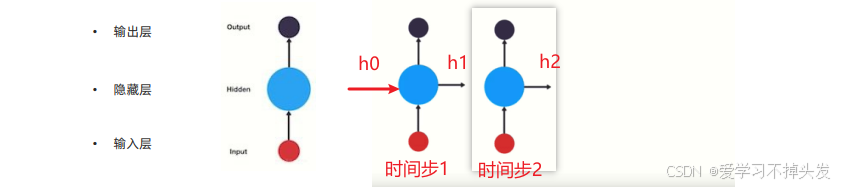
- RNN网络结构特点
- 由输入层、隐藏层、输出层组成;上一时间步的隐藏层输出作为下一个时间步的隐藏层输入
- 每个时间步的输入有2个:数据端输入,隐藏层输入
- 每个时间步的输出有2个:数据端输出,隐藏层输出(当循环神经网络只有一个隐藏层的时候,时间步的输出output和隐藏层的输出一样,当隐藏的个数不是一的时候,时间步输出与最后一隐藏层的输出一样)
1.2 RNN模型作用
- RNN结构能够连续性的输入序列数据,进行特征提取。比如:人类的语言, 语音特别适合RNN进行处理。
- RNN模型广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等。
举例:用户意图识别
- 第一步: 用户输入“What time is it ?”,先进行分词。RNN是一个时间步一个时间步的输入数据, 每次只接收一个单词处理
- 第二步: 首先将单词"What"输送给RNN, 它将产生一个输出O1
- 第三步:继续将单词“time”输送给RNN, RNN不仅利用"time"来产生输出O2, 还使用上一层隐层输出O1作为输入信息,重复这样的步骤, 直到处理完所有的单词,用最后一个输出表示句子的特征。

第五步:最后,将最终的隐层输出O5进行处理来解析用户意图。

1.3 RNN模型分类
按照输入和输出的角度进行分类
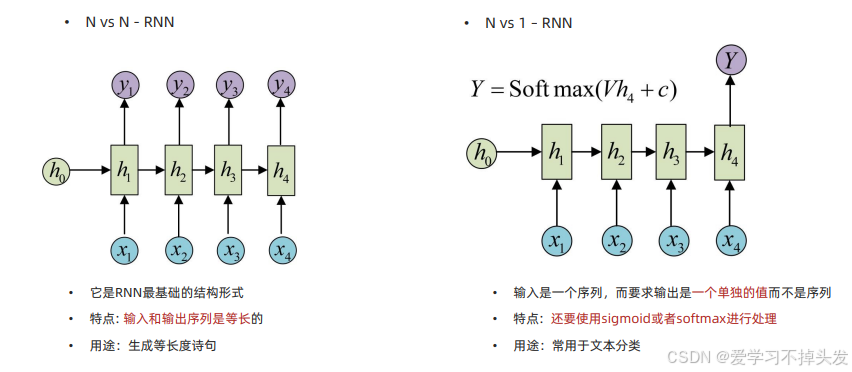
- N vs N – RNN 输入N个序列,输出N个序列 写诗 写对联 固定场景表达
- N vs 1 – RNN 输入N个序列,输出1个的值 情感分类 意图识别
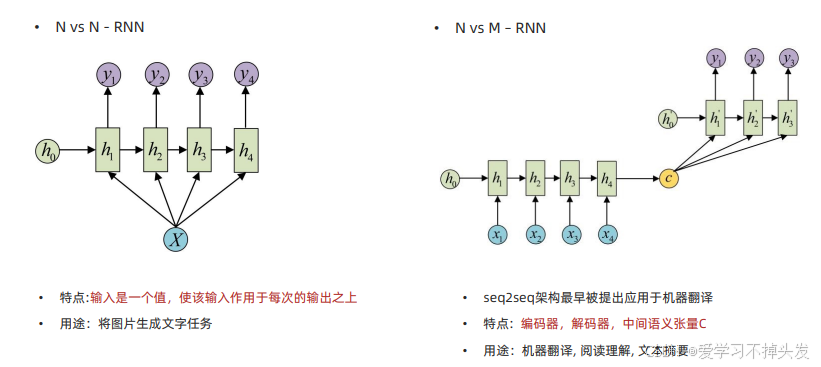
- 1 vs N – RNN 输入1个序列,输出N个的值 看图说话
- N vs M – RNN 输入N个序列,输出M个序列 翻译、语音转换;文本生成、摘要
按照RNN的内部构造进行分类
- 传统RNN
- LSTM
- Bi-LSTM
- GRU
- Bi-GRU
2. 传统RNN模型
2.1 RNN内部结构
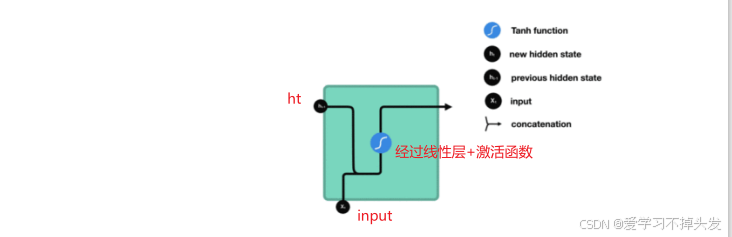
- 每个时间步有2个输入:h(t-1)上一时间步的隐层输出, x(t)当前时间步的输入
- 进入RNN结构体后, 会"融合"到一起, 通过一个全连接层(线性层), 再使用tanh作为激活函数。经过一个线性层就会有一个权重参数矩阵。
- 每个时间步有2个输出:h(t)该时间步的隐藏层输出(它将作为下一个时间步的隐藏层输入),x(t+1) 当前时间步的输出
- 编程符号: input, output, ℎ0, ℎn
- RNN内部计算公式 – 学术界论文
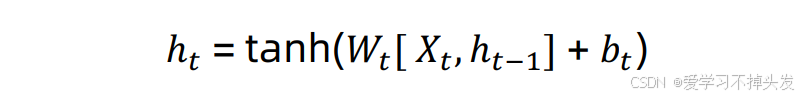
相当于用矩阵参数对数据进行加权求和,再通过激活层添加非线性因素
- pytorch框架 – 工业界实现
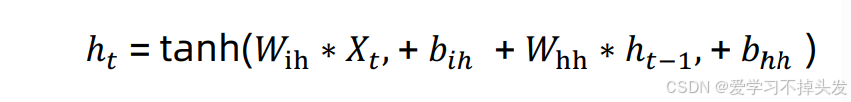
相当于用隐藏层数据@内部隐藏层参数矩阵Whh +用时间步数据@内部参数矩阵Wih,加一起,再用tanh激活
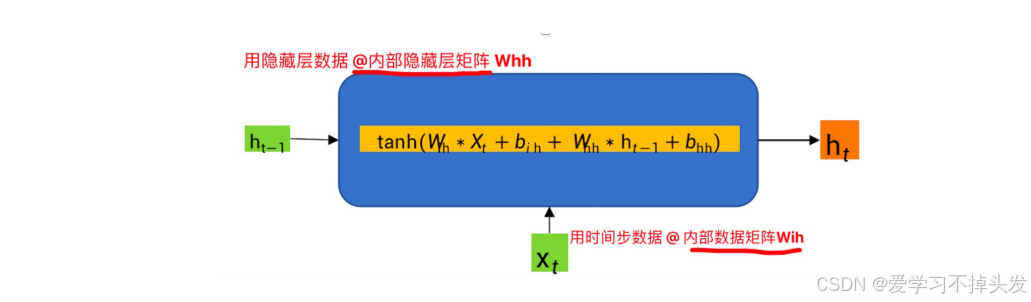
- 激活函数tanh的作用
用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间
2.2 RNN API简介
- 在torch.nn工具包之中, 通过torch.nn.RNN可调用
import torch
import torch.nn as nn
def dm01_rnn_for_base():
# 第一个参数:input_size,输入数据的尺寸,词向量的维度
# 第二个参数:hidden_size 经过RNN之后词向量的维度
# 第三个参数:layer_nums - RNN隐藏层的个数
# RNN模型的创建只与词向量的维度或者是特征的维度有关
rnn = nn.RNN(5,6,1)
if __name__ == '__main__':
dm01_rnn_for_base()
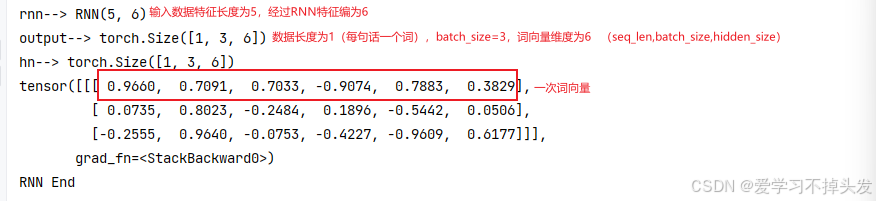
2.3 探究RNN中数据形状的变化
举例:RNN提取文本特征需求
- 数据:[3,1,5] 3个批次 每个批次1个单词 每个单词5个特征
- 模型 :经过模型处理能变6个特征
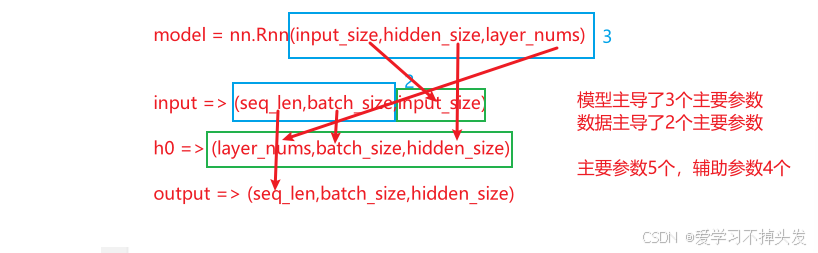
- 探究:9个参数中 主参数和辅助参数的关系
2.3.1 RNN API中的9个参数
def dm01_rnn_for_base():
# 1 定义模型
# 第1个参数input_size: 5 输入的数据特征数
# 第2个参数hidden_size: 6 输出的特征数(输出的数据尺寸, 也代表了神经元的个数)
# 第3个参数layer_nums: 1 隐藏层的个数
rnn = nn.RNN(5, 6, 1)
print('rnn-->', rnn)
# 2 准备数据
# 第1个参数seq_len: 数据长度
# 第2个参数batch_size: 3代表批次数
# 第3个参数input_size: 输入数据的尺寸
# 可以认为是从dataloader中每次取出三个句子,每个句子长度为1,词向量的长度为5
input = torch.randn(1, 3, 5)
# 第1个参数layer_nums: 1 隐藏层的个数
# 第2个参数batch_size: 3 数据的批次数
# 第3个参数hidden_size: 6 输出的数据特征数
h0 = torch.randn(1, 3, 6) # 3句话, 每句话有1个单词, 每个单词有6个特征
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[1,3,5],h0[1,3,6] ---> output[1,3,6 ], hn[1,3,6]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape)
print('hn-->', hn.shape)
print(output)
2.3.2 更改输入特征的维度(input_size)
- 更改输入数据的词向量维度
def dm02_rnn_for_inputdim():
# 1 定义模型
# 第1个参数input_size: 55 输入的数据特征数
# 第2个参数hidden_size: 6 输出的特征数(输出的数据尺寸, 也代表了神经元的个数)
# 第3个参数lay_nums: 1 隐藏层的个数
rnn = nn.RNN(55, 6, 1) # A
print('rnn-->', rnn)
# 2 准备数据
# 第1个参数seq_len: 数据长度
# 第2个参数batch_size: 3代表批次数
# 第3个参数input_size: 55输入数据的尺寸
input = torch.randn(1, 3, 55) # B
# 第1个参数layer_nums: 1 隐藏层的个数
# 第2个参数batch_size: 3 数据的批次数
# 第3个参数hidden_size: 6 输出的数据特征数
h0 = torch.randn(1, 3, 6) # C 3句话, 每句话有1个单词, 每个单词有6个特征
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[1,3,55],h0[1,3,6] ---> output[1,3,6 ], hn[1,3,6]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape)
print('hn-->', hn.shape)
# print(output)
- 修改输入数据的特征数(input_size),会影响input中的输入数据特征维度
- 不影响output和hn

2.3.3 更改输出数据特征数(hidden_size)
def dm022_rnn_for_outputdim():
# hidden_size改为66,经过RNN之后,词向量特征会变为66
rnn = nn.RNN(5, 66, 1)
print('rnn-->', rnn)
input = torch.randn(1, 3, 5)
h0 = torch.randn(1, 3, 66) # 3句话, 每句话有1个单词, 每个单词有66个特征
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[1,3,5],h0[1,3,66] ---> output[1,3,6 ], hn[1,3,66]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape)
print('hn-->', hn.shape)
# print(output)

2.3.4 更改文本序列长度(seq_len)
def dm03_rnn_for_sequencelen():
rnn = nn.RNN(5, 6, 1) # A
print('rnn-->', rnn)
# 每个句子的长度改为11
# batch_size = 3
input = torch.randn(11, 3, 5) # B 3句话, 每句话有1个单词, 每个单词有6个特征
h0 = torch.randn(1, 3, 6) # C
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[1,3,5],h0[1,3,6] ---> output[11,3,6 ], hn[1,3,6]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape)
print('hn-->', hn.shape)
# print(output)

2.3.5 更改批次数(batch_size)
def dm04_rnn_for_batchsize():
rnn = nn.RNN(5, 6, 1) # A
print('rnn-->', rnn)
# batch_size = 33
# 每次送入33个样本
input = torch.randn(1, 33, 5) # B 3句话, 每句话有1个单词, 每个单词有6个特征
h0 = torch.randn(1, 33, 6) # C
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[1,33,5],h0[1,33,6] ---> output[1,33,6], hn[1,33,6]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape)
print('hn-->', hn.shape)
# print(output)

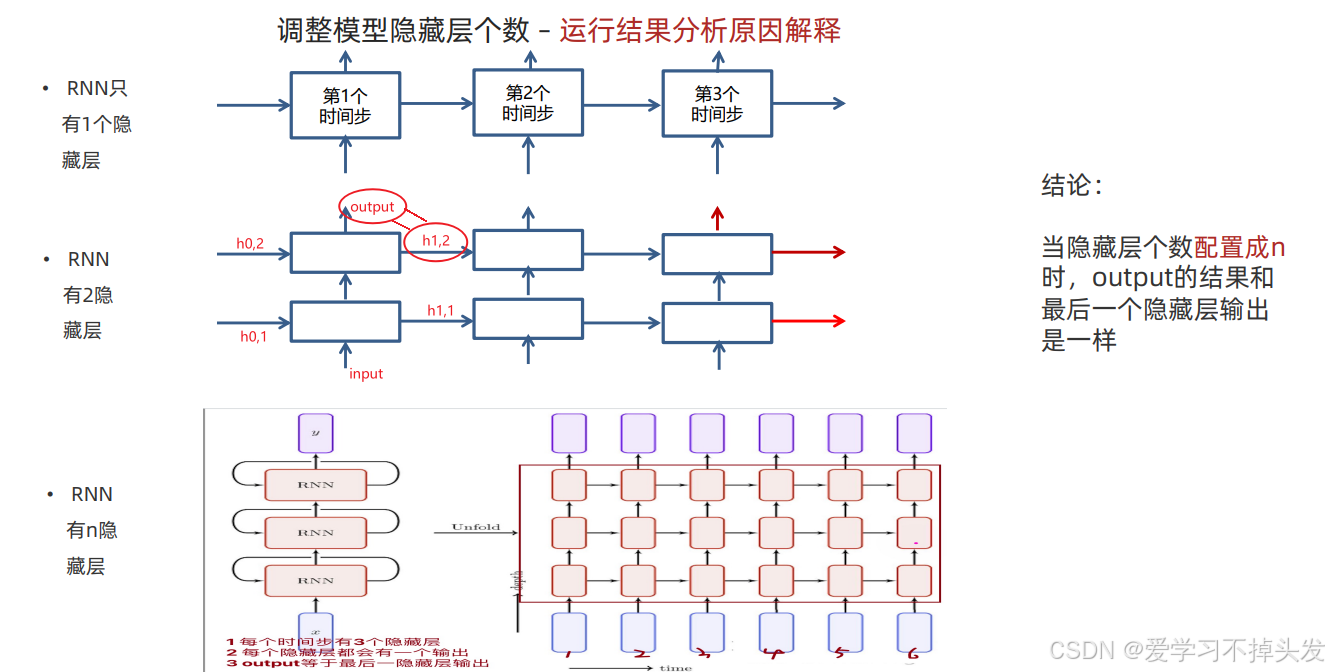
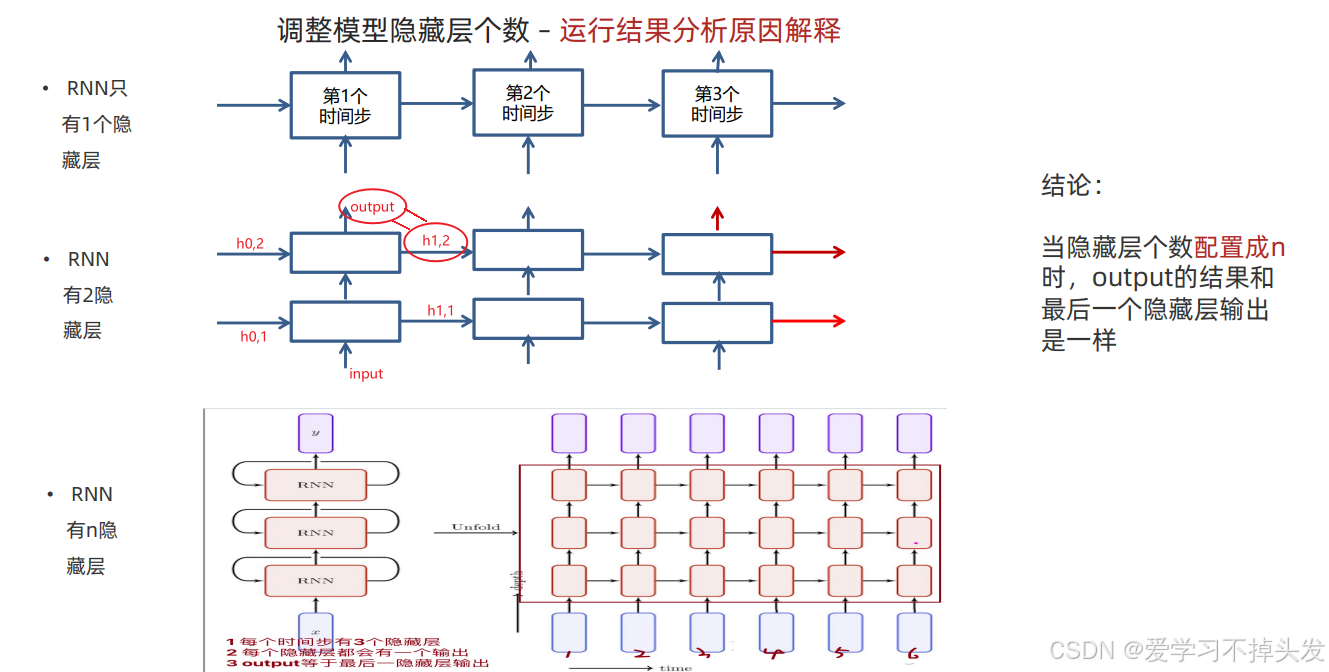
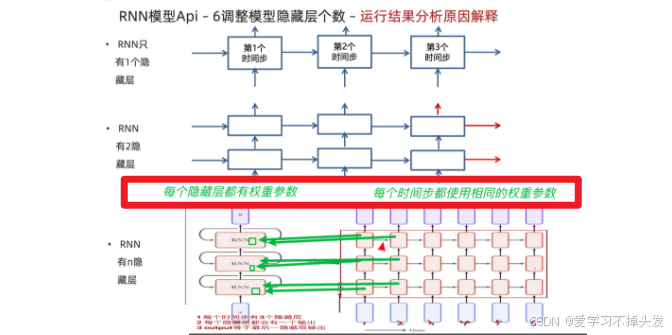
2.3.6 更改隐藏层的层数(layer_nums)
def dm05_rnn_for_hiddennum():
# 1 定义模型
# 第1个参数: 5 输入的数据特征数
# 第2个参数: 6 输出的特征数(输出的数据尺寸, 也代表了神经元的个数)
# 第3个参数: 2 隐藏层的个数
rnn = nn.RNN(5, 6, 2) # A
print('rnn-->', rnn)
# 2 准备数据
# 第1个参数: 数据长度
# 第2个参数: 3代表批次数
# 第3个参数: 输入数据的尺寸
input = torch.randn(1, 3, 5) # B 3句话, 每句话有1个单词, 每个单词有6个特征
# 第1个参数: 1 隐藏层的个数
# 第2个参数: 3 数据的批次数
# 第3个参数: 6 输出的数据特征数
h0 = torch.randn(2, 3, 6) # C
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[1,3,5],h0[2,3,6] ---> output[1,3,6 ], hn[2,3,6]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape, '\n', output)
print('hn-->', hn.shape, '\n', hn)
# print(output)
# 当隐藏层的个数是1时, hn 和 ouput长得一样
# 当隐藏层的个数是2时, hn 和 ouput?

2.3.7 调整参数顺序
- 默认情况下,RNN模型的input形状为(seq_len,batch_size,input_size)、output的形状为(seq_len,batch_size,hidden_size),这样填写参数的时候需要注意
- 创建RNN模型的时候,将batch_first设置为True,就可以将input的形状调整为(batch_size,seq_len,input_size),output的形状调整为(batch_size,seq_len,hidden_size)
- batch_first=True 参数只是对 input 和 output数据影响,不对 h0、hn影响
def dm06_rnn_for_batch_first():
# 1 定义模型
# 第1个参数: 5 输入的数据特征数
# 第2个参数: 6 输出的特征数(输出的数据尺寸, 也代表了神经元的个数)
# 第3个参数: 1 隐藏层的个数
rnn = nn.RNN(5, 6, 1, batch_first=True) # A
print('rnn-->', rnn)
# 2 准备数据
# 第1个参数: 数据长度
# 第2个参数: 3代表批次数
# 第3个参数: 输入数据的尺寸
input = torch.randn(3, 1, 5) # B 3句话, 每句话有1个单词, 每个单词有6个特征
# 第1个参数: 1 隐藏层的个数
# 第2个参数: 3 数据的批次数
# 第3个参数: 6 输出的数据特征数
h0 = torch.randn(1, 3, 6) # C
# 3 给模型喂数据 h0 和 hn的数据形状一样
# input[3,1,5],h0[1,3,6] ---> output[3,1,6 ], hn[1,3,6]
output, hn = rnn(input, h0)
# 4 打印结果
print('output-->', output.shape)
print('hn-->', hn.shape)
# print(output)
2.4 输入RNN模型的两种方式
- 方式1:一个字符一个字符的给模型喂数据 : 程序员需要一个时间步一个时间步的把 hn迭代起来
- 方式2: 一下子把10个字符送给模型 : rnn模型内部会一次性的把运算结果返回给调用者,模型内部会把hn迭代起来
- 两种输入方式最终得到的结果是一样的
def dm07_rnn_for_multinum():
# 1 构建模型 rnn
rnn = nn.RNN(input_size=5, hidden_size=6, num_layers=1, batch_first=True)
print('rnn-->', rnn)
# 2 准备数据 input, hidden
# batch_size = 1
# seq_len = 10 - 一个样本有10个词,每个词5个特征
input = torch.randn(1, 10, 5)
hidden = torch.zeros(1, 1, 6)
# 3 方式1 一个字符一个字符的送数据
for i in range(input.shape[1]):
tmp = input[0][i] # input[0] - (10,5) input[0][i] 得到第i个词向量
print('tmp-->', tmp.shape) # [5] ,需要升维之后送入到rnn中
output, hidden = rnn(tmp.unsqueeze(0).unsqueeze(0), hidden)
print(i+1, '-->', output)
pass
# 4 方式2:一次性给模型喂数据
hidden = torch.zeros(1, 1, 6)
output, hidden = rnn(input, hidden)
print('output-->', output)
# input = torch.randn(1, 10, 5)
# hidden = torch.zeros(1, 1, 6)


2.5 RNN模型的优缺点
- RNN网络的优点
- 内部结构简单,对计算资源要求低
- 在短序列任务上性能和效果都表现优异
- RNN网络缺点
- 长序列文本特征提取效果差
-
过长的序列导致梯度的计算异常,发生梯度消失或爆炸
-
- 长序列文本特征提取效果差
3 RNN模型注意事项
- N vs M 类型的RNN模型是seq2seq架构的基础
- 熟练掌握RNN模型的标志,能够熟练分析数据在RNN中的形状变化
- RNN模型API中的9个参数,主要参数有5个,辅助参数有四个
- 有关隐藏层个数理解,output的输出与最后一个隐藏层的输出一样。每个隐藏层都有权重参数,每个隐藏的不同时间步共享权重参数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









