









文章目录
一、图片分类问题
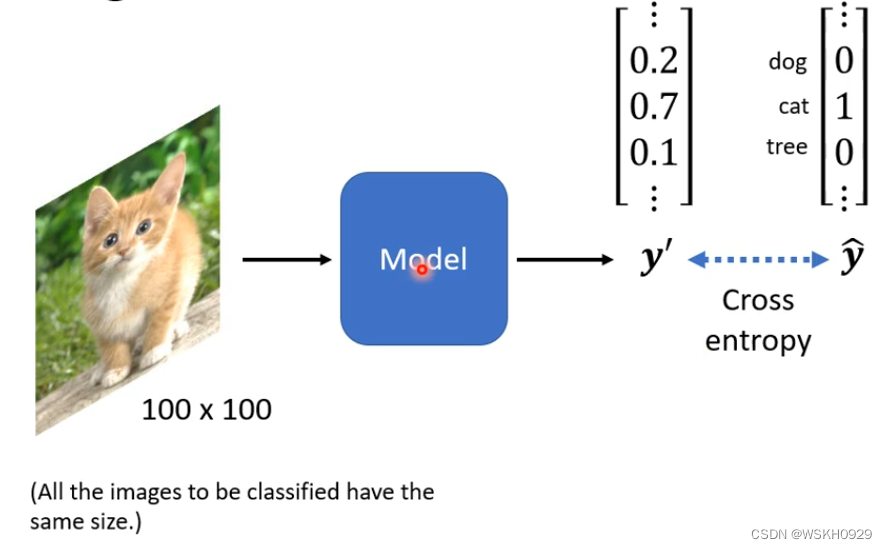
图片分类:输入一张图片,输出该图片的类别
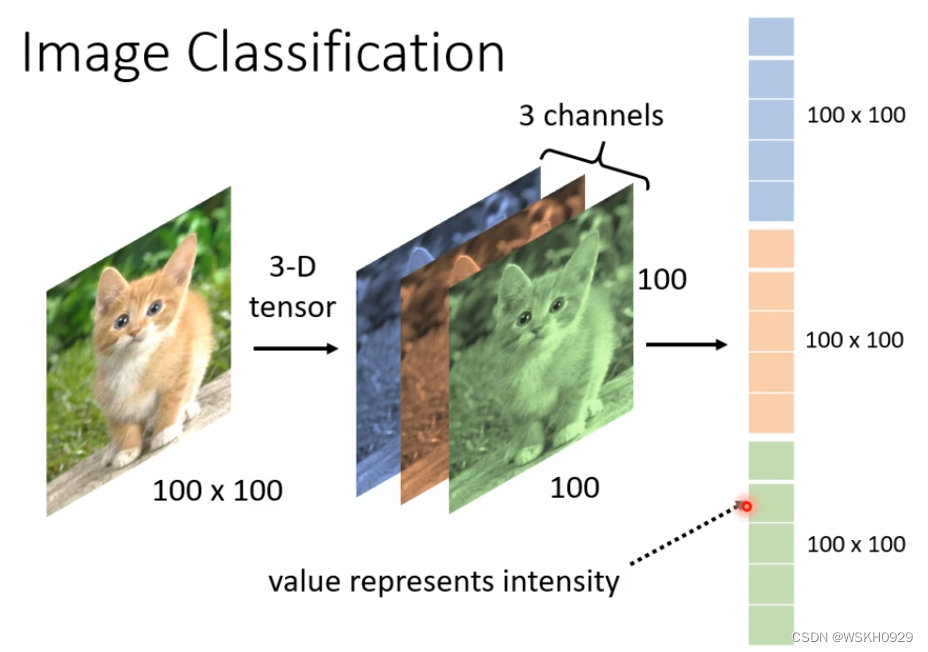
实际上,一张彩色图片是由RGB三个通道(channels)叠加而成的,每个通道都是 100 × 100 的大小,所以彩色图片是 3维 的,如下图所示
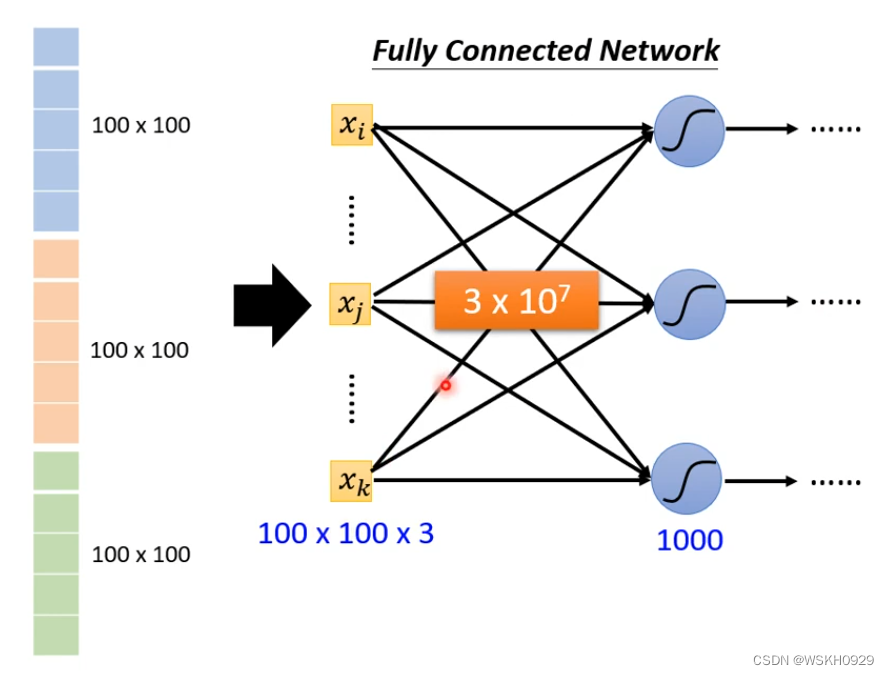
根据【深度学习】李宏毅2021/2022春深度学习课程笔记 - Classification(Short Version)这一节的介绍,我们可以很容易的想到,想要对图像进行分类,我们可以先将其展开、拉长为一条一维向量,如下图所示,再将展平的一维向量传给全连接网络进行训练。这是最简单最直觉的进行图像分类的方法。
二、观察图片分类问题的特性
2.1 观察1
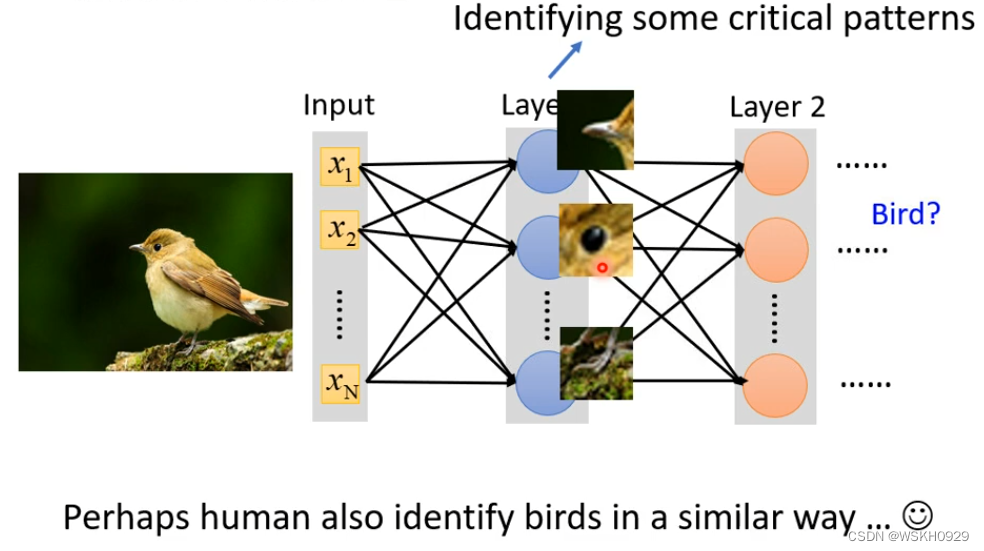
如图所示,假设我们想知道图片的类别是鸟,作为人类,我们要想分辨图中有没有鸟,我们会着重分别图中有没有鸟的某些明显的特征,比如我看到图中有鸟的头,我就认为图中有鸟,我看到图中有鸟的尖嘴,我也认为图中有鸟
下面给出了一个例子,我们可能第一眼看过去,看到了类似乌鸦头的特征,然后下意识地觉得这应该是鸟。但是仔细看才发现,噢原来还有猫头的信息,而且猫头的信息更大,所以最终我们会做出正确的判断,认为图像中的是猫

2.2 简化1:卷积
根据上面的叙述,我们知道,其实对于图像的识别,我们可能不需要用到图片上的所有信息,大多数情况,我们只需要看图片的一小部分就可以识别出图像的类别。
如下图所示,我们可能会对图片划分为一个一个的接受域(receptive field),然后不同的接受域传给不同的层去进行特征的提取和前向传播。
这个特征域是可以根据你要求解的图像分类问题的特性任意设定的,比如你要求解的图像分类问题的图像中的特征位于图片的左上角和右上角,那接受域你也大可不用设置为正方形,可以设置成两个正方形分开的一种特殊接受域。
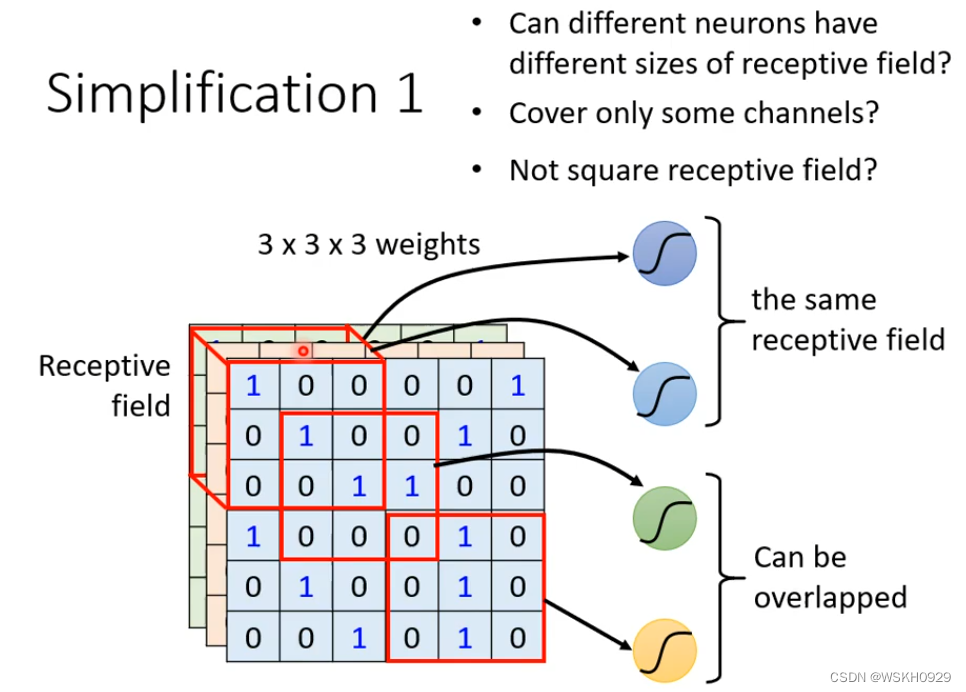
尽管接受域的设计有很多种方法,但实际上,大部分图片的特征都是紧挨着的,比如识别猫的头,那猫头的特征就是一片长方形像素所代表的。所以,在大部分情况下,我们的接受域都是设计一个长方形或者正方形。
下图就展示了最常用的接受域设计方法(正方形):接受域大小为3×3,对所有channels生效,每次移动步长为2,接受域超出图片的部分就用0填充(padding)
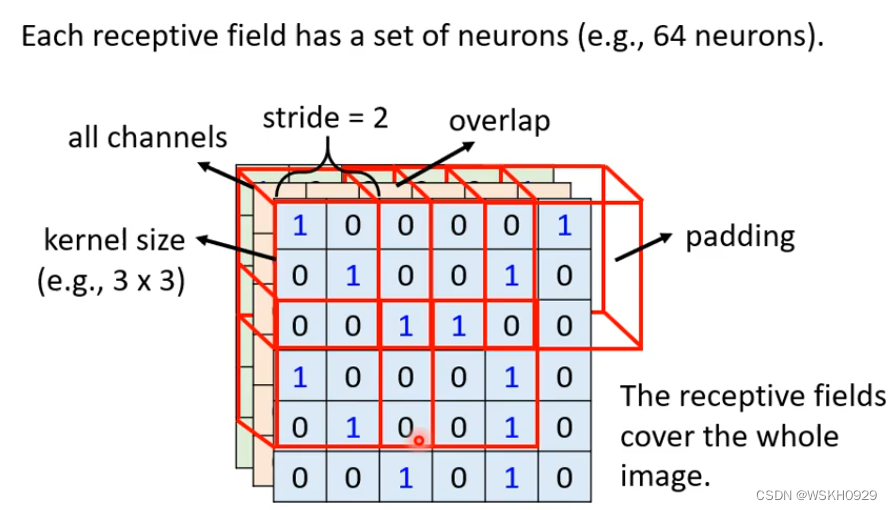
2.3 观察2
如下图所示。在不同图片中,鸟嘴的位置可能是不一样的,但是他们都代表了同一个特征,如果用不同的NetWork去侦测相同的特征,他们干的都是侦测鸟嘴,这样就会有点冗余
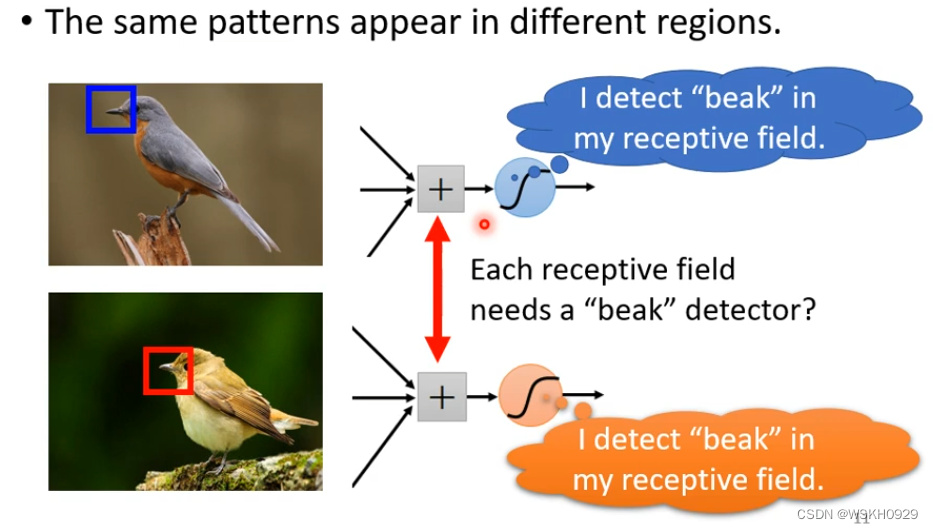
2.4 简化2:共享参数 - 卷积核
可以让两个NetWork共享参数,两个网络参数相同,但是由于侦测的地方不同,输入不同,也会使得输出不同,这样不会导致特征识别不到,还可以减少参数,减少模型冗余
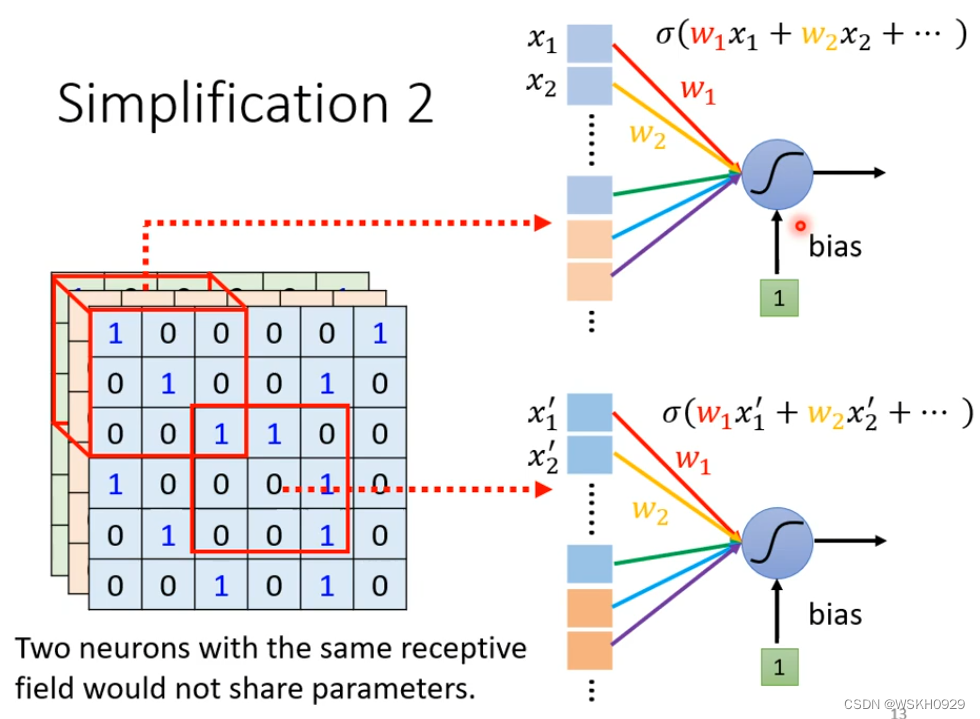
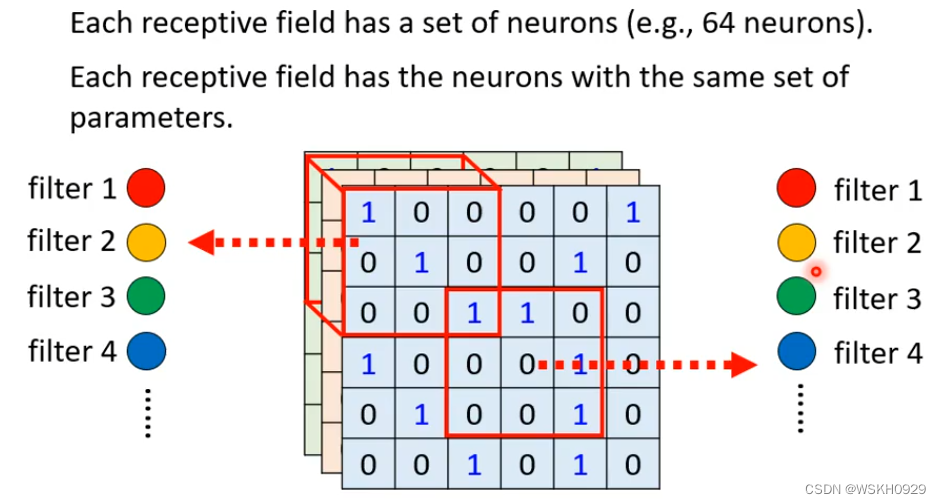
2.5 观察3
一张图片,进行适当的缩小之后,我们还是可以进行较为准确的识别。所以是不是意味着,我们可以对图片进行缩小,从而降低网络的学习难度,并达到比较好的预测效果呢?

2.6 简化3:池化
2.6.1 Max Pooling
最大池化指的是,在指定池化范围内,只保留最大值的像素点
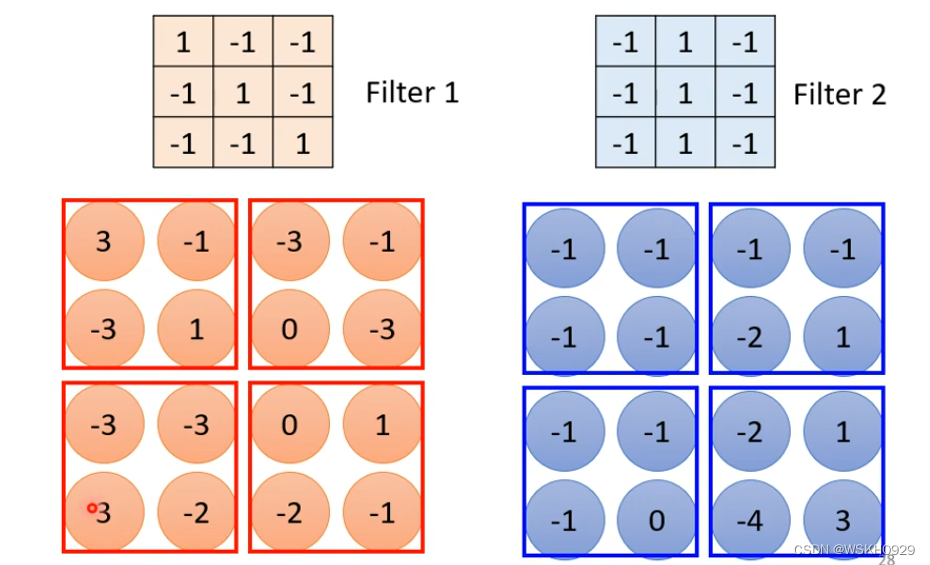
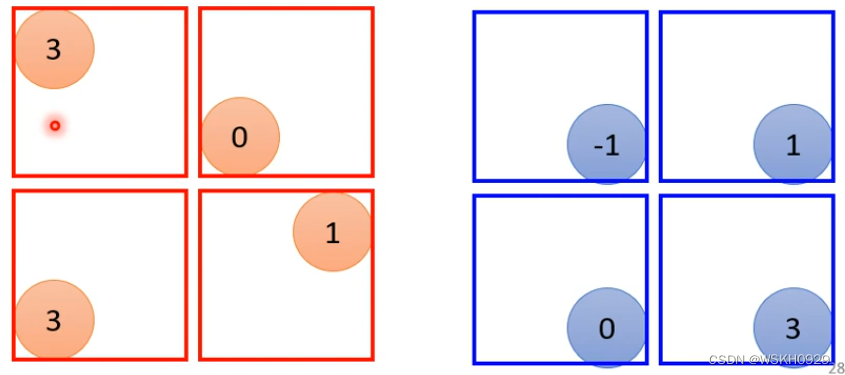
下面就是只保留了最大像素点的示意图。可见,图像数据得到了压缩
2.6.2 Mean Pooling
平均池化:就是在指定池化范围内,保留该范围内像素点的平均值
通常地,一般会在卷积层后接一个Pooling层,如此循环,构成CNN
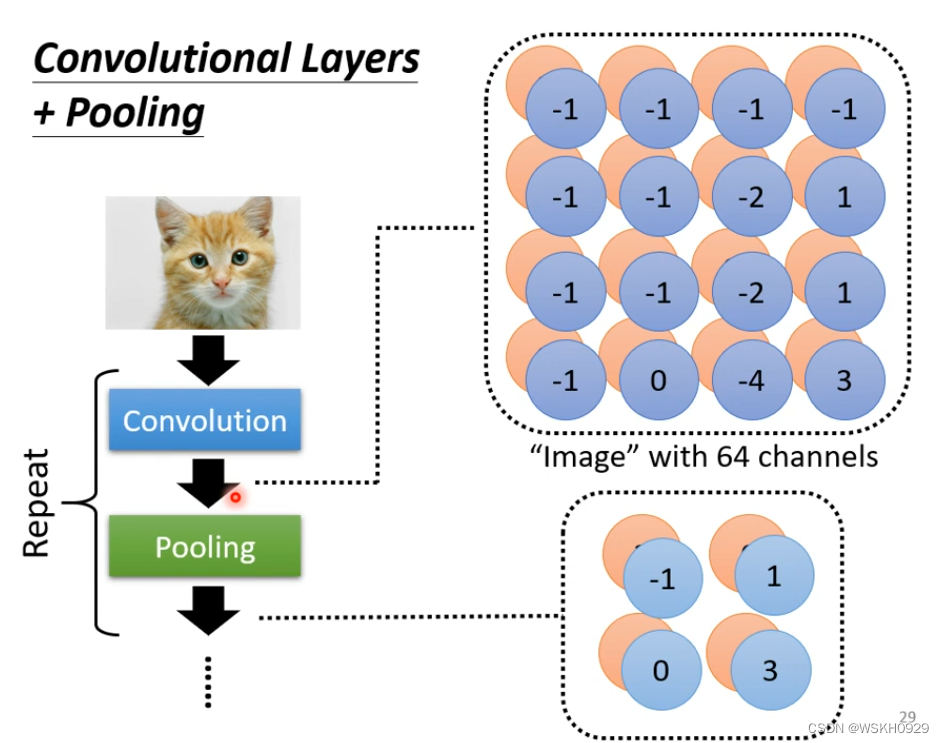
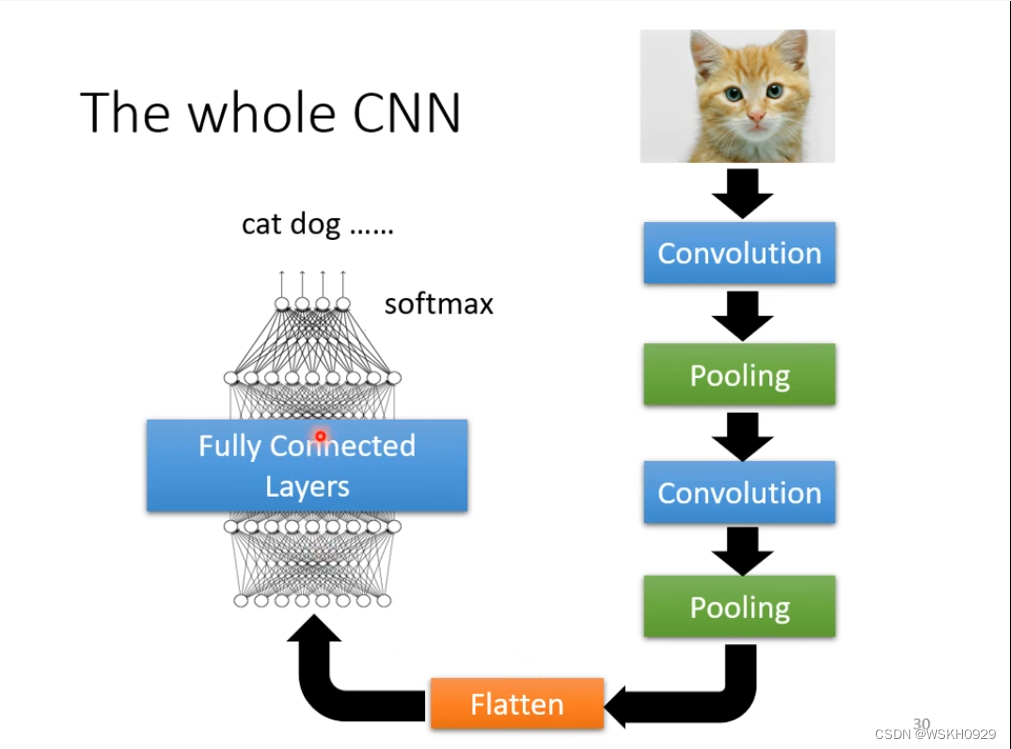
2.7 小结
全连接网络用来求解图像分类问题时,可以获取图片的所有信息,但是这样模型参数太大,很难Train起来,就算Train起来了,由于用到了图片上的所有信息,所以很可能出现过拟合现象。比如,同样的一只猫,可能因为背景的不同,网络就识别不好了,全连接网络不能较好地提取图像特征
卷积神经网络采用接受域和参数共享策略,降低了模型地参数,使得模型过拟合的风险大大降低,且具有较好的图像特征提取能力
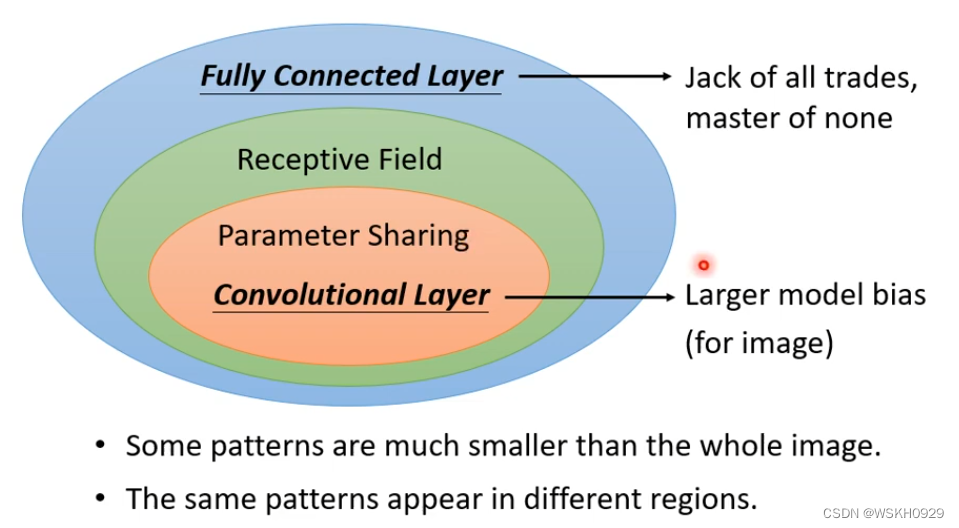
三、卷积工作原理
由于李宏毅老师教程里关于卷积工作原理部分我认为讲的不是很详细,所以大家可以看看下面链接里关于卷积工作原理的讲解
【深度学习】PyTorch深度学习实践课程笔记 - Lecture_10_Basic_CNN
四、CNN的其他应用
4.1 Playing Go
除了图像分类,CNN还可以用在下围棋上,把黑子作为1,白子作为-1,无子作为0,这样就可以构成一张Image,传入CNN,做一个19×19的分类问题,预测下一步要落子的位置
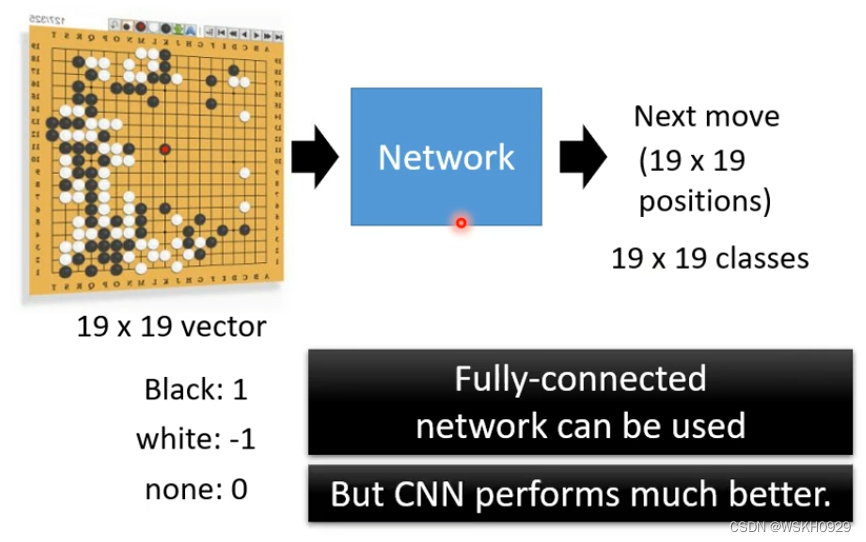
为什么CNN可以用在下围棋上呢?
因为围棋和图片一样,我们有时候可以只看一部分区域的局势,就可以推测出下一步要怎么下,所以可以用CNN

但是我们可以思考一个问题,CNN用在下围棋上时,能不能用Pooling?其实答案很明显,是不能的。这是因为如果我们把一盘棋缩小,相当于等间距的删去若干的行和列,这样子和原局势可能就相差甚远了啊!这也是围棋和图像上的一些不同。
果然,在Alpha Go的网络架构里,也没有采用Pooling,显然,网络架构的设计还是要根据问题而定,不是所有时候CNN都要加Pooling的,只有当Pooling后可以保证原始数据缺少较少的情况下才可以用。

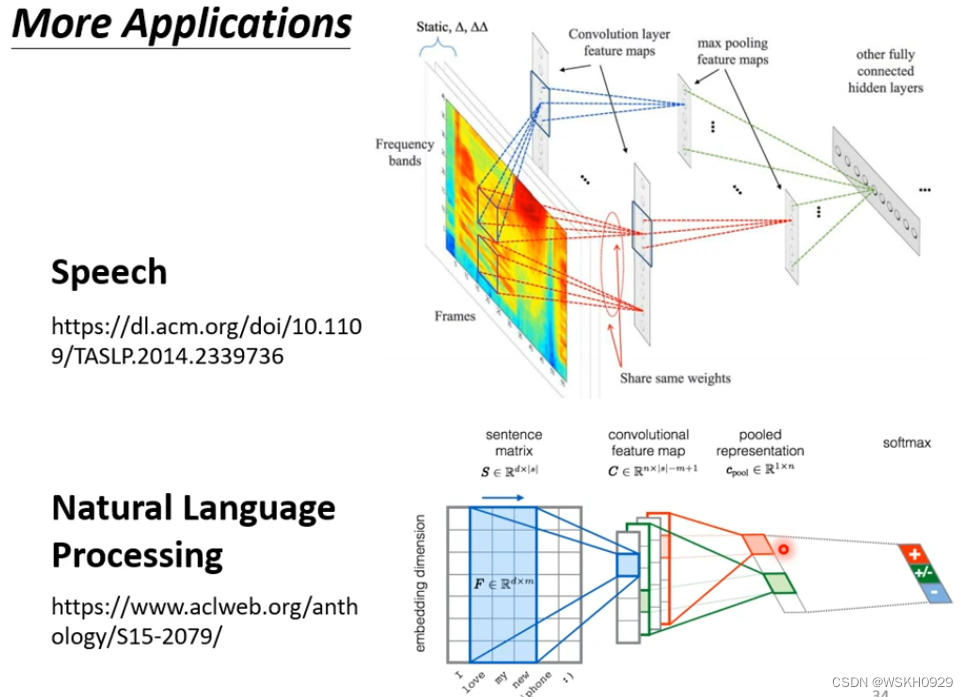
4.2 其他应用
- 语音领域
- 影像领域
五、To Learn More…
下图展示了CNN存在的问题。即它不能很好地处理图像的放大和缩小问题。
如下图所示,假设它能很好的识别上方的狗狗图片,但是将图片放大后,狗狗的特征范围发生了变化,这时候CNN就不一定能识别出狗狗了!有一个网络结构可以解决这个问题:Spatial Transformer Layer,详情见下方链接。

当然,如果非要用CNN,也可以采用一些方法缓解这个问题。例如,我们通常会在图像分类前,对训练数据进行数据增强,增强的方法包括图像旋转、图像平移、图像缩放、图像加噪声等等。目的就是让CNN尽可能多的在训练时就看过这些放大或缩小的情况,以至于测试的时候遇到放缩的情况也能较好的识别。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











