







2021 - Anomaly Detection (1_7)_哔哩哔哩_bilibili
異常偵測就是、我們要讓機器可以知道、我不知道這件事情

那在這門課裡面呢、我們通常用上標、來表示一個完整的東西、用下标,來表示一個完整東西的其中一個部份,
novelty这个词汇, 顯然是要找一個新的東西,比较正面的意思
什麼叫做像訓練資料呢、这就是Anomaly Detection里需要探讨的问题。不同的方法,它就用不同的方式來定義similar,
这里强调一下,這個所謂的異常、我們到底要檢測出什麼東西、其實是取決於你提供給機器什么样的训练资料,


那可能正常的交易它的金額都比較小、頻率都比較低、那如果今天在短時間內連續非常高額的消費、他可能就是一個異常的行為、
你的訓練資料就是正常的細胞、正常細胞它長什麼樣子、它的細胞核的大小、它的分裂的頻率等等、

why not 二元分类?
- 反正不是寶可夢的東西太多了、无法穷举所有可能不是寶可夢的东西,你根本沒有辦法知道你整個class 2整個異常的資料的分佈,异常资料无法视为一个类别,因为它的变化太大了,
- 异常data难收集,
Anomaly Detection是一個獨立的研究主題、是一個仍然尚待研究的問題、
异常检测问题大致分成两类,
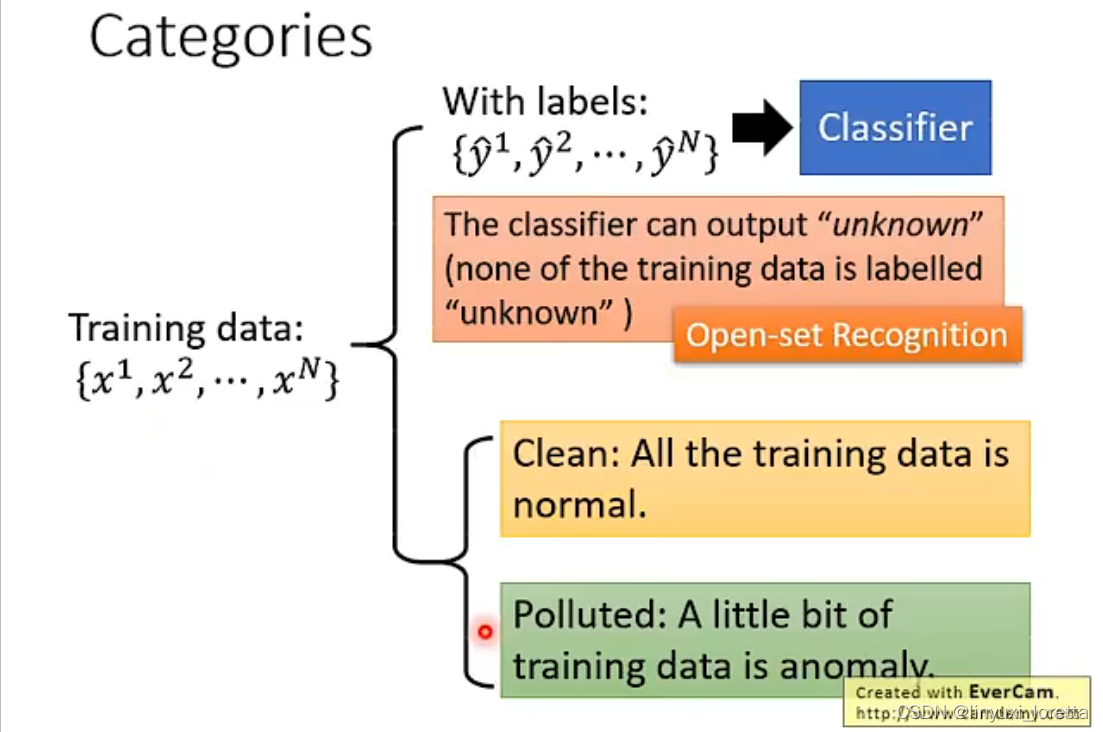
一类是有label的,
有label你就可以拿來訓練一個classifier、教機器說 看到這些x、能不能够预测出它對應的ŷ是什麼
怎么訓練一個classifier?我們上課有講過說 用generative model來做classification、也說過用logistic regression來做classification、还讲过用deep learning來做classification,就可以選一個你喜歡的技術,来訓練一個classifier,
但是在這邊的label裡面,並沒有任何一種label叫做unknown,
那如果 这个Classifier训练好后,如果看到训练数据中不存在的数据,那么可以为其打上【unknown】的标签。open-set recognition
那如果你是說 你有一個classifier,你希望這個classifier具有、看到不知道的東西 它會標上unknown的能力,那這個問題 它是異常偵測其中一種,又叫做open-set recognition
就是说,在做辨识的时候,你的model是open的、它可以辨識它沒有看過的東西、沒有看過的東西 它就貼上一個標籤說、这是没有看过的
另一类是有unlabel的,
又分为两类,clean和polluted,更多的時候 我們遇到的狀況是,我们手上的训练资料没有办法保证完全clean,可能有非常少量的訓練資料 比如說1%的、0.1%的訓練資料 它其實仍然是異常的
Case1:with classifier
判断卡通人物是否来自辛普森家庭
现在有数据及标签:

然后要训练分类器:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









