






我完整具体步骤
1.请求标头,伪装浏览器身份
2.确定请求的路径,根据路径获得网页源代码的html文件
3.解析html,获得对应的图片地址,再一次请求图片地址,保存到本地
构造请求头,伪装浏览器,(这里只用ua伪装的话会被挡)
headers={
'Accept-Encoding':'gzip, deflate, br',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}找到目标图片所处的位置
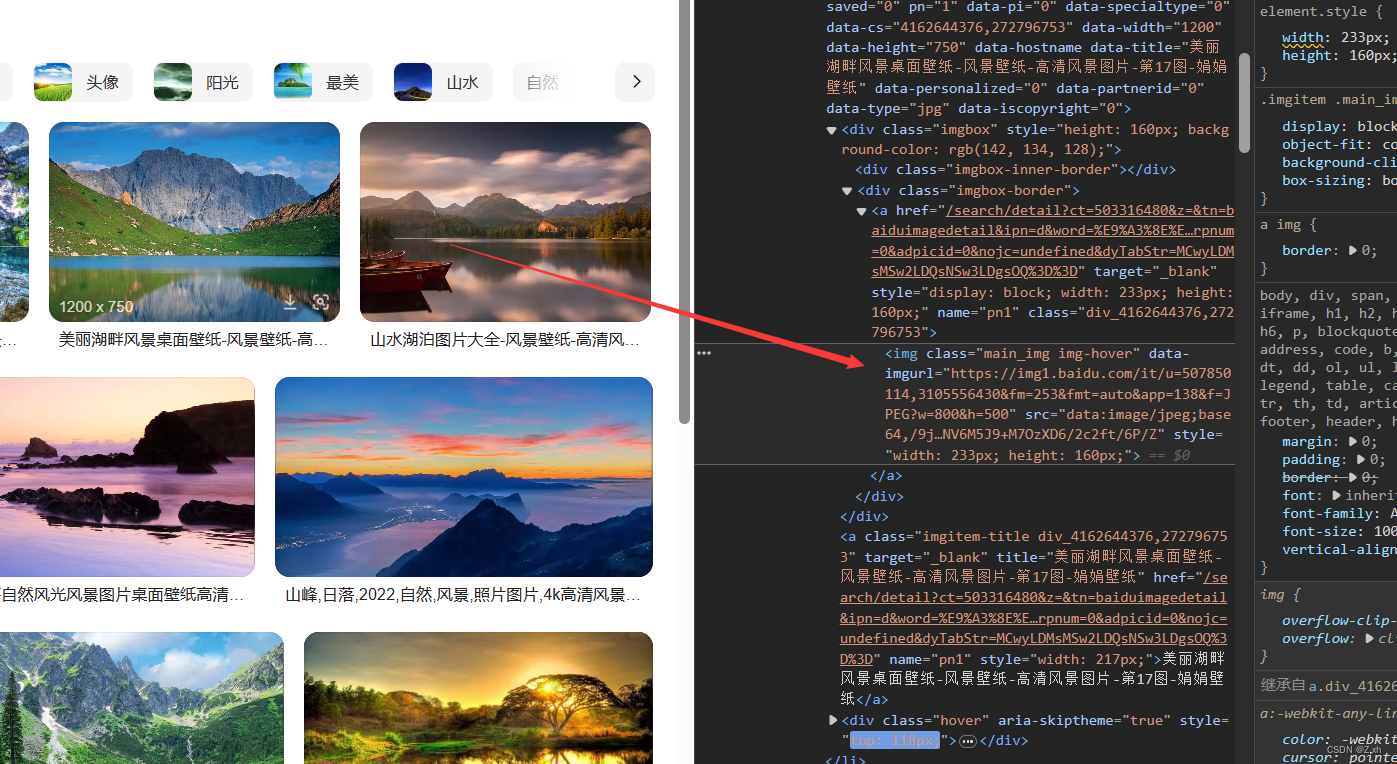
完整代码,不断爬取图片,可手动暂停
import requests
import re
import os
import time
headers={
'Accept-Encoding':'gzip, deflate, br',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-',
'Accept-Language':'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1701837432375_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=MCwyLDMsMSw2LDQsNSw3LDgsOQ%3D%3D&ie=utf-8&sid=&word=%E9%A3%8E%E6%99%AF%E5%9B%BE%E7%89%87'
html = requests.get(url=url,headers=headers)
html.encoding = 'utf-8'
html = html.text
img_url_list = re.findall('"objURL":"(.*?)"',html)
img_path = "./nature/"
if not os.path.exists(img_path):
os.mkdir(img_path)
count=0
for i in img_url_list:
img = requests.get(i)
count+=1
print("正在爬取第", count, '张')
file_name = f'{img_path}图片{str(count)}.jpg'
f = open(file_name, 'wb')
f.write(img.content)
time.sleep(0.5)查看爬取结果
















 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









