






具体步骤:
1.指定url网址
在这里随便点开B站首页推送的一个视频内容
打开开发者工具,下滑页面数据让数据加载出来,随便选择一条评论复制,粘贴到开发工具中的搜索框中,找到对应的包
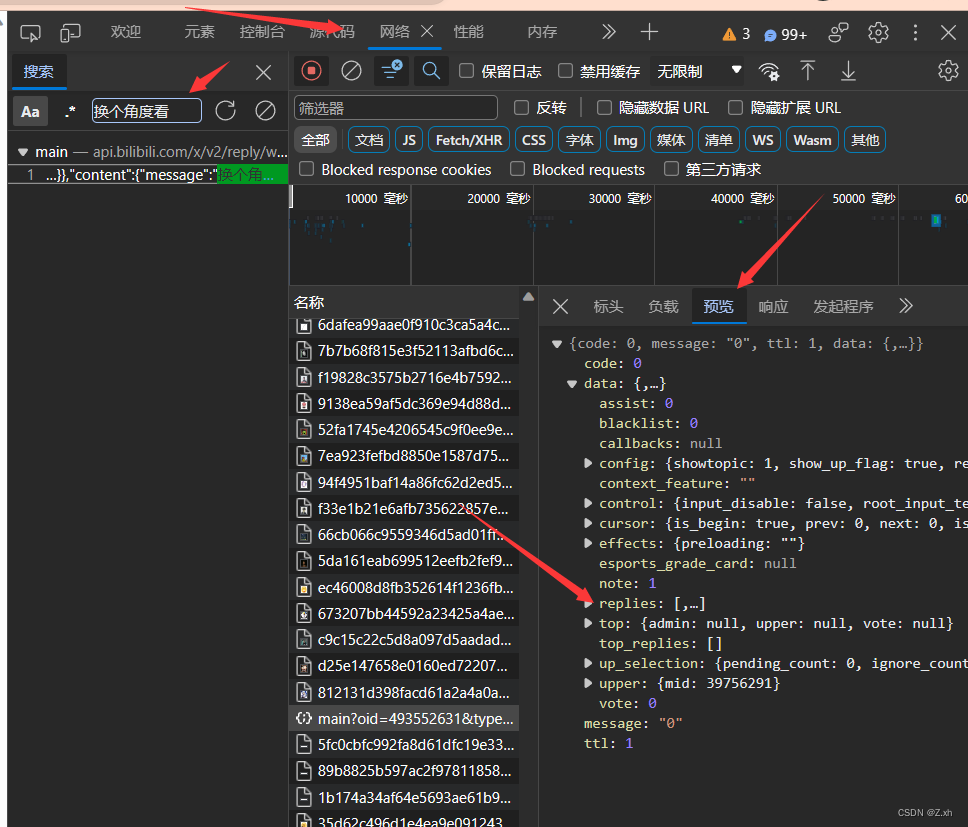
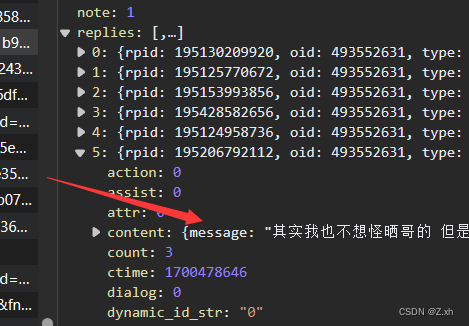
当前页面的评论信息在 replies中
拖过关键字确定链接
2.发送请求,访问网址
这里使用requests方法
3.获取响应数据
4.持久化存储,保存在数据库或本地
#爬取B站视频评论
import requests
import datetime
import csv
url = 'https://api.bilibili.com/x/v2/reply/wbi/main?oid=493552631&type=1&mode=3&pagination_str=%7B%22offset%22:%22%7B%5C%22type%5C%22:1,%5C%22direction%5C%22:1,%5C%22session_id%5C%22:%5C%221741908582826672%5C%22,%5C%22data%5C%22:%7B%7D%7D%22%7D&plat=1&web_location=1315875&w_rid=efb3a06c67206ab206699c14b68693b6&wts=1701082604'
if __name__ == '__main__':
#创建保存文件以及相关配置
f = open('data.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=[
'昵称',
'性别',
'签名',
'内容',
'发布时间',
'归属地',
])
csv_writer.writeheader()
headers={
'Cookie':#浏览器中的cookie
'Referer':'https://www.bilibili.com/video/BV16N411u76v/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=1702d37bb5ca4b1f33292dd3a16bb428',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
response = requests.get(url=url,headers=headers)
json_data = response.json()
for index in json_data['data']['replies']:
try:
#发布时间
date = str(datetime.datetime.fromtimestamp(index['ctime']))
dit={
'昵称':index['member']['uname'],
'性别':index['member']['sex'],
'签名':index['member']['sign'],
'内容': index['content']['message'],
'发布时间':date,
'归属地':index['reply_control']['location'].replace('IP属地:',''),
}
csv_writer.writerow(dit)
print(dit)
except:
pass爬取当前页面的评论信息,用户昵称,性别,前面,内容,发布时间,归属地等
爬取结果保存为csv文件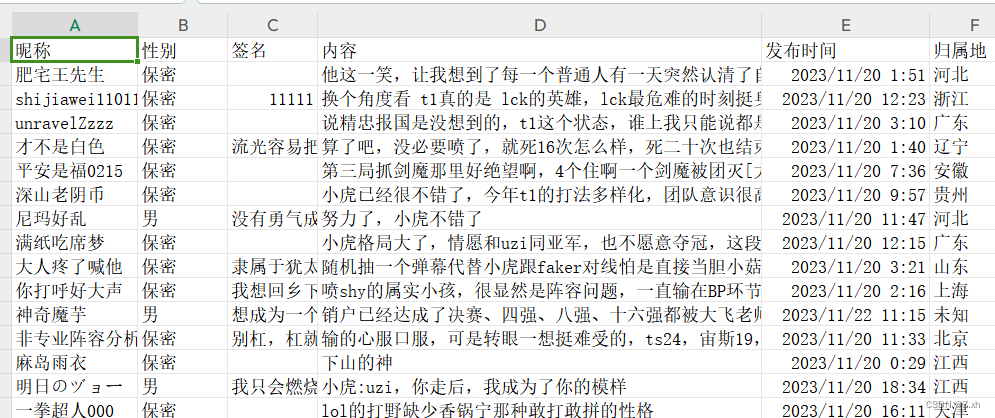
爬取当前页面评论

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









