









文章目录
一、Problem Formulation
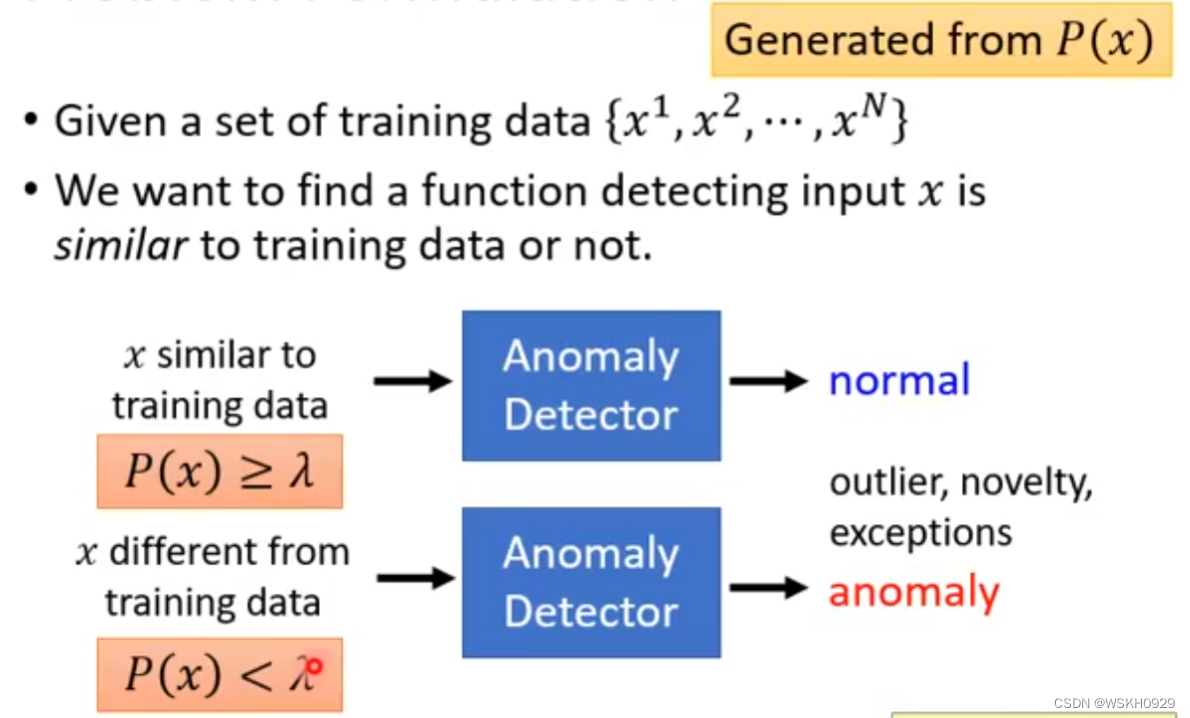
假设我们现在有N个训练资料,异常侦测要做的就是给定一个输入x,判断它是否和N个训练资料相似,如果不相似,可能就是异常资料
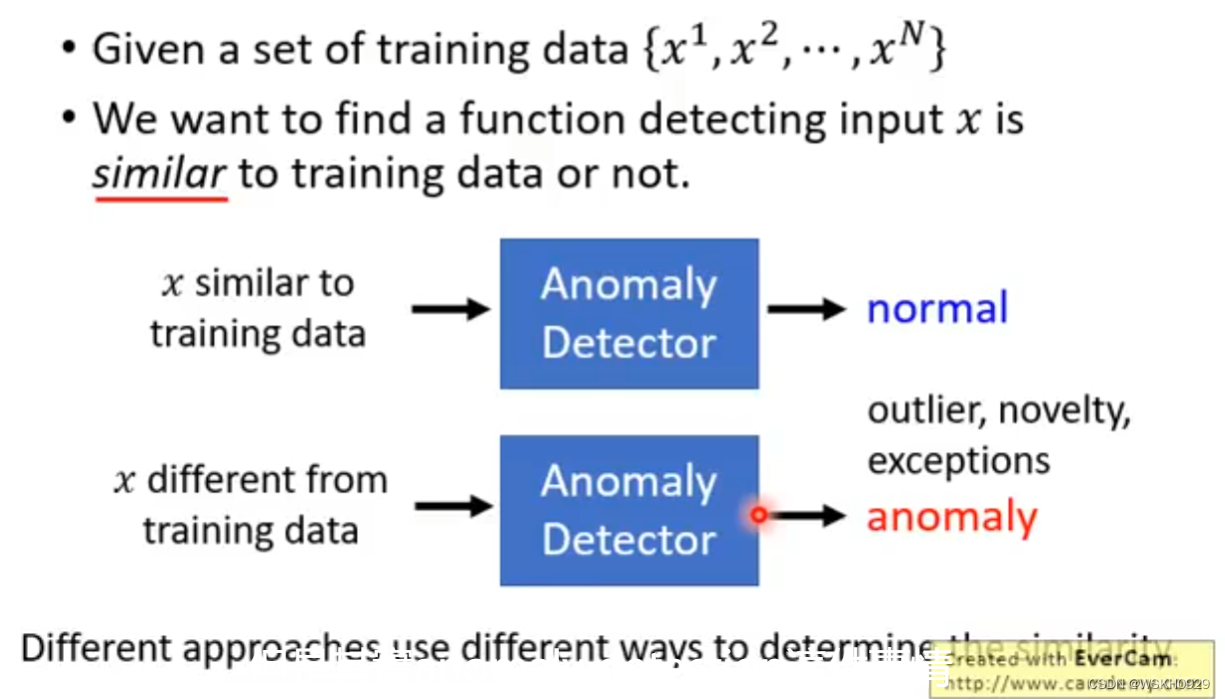
二、What is Anomaly?
如果训练资料是雷丘,那么皮卡丘就是异常的
如果训练资料是皮卡丘,那么雷丘就是异常的
如果训练资料是神奇宝贝,那么数码宝贝就是异常的

三、Applications
诈欺侦测:检测刷卡行为是否异常

网络攻击侦测:检测来访的请求是否异常

癌细胞侦测:检测是否出现癌细胞

四、Binary Classification?
做异常侦测最直觉的想法就是把它当作二分类问题来做,异常或者非异常。如下图所示

但是把异常侦测当作二分类问题来做有一个问题,就是异常能够被当作一个类别吗?假设正常资料是神奇宝贝,那么异常的资料可能是数码宝贝,可能是茶壶,总之可能是非神奇宝贝的任何类别。也就是说异常这个类别包括的范围太大了,只要不是神奇宝贝都可以视作异常。所以,通常来说,我们不能将异常侦测问题当作简单的二分类问题来解。

五、Categories
异常侦测的分类如下:
- 有标签的训练数据
- 无标签的训练数据
- 所有训练数据都是正常的
- 小部分训练数据是异常的

六、Case 1:With Classifier
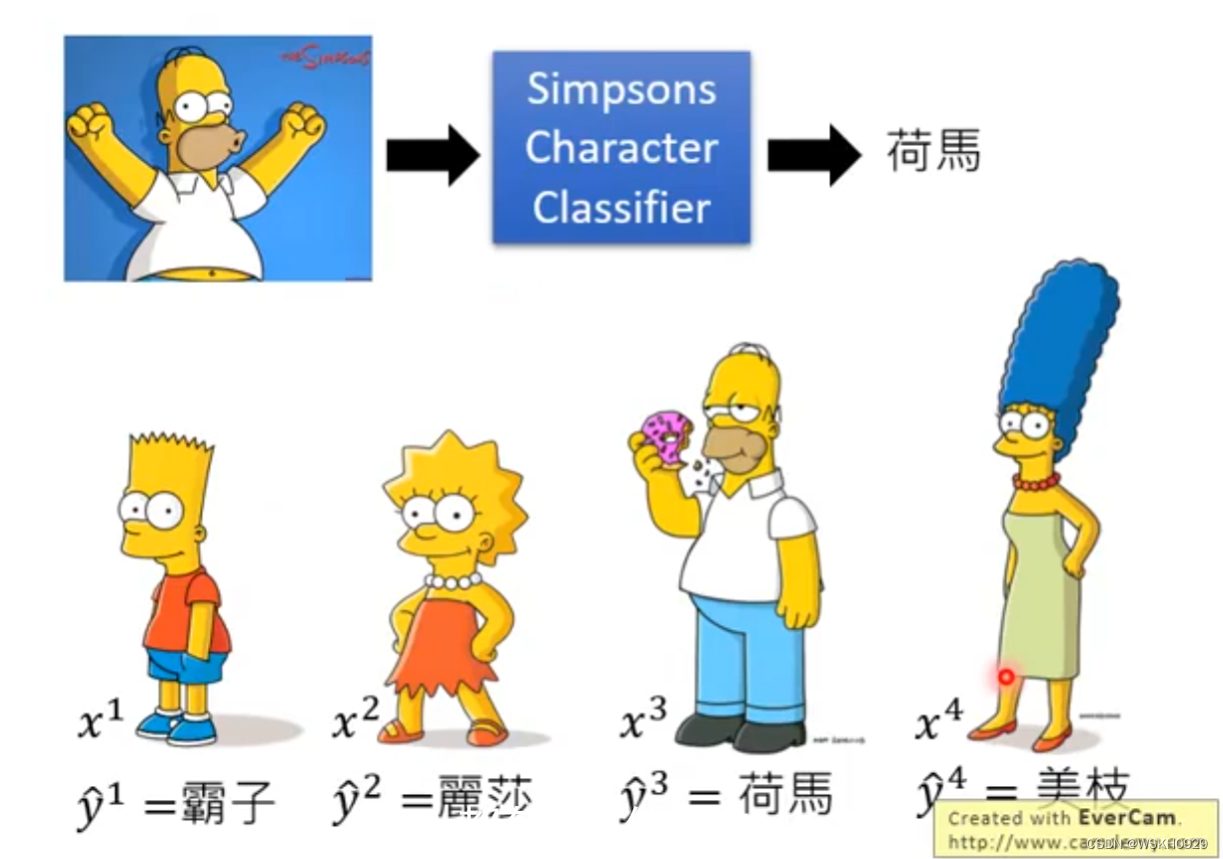
Case 1:检测数据是不是来自辛普森家庭

并且,训练数据还是有标签的
输出预测的类别和置信分数,如果置信分数低于设定的阈值,则说明是异常数据
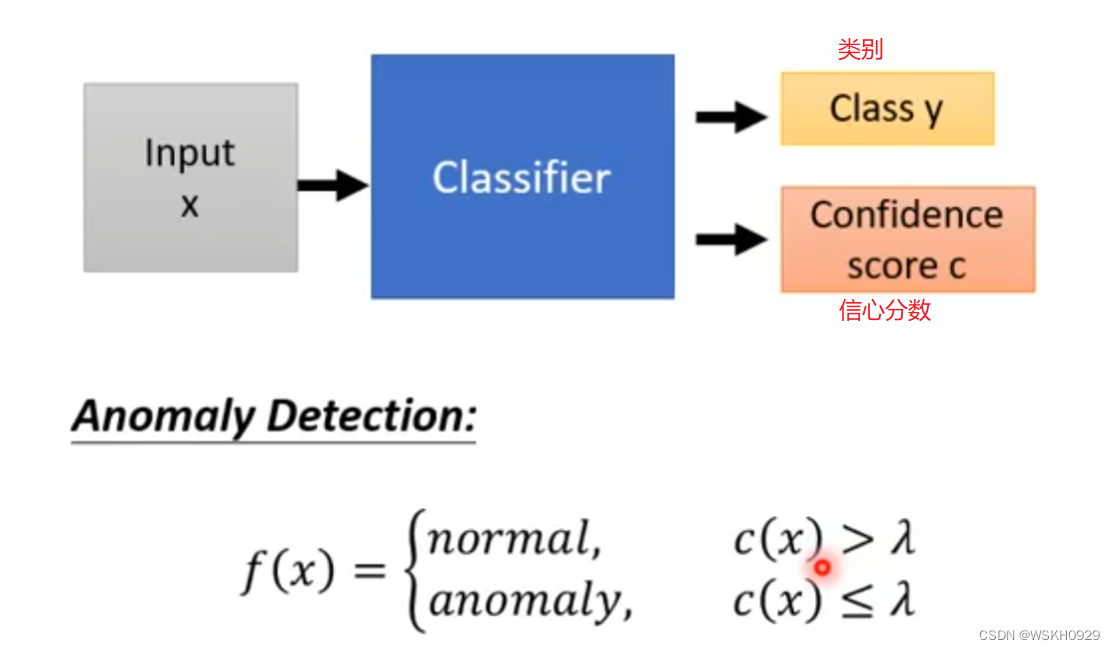
怎么确定置信分数呢?最简单的方法就是,拿输出的类别概率分布中最大的概率值作为置信分数。

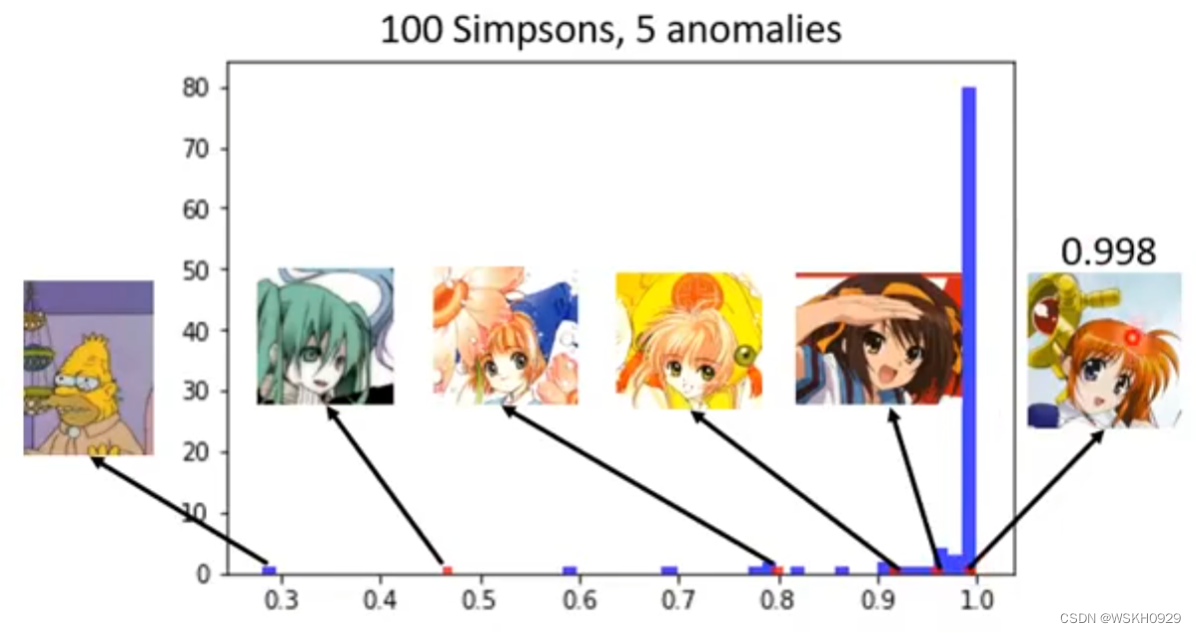
做一下测试发现,网络对辛普森家庭的成员输出的置信分数较大,而对于非辛普森家庭的成员输出的置信分数较小

当然也有例外

当然,我们也可以让网络直接输出置信分数和类别概率分布,如下图所示

训练资料:标签为属于辛普森家庭的哪个人物的图片
验证资料:标签为是否属于辛普森家庭的图片
测试资料:没有标签的图片,直接预测其是否属于辛普森家庭

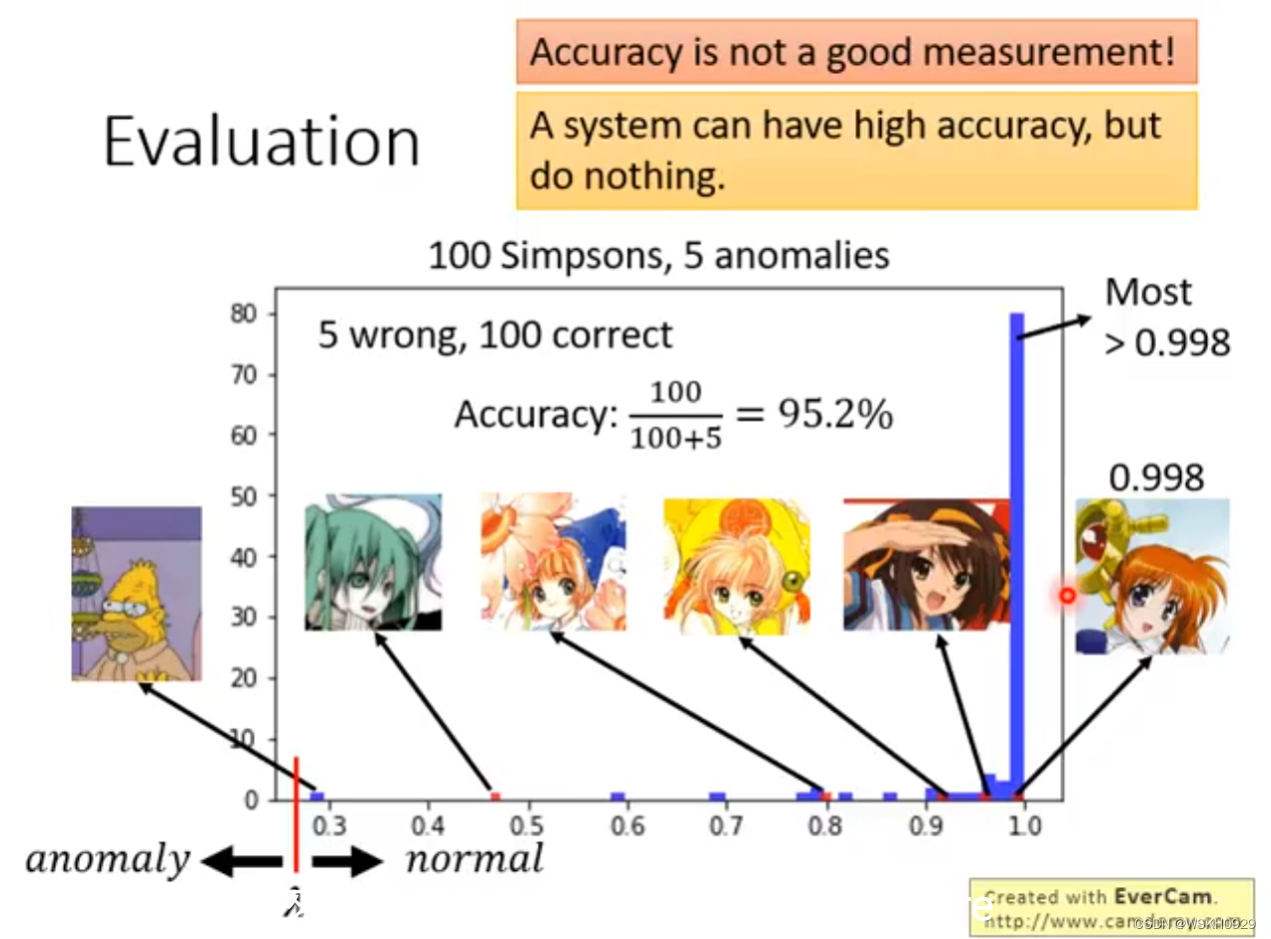
下面进行模型的评估。
在异常侦测任务中,我们往往不会拿正确率来衡量模型的好坏,因为异常数据的数量往往是比较少的,所以,即使模型将所有数据都认定为非异常的数据,算出来的正确率也是很高的
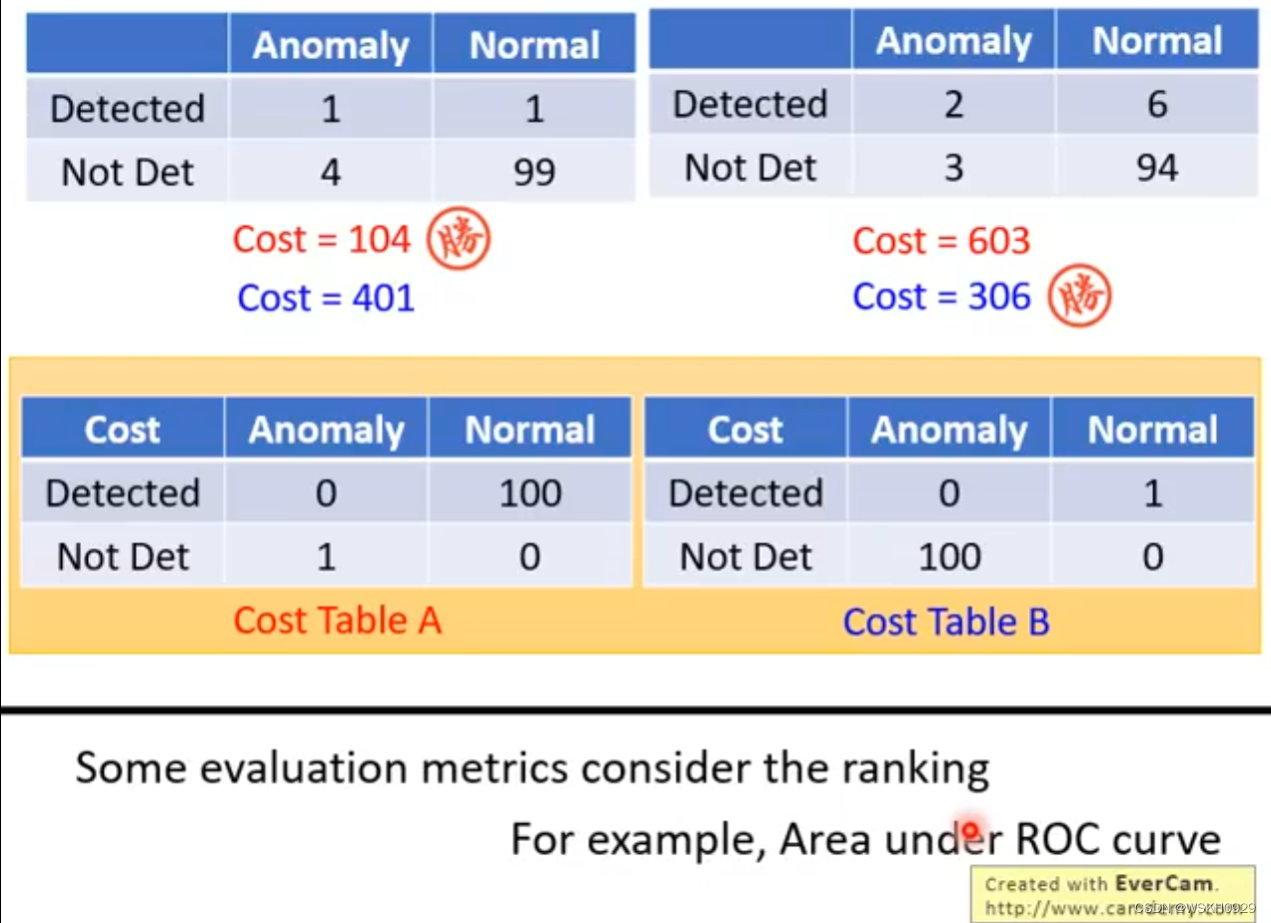
其他评价方法:AUC曲线、混淆矩阵
当然,异常侦测也会遇到挑战,比如当正常资料是猫的时候,给定一个老虎的图片,模型很可能会认为老虎是猫,因为老虎和猫确实是有相似的地方的。

另外,辛普森家庭的人脸特征就是黄色,如果我们将需要侦测异常的图片涂上一些黄色,那么模型就会给出很高的置信分数,因为模型可能认为只要有黄色的头发或者脸就大概率是辛普森家庭的人物

当然有些方法可以解决这个问题,如下图所示。我们希望机器可以学习到在遇到异常数据的时候给出较低的置信分数。但是这样就要求我们在训练的时候拥有较多的异常数据,但是异常数据往往是难以获取的。于是,有人想出了一招,用生成式网络来生成虚假的异常数据不就可以了吗!这个想法真是太棒了,但是要注意,生成的异常数据不能和真实数据太像噢,否则会干扰真实数据的判断。

七、Case 2:Without Labels
如下图所示,是一个风靡一时的游戏,玩法就是很多玩家共同控制同一个角色进行游戏。
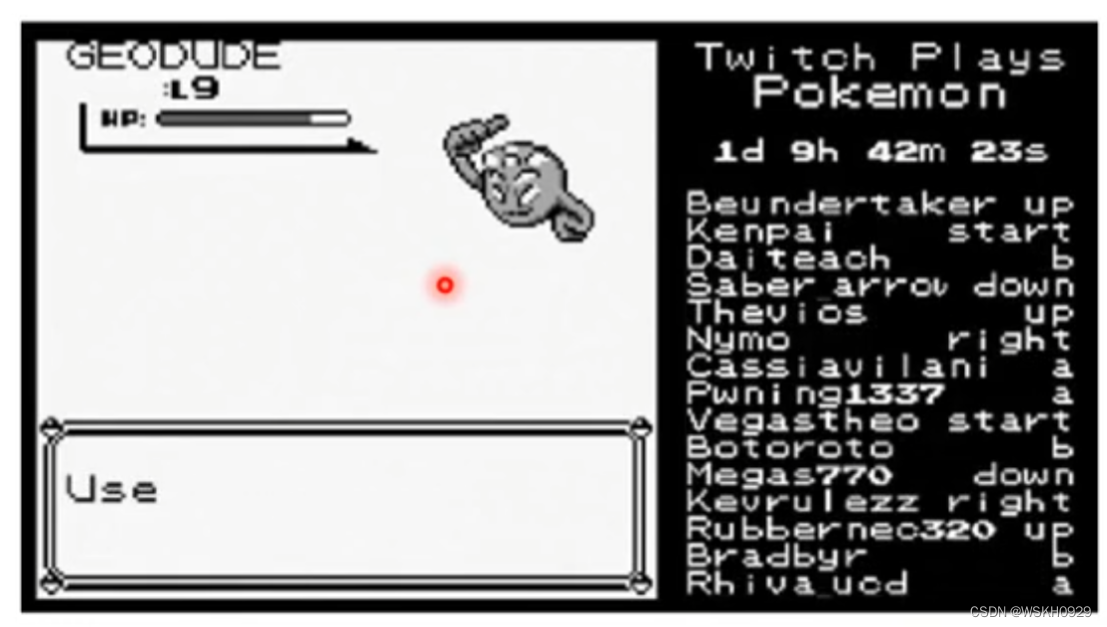
然而,人们相信,有一些小白藏在玩家之中,它们可能是由于不会玩这个游戏,导致按下的键会阻碍游戏的进程。在这个案例中,我们就希望通过异常侦测的手段,把这些小白的操作找出来。

由于训练数据是没有标签的,我们可以让模型输出一个实数,代表输入和训练数据的相似程度,当模型输出小于阈值时,则认为输入是异常的,否则输入是正常的
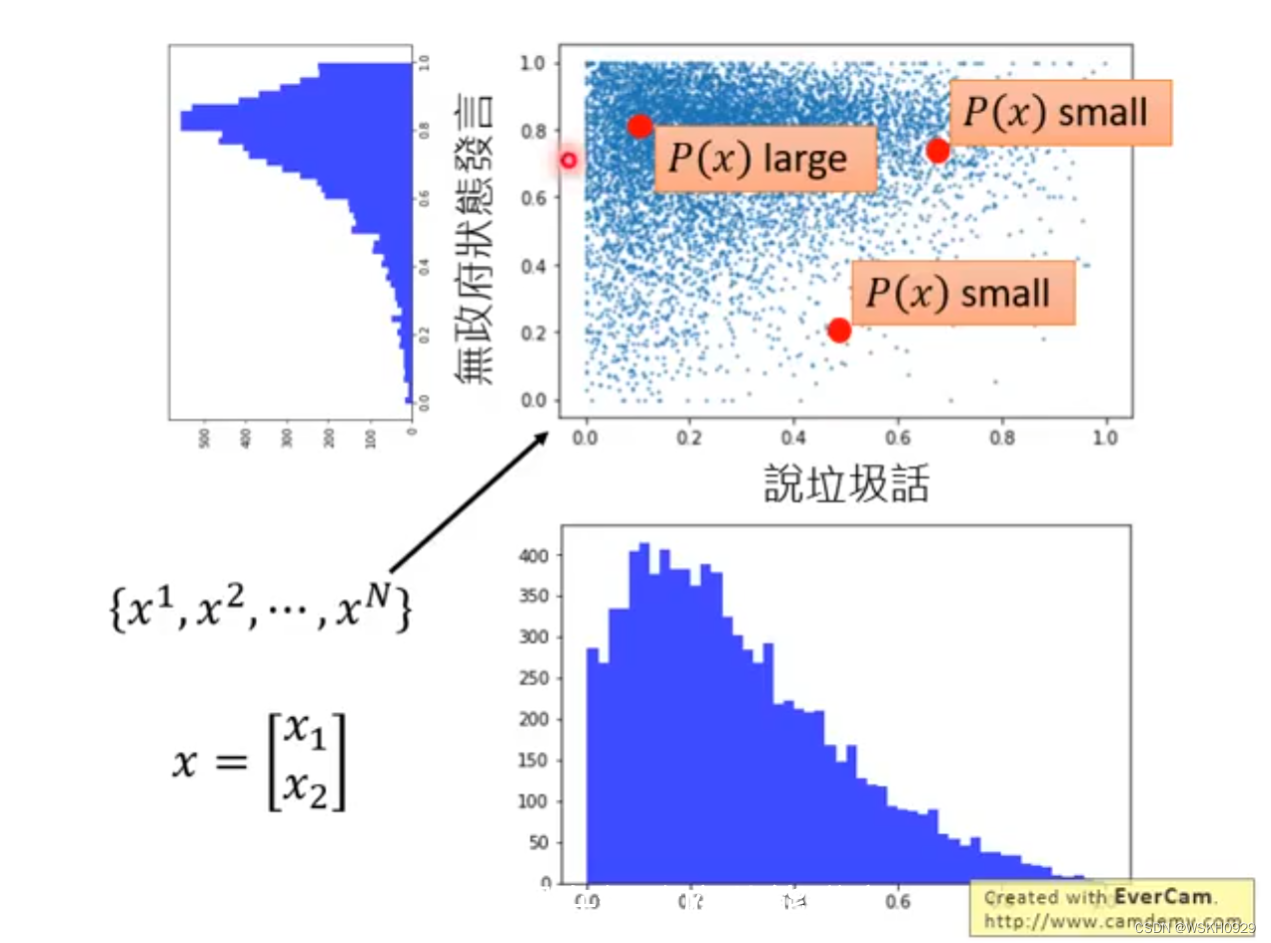
假设输入数据是一个二维向量,每个维度分别代表其说垃圾话的概率和在无政府状态下发言的概率。如下图所示,大部分人在无政府状态发言的概率较高,说垃圾话的概率较低。
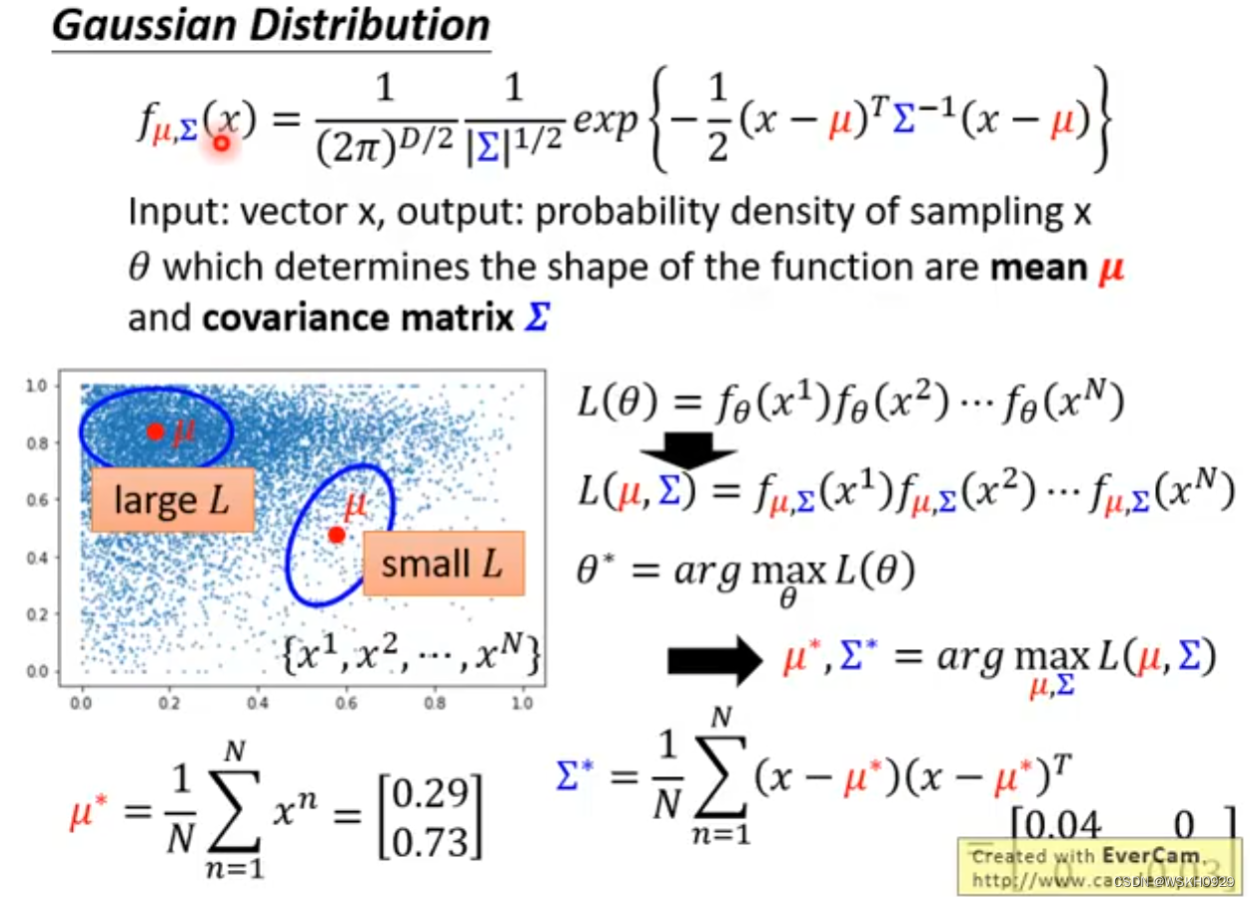
假设数据来自一个概率密度函数f,它由参数 θ \theta θ控制,我们的目标就是找到一个参数 θ \theta θ使得似然函数值达到最大

假设概率密度函数为高斯分布,那么我们可以直接根据公式算出使得似然函数最大的参数
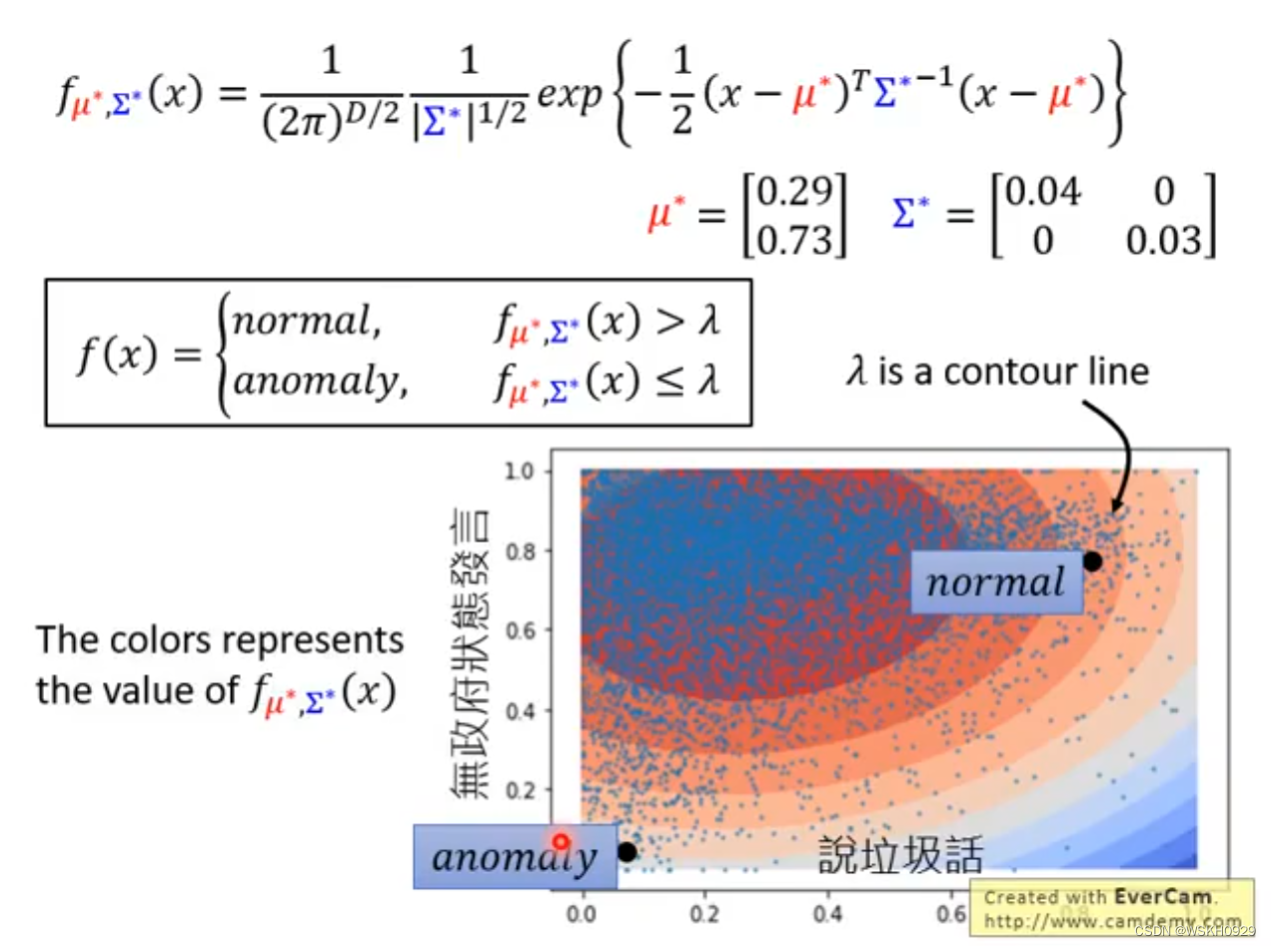
然后根据估计出来的参数,绘制数据x可能被该函数产生出来的概率热力图,颜色浅的地方说明由该概率密度函数产生出来的可能性小,也就代表很可能是异常数据
当然,我们还可以尝试为数据添加更多的特征,例如:跟大家一样的概率、唱反调的概率等

八、Use Auto-Encoder
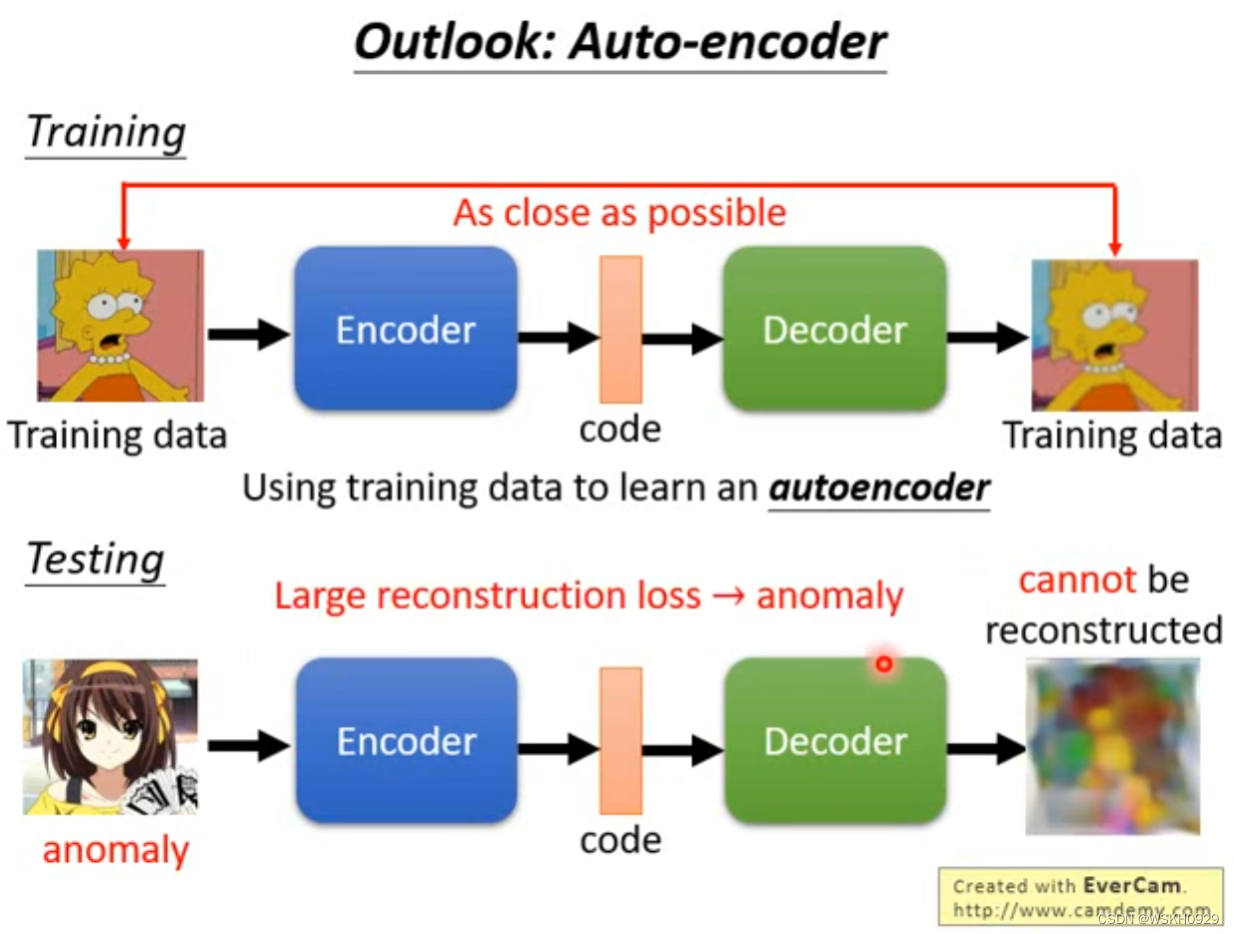
我们可以用Auto-Encoder的技术进行异常侦测。我们知道,Auto-Encoder在训练时的目标是让输入和输出尽可能相近。由于训练数据大部分都是正常数据,所以训练好的Auto-Encoder模型就具备了对正常数据较强的编码和解码能力。但是,如果输入的是异常数据,Auto-Encoder的解码结果可能就会和输入相差甚远,我们可以根据这个现象来判断输入数据是否为异常数据。
九、More

















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











