






具体步骤:
1.指定url网址
2.发送请求,访问网址
3.获取响应数据
4.持久化存储,保存在数据库或本地
在这里使用parsel模块处理爬取到的数据
import requests
import csv
import parsel #数据解析模块
if __name__ == '__main__':
f = open('top250.csv',mode='a',encoding='utf-8',newline='')
csv_write = csv.DictWriter(f, fieldnames=[
'电影',
'导演',
'演员',
'年份',
'国家',
'电影类型',
'评分',
'评价',
'简介',
'详情页',
])
csv_write.writeheader()
#请求链接
for a in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start='+str(a)+'&filter='
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
#发送请求
response = requests.get(url=url,headers=headers)
selector = parsel.Selector(response.text)
#获取所有的电影数据标签
list = selector.css('.grid_view li')#css选择器,根据标签的属性提取内容
#for循环遍历,提出所有元素
#提取一个标签类名为hd下面a标签下面第一个span标签里面的文本数据
#strip()字符串方法,去除左右两端空格
#split()以什么作为分割 ,返回列表
for li in list:
title = li.css('.hd a span:nth-child(1)::text').get() #电影名字
info_list = li.css('.bd p:nth-child(1)::text').getall() #电影所有信息
director = info_list[0].strip().split(' ')[0].replace('导演: ', '').split(' ')[0] #导演
performer = info_list[0].strip().split(' ')[1].replace('主演: ', '').split(' ')[0] #演员
year = info_list[1].strip().split(' / ')[0] #年份
country = info_list[1].strip().split(' / ')[1] #国家
file_type = info_list[1].strip().split(' / ')[2] #电影类型
fraction = li.css('.star .rating_num::text').get() #评分
evaluate = li.css('.star span:nth-child(4)::text').get().replace('人评价', '') #评价
word = li.css('.quote span.inq::text').get() # 简介
href = li.css('.hd a::attr(href)').get() #详情页
dit = {
'电影':title,
'导演':director,
'演员': performer,
'年份': year,
'国家': country,
'电影类型': file_type,
'评分': fraction,
'评价': evaluate,
'简介': word,
'详情页':href,
}
csv_write.writerow(dit) #写入数据
print(dit)
运行结果保存为csv文件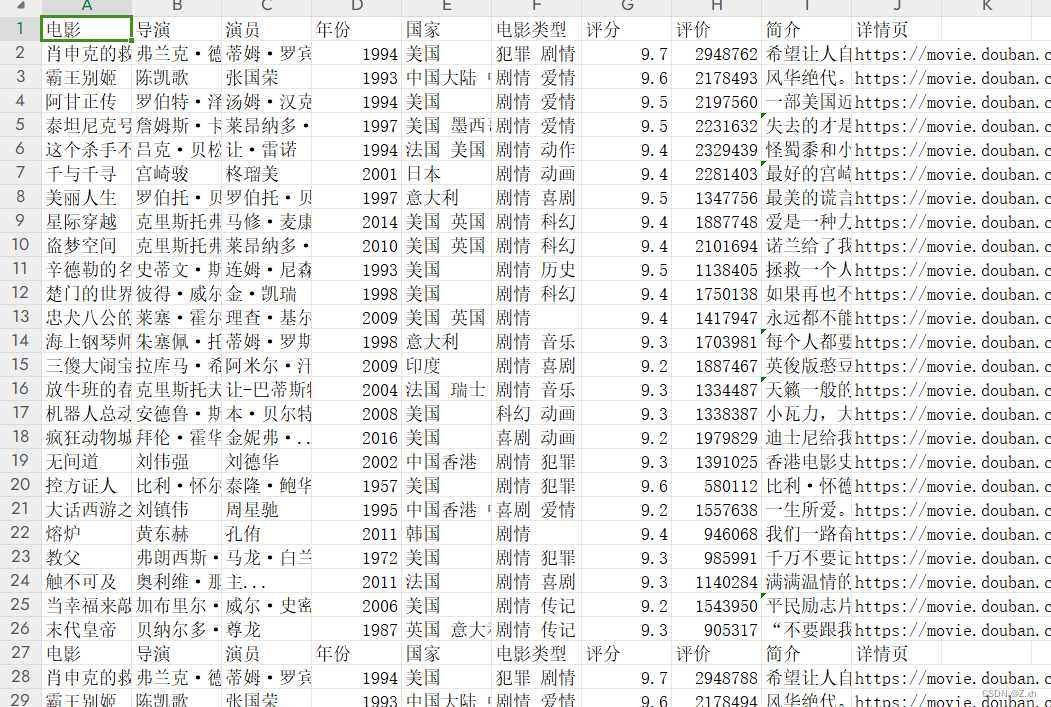 ,文件中查看
,文件中查看















 1958
1958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









