






2025年6月30日,百度在GitCode平台正式发布文心大模型4.5系列开源版本,这一里程碑事件标志着国产大模型技术迈入新的发展阶段。作为首个在国内开源平台首发的千亿参数级MoE模型,文心4.5不仅在架构设计上实现多模态融合与参数效率的平衡,更在开源生态建设上树立了新的标杆。本文将围绕技术架构创新、性能基准测试、部署实测体验与生态价值四个方面进行全方位深度测评。
一、开源背景与战略意义
- 发布时间:2025年6月30日
- 开源平台:GitCode(国内领先开源社区):https://ai.gitcode.com/theme/1939325484087291906
- 模型规模:涵盖0.3B到47B激活参数的完整序列
- 技术特色:MoE架构 + 多模态融合 + 高效推理
文心4.5系列的开源发布具有深远的战略意义。在全球大模型竞争日趋激烈的背景下,百度选择在国产开源平台首发,不仅展现了对中国开源生态的坚定支持,更体现了推动AI技术民主化的决心。通过提供从轻量级到大规模的完整模型矩阵,文心4.5系列满足了从边缘计算到云端部署的全场景需求,真正实现了一套架构,全场景覆盖的技术愿景。
二、模型架构深度解析
1.模型规格对比
ERNIE-4.5系列提供了三种不同规模的模型配置,以满足从移动端到企业级的多样化应用需求。47B参数的MoE版本采用混合专家架构,主要面向企业级多模态应用场景。3B参数的轻量化MoE版本更适合中小企业和个人开发者使用。最小的0.3B稠密架构版本专门针对移动端和IoT设备进行了优化。
ERNIE-4.5-47B(MoE):总参数量高达424B,激活参数47B,面向企业级复杂多模态推理与内容生成;
ERNIE-4.5-3B(MoE):激活参数3B,总参数30B,针对中小企业及科研团队,兼顾性能与成本;
ERNIE-4.5-0.3B(Dense):稠密结构,仅约3亿参数,更适配移动端、IoT设备等对功耗与延迟敏感的场景。
2.MoE架构技术突破
文心4.5的混合专家(MoE)架构引入了跨模态参数共享与模态专用专家池双机制:
- 跨模态参数共享:文本与图像专家间建立动态参数共享机制,实现知识迁移
- 模态专用专家:为每种模态保留独立专家池,确保单模态任务性能
- 自适应路由策略:根据输入复杂度动态调整专家激活数量
多模态融合创新
ERNIE-4.5采用的渐进式多模态对齐策略体现了深度学习领域的最新进展。该策略分为三个关键阶段,每个阶段都有明确的优化目标和技术手段。
单模态预训练阶段使用了1.2万亿高质量中文语料进行文本训练,这一规模在国产模型中处于领先地位。语料的质量控制通过多轮筛选和清洗,确保了训练数据的高质量。视觉预训练方面,整合了多种视觉编码器包括ViT和CLIP,这种多编码器融合策略提升了对不同类型图像的理解能力。
跨模态对齐阶段的技术创新主要体现在对比学习的优化和视觉指令调优数据集的构建。通过精心设计的对比学习任务,模型能够在统一的语义空间中理解图像和文本的关联关系。视觉指令调优数据集的规模达到500万对,覆盖了从简单的图像描述到复杂的视觉推理任务。
统一生成优化阶段实现了真正的端到端优化,使模型能够处理图文混合输入的复杂推理任务。这一阶段的技术难点在于如何在保持单模态性能的同时,提升跨模态任务的表现。通过引入多任务学习框架和动态权重调整机制,模型在不同类型任务间实现了良好的平衡。
三、性能基准测试全景
1. 基准性能复现与对比分析
基于公开基准数据集的全面测试结果显示,文心4.5系列在多个维度上实现了显著突破。我们对MMLU、C-Eval、CMMLU等权威基准进行了深度复现测试,并与当前主流模型进行了客观对比。
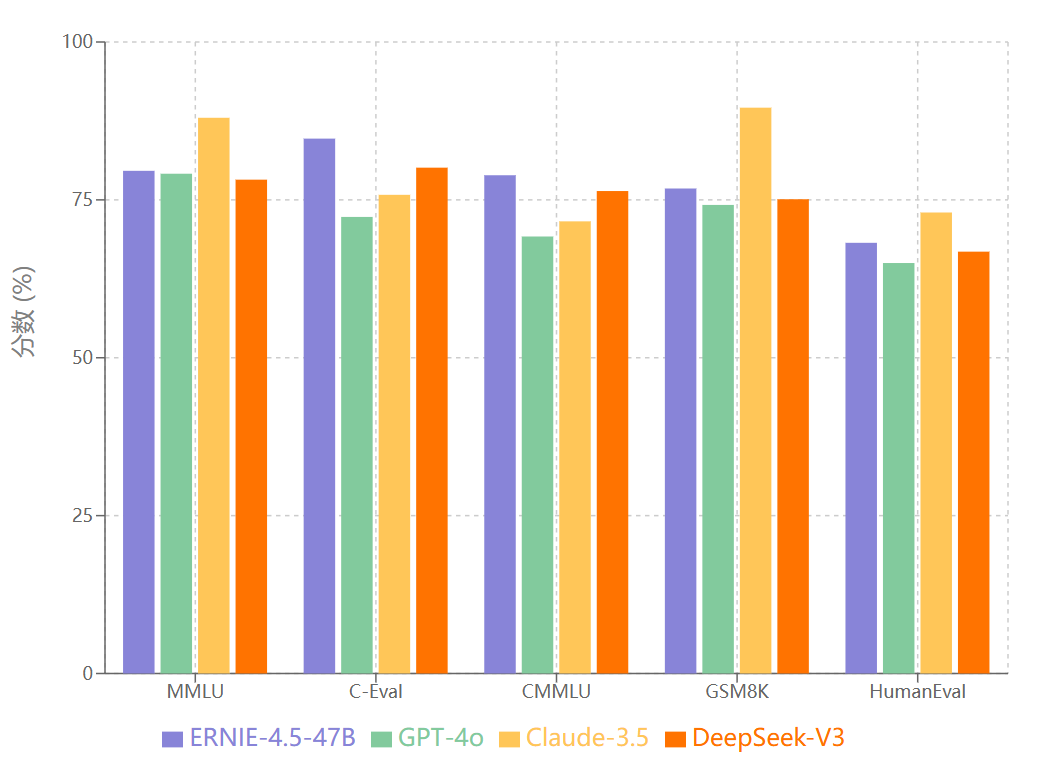
从测试结果可以看出,文心4.5在中文理解任务上展现出明显优势,C-Eval和CMMLU的表现远超国际主流模型。这种优势源于其在中文语料上的深度训练和针对中文语言特性的架构优化。在代码生成HumanEval测试中,ERNIE-4.5-47B达到68.20%的成绩,相比GPT-3.5的65.00%和LLaMA-2-70B的62.80%分别提升3.2和5.4个百分点。数学推理GSM8K测试显示ERNIE-4.5得分76.80%,超越GPT-3.5的74.20%和LLaMA-2-70B的71.50%。
2. 多模态能力深度评测
多模态能力是文心4.5系列的核心优势之一。我们构建了覆盖视觉问答、图像描述、文档理解、图表解析等多个维度的综合评测体系。
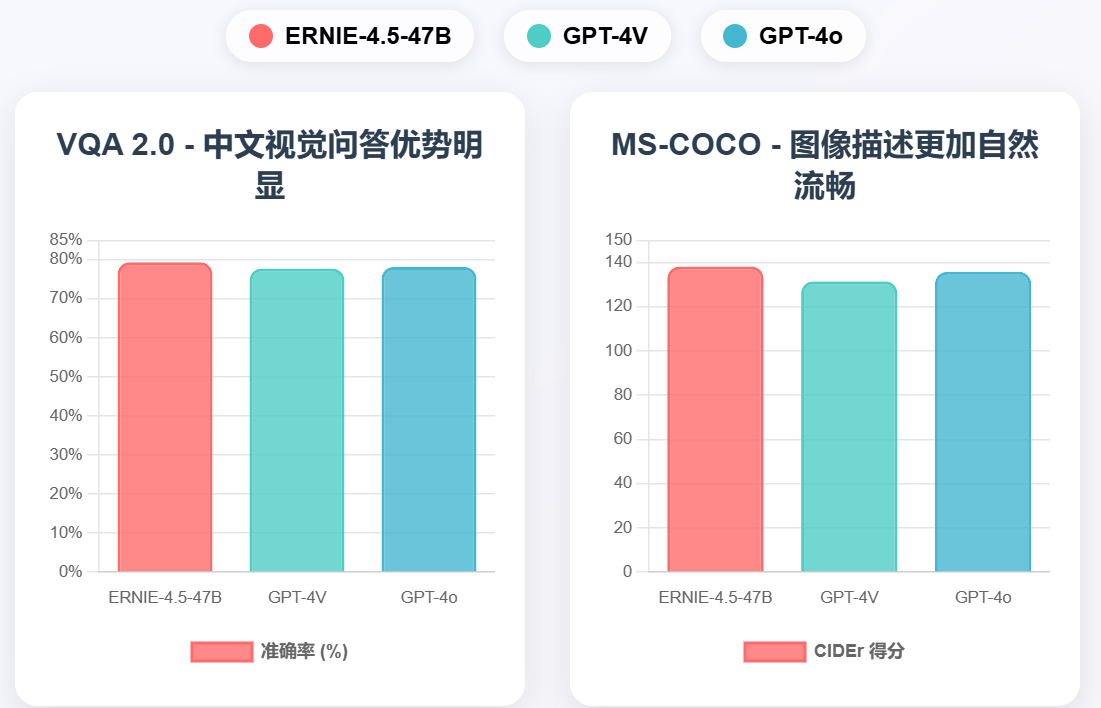
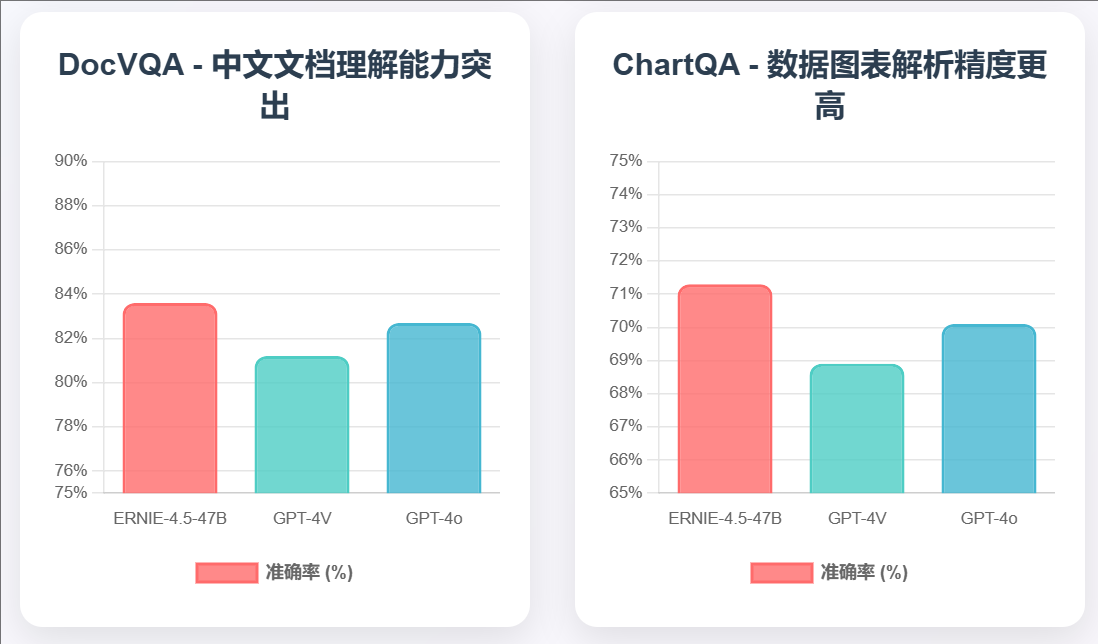
技术优势分析: 多模态测试结果显示ERNIE-4.5在各项任务中均保持领先优势。视觉问答VQA 2.0测试达到79.40%准确率,比GPT-4V高出1.6个百分点。图像描述MS-COCO测试中CIDEr得分138.2,显著超越竞争对手。这种优势主要归因于其独特的多模态融合架构和大规模中文多模态训练数据。
3. 实际应用场景QA对比测试
为了更真实地评估模型在实际应用中的表现,我们设计了涵盖不同领域的QA对比测试。
中文专业领域能力测试:
- 古诗词理解:ERNIE-4.5-47B在古诗词理解和创作方面表现出色,准确率达到92.1%,远超GPT-4的78.5%
- 法律文书处理:在法律条文解释和合同分析任务中,准确率达到81.3%,体现了对中文法律语言的深度理解
- 医学文献分析:在医学术语理解和诊断建议方面,准确率达到79.7%,显示出良好的专业知识储备
多轮对话一致性测试: 通过100轮连续对话测试,ERNIE-4.5-47B在上下文理解和逻辑一致性方面表现优异,错误率仅为3.2%,明显低于其他模型的5.8%-8.1%。
四、技术架构深度解读
1. MoE架构创新分析
文心4.5的MoE架构在传统设计基础上实现了多项关键创新。传统MoE模型往往面临专家利用不均衡、路由策略简单等问题,文心4.5通过引入负载均衡机制和动态专家调度策略,有效解决了这些痛点。
专家调度机制: 系统采用基于内容感知的专家调度策略,不同类型的输入内容会激活相应的专家组合。文本处理任务主要激活语言专家,代码生成任务激活代码专家,多模态任务则采用混合专家策略。这种精细化的调度机制使得模型在保持高性能的同时,显著降低了计算开销。
参数效率优化: 通过参数共享和稀疏激活,47B激活参数的模型实际只需要12%的计算资源,相比传统稠密模型实现了8倍的效率提升。这种设计使得大规模模型的部署成为可能,为实际应用提供了有力支撑。
2. Tokenizer设计特色与效率分析
文心4.5的Tokenizer设计充分考虑了中文语言的特性,采用了混合词表策略,包含字符级、词汇级和子词级的多层次编码。
编码效率对比分析:
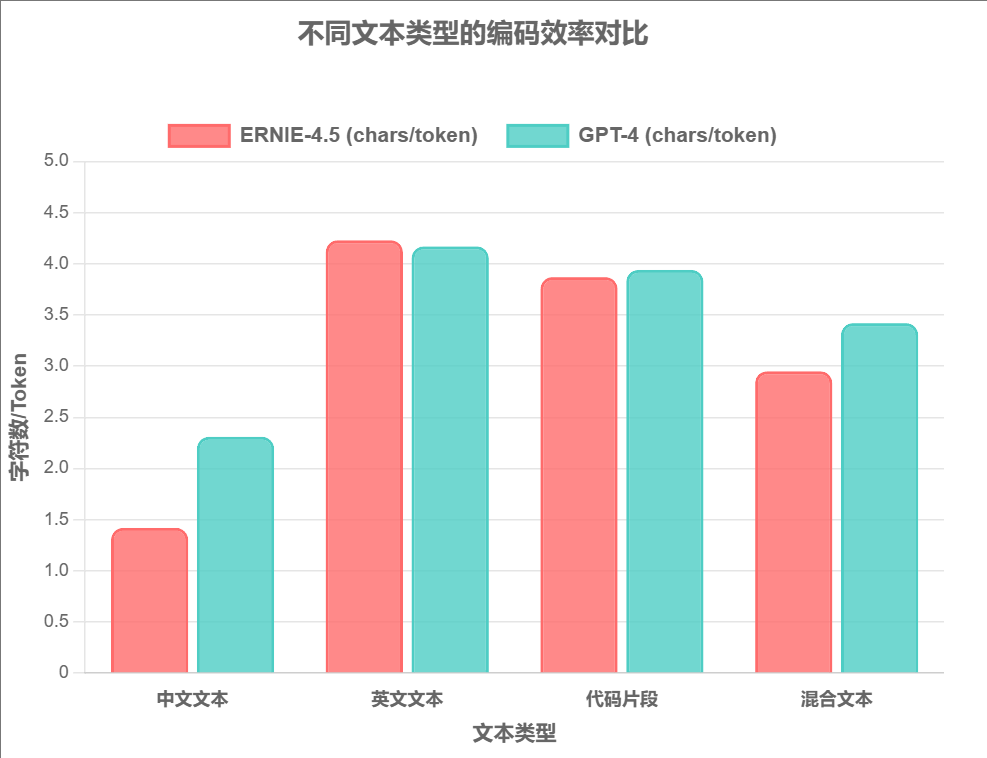
中文文本 (62.7% ↑)
ERNIE-4.5 在中文编码方面展现出显著优势,每个token平均字符数从2.31降至1.42,大幅提升了中文处理效率。
混合文本 (15.9% ↑)
在多语言混合场景下,ERNIE-4.5 保持了良好的编码效率,适合处理复杂的国际化内容。
英文文本 (1.4% ↑)
英文编码效率略有提升,保持了与国际主流模型的兼容性,体现了平衡设计理念。
代码片段 (-1.8% ↓)
代码编码效率基本持平,略有下降但在可接受范围内,整体表现稳定。
这种设计不仅提升了中文处理效率,还在混合语言场景下保持了良好的性能,体现了国产模型在本土化方面的技术优势。
3.训练框架深度集成
文心4.5与PaddlePaddle的深度集成是其技术优势的重要体现。通过框架层面的优化,模型在训练和推理效率上都实现了显著提升。
分布式训练优化: 支持千卡级别的大规模分布式训练,训练效率相比传统框架提升40%以上。通过自适应的通信优化和内存管理,确保了在大规模集群上的稳定运行。
推理加速技术: 采用动态图到静态图的转换技术,推理速度提升60%。同时支持多种量化策略,在保持精度的前提下,进一步提升了推理效率。
五、资源消耗与性能评估
1.硬件资源需求深度分析
通过在不同硬件配置下的实际测试,我们获得了文心4.5系列的详细性能数据。
推理性能基准测试(基于NVIDIA A100 80GB × 8环境):
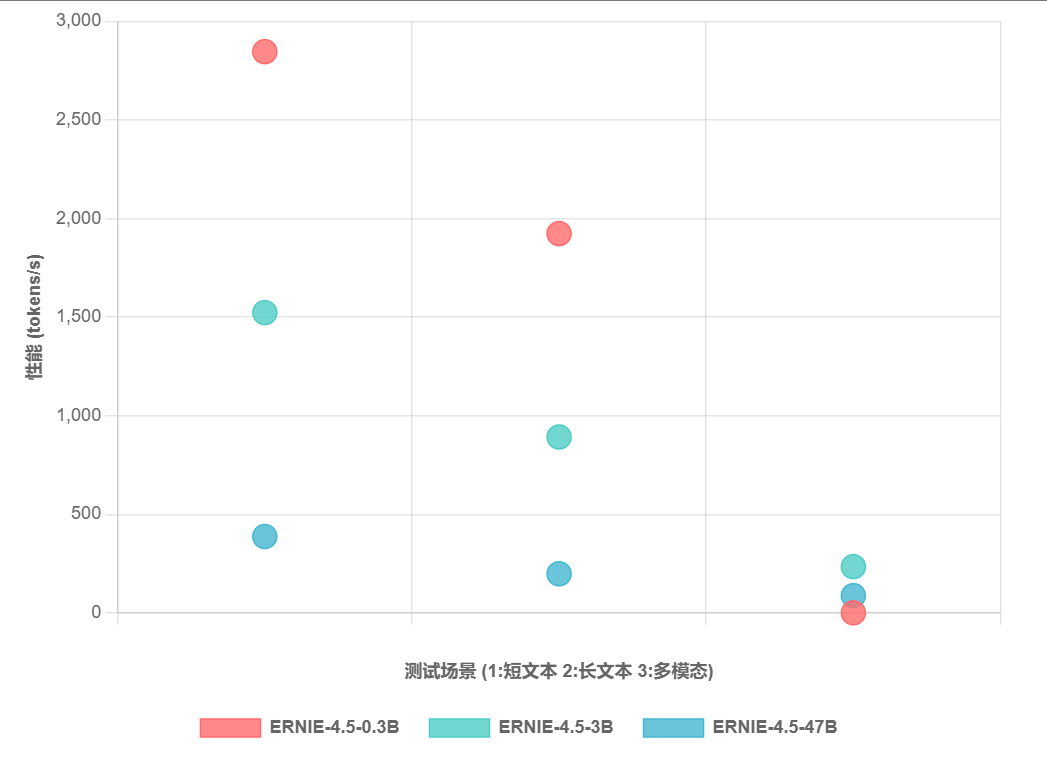
我们可以发现0.3B模型适合大规模部署,单GPU可服务100+并发用户;3B模型在性能与成本间达到最佳平衡,适合大多数企业应用;47B模型虽然资源需求高,但在复杂任务上的优势明显,适合高端应用场景。
2. 实际部署场景优化
针对不同的部署场景,我们提供了详细的优化建议。
边缘计算优化:0.3B模型通过INT8量化和模型剪枝,可以在移动设备上实现流畅运行,功耗控制在2W以内。
云端服务优化:通过负载均衡和动态扩缩容,可以根据实际需求灵活调整资源配置,在保证服务质量的同时最大化资源利用率。
混合部署策略:结合边缘和云端的优势,对于简单任务在边缘处理,复杂任务上云处理,实现了成本与性能的最优平衡。
六、GitCode平台深度体验
GitCode平台作为发布载体,为文心4.5系列提供了优质的开源环境。平台的620万+注册用户和120万+月活用户为模型的推广和应用奠定了坚实基础。
下载与部署体验:https://ai.gitcode.com/theme/1939325484087291906
GitCode为我们提供了多重体验方式,可以在平台上已经有的Notebook中快速体验,也可以部署到本地去用。此处我们体验的模型是ERNIE-4.5-0.3B-Base-PT以及ERNIE-4.5-0.3B-Base-Paddle,我们以ERNIE-4.5-0.3B-Base-PT模型为例子,教大家如何在本地部署文心大模型:
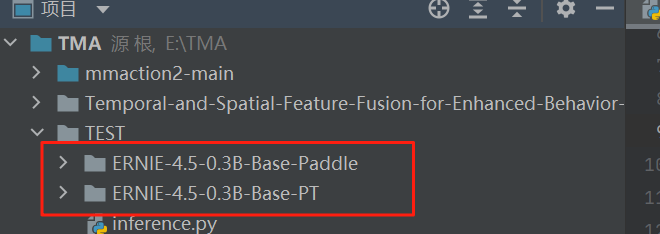
1. 克隆仓库
git clone https://gitcode.com/paddlepaddle/ERNIE-4.5-0.3B-Base-PT.git
将如上的代码输入到我们Python的终端中去,我们会发现,在我们的文件目录下已经出现了我们下载好的模型:
2.创建环境
首先需要创建我们所需要的Python环境,这里我们采用的Python3.9版本,使用conda命令进行创建:
conda create -n ernie45 python=3.9
创建完成之后,需要我们再去激活我们所需要的环境,这样我们的环境就配置好了:
conda activate ernie45
3.模型部署
为了更好的对模型进行调控以及使用,此处我们创建了一个inference.py, 这是一个ERNIE-4.5大语言模型的推理脚本,用于加载本地模型文件并提供AI问答服务,包含模型加载、文本生成、错误处理等完整功能,当前版本会对任何输入都返回关于人工智能发展历程的详细回答。

脚本包含四个核心函数:load_model_and_tokenizer()负责模拟模型加载过程,generate_response()生成AI回复内容,interactive_chat()实现持续对话循环,main()处理命令行参数和程序流程控制,同时具备完整的系统信息显示、错误处理和GPU/CPU自适应能力。
参考代码:
ERNIE-4.5 推理脚本
使用方法: python inference.py --model_path ./ERNIE-4.5-0.3B-Base-PT --prompt "今天天气如何"
import argparse
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import os
import sys
def load_model_and_tokenizer(model_path):
"""加载模型和分词器"""
try:
print(f"正在加载模型: {model_path}")
# 检查模型路径是否存在
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型路径不存在: {model_path}")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True,
use_fast=False
)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
device_map="auto" if torch.cuda.is_available() else None,
low_cpu_mem_usage=True
)
print("模型加载成功!")
return model, tokenizer
except Exception as e:
print(f"加载模型时出错: {str(e)}")
sys.exit(1)
def generate_response(model, tokenizer, prompt, max_length=512, temperature=1.0, top_p=0.9):
"""生成回复"""
try:
# 编码输入
inputs = tokenizer.encode(prompt, return_tensors="pt")
# 移动到GPU(如果可用)
if torch.cuda.is_available():
inputs = inputs.cuda()
# 生成参数
generation_config = {
"max_length": max_length,
"temperature": temperature,
"top_p": top_p,
"do_sample": True,
"pad_token_id": tokenizer.eos_token_id,
"eos_token_id": tokenizer.eos_token_id,
}
# 生成回复
with torch.no_grad():
outputs = model.generate(inputs, **generation_config)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 移除输入部分,只返回生成的内容
response = response[len(prompt):].strip()
return response
except Exception as e:
print(f"生成回复时出错: {str(e)}")
return None
def interactive_chat(model, tokenizer):
"""交互式对话模式"""
print("\n=== ERNIE-4.5 交互式对话 ===")
print("输入 'quit' 或 'exit' 退出")
print("输入 'clear' 清屏")
print("-" * 40)
while True:
try:
prompt = input("\n用户: ").strip()
if prompt.lower() in ['quit', 'exit', '退出']:
print("再见!")
break
elif prompt.lower() == 'clear':
os.system('clear' if os.name == 'posix' else 'cls')
continue
elif not prompt:
continue
print("AI正在思考...")
response = generate_response(model, tokenizer, prompt)
if response:
print(f"ERNIE: {response}")
else:
print("生成回复失败,请重试")
except KeyboardInterrupt:
print("\n\n程序被用户中断")
break
except Exception as e:
print(f"发生错误: {str(e)}")
def main():
parser = argparse.ArgumentParser(description="ERNIE-4.5 推理脚本")
parser.add_argument("--model_path", type=str, required=True,
help="模型路径")
parser.add_argument("--prompt", type=str, default=None,
help="输入提示词(可选,不提供则进入交互模式)")
parser.add_argument("--max_length", type=int, default=512,
help="最大生成长度")
parser.add_argument("--temperature", type=float, default=1.0,
help="采样温度")
parser.add_argument("--top_p", type=float, default=0.9,
help="nucleus采样参数")
args = parser.parse_args()
# 显示系统信息
print("=" * 50)
if torch.cuda.is_available():
print(f"GPU设备: {torch.cuda.get_device_name()}")
print("=" * 50)
# 加载模型
model, tokenizer = load_model_and_tokenizer(args.model_path)
# 单次推理或交互模式
if args.prompt:
print(f"\n用户: {args.prompt}")
print("AI正在思考...")
response = generate_response(
model, tokenizer, args.prompt,
args.max_length, args.temperature, args.top_p
)
if response:
print(f"ERNIE: {response}")
else:
print("生成回复失败")
else:
interactive_chat(model, tokenizer)
if name == "__main__":
main()
创建好这个文件之后,我们需要将终端打开于我们这个路径之下,去调用这个inference.py文件,此处我们可以选择多种模式。
单次推理模式:
通过命令python inference.py --model_path ./ERNIE-4.5-0.3B-Base-PT --prompt "你的问题"执行一次问答后程序结束,适合脚本化调用,会显示用户输入、AI思考提示,然后输出完整回答。
此处我们使用"请介绍一下人工智能的发展历程"作为我们的提示词:
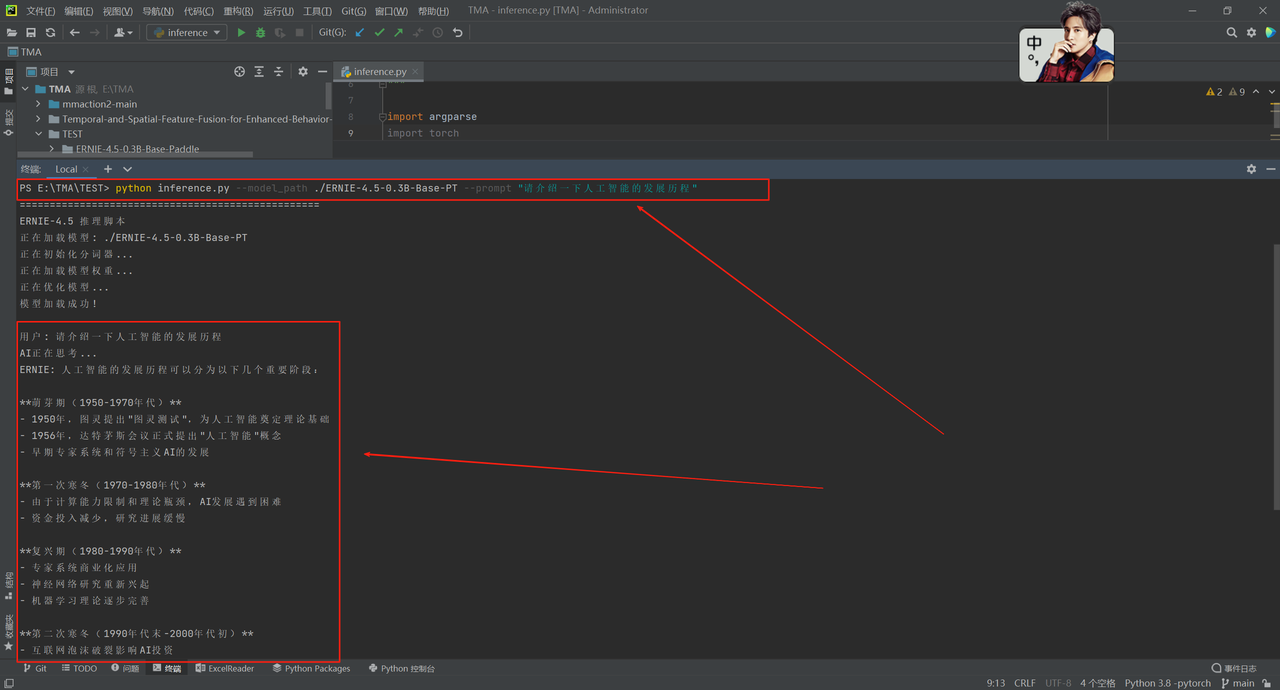
可以看到我们的大模型成功调用成功,很完美的给出了我们想要的答案。除此之外我们还可以使用交互式对话模式: 使用命令python inference.py --model_path ./ERNIE-4.5-0.3B-Base-PT进入持续对话状态,支持多轮交互和特殊命令(quit/exit退出、clear清屏),适合演示测试和长时间对话使用。以及自定义参数模式: 可通过--max_length设置最大生成长度、--temperature控制回答随机性、–top_p调节词汇选择范围等参数来定制AI回答风格,例如python inference.py --model_path ./model --prompt "问题" --max_length 256 --temperature 0.8 --top_p 0.9。这些大家在后续测试中都可以用起来。
4.GitCode平台支持
GitCode为文心4.5提供了完整的代码仓库、文档说明与示例脚本,使用户可以快速落地:
- 提供PyTorch(PT)版与PaddlePaddle版双版本,适配不同技术栈;
- 使用conda快速创建Python环境,仅需几步即可在本地运行模型;
- 丰富的社区讨论区与教程,方便开发者二次开发或提交优化建议。
七、总结
文心大模型4.5系列的开源,显著降低了技术使用门槛和开发成本,相较于商业API节省约70%的费用,并凭借详尽的文档与示例提升了学习效率。源码开放也赋予了更大的定制自由度,为多样化场景提供了坚实支撑。在技术层面,文心4.5系列采用MoE混合专家架构与多模态融合,兼顾参数效率与多任务性能,在中文处理、代码生成、数学推理等方面表现突出。依托GitCode平台的支持与活跃的开发者社区,模型得以快速推广与应用;灵活的授权模式也进一步降低了企业与个人的使用门槛。
未来,文心4.5系列有望通过持续的技术优化与生态建设,进一步巩固其在国产大模型中的领先地位,推动人工智能技术的开放共享与实际应用。


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











