







机器学习课程学习周报四
文章目录
摘要
本周的学习主要集中在卷积神经网络(CNN)和贝叶斯理论的基本概念和应用上。首先,深入探讨了卷积神经网络的架构,包括卷积层、感受野、参数共享和下采样等核心概念,并解释了这些技术如何提高图像识别的效率和准确性。接着,学习了贝叶斯定理及其在分类问题中的应用,详细介绍了朴素贝叶斯分类器的原理和实现方法。通过这些学习,我对机器学习中的关键技术和理论有了更深入的理解。
Abstract
This week’s study focused on the fundamental concepts and applications of Convolutional Neural Networks (CNNs) and Bayesian theory. First, I delved into the architecture of CNNs, covering core concepts such as convolutional layers, receptive fields, parameter sharing, and downsampling, and explained how these techniques enhance the efficiency and accuracy of image recognition. Next, I explored Bayes’ theorem and its application in classification problems, providing a detailed introduction to the principles and implementation of the Naive Bayes classifier. Through these studies, I gained a deeper understanding of key technologies and theories in machine learning.
一、机器学习部分
1.1 卷积神经网络概述
卷积神经网络是一种非常典型的网络架构,常用于图像分类等任务。一张彩色图像可以描述为一个三维的张量,其中一维代表图像的宽,另外一维代表图像的高,还有一维代表图像的通道(channel)的数目。彩色图像的每个像素都可以描述为红色(red)、绿色(green)、蓝色(blue)的组合,这3种颜色就称为图像的 3 个色彩通道,这种颜色描述方式称为RGB色彩模型。
网络的输入往往是向量,因此,将代表图像的三维张量“丢”到网络里之前,需要先将它 “拉直”,如下图所示。在这个例子里面,张量有 100 × 100 × 3 100{\rm{ }} \times {\rm{ }}100{\rm{ }} \times {\rm{ }}3 100×100×3个数字,所以一张图像是由 100 × 100 × 3 100{\rm{ }} \times {\rm{ }}100{\rm{ }} \times {\rm{ }}3 100×100×3个数字所组成的,把这些数字排成一排就是一个巨大的向量。这个向量可以作为网络的输入,而这个向量里面每一维里面存的数值是某一个像素在某一个通道下的颜色强度。
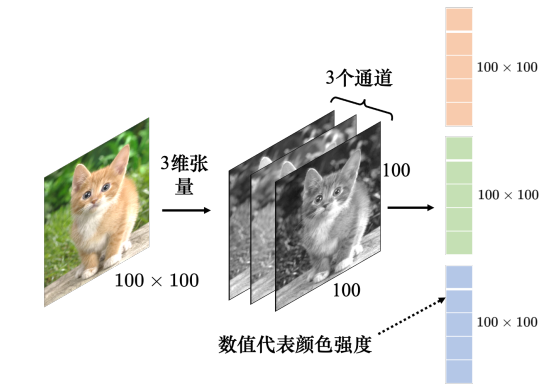
如果把向量当做全连接网络的输入,输入的**特征向量(feature vector)**的长度就是 100 × 100 × 3 100{\rm{ }} \times {\rm{ }}100{\rm{ }} \times {\rm{ }}3 100×100×3,当全连接网络的第1层有1000个神经元时,第 1 层的权重就需要 1000 × 100 × 100 × 3 = 3 × 1 0 7 1000 \times 100 \times 100 \times 3 = 3 \times {10^7} 1000×100×100×3=3×107个权重,这样大规模的参数为模型带来了更好的弹性和能力,但是也增加了过拟合的风险。因此在做图像识别这样的任务时,并不一定需要全连接。
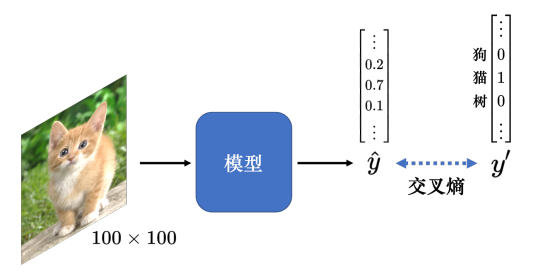
通常在分类任务中,用one-hot向量 y ′ y' y′来表示类别的标签,在one-hot向量中,类别对应的值为1,其余类别对应的值为0。网络模型的输出通过softmax函数后,用 y ^ \hat y y^表示,然后优化 y ′ y' y′和 y ^ \hat y y^的交叉熵变小。
1.2 感受野
对于图像识别的任务来说,神经网络要做的是检测图像里面有没有出现一些特别的模式(pattern),这些模式是代表了某种物体的。人在判断一个物体的时候,往往也是抓最重要的特征。看到这些特征以后,就会看出是某种物体。现在用神经元来判断某种模式是否出现,并不需要每个神经元都去看一张完整的图像,而只需要把图像的一小部分当作输入。
根据上述的思路,卷积神经网络会设定一个区域,即感受野(receptive field),每个神经元都只关心自己的感受野。下图中,同一个感受野的大小为 3 × 3 × 3 3{\rm{ }} \times {\rm{ }}3{\rm{ }} \times {\rm{ }}3 3×3×3,这个神经元会把这个数值变成一个长度为27维的向量,再把这27维的向量作为神经元的输入,这个神经元会给27维的向量的每个维度一个权重,所以这个神经元有 3 × 3 × 3 = 27 3{\rm{ }} \times {\rm{ }}3{\rm{ }} \times {\rm{ }}3{\rm{ }} = {\rm{ }}27 3×3×3=27个权重,再加上偏置得到输出,这个输出再送给一下层的神经元当作输入。
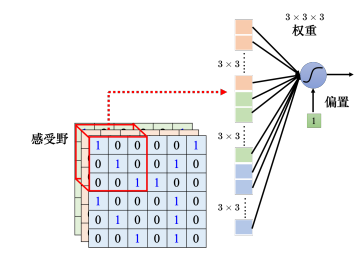
感受野之间是可以重叠的。同个范围内也可以有多个不同的神经元,即多个神经元可以去守备同一个感受野。在描述一个感受野的时候,只要讲它的高和宽,不用强调其深度,因为它的深度就等于通道数,所以我们把高和宽合起来称为核大小(kernel size)。
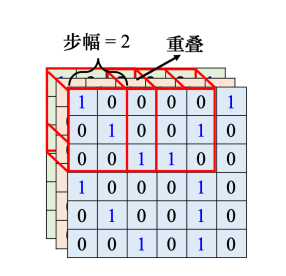
在上图中,我们把左上角的感受野往右移一个步幅,就创造出了一个新的感受野,移动的量称为步幅(stride),如果正好有一个模式出现在两个感受野的交界上面,就没有任何神经元去检测它。因此我们希望感受野与感受野之间是有重叠的,所以步幅往往不会设的太大,一般设置为1或2。
当感受野为了检测边界的模式时,就会移动到超出图像范围的范围,在超出范围的部分做填充(padding),填充就是补值,一般使用零填充(zero padding),感受野有一部分超出图像的范围,那一部分的值就全视为0。步幅移动和填充补值不仅适用于水平方向,也应用于垂直方向。
1.3 共享参数
另一个值得思考的问题是:同样的模式,可能会出现在图像的不同区域。感受野是盖满整个图像的,所以图像里面所有地方都在某个神经元的守备范围内。以检测鸟嘴这一模式为例,假设在每一个个感受野里面,都有一个神经元的工作就是检测鸟嘴,鸟嘴就会被检测出来。但这些检测鸟嘴的神经元做的事情是一样的,只是它们守备的范围不一样。既然如 此,其实没必要每个守备范围都去放一个检测鸟嘴的神经元。如果不同的守备范围都要有一 个检测鸟嘴的神经元,参数量会太多了,因此需要做出相应的简化。
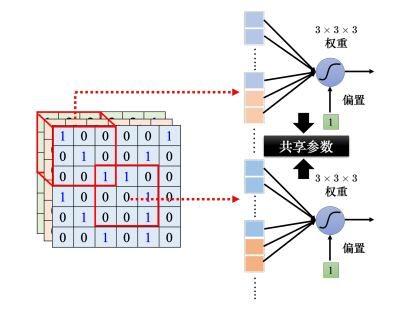
让不同感受野的神经元共享参数,也就是做参数共享(parameter sharing),即让上图中两个神经元的权重完全是一样的。因为感受野包含区域的输入不一致,因此就算是两个神经元共用参数,它们的输出也不会是一样的。
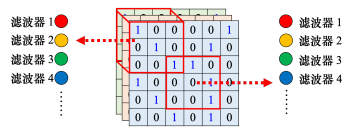
如上图,每一个感受野都有一组神经元在负责守备,它们彼此之间可以共享参数,使用一样的颜色代表这两个神经元共享一样的参数,所以每个感受野都只有一组参数,就是上面感受野的第1个神经元会跟下面感受野的第1个神经元共用参数,上面感受野的第2个神经元跟下面感受野的第2个神经元共用参数等等。每个感受野都只有一组参数,这些参数称为滤波器(filter)。
1.4 下采样
下采样(downsampling)不影响模式检测,缩小一张图片,图片中的模式并不会改变。卷积神经网络使用汇聚进行下采样,汇聚没有需要学习的权重,可以视为一种操作符,其行为都是固定好的。汇聚操作有多种,如最大汇聚(max pooling),在每一组里选一个最大值代表该组(如下图);平均汇聚(mean pooling),平均汇聚是取每一组的平均值。
一般在实践上,往往就是卷积跟汇聚交替使用,可能做几次卷积,做一次汇聚。不过汇聚对于模型的性能可能会带来一点伤害。假设要检测的是非常微细的东西,随便做下采样,性能可能会稍微差一点。汇聚最主要的作用是减少运算量, 通过下采样把图像变小,从而减少运算量。随着近年来运算能力越来越强,如果运算资源足够支撑不做汇聚,很多网络的架构的设计往往就不做汇聚,而是使用全卷积。
1.5 卷积神经网络小结
全连接层可以自己决定看整张图像还是一个小范围。但加上感受野的概念以后,只能看一个小范围,网络的弹性是变小的。参数共享又进一步限制了网络的弹性。本来在学习的时候,每个神经元可以各自有不同的参数,它们可以学出相同的参数,也可以有不一样的参数。但是加入参数共享以后,某一些神经元无论如何参数都要一模一样的,这又增加了对神经元的限制。而感受野加上参数共享就是卷积层 (convolutional layer),用到卷积层的网络就叫卷积神经网络。卷积神经网络的偏差比较大。 但模型偏差大不一定是坏事,因为当模型偏差大,模型的灵活性较低时,比较不容易过拟合。 全连接层可以做各式各样的事情,但它可能没有办法在任何特定的任务上做好。而卷积层是专门为图像设计的,感受野、参数共享都是为图像设计的。
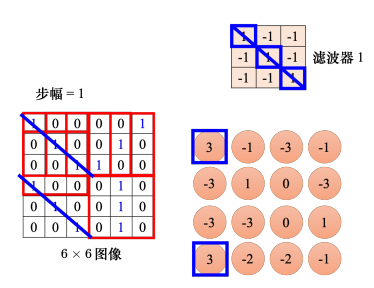
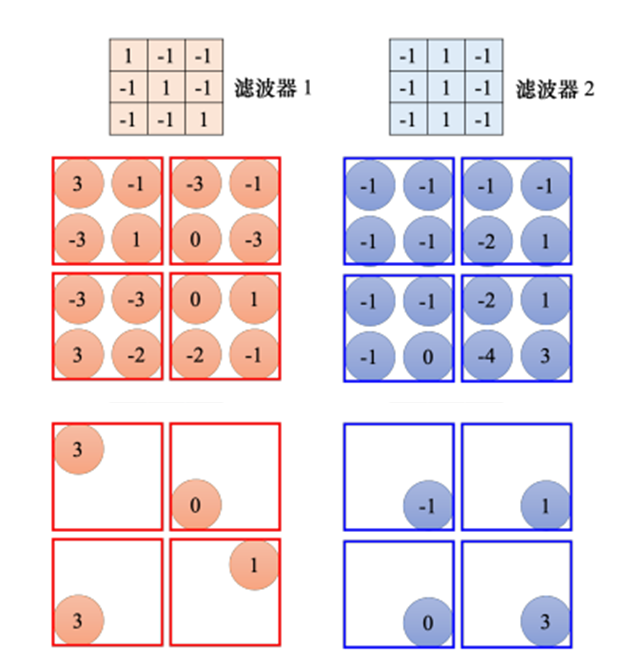
这是一个 6 × 6 6{\rm{ }} \times {\rm{ }}6 6×6的大小的图像。先把滤波器放在图像的左上角,接着把滤波器里面所有的 9 个值跟左上角这个范围内的 9 个值对应相乘再相加,也就是做内积,结果是 3。接下来设置好步幅,然后把滤波器往右移或往下移,重复几次,可得到模式检测的结果。接下来用滤波器2做上述同样的操作,如果有64个滤波器,就可以得到64组的数字,这组数字称为特征映射(feature map)。
卷积层是可以叠很多层,第 2 层的卷积里面也有一堆的滤波器,每个滤波器的大小设成 3 × 3 3{\rm{ }} \times {\rm{ }}3 3×3。其深度必须设为 64,因为滤波器的深度就是它要处理的图像的通道。在第 2 层卷积层滤波器的大小一样设 3 × 3 3{\rm{ }} \times {\rm{ }}3 3×3,当我们看 第 1 个卷积层输出的特征映射的的范围的时候,在原来的图像上是考虑了一个 5 × 5 5{\rm{ }} \times {\rm{ }}5 5×5的范围。虽然滤波器只有 3 × 3 3{\rm{ }} \times {\rm{ }}3 3×3,但它在图像上考虑的范围是比较大的是 5 × 5 5{\rm{ }} \times {\rm{ }}5 5×5。 因此网络叠得越深,同样是 3 × 3 3{\rm{ }} \times {\rm{ }}3 3×3的大小的滤波器,它看的范围就会越来越大。
二、贝叶斯理论
2.1 贝叶斯公式



2.2 朴素贝叶斯
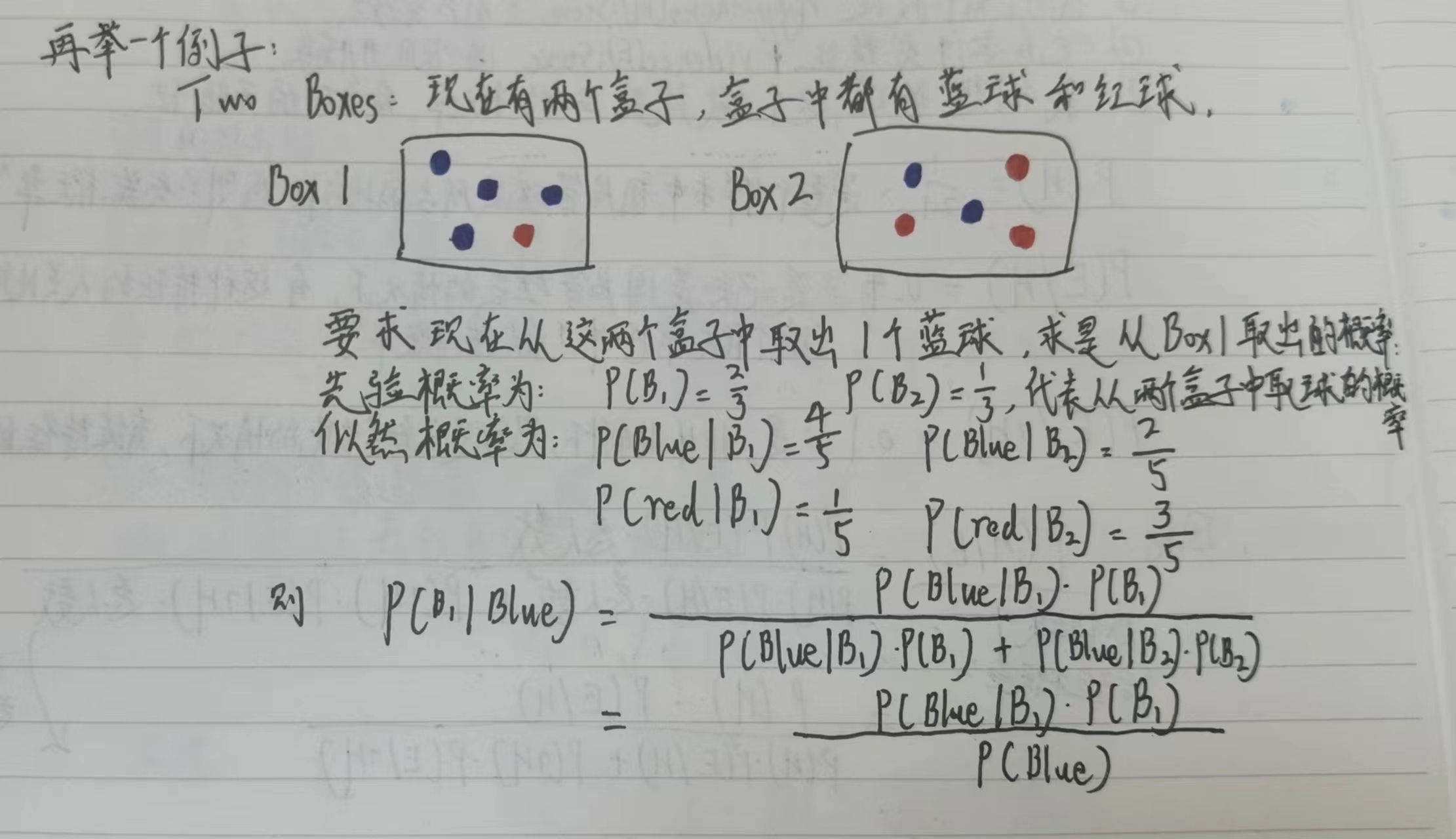
从分类的角度理解贝叶斯:

在规定两个高斯分布共享同样的协方差矩阵$\Sigma $,需重新计算极大似然估计:

计算后验概率的最终形式:

后验概率转化为线性模型:
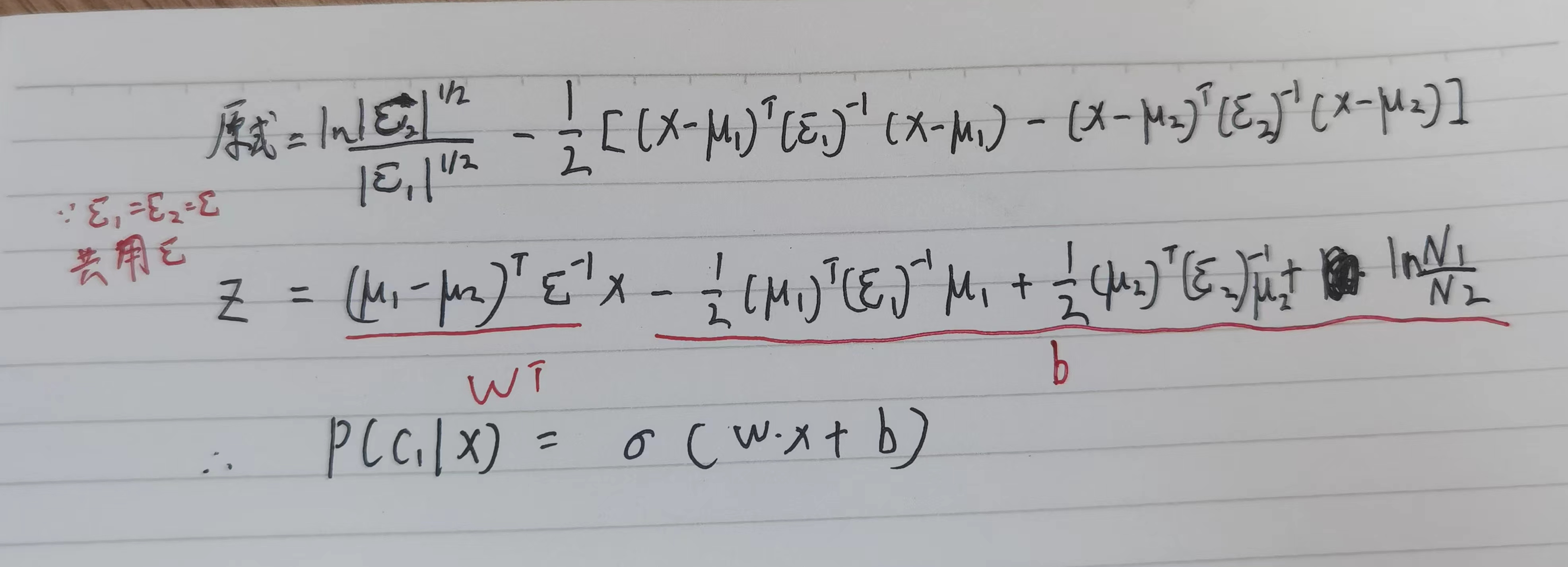
总结
这一周学习贝叶斯理论时,复习了概率的知识,希望能继续探究贝叶斯在机器学习中的应用。下一周准备学习自注意力机制。















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









