









1 案例介绍
Seq2Seq思想:将输入序列映射为一个中间表示,然后再从这个中间表示生成目标序列
1.1 Seq2Seq架构
本案例英译法通过seq2seq设计与实现;并且在解码部分添加上attention计算规则
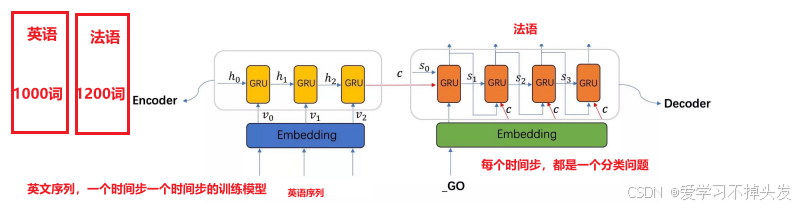
seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c
编码流程:1个时间步1个时间步的编码,每个时间步有隐藏层输出,最终组合成中间语义张量C
解码流程:1个时间步1个时间步的解码
- 解码 eg:每个时间步输入:input和h!"# 输出output和ht
- 再接一个全连接层+softmax做一个分类,从分类结果中找一个预测结果即可
1.2 案例介绍
案例需求:
- 输入一个英文句子,使用模型将其翻译成法文
- 使用seq2seq架构探索英文和法文之间的关系
- 在解码器端增加注意力机制
案例价值:
- 属于AI赋能互联网业务
- 比如:为企业和个人提供不同语种间快速翻译能力
- 快速探索source源文本和目标文本target之间的关系
数据说明
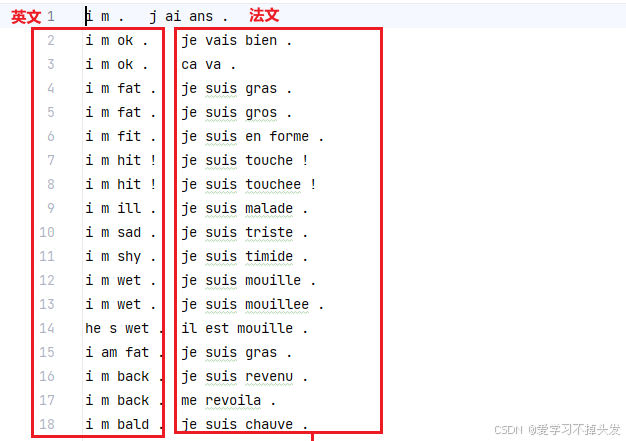
- 数据格式说明:每一行有2列,第1列为英文,第2列为法文,中间用制表符tab分割
- 标注好的,可以训练的数据一共有10599条
1.3 案例实现步骤
整个案例的实现分为以下几个步骤
- 第一步:任务识别
- 第二步:数据的处理
- 数据处理三部曲:读数据到内存、构建数据集dataset、构建dataloader
- 第三步:构建GRU的编码器、解码器模型、基于注意力机制解码器模型
- 搭建模型和模型的测试程序(重点)
- 第四步:构建训练函数并进行训练
- 第五步:构建模型评估函数并进行测试
2 数据处理
2.1 任务识别
-
给出一个英文,翻译成法文,最终每个时间步相当于一个分类问题
- 其中source单词-英文数目:2803;target单词-法文数目:4345
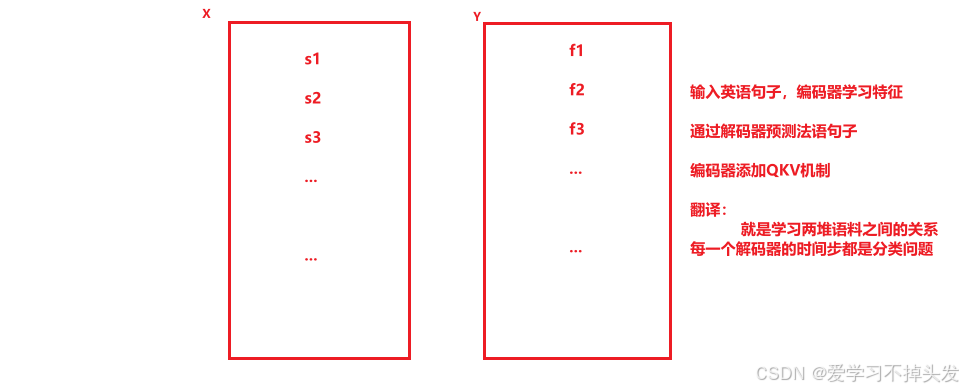
- 探索source文本(eg:英文)和target文本(eg:法文)之间的语义关系。
- eg:输入一个英文(2803个词汇的一个)来找一个法文(4345个词汇中的一个)
- 不是单词之间的直译:i <—> 我 love<—>爱 china<—>中国
-
文本数值化数值张量的技术选型分析(数据如何送给模型?)
- 探索source文本和target文本之间的关系,属于word词汇之间的语义抽象和探索
- 使用单词张量化技术,以每个句子的词汇作为最小的单位
- 文本分词 —>数值化(word2idx idx2word)—> 数值张量化(word2vec)
- 本案例:把句子分词,按照词表转成数字序列,再通过nn.Embedding构建词向量,再送给模型
-
模型选型分析(如何选择模型?)
- 模型解码:可以带注意力机制,也可以不带注意力机制
- 模型训练:可采用Teacher-forcing方式,也可以不采用Teacher-forcing
- 注意:训练模型时,需要把英文和法文(标准答案)一块送给模型,来训练模型
- 每个时间步的预测值和真实值之间有差异,计算loss,反向传播不断的更新模型权重参数,学习英译法数据的规律
2.2 文本数值化
- 文本数值化是为了获取到构词表word2index和index2word,还有词汇的数量,为了传入到nn.Embedding中,将词汇映射成张量,然后根据索引查找对应的张量。
- 经过数据最终得到的结果是构词表和总的单词数
- english_word2index
- english_index2word
- english_word_n
- french_word2index
- french_index2word
- french_word_n
- my_pairs
- 读取数据,获得文件句柄,将数据全部读入到内存中,去除前后两端的空格,按照行进行切分
# my_lines是一个列表,其中每一个元素是原文本中一行的字符串
my_lines = open('./data/eng-fra-v2.txt', encoding='utf-8').read().strip().split('\n')
- 遍历每一行的数据,进行数据清洗,将每一行的英文和法文切分成列表放到my_pairs表中
tmppairs = []
my_pairs = []
for line in my_lines:
for s in line.split("\t"): # line.split("\t")得到一个列表,一个是英文句子,一个是法文句子
tmppairs.append(normalizeString(s))
my_pairs.append(tmppairs)
tmppairs = []
# 可以使用列表生成式实现
# my_pairs = [[normalizeString(s) for s in line.split("\t")] for line in my_lines]
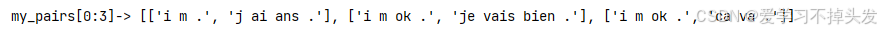
3. 创建english_word2index、french_word2index表
# 添加开始和结束两个标志,所以构词表的长度初始就为2
english_word2index = {"SOS": 0, "EOS": 1};
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1};
french_word_n = 2
# 遍历每个英语和法语配对的列表
for pair in my_pairs:
for word in pair[0].split(" "): # 对英语句子根据空格分词,然后进行遍历
# 如果不在构词表中就添加进入
if word not in english_word2index:
english_word2index[word] = english_word_n
english_word_n += 1
for word in pair[1].split(" "): # 对法文句子进行相同的处理
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
# print('english_word2index-->', len(english_word2index))
# print('french_word2index-->', len(french_word2index))
- 获取english_index2word、和french_index2word表,使用字典生成式,遍历word2index表,获取到k,v之后,将其反转为v,k,添加到新字典中获取到新的表
english_index2word = {v:k for k, v in english_word2index.items()}
french_index2word = {v:k for k, v in french_word2index.items()}
- 封装为函数
# 用于正则表达式
import re
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
# torch中预定义的优化方法工具包
import torch.optim as optim
import time
# 用于随机生成数据
import random
import matplotlib.pyplot as plt
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 起始标志
SOS_token = 0
# 结束标志
EOS_token = 1
# 最大句子长度不能超过10个 (包含标点)
MAX_LENGTH = 10
# 数据文件路径
data_path = './data/eng-fra-v2.txt'
# 工具函数
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
# my_getdata() 清洗文本构建字典思路分析
# 1 按行读文件 open().read().strip().split(\n) my_lines
# 2 按行清洗文本 构建语言对 my_pairs[] tmppair[] for line in my_lines for s in line.split('\t')
# 2-1格式 [['英文', '法文'], ['英文', '法文'], ['英文', '法文'], ['英文', '法文']....]
# 2-2调用清洗文本工具函数normalizeString(s)
# 3 遍历语言对 构建英语单词字典 法语单词字典 my_pairs->pair->pair[0].splt(' ') pair[1].split(' ')->word
# 3-1 english_word2index english_word_n french_word2index french_word_n
# 其中 english_word2index = {"SOS":0, "EOS":1} english_word_n=2
# 3-2 english_index2word french_index2word
# 4 返回数据的7个结果
# english_word2index, english_index2word, english_word_n,
# french_word2index, french_index2word, french_word_n, my_pairs
def my_getdata():
# 1 读数据
my_lines = open('./data/eng-fra-v2.txt', encoding='utf-8').read().strip().split('\n')
print('len(my_lines)-->', len(my_lines))
# 2 按行清洗文本 构建语言对
tmppairs = []; my_pairs = []
for line in my_lines:
for s in line.split('\t'):
tmppairs.append(normalizeString(s))
my_pairs.append(tmppairs)
tmppairs = []
my_pairs = [[normalizeString(s) for s in line.split('\t')] for line in my_lines]
print('my_pairs[0:3]->', my_pairs[0:3])
# print('第8000样本的英文-->', my_pairs[8000][0])
# print('第8000样本的法文-->', my_pairs[8000][1])
# 3 遍历语言对 构建英语单词字典 法语单词字典 my_pairs->pair->pair[0].splt(' ') pair[1].split(' ')->word
# 3-1 english_word2index english_word_n french_word2index french_word_n
# 其中 english_word2index = {"SOS":0, "EOS":1} english_word_n=2
# 3-2 english_index2word french_index2word
english_word2index = {"SOS": 0, "EOS": 1};
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1};
french_word_n = 2
for pair in my_pairs:
for word in pair[0].split():
if word not in english_word2index:
english_word2index[word] = english_word_n
english_word_n += 1
for word in pair[1].split():
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
print('english_word2index-->', len(english_word2index))
print('french_word2index-->', len(french_word2index))
english_index2word = {v:k for k, v in english_word2index.items()}
french_index2word = {v:k for k, v in french_word2index.items()}
# print('english_index2word-->', len(english_index2word))
# print('french_index2word-->', len(french_index2word))
# 4 返回数据的7个结果
return english_word2index, english_index2word, english_word_n, \
french_word2index, french_index2word, french_word_n, my_pairs
# 全局函数 获取英语单词字典 法语单词字典 语言对列表my_pairs
english_word2index, english_index2word, english_word_n,\
french_word2index, french_index2word, french_word_n, my_pairs = my_getdata()
2.3 创建数据集对象
- 数据集类实现三个方法
- init,需要将用到的数据传入到数据集中
- len,获取数据集长度
- getitem,可以通过索引取值
class MyPairsDataset(Dataset):
def __init__(self, my_pairs):
self.my_pairs = my_pairs
self.sample_len = len(my_pairs)
def __len__(self):
return self.sample_len
# item就是索引index
def __getitem__(self, item):
# 按索引 获取数据样本 x y
x = self.my_pairs[item][0] # 英语句子
y = self.my_pairs[item][1] # 法语句子
# 样本x 文本数值化 word2id x.append(EOS_token)
# 遍历句子中的词汇,查找到词汇索引,放到一个列表中
x = [english_word2index[word] for word in x.split(' ')]
# 添加结束标志符
x.append(EOS_token)
# 将表示句子的索引列表转换为张量
tensor_x = torch.tensor(x, dtype=torch.long, device=device)
# 样本y 文本数值化 word2id y.append(EOS_token)
y = [french_word2index[word] for word in y.split(' ')]
y.append(EOS_token)
tensor_y = torch.tensor(y, dtype=torch.long, device=device)
# 返回tensor_x, tensor_y
return tensor_x, tensor_y
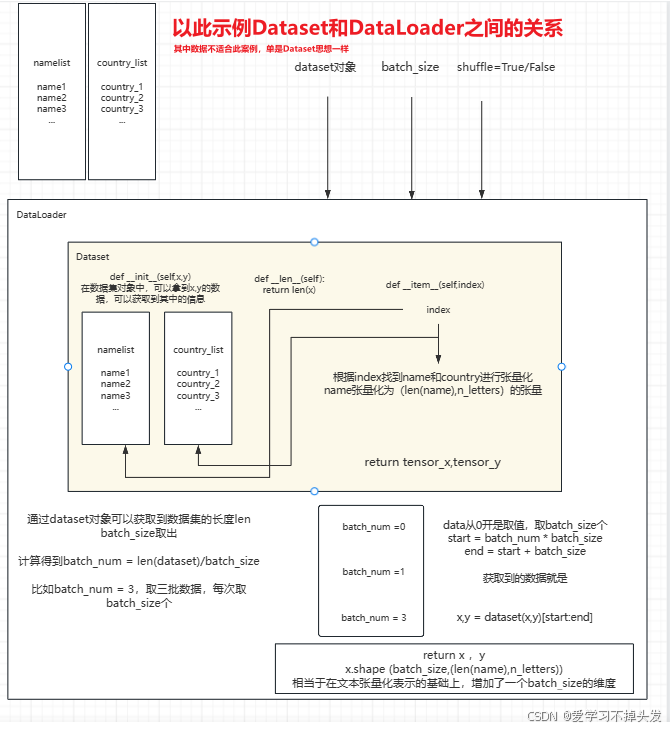
2.4 通过DataLoader获取数据
def dm01_test_MyPairsDataset():
# 1 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
print('mypairsdataset-->', mypairsdataset)
# 2 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 3 遍历容器拿数据
for idx, (x, y) in enumerate(mydataloader):
print('x-->', x.shape, x)
print('y-->', y.shape, y)
if idx == 1:
break
print('文本数值化 ok')



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









