









一、倒立摆问题介绍
Agent 必须在两个动作之间做出决定 - 向左或向右移动推车 - 以使连接到它的杆保持直立。

二、双深度Q网络简介
如下式所示,假设我们有两个Q函数:
Q
Q
Q 和
Q
′
Q^{\prime}
Q′ ,如果
Q
Q
Q 高估了它选出来的动作
a
a
a ,只要
Q
′
Q^{\prime}
Q′ 没有高估动作
a
a
a 的值,算出来的就还是正常的值。假设
Q
′
Q^{\prime}
Q′ 高估了某一个动作的值,也 是没问题的,因为只要
Q
Q
Q 不选这个动作就可以,这就是DDQN神奇的地方。
Q
(
s
t
,
a
t
)
⟷
r
t
+
Q
′
(
s
t
+
1
,
arg
max
a
Q
(
s
t
+
1
,
a
)
)
Q\left(s_t, a_t\right) \longleftrightarrow r_t+Q^{\prime}\left(s_{t+1}, \arg \max _a Q\left(s_{t+1}, a\right)\right)
Q(st,at)⟷rt+Q′(st+1,argamaxQ(st+1,a))
我们动手实现的时候,有两个
Q
\mathrm{Q}
Q 网络:会更新的
Q
\mathrm{Q}
Q 网络和目标
Q
\mathrm{Q}
Q 网络。所以在DDQN里面,我们 会用会更新参数的
Q
Q
Q 网络去选动作,用目标
Q
Q
Q 网络(固定住的网络) 计算值。
D
D
Q
N
D D Q N
DDQN 相较于原来的深度
Q
Q
Q 网络的更改是最少的,它几乎没有增加任何的运算量,也不需要新的 网络,因为原来就有两个网络。我们只需要做一件事:本来是用目标网络
Q
′
Q^{\prime}
Q′ 来找使
Q
\mathrm{Q}
Q 值最大 的
a
a
a ,现在改成用另外一个会更新的Q网络来找使
Q
\mathrm{Q}
Q 值最大的
a
a
a 。
三、详细资料
关于更加详细的双深度Q网络的介绍,请看我之前发的博客:【EasyRL学习笔记】第七章 深度Q网络进阶技巧(Double-DQN、Dueling-DQN、Noisy-DQN、Distributional-DQN、Rainbow-DQN)
在学习双深度Q网络前你最好能了解以下知识点:
- 深度Q网络
四、Python代码实战
4.1 运行前配置
准备好一个RL_Utils.py文件,文件内容可以从我的一篇里博客获取:【RL工具类】强化学习常用函数工具类(Python代码)
这一步很重要,后面需要引入该RL_Utils.py文件

4.2 主要代码
import argparse
import datetime
import time
import math
import torch.optim as optim
import gym
from torch import nn
# 这里需要改成自己的RL_Utils.py文件的路径
from Python.ReinforcementLearning.EasyRL.RL_Utils import *
# Q网络(3层全连接网络)
class MLP(nn.Module):
def __init__(self, input_dim, output_dim, hidden_dim=128):
""" 初始化q网络,为全连接网络
input_dim: 输入的特征数即环境的状态维度
output_dim: 输出的动作维度
"""
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim) # 输入层
self.fc2 = nn.Linear(hidden_dim, hidden_dim) # 隐藏层
self.fc3 = nn.Linear(hidden_dim, output_dim) # 输出层
def forward(self, x):
# 各层对应的激活函数
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 经验回放缓存区
class ReplayBuffer:
def __init__(self, capacity):
self.capacity = capacity # 经验回放的容量
self.buffer = [] # 缓冲区
self.position = 0
def push(self, state, action, reward, next_state, done):
''' 缓冲区是一个队列,容量超出时去掉开始存入的转移(transition)
'''
if len(self.buffer) < self.capacity:
self.buffer.append(None)
self.buffer[self.position] = (state, action, reward, next_state, done)
self.position = (self.position + 1) % self.capacity
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size) # 随机采出小批量转移
state, action, reward, next_state, done = zip(*batch) # 解压成状态,动作等
return state, action, reward, next_state, done
def __len__(self):
''' 返回当前存储的量
'''
return len(self.buffer)
# DDQN智能体对象
class DDQN:
def __init__(self, model, memory, cfg):
self.n_actions = cfg['n_actions']
self.device = torch.device(cfg['device'])
self.gamma = cfg['gamma']
## e-greedy 探索策略参数
self.sample_count = 0 # 采样次数
self.epsilon = cfg['epsilon_start']
self.sample_count = 0
self.epsilon_start = cfg['epsilon_start']
self.epsilon_end = cfg['epsilon_end']
self.epsilon_decay = cfg['epsilon_decay']
self.batch_size = cfg['batch_size']
self.policy_net = model.to(self.device)
self.target_net = model.to(self.device)
# 初始化的时候,目标Q网络和估计Q网络相等,将策略网络的参数复制给目标网络
self.target_net.load_state_dict(self.policy_net.state_dict())
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=cfg['lr'])
self.memory = memory
self.update_flag = False
# 训练过程采样:e-greedy policy
def sample_action(self, state):
self.sample_count += 1
self.epsilon = self.epsilon_end + (self.epsilon_start - self.epsilon_end) * \
math.exp(-1. * self.sample_count / self.epsilon_decay)
if random.random() > self.epsilon:
return self.predict_action(state)
else:
action = random.randrange(self.n_actions)
return action
# 测试过程:以最大Q值选取动作
def predict_action(self, state):
with torch.no_grad():
state = torch.tensor(state, device=self.device, dtype=torch.float32).unsqueeze(dim=0)
q_values = self.policy_net(state)
action = q_values.max(1)[1].item()
return action
def update(self):
# 当经验缓存区没有满的时候,不进行更新
if len(self.memory) < self.batch_size:
return
else:
if not self.update_flag:
print("Begin to update!")
self.update_flag = True
# 从经验缓存区随机取出一个batch的数据
state_batch, action_batch, reward_batch, next_state_batch, done_batch = self.memory.sample(
self.batch_size)
# 将数据转化成Tensor格式
state_batch = torch.tensor(np.array(state_batch), device=self.device,
dtype=torch.float) # shape(batchsize,n_states)
action_batch = torch.tensor(action_batch, device=self.device).unsqueeze(1) # shape(batchsize,1)
reward_batch = torch.tensor(reward_batch, device=self.device, dtype=torch.float).unsqueeze(
1) # shape(batchsize,1)
next_state_batch = torch.tensor(np.array(next_state_batch), device=self.device,
dtype=torch.float) # shape(batchsize,n_states)
done_batch = torch.tensor(np.float32(done_batch), device=self.device).unsqueeze(1) # shape(batchsize,1)
# 计算Q估计
q_value_batch = self.policy_net(state_batch).gather(dim=1,
index=action_batch) # shape(batchsize,1),requires_grad=True
# DDQN和DQN不同之处!DDQN先用policy_net预测处最大的动作,然后再用target_net预测其Q值
# next_max_q_value_batch = self.policy_net(next_state_batch).max(1)[0].detach().unsqueeze(1)
next_q_value_batch = self.policy_net(next_state_batch)
next_target_value_batch = self.target_net(next_state_batch) # type = Tensor , shape([batch_size, n_actions])
# gather函数的功能可以解释为根据 index 参数(即是索引)返回数组里面对应位置的值 , 第一个参数为1代表按列索引,为0代表按行索引
# unsqueeze函数起到了升维的作用,例如 torch.Size([6]):tensor([0, 1, 2, 3, 4, 5]).unsqueeze(0) => torch.Size([1, 6])
# torch.max(tensorData,dim) 返回输入张量给定维度上每行的最大值,并同时返回每个最大值的位置索引。
# .detach(): 输入一个张量,返回一个不具有梯度的张量(返回的张量将永久失去梯度,即使修改其requires_grad属性也无法改变)
next_max_q_value_batch = next_target_value_batch.gather(1, torch.max(next_q_value_batch, 1)[1].unsqueeze(1))
# 计算Q现实
expected_q_value_batch = reward_batch + self.gamma * next_max_q_value_batch * (1 - done_batch)
# 计算损失函数MSE(Q估计,Q现实)
loss = nn.MSELoss()(q_value_batch, expected_q_value_batch)
# 梯度下降
self.optimizer.zero_grad()
loss.backward()
# 限制梯度的范围,以避免梯度爆炸
for param in self.policy_net.parameters():
param.grad.data.clamp_(-1.0, 1.0)
self.optimizer.step()
def save_model(self, path):
Path(path).mkdir(parents=True, exist_ok=True)
torch.save(self.target_net.state_dict(), f"{path}/checkpoint.pt")
def load_model(self, path):
self.target_net.load_state_dict(torch.load(f"{path}/checkpoint.pt"))
for target_param, param in zip(self.target_net.parameters(), self.policy_net.parameters()):
param.data.copy_(target_param.data)
# 训练函数
def train(arg_dict, env, agent):
# 开始计时
startTime = time.time()
print(f"环境名: {arg_dict['env_name']}, 算法名: {arg_dict['algo_name']}, Device: {arg_dict['device']}")
print("开始训练智能体......")
rewards = []
steps = []
for i_ep in range(arg_dict["train_eps"]):
ep_reward = 0
ep_step = 0
state = env.reset()
for _ in range(arg_dict['ep_max_steps']):
# 画图
if arg_dict['train_render']:
env.render()
ep_step += 1
action = agent.sample_action(state)
next_state, reward, done, _ = env.step(action)
agent.memory.push(state, action, reward,
next_state, done)
state = next_state
agent.update()
ep_reward += reward
if done:
break
# 目标网络更新
if (i_ep + 1) % arg_dict["target_update"] == 0:
agent.target_net.load_state_dict(agent.policy_net.state_dict())
steps.append(ep_step)
rewards.append(ep_reward)
if (i_ep + 1) % 10 == 0:
print(f'Episode: {i_ep + 1}/{arg_dict["train_eps"]}, Reward: {ep_reward:.2f}: Epislon: {agent.epsilon:.3f}')
print('训练结束 , 用时: ' + str(time.time() - startTime) + " s")
# 关闭环境
env.close()
return {'episodes': range(len(rewards)), 'rewards': rewards}
# 测试函数
def test(arg_dict, env, agent):
startTime = time.time()
print("开始测试智能体......")
print(f"环境名: {arg_dict['env_name']}, 算法名: {arg_dict['algo_name']}, Device: {arg_dict['device']}")
rewards = []
steps = []
for i_ep in range(arg_dict['test_eps']):
ep_reward = 0
ep_step = 0
state = env.reset()
for _ in range(arg_dict['ep_max_steps']):
# 画图
if arg_dict['test_render']:
env.render()
ep_step += 1
action = agent.predict_action(state)
next_state, reward, done, _ = env.step(action)
state = next_state
ep_reward += reward
if done:
break
steps.append(ep_step)
rewards.append(ep_reward)
print(f"Episode: {i_ep + 1}/{arg_dict['test_eps']},Reward: {ep_reward:.2f}")
print("测试结束 , 用时: " + str(time.time() - startTime) + " s")
env.close()
return {'episodes': range(len(rewards)), 'rewards': rewards}
# 创建环境和智能体
def create_env_agent(arg_dict):
# 创建环境
env = gym.make(arg_dict['env_name'])
# 设置随机种子
all_seed(env, seed=arg_dict["seed"])
# 获取状态数
try:
n_states = env.observation_space.n
except AttributeError:
n_states = env.observation_space.shape[0]
# 获取动作数
n_actions = env.action_space.n
print(f"状态数: {n_states}, 动作数: {n_actions}")
# 将状态数和动作数加入算法参数字典
arg_dict.update({"n_states": n_states, "n_actions": n_actions})
# 实例化智能体对象
# Q网络模型
model = MLP(n_states, n_actions, hidden_dim=arg_dict["hidden_dim"])
# 回放缓存区对象
memory = ReplayBuffer(arg_dict["memory_capacity"])
# 智能体
agent = DDQN(model, memory, arg_dict)
# 返回环境,智能体
return env, agent
if __name__ == '__main__':
# 防止报错 OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 获取当前路径
curr_path = os.path.dirname(os.path.abspath(__file__))
# 获取当前时间
curr_time = datetime.datetime.now().strftime("%Y_%m_%d-%H_%M_%S")
# 相关参数设置
parser = argparse.ArgumentParser(description="hyper parameters")
parser.add_argument('--algo_name', default='DDQN', type=str, help="name of algorithm")
parser.add_argument('--env_name', default='CartPole-v0', type=str, help="name of environment")
parser.add_argument('--train_eps', default=200, type=int, help="episodes of training")
parser.add_argument('--test_eps', default=20, type=int, help="episodes of testing")
parser.add_argument('--ep_max_steps', default=100000, type=int,
help="steps per episode, much larger value can simulate infinite steps")
parser.add_argument('--gamma', default=0.95, type=float, help="discounted factor")
parser.add_argument('--epsilon_start', default=0.95, type=float, help="initial value of epsilon")
parser.add_argument('--epsilon_end', default=0.01, type=float, help="final value of epsilon")
parser.add_argument('--epsilon_decay', default=500, type=int,
help="decay rate of epsilon, the higher value, the slower decay")
parser.add_argument('--lr', default=0.0001, type=float, help="learning rate")
parser.add_argument('--memory_capacity', default=100000, type=int, help="memory capacity")
parser.add_argument('--batch_size', default=64, type=int)
parser.add_argument('--target_update', default=4, type=int)
parser.add_argument('--hidden_dim', default=256, type=int)
parser.add_argument('--device', default='cpu', type=str, help="cpu or cuda")
parser.add_argument('--seed', default=520, type=int, help="seed")
parser.add_argument('--show_fig', default=False, type=bool, help="if show figure or not")
parser.add_argument('--save_fig', default=True, type=bool, help="if save figure or not")
parser.add_argument('--train_render', default=False, type=bool,
help="Whether to render the environment during training")
parser.add_argument('--test_render', default=True, type=bool,
help="Whether to render the environment during testing")
args = parser.parse_args()
default_args = {'result_path': f"{curr_path}/outputs/{args.env_name}/{curr_time}/results/",
'model_path': f"{curr_path}/outputs/{args.env_name}/{curr_time}/models/",
}
# 将参数转化为字典 type(dict)
arg_dict = {**vars(args), **default_args}
print("算法参数字典:", arg_dict)
# 创建环境和智能体
env, agent = create_env_agent(arg_dict)
# 传入算法参数、环境、智能体,然后开始训练
res_dic = train(arg_dict, env, agent)
print("算法返回结果字典:", res_dic)
# 保存相关信息
agent.save_model(path=arg_dict['model_path'])
save_args(arg_dict, path=arg_dict['result_path'])
save_results(res_dic, tag='train', path=arg_dict['result_path'])
plot_rewards(res_dic['rewards'], arg_dict, path=arg_dict['result_path'], tag="train")
# =================================================================================================
# 创建新环境和智能体用来测试
print("=" * 300)
env, agent = create_env_agent(arg_dict)
# 加载已保存的智能体
agent.load_model(path=arg_dict['model_path'])
res_dic = test(arg_dict, env, agent)
save_results(res_dic, tag='test', path=arg_dict['result_path'])
plot_rewards(res_dic['rewards'], arg_dict, path=arg_dict['result_path'], tag="test")
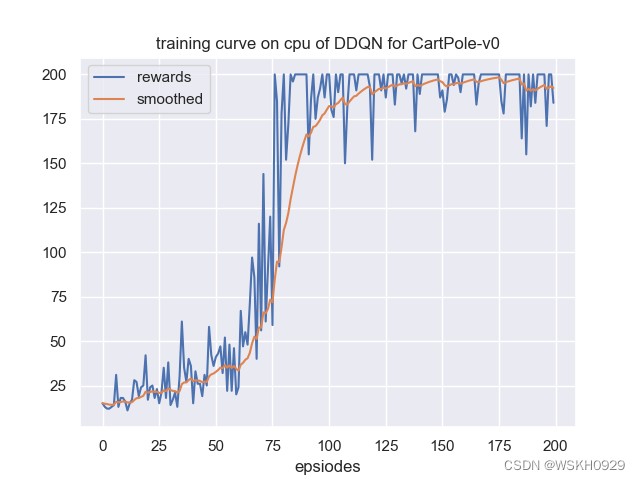
4.3 运行结果展示
由于有些输出太长,下面仅展示部分输出
状态数: 4, 动作数: 2
环境名: CartPole-v0, 算法名: DDQN, Device: cpu
开始训练智能体......
Begin to update!
Episode: 10/200, Reward: 18.00: Epislon: 0.694
Episode: 20/200, Reward: 42.00: Epislon: 0.447
Episode: 30/200, Reward: 38.00: Epislon: 0.284
Episode: 40/200, Reward: 36.00: Epislon: 0.162
Episode: 50/200, Reward: 36.00: Epislon: 0.092
Episode: 60/200, Reward: 20.00: Epislon: 0.049
Episode: 70/200, Reward: 116.00: Epislon: 0.021
Episode: 80/200, Reward: 178.00: Epislon: 0.011
Episode: 90/200, Reward: 200.00: Epislon: 0.010
Episode: 100/200, Reward: 200.00: Epislon: 0.010
Episode: 110/200, Reward: 200.00: Epislon: 0.010
Episode: 120/200, Reward: 152.00: Epislon: 0.010
Episode: 130/200, Reward: 183.00: Epislon: 0.010
Episode: 140/200, Reward: 200.00: Epislon: 0.010
Episode: 150/200, Reward: 187.00: Epislon: 0.010
Episode: 160/200, Reward: 200.00: Epislon: 0.010
Episode: 170/200, Reward: 200.00: Epislon: 0.010
Episode: 180/200, Reward: 200.00: Epislon: 0.010
Episode: 190/200, Reward: 182.00: Epislon: 0.010
Episode: 200/200, Reward: 184.00: Epislon: 0.010
训练结束 , 用时: 128.61002945899963 s
============================================================================================================================================================================================================================================================================================================
状态数: 4, 动作数: 2
开始测试智能体......
环境名: CartPole-v0, 算法名: DDQN, Device: cpu
Episode: 1/20,Reward: 200.00
Episode: 2/20,Reward: 200.00
Episode: 3/20,Reward: 200.00
Episode: 4/20,Reward: 167.00
Episode: 5/20,Reward: 200.00
Episode: 6/20,Reward: 161.00
Episode: 7/20,Reward: 163.00
Episode: 8/20,Reward: 200.00
Episode: 9/20,Reward: 165.00
Episode: 10/20,Reward: 200.00
Episode: 11/20,Reward: 200.00
Episode: 12/20,Reward: 200.00
Episode: 13/20,Reward: 200.00
Episode: 14/20,Reward: 155.00
Episode: 15/20,Reward: 183.00
Episode: 16/20,Reward: 153.00
Episode: 17/20,Reward: 200.00
Episode: 18/20,Reward: 200.00
Episode: 19/20,Reward: 200.00
Episode: 20/20,Reward: 200.00
测试结束 , 用时: 23.754974365234375 s

4.4 关于可视化的设置
如果你觉得可视化比较耗时,你可以进行设置,取消可视化。
或者你想看看训练过程的可视化,也可以进行相关设置



















 3342
3342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











