






接上一步
scrapy爬虫框架初实现爬取豆瓣电影top250-CSDN博客
创建成功scrapy项目后,左侧pipelines即为管道

1.使用管道将爬取到的数据写入Excel
打开 pipelines.py,里面自动有process_item,处理对象方法。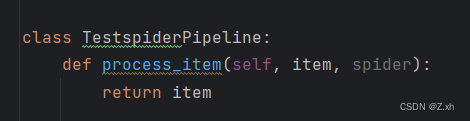
(1)pip install openpyxl 导入工具包
要将数据写入到Excel文件中,要先创造文件,写在构造方法中
(2)管道部分完整代码
from itemadapter import ItemAdapter
import openpyxl
class TestspiderPipeline:
def __init__(self):
self.wb = openpyxl.Workbook() #创建一个工作簿对象
self.ws = self.wb.active #拿到默认以及激活的工作表
self.ws.title = 'Top250' #改工作簿名字
self.ws.append(('名字','评分','简介'))
def close_spider(self,spider): #当关闭爬虫时候,保存工作簿
self.wb.save('电影数据.xlsx')
def process_item(self, item, spider):
title = item.get('title','') #若拿不到数据,给空字符串
rank = item.get('rank','')
subject = item.get('subject','')
self.ws.append((title,rank,subject))
return item(3)配置管道文件,再左侧的setting文件中,取消管道注释

(4) 在爬虫项目的终端中运行爬虫程序
scrapy crawl test1 程序结束后会生成excel文件
 查看文件,(最下方top250是定义的工作簿名字)
查看文件,(最下方top250是定义的工作簿名字)

2.使用管道将爬取到的数据写入Mysql数据库。
(1)首先启动数据库,在图形化界面中建立名为douban的数据库,表和表头
这里我用到的Navicat ,建立表和对应表头如图所示

(2)在左侧管道文件中,新建一个类,将数据导入到数据库
class DbPipeline:
def __init__(self):
self.conn = pymysql.connect(host='localhost',port=3306,user='root',password='123456',database='douban',charset='utf8mb4')
self.cursor = self.conn.cursor()
def close_spider(self,spider):
self.conn.commit()
self.conn.close()
def process_item(self,item,spider):
title = item.get('title', '') # 若拿不到数据,给空字符串
rank = item.get('rank', '')
subject = item.get('subject', '')
self.cursor.execute(
'insert into tb_top_movie (title, rating, subject) values (%s,%s,%s)',
(title,rank,subject)
)
return item(3) 配置管道文件,再左侧的setting文件中,加上刚写的数据写入数据库管道类

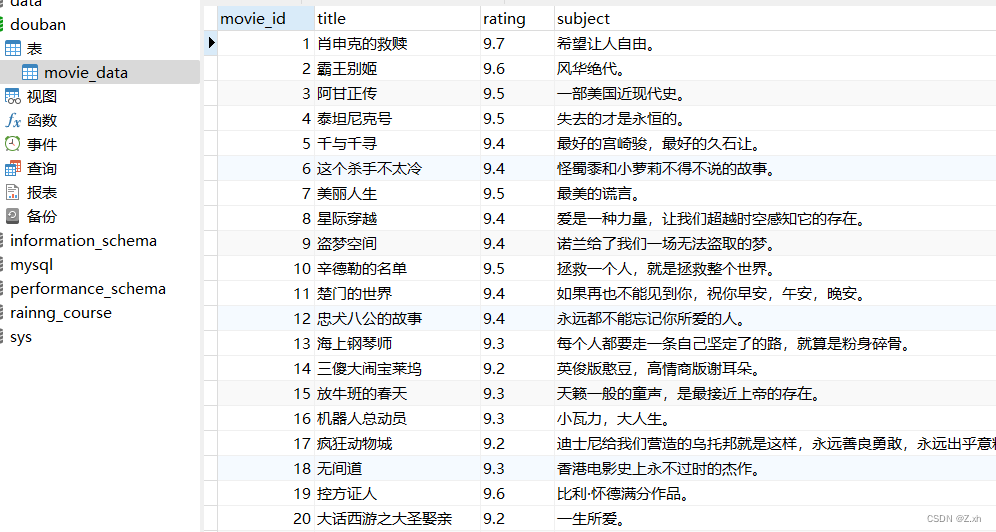
(4)运行程序,数据库中查看结果















 58万+
58万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









