







机器学习课程学习周报二
文章目录
摘要
本周在机器学习部分主要学习了PyTorch的基础用法,手推了反向传播的过程以及使用深度学习的方法完成一个回归问题。在docker的学习部分,开始学习docker的原理部分,了解了docker的联合文件系统及其镜像加载的原理,并实践了使用容器数据卷达到宿主机与容器内数据的同步与持久化,最后使用dockerfile构建一个自己的docker镜像文件。
Abstract
This week in the Machine Learning section I learned the basics of PyTorch usage, the backpropagation process step by step and a regression problem using deep learning methods. In the learning part of docker, I began to learn the principle of docker, understand the joint file system of docker and the principle of image loading, and practice the use of container data volume to achieve the synchronization and persistence of data between the host machine and the container, and finally use dockerfile to build a docker image file of my own.
一、机器学习部分
1.1 PyTorch教程
Dataset&Dataloader
#Dataset: 存储数据样本和期望值
#Dataloader: 对数据进行批量分组,支持多进程处理
#例:
dataset = MyDataset(file)
dataloader = DataLoader(dataset,batch_size,shuffle=True) # Training:True,Testing:False
from torch.utils.data import Dataset,DataLoader
class MyDataset(Dataset):
def __init__(self,file): #读取数据并处理
self.data = xxx
def __getitem__(self,index): #一次返回一个数据集样本
return self.data[index]
def __len__(self):
return len(self.data) #返回数据集的大小
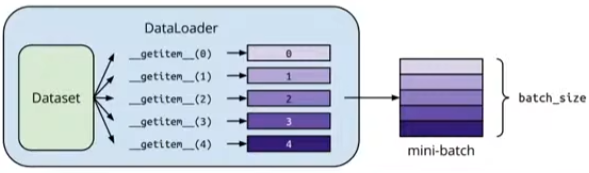
创建Tensors
#从list或者numpy数组中创建tensor
x = torch.tensor([[1,-1],[-1,1]])
x = torch.from_numpy(np.array([[1,-1],[-1,1]]))
'''
tensor([[ 1, -1],
[-1, 1]])
'''
#创建全是0或1的tensor
x = torch.zeros([2,2])
'''
tensor([[0., 0.],
[0., 0.]])
'''
x = torch.ones([1,2,5])
'''
tensor([[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]])
'''
Tensors基本操作
#transpose 转置
x = torch.tensor([[1,2,3],[4,5,6]])
'''
tensor([[1, 2, 3],
[4, 5, 6]])
'''
x = x.transpose(0,1) # 交换dim0和dim1的维度,01和10是一样的
'''
tensor([[1, 4],
[2, 5],
[3, 6]])
'''
#squeeze 移除特定的长度为1的维度
x = torch.zeros([1,2,3])
x.shape
'''
torch.Size([1, 2, 3])
'''
x = x.squeeze(0) #消除的维度为dim0
x.shape
'''
torch.Size([2, 3])
'''
#unsqueeze 拓展一个新的维度
x = torch.zeros([2,3])
x.shape
'''
torch.Size([2, 3])
'''
x = x.unsqueeze(1)
x.shape
'''
torch.Size([2, 1, 3])
'''
#cat 连接多个tensor
x = torch.zeros([2,1,3])
y = torch.zeros([2,3,3])
z = torch.zeros([2,2,3])
w = torch.cat([x,y,z],dim=1)
w.shape
'''
torch.Size([2, 6, 3])
'''
Tensors数据类型
| Data type | dtype | 创建tensor函数 |
|---|---|---|
| 32-bit floating point | torch.float | torch.FloatTensor([ ]) |
| 64-bit integer(signed) | torch.long | torch.LongTensor([ ]) |
x = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float)
x.dtype
'''
torch.float32
'''
x = torch.FloatTensor([1.0, 2.0, 3.0])
x.dtype
'''
torch.float32
'''
Tensors运行设备
x = x.to('cpu') #默认项
x = x.to('cuda') #将tensors移动到显卡上运算
自动计算梯度

构建网络层
以Linear Layer线性层(也叫Fully-connected Layer全连接层)
import torch.nn as nn
fc = nn.Linear(in_features, out_features)
#在下图中,in_features=x=32,out_features=y=64
fc.weight.shape
'''
torch.Size([64, 32]) #看下图中的w
'''
fc.bias.shape
'''
torch.Size([64]) #看下图中的b
'''
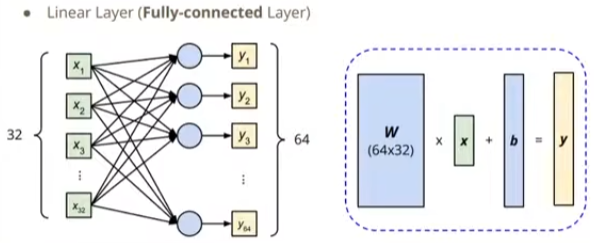
#Pytorch中的激活函数
nn.Sigmoid()
nn.ReLU()
构建整个神经网络
import torch.nn as nn
class MyModel(nn.Module):
#nn.Module是一个重要的基类,用于定义神经网络模型。nn.Module提供了一些有用的方法和属性,帮助我们管理模型的参数、执行前向传播以及其他一些功能。
def __init__(self):
super(MyModel, self).__init__()
self.net=nn.Sequential(
nn.Linear(10,32),
nn.Sigmoid(),
nn.Linear(32,1)
)
#nn.Sequential是PyTorch中的一个模型容器,用于按顺序组合多个层或模块。它可以简化模型的定义和前向传播过程。
def forward(self,x):
return self.net(x)
损失函数
criterion=nn.MSELoss() #均方误差
criterion=nn.CrossEntropyLoss() #交叉熵损失
loss=criterion(model_output,expected_value)
优化方法
#torch.optim是PyTorch中的优化器模块,用于实现各种优化算法来更新神经网络模型的参数。优化器在训练过程中根据计算出的损失函数梯度来更新模型的参数,以最小化损失函数。
torch.optim.SGD(model.parameters(),lr,momentum=0)
#对每一个批次的数据来说,按以下次步骤优化
#1.call optimizer.zero_grad() 梯度归0
#2.call loss.backward() 反向传播,用于计算损失函数对模型参数的梯度,它执行自动求导(Automatic Differentiation)的过程
#3.call optimizer.step() 调整参数
保存/加载模型
#保存模型
torch.save(model.state_dict(),path)
#加载模型
ckpt=torch.load(path)
model.load_state_dict(ckpt)
1.2 Backpropagation

计算反向传播的过程:

Forward pass的值就是相应的激活函数的输入值x:
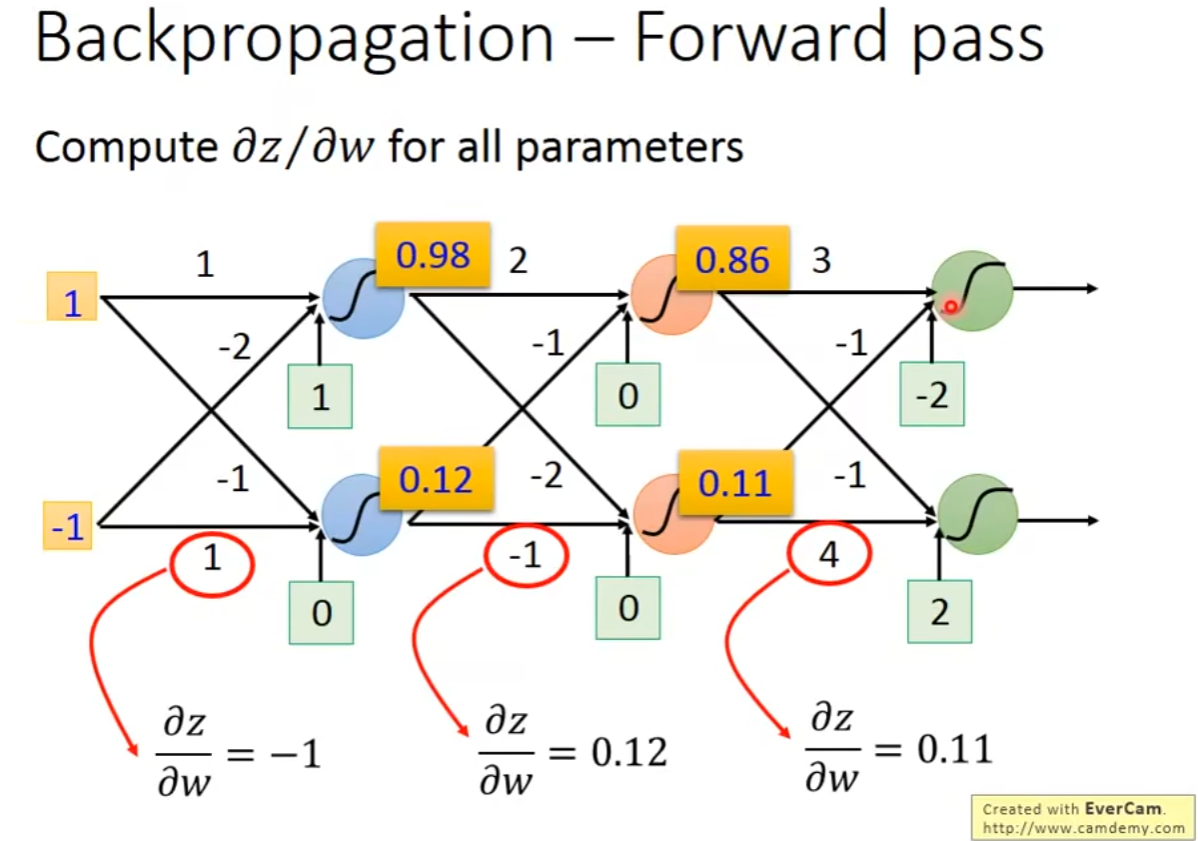
其中Forward pass较为容易计算,下面考虑Backward pass的计算过程:

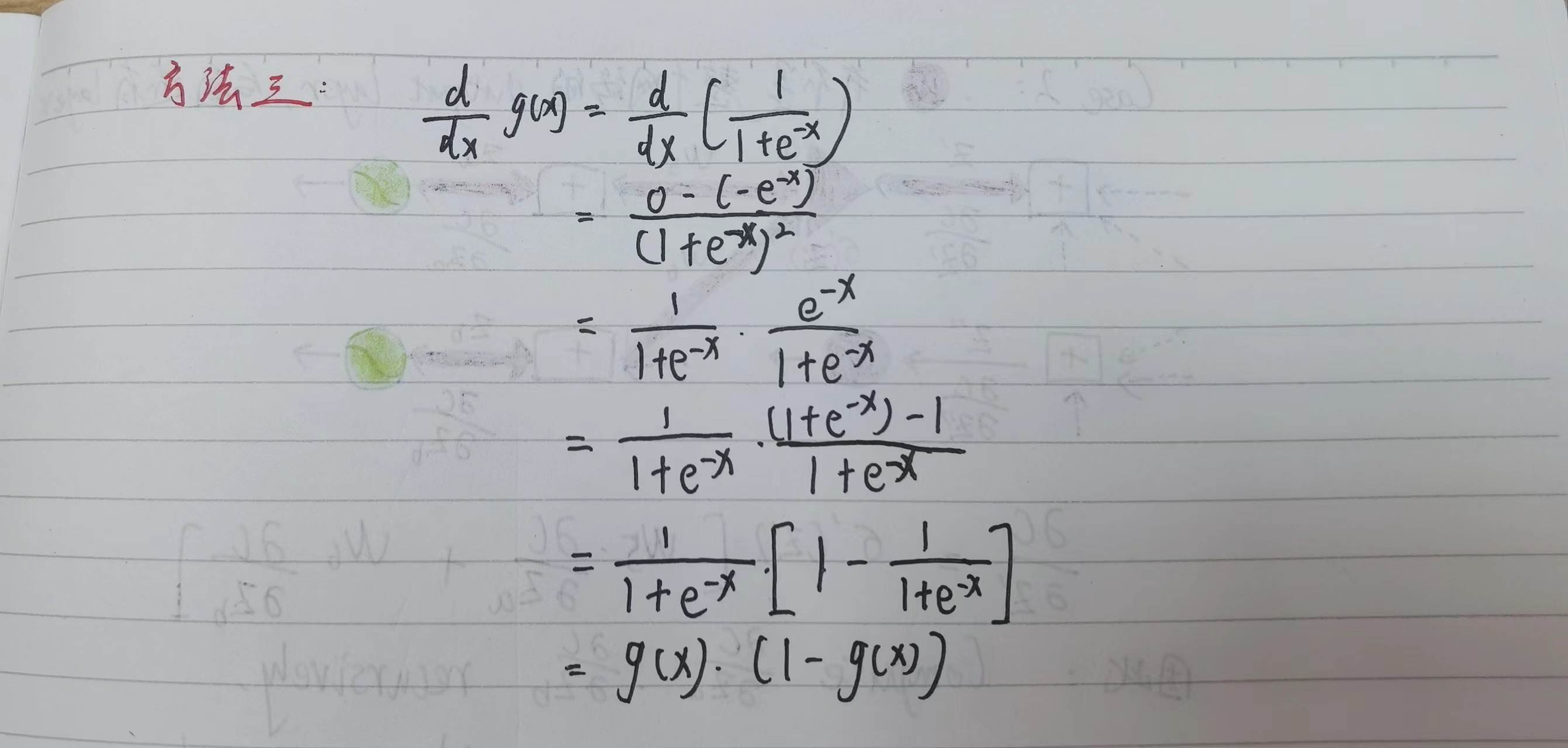

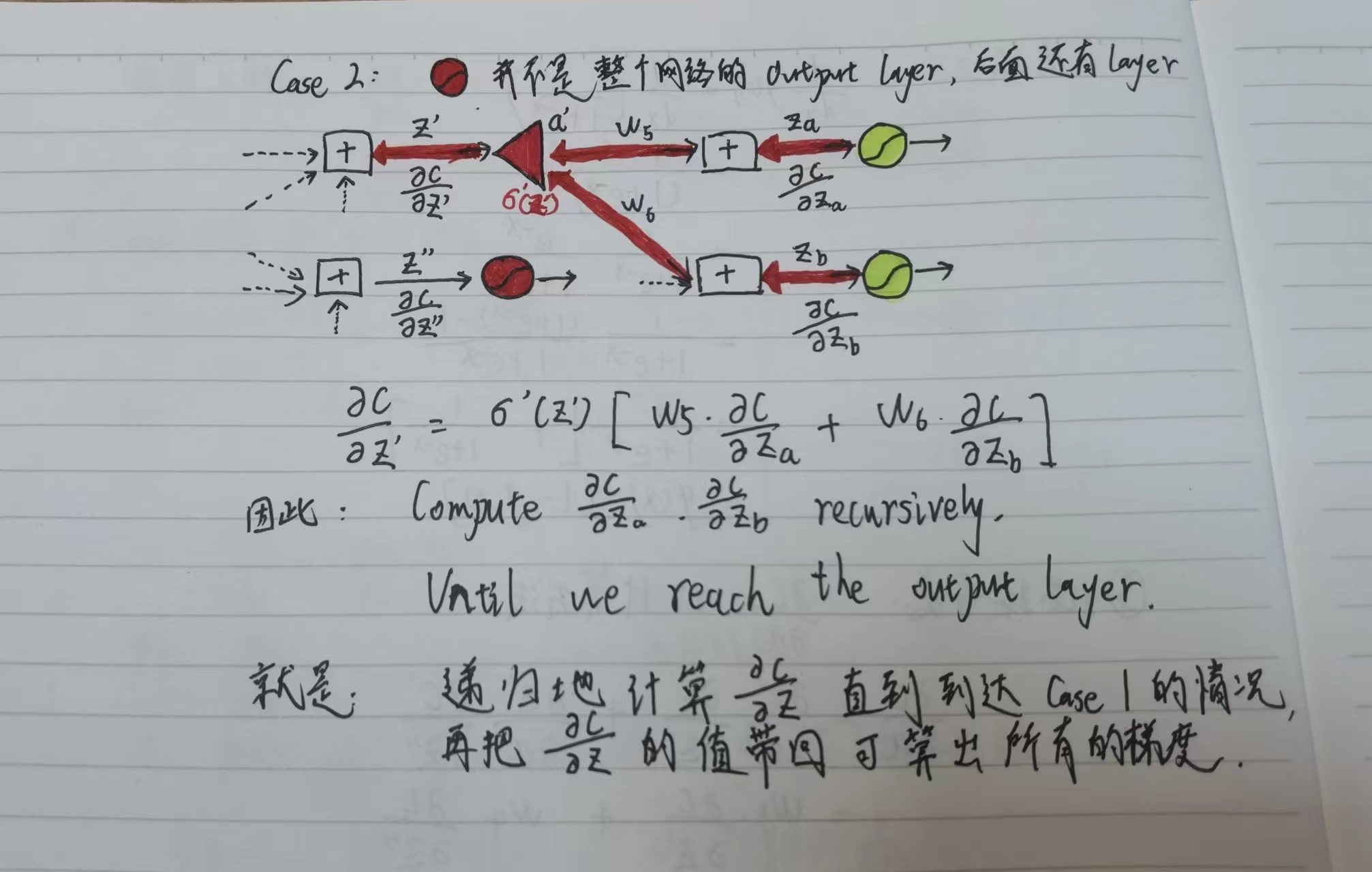
考虑Backward pass的第一种情况:激活函数这一层就是Output layer

考虑Backward pass的第二种情况:激活函数这一层不是Output layer,网络更深,需要递归地计算直到到达Backward pass的第一种情况为止。
1.3 Regression实战——COVID-19 Cases Prediction
Import packages
# Numerical Operations 数值操作
import math
import numpy as np
# Reading/Writing Data 读写数据
import pandas as pd
import os
import csv
# For Progress Bar 使用进度条库
from tqdm import tqdm
# Pytorch 引入torch以及数据集加载模块
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split
# For plotting learning curve 使用TensorBoard的可视化功能
from torch.utils.tensorboard import SummaryWriter
Some Utility Functions
def same_seed(seed):
'''Fixes random number generator seeds for reproducibility.'''
#设置随机数生成器种子可以使得每次运行时生成的随机数序列保持一致,从而使实验结果可重复
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
def train_valid_split(data_set, valid_ratio, seed):
'''Split provided training data into training set and validation set'''
#按照valid_ratio的比例随机划分训练集和验证集
valid_set_size = int(valid_ratio * len(data_set))
train_set_size = len(data_set) - valid_set_size
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed))
return np.array(train_set), np.array(valid_set)
def predict(test_loader, model, device):
#使用训练好的模型进行预测
model.eval() # Set your model to evaluation mode.
preds = []
for x in tqdm(test_loader):
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
return preds
Dataset
class COVID19Dataset(Dataset):
'''
x: Features.
y: Targets, if none, do prediction.
'''
def __init__(self, x, y=None):
if y is None:
self.y = y
else:
self.y = torch.FloatTensor(y)
self.x = torch.FloatTensor(x)
def __getitem__(self, idx):
if self.y is None:
return self.x[idx]
else:
return self.x[idx], self.y[idx]
def __len__(self):
return len(self.x)
Neural Network Model
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# 可自定义网络结构
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
Feature Selection
def select_feat(train_data, valid_data, test_data, select_all=True):
'''Selects useful features to perform regression'''
y_train, y_valid = train_data[:,-1], valid_data[:,-1]
raw_x_train, raw_x_valid, raw_x_test = train_data[:,:-1], valid_data[:,:-1], test_data
if select_all:
feat_idx = list(range(raw_x_train.shape[1]))
else:
feat_idx = [0,1,2,3,4] # Select suitable feature columns.
return raw_x_train[:,feat_idx], raw_x_valid[:,feat_idx], raw_x_test[:,feat_idx], y_train, y_valid
Training Loop
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
# check https://pytorch.org/docs/stable/optim.html to get more available algorithms.
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9)
writer = SummaryWriter() # Writer of tensoboard.
if not os.path.isdir('./models'):
os.mkdir('./models') # Create directory of saving models.
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = []
# tqdm is a package to visualize your training progress.
train_pbar = tqdm(train_loader, position=0, leave=True)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record)/len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record)/len(loss_record)
print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
writer.add_scalar('Loss/valid', mean_valid_loss, step)
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
Configurations
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 5201314, # Your seed number, you can pick your lucky number. :)
'select_all': True, # Whether to use all features.
'valid_ratio': 0.2, # validation_size = train_size * valid_ratio
'n_epochs': 3000, # Number of epochs.
'batch_size': 256,
'learning_rate': 1e-5,
'early_stop': 400, # If model has not improved for this many consecutive epochs, stop training.
'save_path': './models/model.ckpt' # Your model will be saved here.
}
Dataloader
# Set seed for reproducibility
same_seed(config['seed'])
# train_data size: 2699 x 118 (id + 37 states + 16 features x 5 days)
# test_data size: 1078 x 117 (without last day's positive rate)
train_data, test_data = pd.read_csv('./covid.train.csv').values, pd.read_csv('./covid.test.csv').values
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])
# Print out the data size.
print(f"""train_data size: {train_data.shape}
valid_data size: {valid_data.shape}
test_data size: {test_data.shape}""")
# Select features
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])
# Print out the number of features.
print(f'number of features: {x_train.shape[1]}')
train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \
COVID19Dataset(x_valid, y_valid), \
COVID19Dataset(x_test)
# Pytorch data loader loads pytorch dataset into batches.
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
'''
train_data size: (2160, 118)
valid_data size: (539, 118)
test_data size: (1078, 117)
number of features: 117
'''
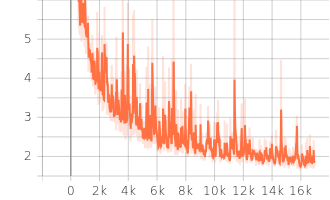
Start training!
model = My_Model(input_dim=x_train.shape[1]).to(device) # put your model and data on the same computation device.
trainer(train_loader, valid_loader, model, config, device)
Testing
#使用训练好的模型在测试集上预测
model = My_Model(input_dim=x_train.shape[1]).to(device)
model.load_state_dict(torch.load(config['save_path']))
preds = predict(test_loader, model, device)
二、docker学习部分
机器学习课程学习周报一-CSDN博客 接着上次的内容
2.1 docker镜像加载原理
UnionFS(联合文件系统):Union文件系统是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。Union文件系统是docker镜像的基础,镜像可以通过分层来继承,基于基础镜像,可以制作各种具体的应用镜像。
特点:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。
docker镜像加载原理:
docker的镜像实际上是由一层一层的文件系统组成的,这种层级的文件系统是UnionFS。
bootfs(boot file system)主要包含bootloader和kernel,bootloader主要引导加载kernel。Linux刚启动时会加载bootfs文件系统,docker镜像最底层的就是bootfs,这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs(root file system)在bootfs之上,包含Linux系统中的/dev,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,CentOs等等。

平时我们安装进虚拟机的CentOS都是好几个G,为什么docker镜像中的CentOs这里才200M??

对于一个精简的OS,rootfs可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用Host的kernel,自己只需要提供 rootfs 就行了。由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs。
2.2 commit镜像
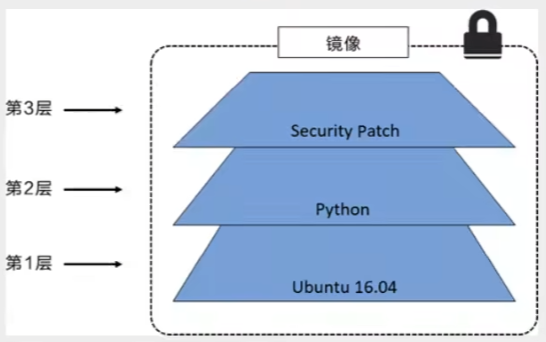
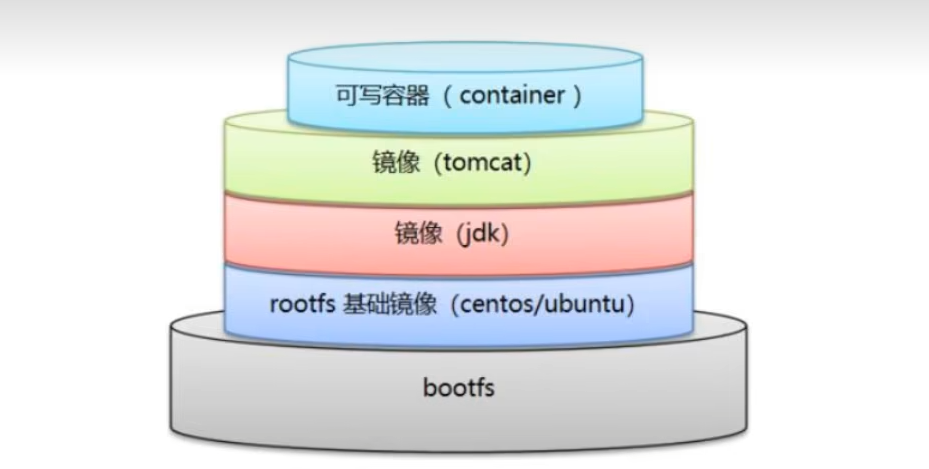
所有的docker镜像都起始于一个基础镜像层,当进行修改或增加新的内容时,就会在当前镜像层之上,创建新的镜像层。例:假如基于Ubuntu Linux 16.04创建一个镜像,这就是新镜像的第一层;如果在该镜像中添加Python包,就会在基础镜像层之上创建第二个镜像层;如果继续添加一个安全补丁,就会创建第三个镜像层。
docker镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部,这一层就是我们通常说的容器层,容器层之下的都叫镜像层。
docker commit 提交容器成为一个新的副本
#命令与git原理类似
docker commit -m="提交描述信息" -a="作者" 容器ID 镜像名[:TAG]
2.3 容器数据卷使用
如果数据都在容器中,那么我们容器删除,数据就会丢失!数据应当可以持久化并且容器之间的数据应当可以共享,且docker容器中产生的数据能同步到本地。
容器数据卷技术:将容器内的目录挂载到主机上。
第一种挂载方式:命令
#方式一:直接使用命令来挂载 -v
docker run -it -v 主机目录:容器内目录 image名 #主机目录和容器内目录是同步的
具名和匿名挂载
# 匿名挂载
-v 容器内路径
docker run -d -P(随机映射端口) nginx -v 容器内路径 #不指定主机目录
# 具名挂载
-v 卷名:容器内路径
docker run -d -P(随机映射端口) nginx -v 卷名:容器内路径 #不指定主机目录
#查看所有卷
docker volume ls
#查看单独的卷
docker volume inspect 卷名 #可以查看上述的容器内路径究竟绑定到哪个主机路径上了
我们通过具名挂载可以方便地找到我们的一个卷,大多数情况下都使用具名挂载。
第二种挂载方式:Dockerfile
dockerfile就是用来构建docker镜像的构建文件。
先自定义一个dockerfile文件:
#编写一个Dockerfile
FROM centos #基础镜像源于centos
VOLUME ["/volume01","/volume02"] #指定两个匿名挂载
cmd echo "-------end---------"
cmd /bin/bash
然后使用build命令根据dockerfile生成镜像
docker build -f dockerfile文件的位置 -t 作者名/生成镜像的名字:版本号 . #一定注意后面有个空格和.
然后使用inspect命令查看挂载:Mounts是挂载的文件系统,source是主机上的文件位置,destination是容器中的文件位置
docker inspect 容器id
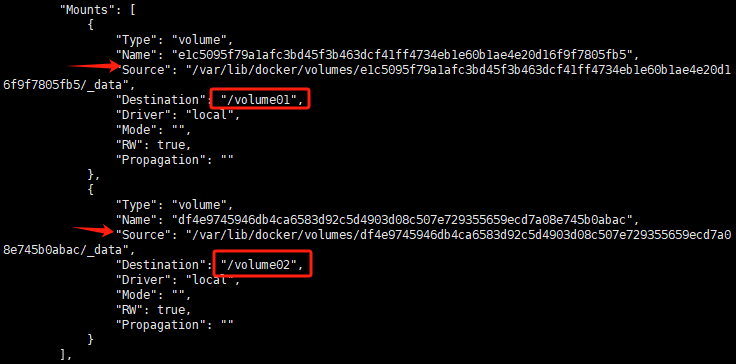
数据卷间的同步与共享

docker run -it --name 新建的容器名 --volumes-from 要挂载的父容器名 镜像名
2.4 DockerFile
dockerfile就是用来构建docker镜像的构建文件。
构建步骤
- 编写一个dockerFile文件
- docker build 构建成为一个镜像
- docker run 运行镜像
- docker push 发布镜像(DockerHub、阿里云镜像)
基础知识
- 每个保留关键字(指令)都是必须大写字母
- 执行从上到下顺序执行
#表示注释- 每个指令都会创建提交一个新的镜像层
DockerFile的指令
FROM # 基础镜像,一切从这里开始构建。Docker Hub 中 99%的镜像都是从这个基础镜像过来的 FROM scratch
MAINTAINER # 镜像是谁写的, 姓名+邮箱(新版本Docker采用LABEL,不建议使用MAINTAINER,LABEL author="姓名<邮箱>")
RUN # 镜像构建的时候需要运行的命令
ADD # 步骤,tomcat镜像,这个tomcat压缩包(自动解压)!添加内容 添加同目录
WORKDIR # 镜像的工作目录
VOLUME # 挂载的目录
EXPOSE # 保留端口配置(多端口直接空格)
CMD # 指定这个容器启动的时候要运行的命令,只有最后一个会生效,可被替代
ENTRYPOINT # 指定这个容器启动的时候要运行的命令,可以追加命令
ONBUILD # 当构建一个被继承DockerFile这个时候就会运行onbuild的指令,触发指令
COPY # 类似ADD,将我们文件拷贝到镜像中
ENV # 构建的时候设置环境变量!
DockerFile实战
创建一个自己的centos
# 1./home下新建dockerfile目录
$ mkdir dockerfile
# 2. dockerfile目录下新建mydockerfile-centos文件
$ vim mydockerfile-centos
# 3.编写Dockerfile配置文件
FROM centos # 基础镜像是官方原生的centos
MAINTAINER cao<196655494@qq.com> # 作者
ENV MYPATH /usr/local # 配置环境变量的目录
WORKDIR $MYPATH # 将工作目录设置为 MYPATH
RUN yum -y install vim # 给官方原生的centos 增加 vim指令
RUN yum -y install net-tools # 给官方原生的centos 增加 ifconfig命令
EXPOSE 80 # 暴露端口号为80
CMD echo $MYPATH # 输出下 MYPATH 路径
CMD echo "-----end----"
CMD /bin/bash # 启动后进入 /bin/bash
# 4.通过这个文件构建镜像
# 命令: docker build -f 文件路径 -t 镜像名:[tag] .
$ docker build -f mydockerfile-centos -t mycentos:0.1 .
# 5.出现Successfully则构建成功
CMD 和ENTRYPOINT区别
CMD # 指定这个容器启动的时候要运行的命令,只有最后一个会生效,可被替代。
ENTRYPOINT # 指定这个容器启动的时候要运行的命令,可以追加命令
测试cmd
# 1、编写dockerfile文件
$ vim dockerfile-test-cmd
FROM centos
CMD ["ls","-a"] # 启动后执行 ls -a 命令
# 2、构建镜像
$ docker build -f dockerfile-test-cmd -t cmd-test:0.1 .
# 3、运行镜像,发现我们的ls -a 命令生效
$ docker run cmd-test:0.1 # 由结果可得,运行后就执行了 ls -a 命令
.
..
.dockerenv
bin
dev
etc
home
# 想追加一个命令 -l 成为ls -al:展示列表详细数据
$ docker run cmd-test:0.1 -l
docker: Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "exec: \"-l\":
executable file not found in $PATH": unknown.
ERRO[0000] error waiting for container: context canceled
# cmd的情况下 -l 替换了CMD["ls","-a"] 而 -l 不是命令所以报错
测试entrypoint
# 1、编写dockerfile文件
$ vim dockerfile-test-entrypoint
FROM centos
ENTRYPOINT ["ls","-a"]
# 2、构建镜像
$ docker build -f dockerfile-test-entrypoint -t entrypoint-test:0.1 .
# 3、运行镜像,现我们的ls -a 命令同样生效
$ docker run entrypoint-test:0.1
.
..
.dockerenv
bin
dev
etc
home
lib
lib64
lost+found ...
# 4、我们的追加命令,是直接拼接在我们的ENTRYPOINT命令后面的
$ docker run entrypoint-test:0.1 -l
total 56
drwxr-xr-x 1 root root 4096 May 16 06:32 .
drwxr-xr-x 1 root root 4096 May 16 06:32 ..
-rwxr-xr-x 1 root root 0 May 16 06:32 .dockerenv
lrwxrwxrwx 1 root root 7 May 11 2019 bin -> usr/bin
drwxr-xr-x 5 root root 340 May 16 06:32 dev
drwxr-xr-x 1 root root 4096 May 16 06:32 etc
drwxr-xr-x 2 root root 4096 May 11 2019 home
lrwxrwxrwx 1 root root 7 May 11 2019 lib -> usr/lib
lrwxrwxrwx 1 root root 9 May 11 2019 lib64 -> usr/lib64 ....
总结
下周预计学习局部极小值与鞍点,批量与动量,自适应学习率,学习率调度等小节。docker部分预计实操一下nvidia-docker,实现利用宿主机的硬件GPU加速容器内运行的深度学习项目。















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









