







1.首先打开B站的首页,热门视频
2.按住F12打开浏览器的开发者模式,点击网络,旁边左上角有搜索框,刷新页面,搜索某一个热门视频的id,找到数据包
3.例如热门第一个视频,“爱意” 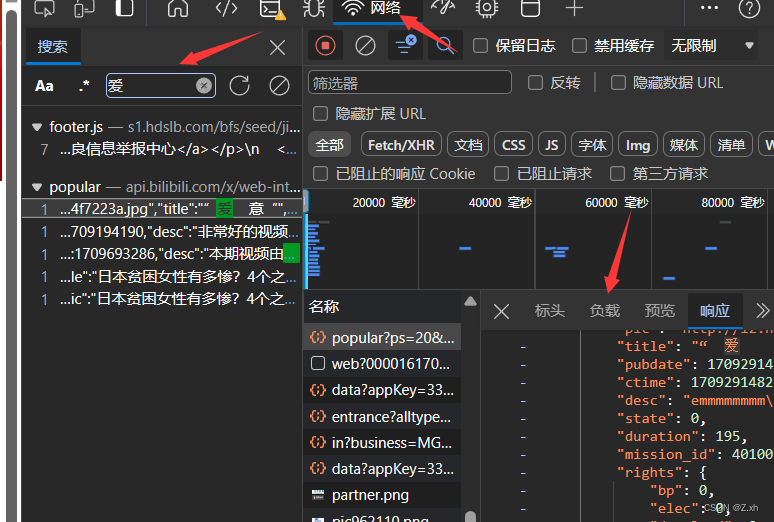
在标头能看到请求url,这也是要爬取的目标url
4.复制url地址,浏览器中打开,发现是json数据
5.其中的元素一一对应热门视频的信息


'视频标题':title,
'视频类型':tname,
'播放量':view,
'弹幕量':danmaku,
'评论数量':reply,
'收藏数量':favorite,
'投币数量':coin,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









