






引言
大三的大数据导论老师要求进行爬虫的编写,为接下来的数据处理实验做准备,无奈自学爬虫,成功爬取b站的评论。
b站的反爬机制没有那么严格(单对于评论),并且还有官方的api接口可以获取(推荐方法),但是能爬还不如自己爬,正好锻炼自己写爬的能力
API接口获取
b站在2021年左右更新了api接口,从以前的简单的
https://api.bilibili.com/x/v2/reply/更新到了新的接口。
使用f12检测如下操作:当向下滚动页面有新的评论出现时,检测网络请求变化

发现这个请求里涉及到了“replay”,可能与”回复“ 或 “评论”有关。
经多次尝试得到请求接口:
url = f'https://api.bilibili.com/x/v2/reply/main?
next=1&
type=1&
oid=BV1T5411K7Wc&
mode=3'b站返回的评论都是一页为一个json,默认为10条为一页,next = 1 意味着当前是第一页
type = 1:必须,但是作用未知。
oid:视频的bv号。
值得注意的是,以前的oid需要的是由bv号转化得来的avi号,但是现在的接口不需要了。
mode = 3:返回的api 的版本(最新是3)
User - Agent 获取(必须)
b站的反爬机制很简单,只需要User-agent与其要求格式可以对应即可。
每一次在网页上对网页做出请求时,都会有一个不同的user-agent,这也是想要使用api的必要条件。
获取方法:
打开你想爬取的视频,翻到评论区,右键,检查,打开网络监测页面
不播放视频,将评论区下滑,发现右侧出现了新的请求,打开main开头的请求。
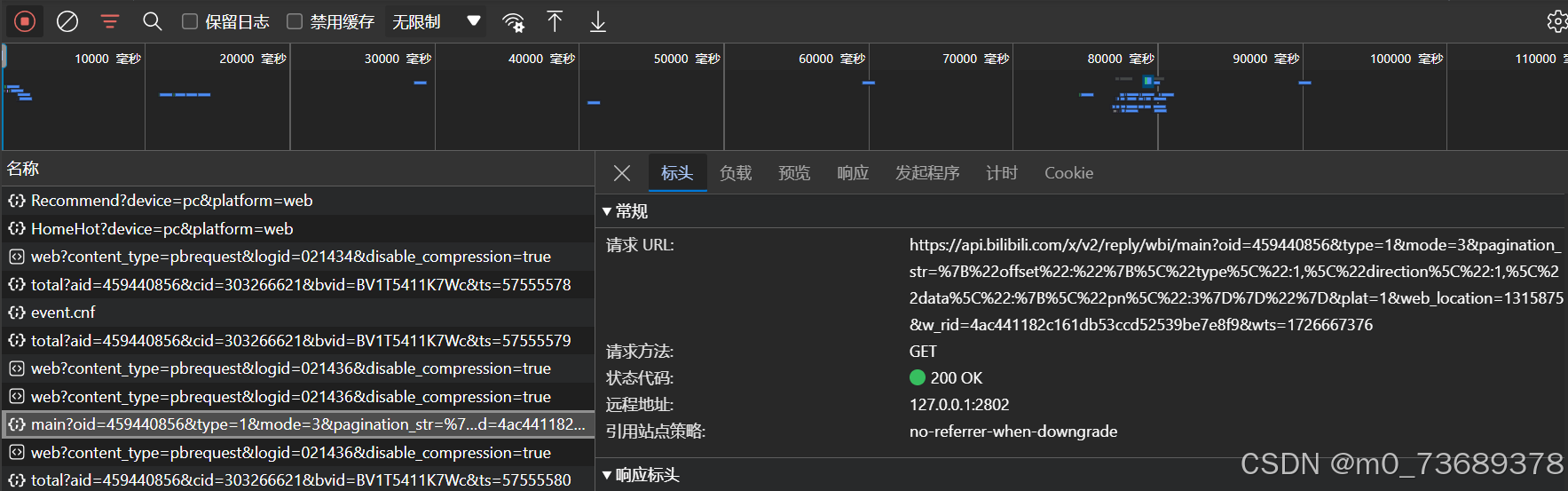
随后在右侧-标头页面,向下滑
在请求标头下找到最下面的user-agent:
![]()
直接将其复制。
代码(需要有自己的user-agent)
import requests
import re
import time
import csv
import json
headers = {
'User-Agent': '使用你自己的user-agent'
}
def fetch_comments(video_id, max_pages=1000):#最大页面数量可调整
comments = []
last_count = 0
for page in range(1, max_pages+1):
url = f'https://api.bilibili.com/x/v2/reply/main?next=1&type=1&oid={video_id}&mode=3'
try:
# 添加超时设置
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
data = response.json()
print(page)
if data['data']['replies'] == None:
break
if data and 'replies' in data['data']:
for comment in data['data']['replies']:
comment_info = {
'用户昵称': comment['member']['uname'],
'评论内容': comment['content']['message'],
'被回复用户': '',
'评论层级': '一级评论',
'性别': comment['member']['sex'],
'用户当前等级': comment['member']['level_info']['current_level'],
'点赞数量': comment['like'],
'回复时间': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(comment['ctime']))
}
comments.append(comment_info)
if last_count == len(comments):
break
last_count = len(comments)
else:
break
except requests.RequestException as e:
print(f"请求出错: {e}")
break
# 控制请求频率
time.sleep(1)
return comments
def save_comments_to_csv(comments, video_bv):
with open(f'./result/{video_bv}.csv', mode='w', encoding='utf-8',
newline='') as file:
writer = csv.DictWriter(file,
fieldnames=['用户昵称', '性别', '评论内容', '被回复用户', '评论层级', '用户当前等级',
'点赞数量', '回复时间'])
writer.writeheader()
for comment in comments:
writer.writerow(comment)
video_name = '你想要的视频名字' # 视频名字
video_bv = '视频的BV号' # video_bv
print(f'视频名字: {video_name}, video_bv: {video_bv}')
comments = fetch_comments(video_id)
save_comments_to_csv(comments, video_name)# 会将所有评论保存到一个csv文件

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









