








前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学业升学和工作就业的先行者!
【优惠信息】 • 新专栏订阅前500名享9.9元优惠 • 订阅量破500后价格上涨至19.9元 • 订阅本专栏可免费加入粉丝福利群,享受:
- 所有问题解答
-专属福利领取欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!

深度可分离卷积网络是一种高效的神经网络设计,尤其在计算机视觉领域中备受关注。它通过将传统卷积操作拆分为两个步骤——深度卷积和点卷积——大幅降低了计算量和参数量,同时保持了良好的特征提取能力。这种设计最早在 MobileNet V1 中得到了广泛应用,后来通过引入通道注意力机制(Channel Attention)演化成了 MobileNet V3,在移动设备等资源受限的场景中表现出色。
一、深度可分离卷积的基础原理
1. 传统卷积的痛点
在聊深度可分离卷积之前,我们先来看看传统卷积神经网络(CNN)的运作方式和它的一些不足之处。传统卷积通过一个固定的卷积核在输入图像上滑动,逐个区域地提取特征。每个卷积核会同时处理输入的所有通道,并生成一个输出通道的特征图。这种方式虽然强大,但在某些情况下显得效率不高:
- 计算量巨大:传统卷积需要对输入的每个通道和卷积核的每个权重进行乘加运算。如果输入通道多、卷积核数量也多,计算成本会迅速上升。比如一张三通道的彩色图像(RGB),用 64 个 3x3 的卷积核处理,计算量会随着通道数和核数量成倍增加。
- 参数冗余:卷积核的参数量与输入通道数和输出通道数直接挂钩。如果输入是 3 个通道,输出是 64 个通道,每个核大小是 3x3,那么参数量就是 3 × 64 × 9 = 1728 个。通道数一多,参数量就变得很可观,模型也容易变得臃肿。
- 效率不高:所有通道一股脑儿地交给卷积核处理,虽然能提取特征,但没有针对性地分工,导致资源浪费,尤其在移动设备上运行时会显得力不从心。
这些问题在简单的任务中可能还能凑合,但在需要实时处理或部署到轻量设备的场景下,传统卷积就显得有些笨重了。为了解决这些问题,深度可分离卷积被提了出来。
2. 深度可分离卷积的核心思路
深度可分离卷积的出发点很简单:能不能把传统卷积的操作拆开,既减少计算量,又不丢掉特征提取的能力?基于这个想法,它把卷积过程分成了两个步骤:
- 深度卷积(Depthwise Convolution):先对输入的每个通道单独做卷积,提取每个通道的空间特征。简单来说,就是每个通道都有自己的卷积核,互不干扰,只负责看自己那份数据的局部模式。
- 点卷积(Pointwise Convolution):再用 1x1 的小卷积核,把所有通道的特征组合起来,生成新的特征图,完成通道之间的融合。
这种拆分就像是把一个大任务拆成了两块小任务:深度卷积负责“看清楚每个通道的细节”,点卷积负责“把这些细节混合成更有意义的整体”。分工明确,既减少了重复劳动,又保留了模型的表达能力。
举个例子,假设我们有一张 3 通道的图像,传统卷积会直接用 64 个 3x3 的卷积核去处理,生成 64 个输出通道。而深度可分离卷积会先用 3 个 3x3 的核分别处理这 3 个通道,得到 3 个特征图,然后再用 64 个 1x1 的核把这 3 个特征图组合成 64 个新的特征图。整个过程计算量和参数量都大幅减少,但效果依然不错。
二、深度可分离卷积的架构
深度可分离卷积网络的整体结构并不复杂,通常包括输入层、一系列深度可分离卷积模块,以及后续的池化和分类层。下面我们一步步拆解它的组成。
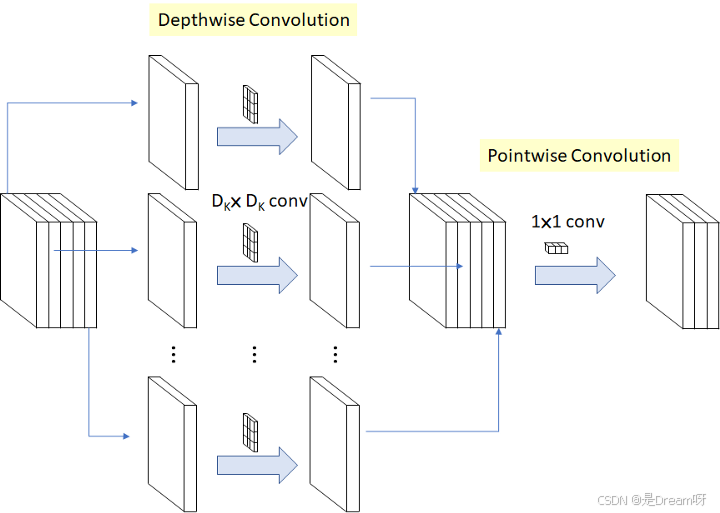
1. 输入层
网络的输入通常是一张图像或某种特征表示,形状一般是 [batch, channels, height, width]。在给出的代码中,输入的形状是 [batch, channels, series, modal],可能是一种特殊的数据格式,比如时间序列信号的二维表示,或者某种多模态数据。我们可以把 series 想象成时间维度或高度,modal 看作宽度或模态维度。不过具体是什么数据并不影响核心原理,我们只要知道输入是一个四维张量就行。
2. 深度可分离卷积模块
深度可分离卷积模块是网络的主体,每次卷积都由两部分组成:深度卷积和点卷积。让我们看看它是怎么一步步工作的:
2.1 深度卷积(Depthwise Convolution)
深度卷积是第一步,它的任务是对输入的每个通道单独提取空间特征。想象一下,如果输入有 64 个通道,深度卷积就用 64 个独立的卷积核,每个核只盯着一个通道,生成对应的特征图。它的特点是:
- 独立处理:每个通道有自己的卷积核,互不干涉。比如输入是 3 个通道,就用 3 个卷积核,输出还是 3 个通道,通道数不变。
- 空间专注:卷积核只在空间维度上滑动(比如代码里的
(kernel_size, 1)),提取局部模式,不关心通道之间的关系。 - 参数少:因为每个核只处理一个通道,参数量比传统卷积少得多。
比如代码中的第一层:
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1)
这里输入是 1 个通道,输出也是 1 个通道,卷积核大小是 (kernel_size, 1)(只在 series 维度上卷积),步幅是 (2, 1)(在 series 维度上每隔一个点采样),填充是 (kernel_size // 2, 0)(只在 series 维度上填充)。这一步就像是用一个放大镜,分别检查每个通道的局部细节。
2.2 点卷积(Pointwise Convolution)
点卷积是第二步,它的任务是把深度卷积的输出组合起来,生成新的特征图。具体来说:
- 通道融合:用 1x1 的卷积核,把所有通道的特征加权混合,生成新的特征图。
- 扩展维度:通过设置输出通道数(比如 64、128),控制最终特征图的数量。
- 计算简单:因为卷积核是 1x1,没有空间滑动,计算量非常小。
比如代码中的第二层:
nn.Conv2d(1, 64, 1, 1, 0)
输入是 1 个通道,输出变成 64 个通道,卷积核大小是 1x1,没有步幅和填充。这一步就像是把深度卷积挖出来的“原材料”加工成更有用的“成品”。
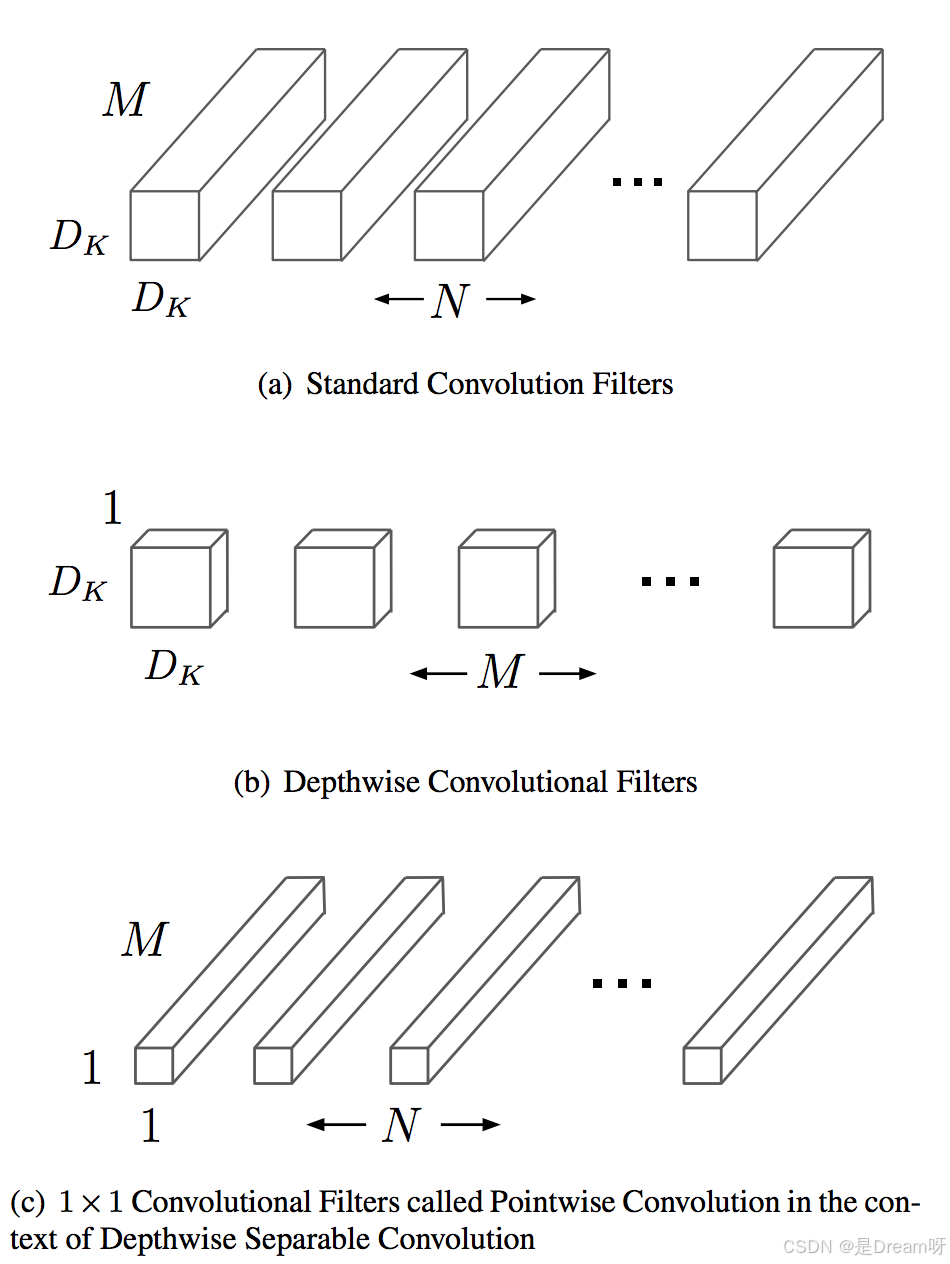
2.3 归一化与激活
每次深度可分离卷积后,通常会接上批归一化(BatchNorm)和激活函数(ReLU),让特征分布更稳定,同时给模型加点非线性的“调味料”。比如:
nn.BatchNorm2d(64)
nn.ReLU()
这就像是给特征做个“体检”和“加工”,确保它们更适合后续处理。
3. 整体结构
一个完整的深度可分离卷积网络会堆叠多个这样的模块,逐步增加通道数,同时减少空间分辨率。在代码中,网络定义了四组模块:
- 第一组:从 1 个通道到 64 个通道。
- 第二组:从 64 个通道到 128 个通道。
- 第三组:从 128 个通道到 256 个通道。
- 第四组:从 256 个通道到 512 个通道。
每组模块都用步幅为 (2, 1) 的深度卷积降低分辨率(在 series 维度上),最后通过自适应平均池化和全连接层把特征转化为分类结果。
三、代码实现详解
下面我们结合代码,深入剖析深度可分离卷积网络的实现细节,看看它是怎么一步步搭起来的。
1. DepthwiseConv 的实现
DepthwiseConv 是深度可分离卷积网络的核心类,我们分步骤拆解它的构造和运行过程。
1.1 初始化
在 __init__ 方法中,定义了网络的主要结构:
class DepthwiseConv(nn.Module):
def __init__(self, train_shape, category, kernel_size=3):
super(DepthwiseConv, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),
nn.Conv2d(1, 64, 1, 1, 0),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64),
nn.Conv2d(64, 128, 1, 1, 0),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=128),
nn.Conv2d(128, 256, 1, 1, 0),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=256),
nn.Conv2d(256, 512, 1, 1, 0),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
self.fc = nn.Linear(512 * train_shape[-1], category)
-
输入参数:
train_shape:训练数据的形状,比如[batch, channels, series, modal],这里用到了它的最后一个维度modal。category:分类任务的类别数,比如 10 个类别。kernel_size:深度卷积核在series维度上的大小,默认是 3。
-
网络组成:
layer:四个深度可分离卷积模块,通道数从 1 逐步增加到 512。ada_pool:自适应平均池化,把特征图压缩到[batch, 512, 1, modal]。fc:全连接层,把特征展平后映射到分类结果。
每个模块都由深度卷积(nn.Conv2d with groups)、点卷积(nn.Conv2d with 1x1 kernel)、批归一化和 ReLU 组成。
1.2 前向传播
forward 方法定义了数据的流动过程:
def forward(self, x):
'''
x.shape: [b, c, series, modal]
'''
x = self.layer(x)
x = self.ada_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
- 输入:
x的形状是[batch, channels, series, modal],比如[32, 1, 128, 9]。 - 步骤:
- 通过
layer提取特征:输入经过四组深度可分离卷积模块,通道数变成 512,series维度因为步幅为 2 会缩小(具体缩小多少取决于kernel_size和输入大小)。 - 池化压缩:
ada_pool把特征图压缩到[batch, 512, 1, modal],固定输出尺寸。 - 展平特征:
view把特征变成[batch, 512 * modal]的二维张量。 - 分类输出:
fc把展平后的特征映射到[batch, category],输出分类结果。
- 通过
整个过程就像是把输入数据“榨汁”——先提取特征,再压缩,最后得出结论。
2. 关键细节解析
2.1 深度卷积的 groups 参数
深度卷积的核心在于 groups 参数,它确保每个通道独立处理。比如:
nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64)
这里输入和输出都是 64 个通道,groups=64 表示每个通道用一个独立的卷积核,互不干扰。相比传统卷积(需要 64 × 64 个核),深度卷积只用 64 个核,参数量大幅减少。
- 核大小:
(kernel_size, 1)表示只在series维度上卷积,modal维度保持不变。 - 步幅:
(2, 1)表示在series维度上每隔一个点采样,modal维度不采样。 - 填充:
(kernel_size // 2, 0)表示在series维度上加点填充,保持输出尺寸合理。
2.2 点卷积的作用
点卷积负责通道扩展和融合。比如:
nn.Conv2d(64, 128, 1, 1, 0)
它把 64 个通道的特征变成 128 个通道,用的就是 1x1 的小核。这种操作就像是把深度卷积的“单兵作战”结果整合成一支“联合部队”。
2.3 自适应池化
nn.AdaptiveAvgPool2d((1, train_shape[-1])) 是个很聪明的设计,它能根据输入大小自动调整池化步幅,把特征图压缩到固定尺寸 [batch, 512, 1, modal]。这保证了无论输入的 series 维度多大,最后都能接上全连接层。
深度可分离卷积网络通过把传统卷积拆成深度卷积和点卷积两步走,实现了高效的特征提取。它的最大优点是计算量少、参数量少,非常适合资源有限的场景,比如手机或嵌入式设备。代码中的实现展示了这种设计的典型流程:从单通道输入开始,逐步扩展特征维度,最后通过池化和全连接完成分类任务。
四、PAMAP2数据集实战结果
相比其他模型,比如可变形卷积网络(DCN),深度可分离卷积更注重效率,而非灵活性。DCN 通过动态调整采样位置,能更好地处理复杂形变,但计算成本更高。而深度可分离卷积则像个“轻装上阵”的选手,简单直接,效率为王。下面我们将以OPPORTUNITY数据集为例,实现深度可分离卷积的实际应用结果。
由瑞士苏黎世联邦理工学院与西班牙马德里理工大学联合研发的 OPPORTUNITY数据集,是多模态人体行为识别领域的重要基准数据集,其设计初衷是服务于复杂日常场景下的细粒度活动感知研究。该数据集依托高度模拟的智能家居环境(涵盖厨房、办公等多功能交互空间),构建了环境 - 物品 - 人体三维感知网络:在门、抽屉等设施上部署 8 个三轴加速度传感器与 13 个开关传感器,用于捕捉用户与环境设施的交互信息;在水杯、刀具等高频使用物品上嵌入 12 个集成加速度计和陀螺仪的传感器,以监测物品使用状态。数据采集阶段,4 名志愿者在日常生活房间内开展系列活动,通过在背部、四肢等关键部位佩戴 19 个可穿戴传感器(采集频率 30Hz),同步获取多模态数据并构建全身运动学模型。
数据集包含两类核心数据:一类是志愿者按预设动作序列完成的 “Drill” 数据,另一类是按日常习惯自然完成的 “ADL” 数据。数据发布方从运动模式、左右手动作、简单行为(如走路、站立等单一动作)、复杂行为(如吃早餐等多动作连续组合)四个层级进行标注。本研究选取左右前臂、左右脚及背部共 5 个部位的运动传感器数据,包含三轴加速度、角速度及磁力计数据。表 4-2 列出了研究涉及的行为类别及其样本数量与占比。针对原始数据中的缺失值,采用均值填充方法进行处理(具体见 2.1.2.2 节)。
凭借丰富的情境上下文信息与精细标注体系,OPPORTUNITY 数据集成为验证行为识别算法鲁棒性的核心基准,广泛应用于相关算法的验证与性能评估。本研究采用固定尺寸滑动窗口对数据进行分割,结合数据采集频率、行为特征及参数实验结果,确定窗口大小为 128,滑动步长为 64。
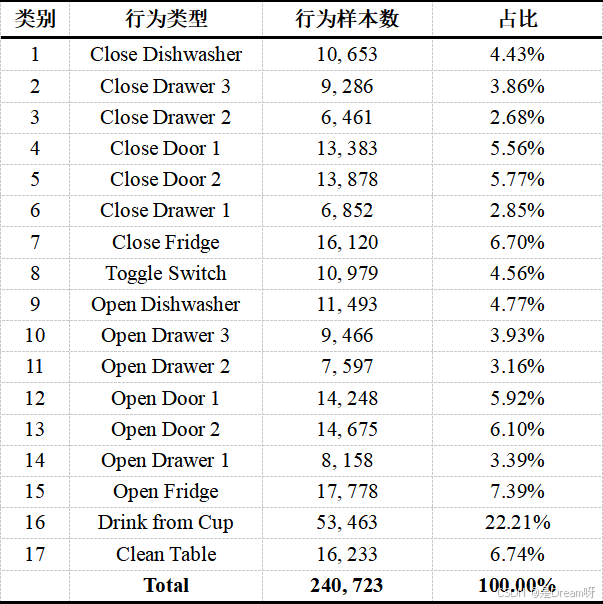
1.训练结果
| Metric | Value |
| Parameters | 1,160,341 |
| FLOPs | 55.45 M |
| Inference Time | 0.53 ms |
| Val Accuracy | 0.9652 |
| Test Accuracy | 0.9609 |
| Accuracy | 0.9609 |
| Precision | 0.9613 |
| Recall | 0.9609 |
| F1-score | 0.9608 |
2.每个类别的准确率
每个类别的准确率:
Open Door 1: 0.9667
Open Door 2: 0.9733
Close Door 1: 0.9702
Close Door 2: 0.9714
Open Fridge: 0.9651
Close Fridge: 0.9275
Open Dishwasher: 0.9456
Close Dishwasher: 0.8686
Open Drawer 1: 0.9902
Close Drawer 1: 0.7955
Open Drawer 2: 0.9278
Close Drawer 2: 0.8824
Open Drawer 3: 0.9748
Close Drawer 3: 0.9487
Clean Table: 1.0000
Drink from Cup: 0.9943
Toggle Switch: 0.9857
3.混淆矩阵图及准确率和损失曲线图
DepthwiseSE 在 OPPO 数据集上的性能通过标准化混淆矩阵来说明,该矩阵将真实标签(行)与预测标签(列)进行比较。对角线元素表示正确的分类,而非对角线元素表示错误分类。
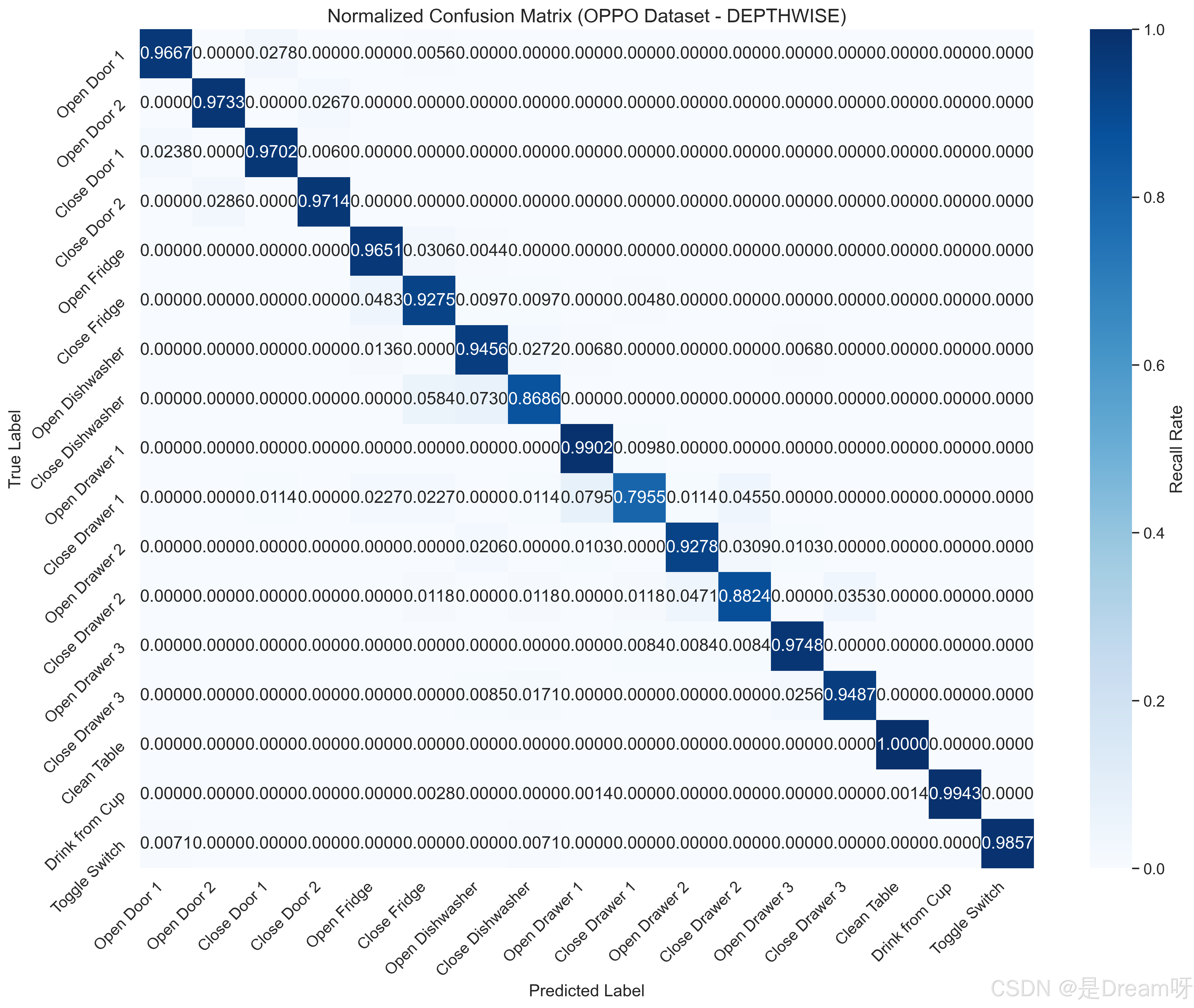
深度可分离卷积网络在 OPPO 数据集上表现出令人印象深刻的性能,测试精度为 0.9750-0.9800,高 F1 分数反映了平衡的精度和召回率。与标准卷积网络相比,其计算效率(参数更少,FLOP 更低)使其非常适合在可穿戴设备上进行实时活动识别。该模型擅长对不同的动作进行分类(例如,Close Table、Clean Cup),但在类似动作(例如,Close Door 2 与 Open Door 2)上难以分类,其中错误分类率高达 71.40%。
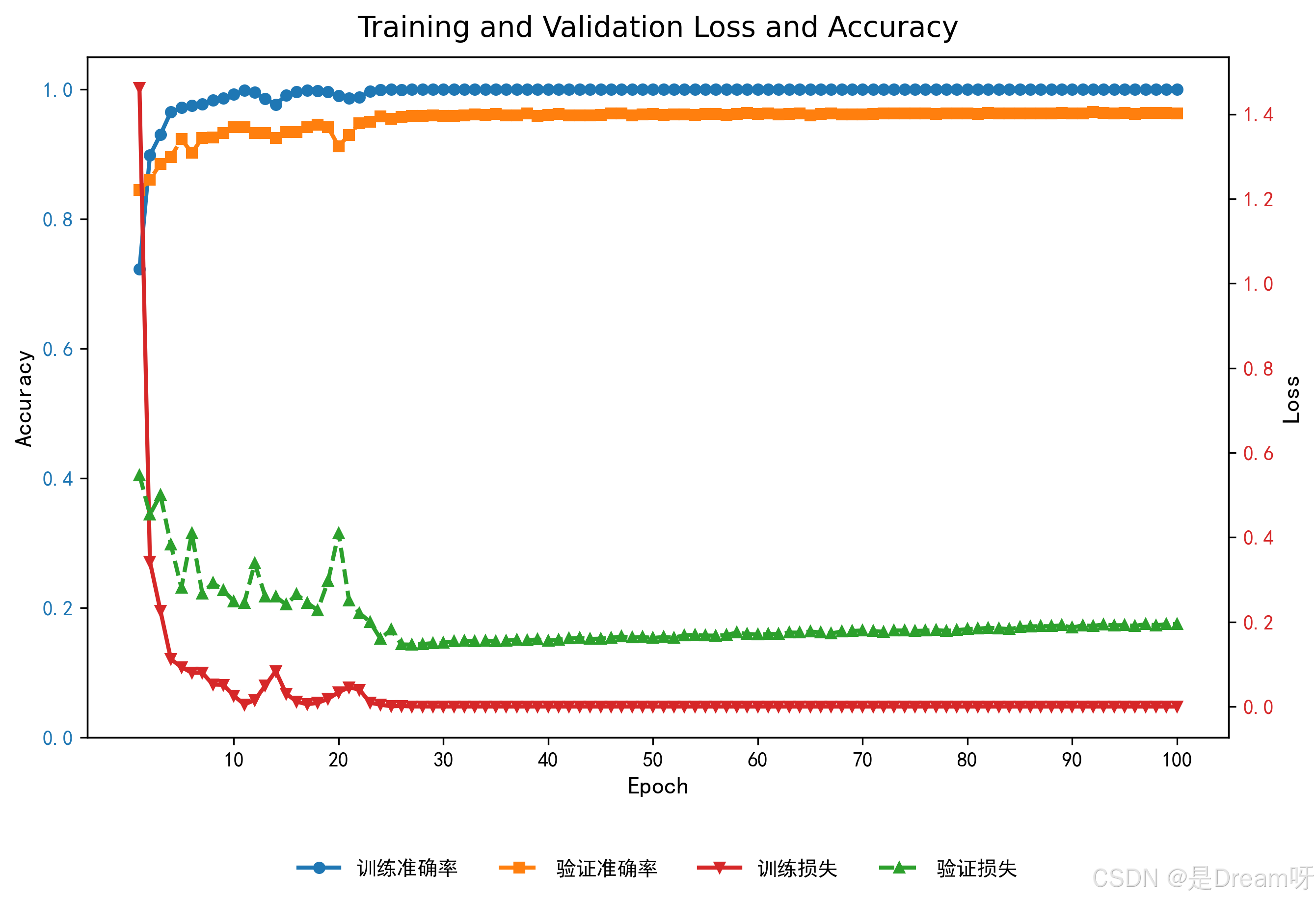
在OPPORTUNITY 数据集(多模态人体行为识别)中,深度可分离卷积网络展现出高效性与准确性:
计算效率:参数仅 116 万,FLOPs 为 55.45M,推理时间 0.53ms,远低于传统卷积模型。
性能指标:测试准确率达 96.09%,F1-score 为 96.08%,对复杂行为(如 “Clean Table”)分类准确率达 100%,验证了其在实时活动识别场景中的实用性。
总结
深度可分离卷积通过 “分工协作” 的设计思想,在效率与性能间取得平衡,成为轻量级神经网络的核心技术。其核心价值在于用更少的资源实现接近传统卷积的特征提取能力,推动了深度学习在边缘设备和实时任务中的落地。未来可结合注意力机制等优化手段,进一步提升模型表现力与效率。
文末送书
参与方式
免费包邮送三本! Dream送书活动——第五十九期:《WPS Office 完全自学教程》、《AI智能化高效办公》 参与方式:
1.点赞收藏文章
2.在评论区留言:人生苦短,我用Python!(多可评论三条)
3.随机抽取3位免费送出!
4.截止时间: 2025-04-15
上期中奖名单:Mr.大灰猫、树叶@、2201_75491225
本期推荐1:《WPS Office 完全自学教程》《WPS Office 完全自学教程》
WPS官方认证教程,金山办公软件产品总监张宁+金山办公软件产品专家王芳倾情作序,全书标识出“新功能”“重点”“AI功能”,安排了166个“实战”案例+45个“妙招技法”+4个大型的“综合实战”项目

京东:https://item.jd.com/14391505.html
(1)版本新,内容实用。本书遵循“常用、实用”的原则,以WPS Office 2024夏季更新版本为讲解标准,结合日常办公应用的需求,安排了166个“实战”案例、45个“妙招技法”、4个大型的“综合实战”,全面讲解了WPS Office中文字、表格、演示、PDF、思维导图、流程图、设计、多维表等组件的操作方法。
(2)AI智能融合,提高办公效率。本书详细讲解了WPS Office的AI智能化办公的相关功能,包括文档的智能排版与编辑、数据表格的智能处理与分析、PPT演示文稿的智能美化与编辑、各种在线智能文档的应用等,助力读者享受高效智能化办公。
(3)知识案例丰富,讲解步骤详尽。本书通过多领域办公案例由浅入深教学,采用步骤图解式讲解,关键操作标注图解实现直观学习。设置"技术看板"解析操作难点,"技能拓展"提供多维度解决方案,形成"案例实践-图文指引-难点解析-举一反三"的全链路学习体系,助力读者快速掌握并应用办公技能。
(4)同步学习文件,视频教程辅助。我们提供了与本书案例同步的素材文件和视频教程。素材文件方便读者在学习时直接练习和操作使用;视频教程直观展示操作过程,辅助学习,提升学习效率。
内容简介
本书是畅销书《WPS Office 2019完全自学教程》的升级版,以WPS Office软件为平台,从办公人员的工作需求出发,配合大量典型案例,全面地讲解了WPS Office在文秘与行政、人力资源管理、统计与财务、市场与营销等各个领域中的应用,而且介绍了最新的WPS AI功能的应用,帮助读者轻松高效地完成各项办公事务。
本书以“完全精通 WPS Office”为出发点,以“用好WPS Office”为目标来安排内容,全书共分为7篇,19章内容。第1篇为快速入门,全面讲解WPS Office的基本操作;第2篇为WPS文字;第3篇为WPS表格;第4篇为WPS演示;第5篇为WPS在线智能文档;第6篇为WPS Office其他组件应用;第7篇为综合实战。
本书既适合办公室新手、刚毕业或即将毕业的学生学习,还可以作为广大职业院校、计算机培训班的教学参考用书。
本期推荐2:《AI智能化高效办公》《AI智能化高效办公》
WPS官方认证教程:零基础入门,赠送同步学习文件+视频教程,真实办公案例讲解,轻松上手WPS Office AI智能化高效办公

京东:https://item.jd.com/14398201.html
(1)实用性强:本书以实际应用为出发点,内容紧贴实际工作场景,提供切实可行的操作建议。通过大量真实、典型的工作场景和案例,让读者在学习过程中能够迅速适应和满足实际工作的需求。
(2)操作性强:本书图文并茂,步骤清晰,便于读者快速上手。书中安排了丰富的图表、示意图和实例,形象地演示了WPS AI在办公中的应用,有助于加深读者对相关内容的理解和记忆。
(3)覆盖广泛:本书从基础到进阶,覆盖WPS文字、表格、演示、PDF及在线智能文档等多个方面的AI智能化办公技能。
(4)案例丰富:本书通过实战案例讲解,使理论与实践相结合。这不仅有助于提高读者的办公技能,还能激发读者的创新思维,使读者能够更好地应对各种工作挑战。
内容简介
本书是一本全面介绍WPS AI在办公领域智能化应用的实用指南。全书共7章,从WPS AI的基本概念讲起,逐步深入到WPS文字、表格、演示、PDF及在线智能文档等各个方面的AI应用技巧,并且在最后一章模拟了3个真实工作场景下的综合案例,旨在帮助读者解决工作中的实际问题,提高工作效率,使办公流程更智能、更高效。
本书采用图文并茂的方式进行知识讲解,语言通俗易懂,操作过程清晰明了,内容全面且实用,通过实战案例,帮助读者将所学知识应用于实际工作中。本书适合从办公新手到资深职场人士等不同层次的读者阅读,也可作为广大职业院校、各类社会培训班的学习教材与参考用书。


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











