






50%A100开发机
文章目录
前言
本博客是第四期书生大模型实战营进阶岛的第四个大任务,我们将学习多模态大模型的基本原理,并用给定数据集利用XTuner微调InternVL2-2B,用LMDeploy部署多模态大模型。
一、多模态大模型简介

多模态大语言模型(Multimodal Large Lanquage Model)是指能够处理和融合多种不同类型数据(如文本、图像、音频、视频等)的大型人工智能模型。这些模型通常基于深度学习技术能够理解和生成多种模态的数据,从而在各种复杂的应用场景中表现出强大的能力。
多模态大模型研究的一个关键点是不同模态特征空间的对齐。常见的多模态融合模式有Q-former和MLP。
1. Q-former

BLIP2的整体架构如上图所示。Q-former本质上是图像模态对齐到文本模态的一个中间桥梁。可学习的查询向量与图像的嵌入向量通过Q-former充分融合后的向量与文本嵌入向量拼接送入到LLM。
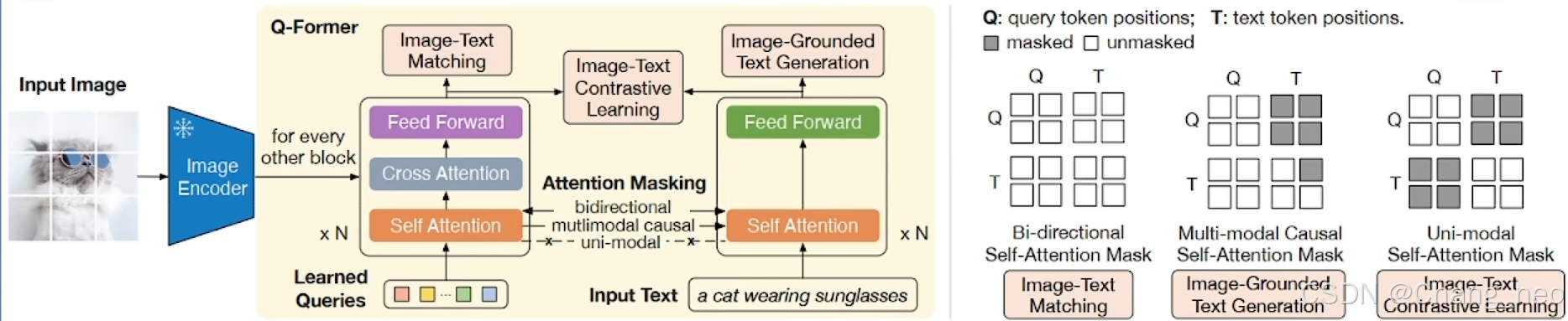
Q-former的训练参考了传统的多模态大模型CLIP的双塔式架构。有三个主要的损失三个loss:
ITM loss:图文匹配
LM loss: Predict Next Token
ITC loss:对比学习
架构设计如下:
共享Self Attention: 模态交融
专家FFN:处理差异化模态信息
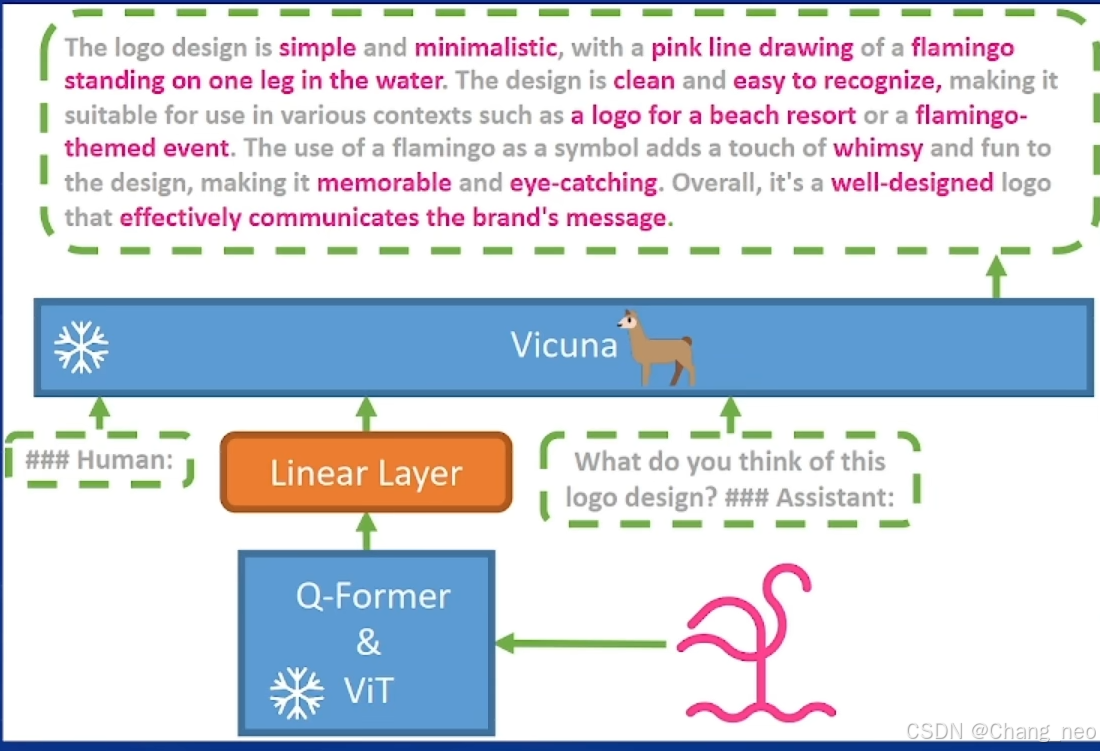
MiniGPT4就是利用Q-former对齐模态的
2. MLP

LLaVA的设计非常简单,仅仅使用简单的线性层将图像特征投影到文本空间。参数少。
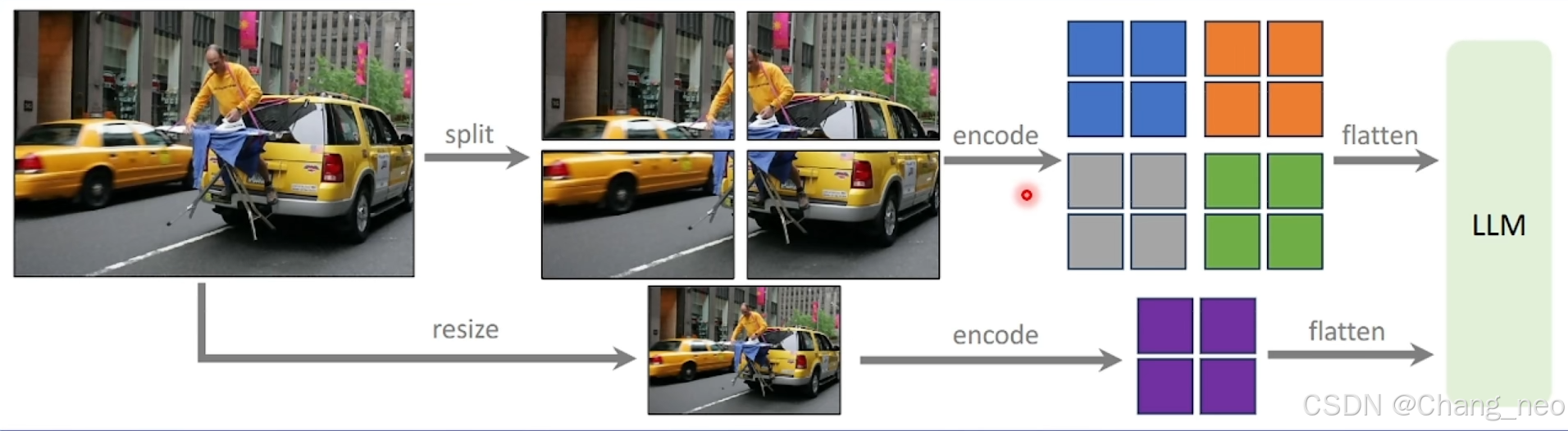
LLaVA-NeXT在LLaVA1.5的基础上,将图片分块后分别编码,这样可以支持更高分辨率。同时将整体图像resize到规定尺寸编码,保留全局信息。
动态分辨率:336x[(2,2),(1,2),(2,1),(1,3),(3,1),(1,4),(4,1)] 这样可以根据原始图像分辨率选择合适的比例resize后再分块
更强的训练数据

为什么MLP更加常用
https://www.bilibili.com/video/BV1nESCYWEnN
收敛速度慢:Q-Former的参数量较大(例如BLIP-2中的100M参数)导致其在训练过程中收敛速度较慢。相比之下,MLP作为connector的模型(如LLaVA-1.5)在相同设置下能够更快地收敛,并且取得更好的性能。
性能收益不明显:在数据量和计算资源充足的情况下,Q-Former并没有展现出明显的性能提升。即使通过增加数据量和计算资源,Q-Former的性能提升也并不显著,无法超越简单的MLP方案。
更强的baseline setting:LLaVA-1.5通过改进训练数据,在较少的数据量和计算资源下取得了优异的性能,成为了一个强有力的baseline。相比之下,BLIP2的后续工作InstructBLlP在模型结构上的改进并未带来显著的性能提升,且无法推广至多轮对话。
模型结构的简洁性:LLaVA系列采用了最简洁的模型结构,而后续从模型结构上进行改进的工作并未取得明显的效果。这表明,在当前的技术和数据条件下,简洁的模型结构可能更为有效。
二、InternVL2的设计模式
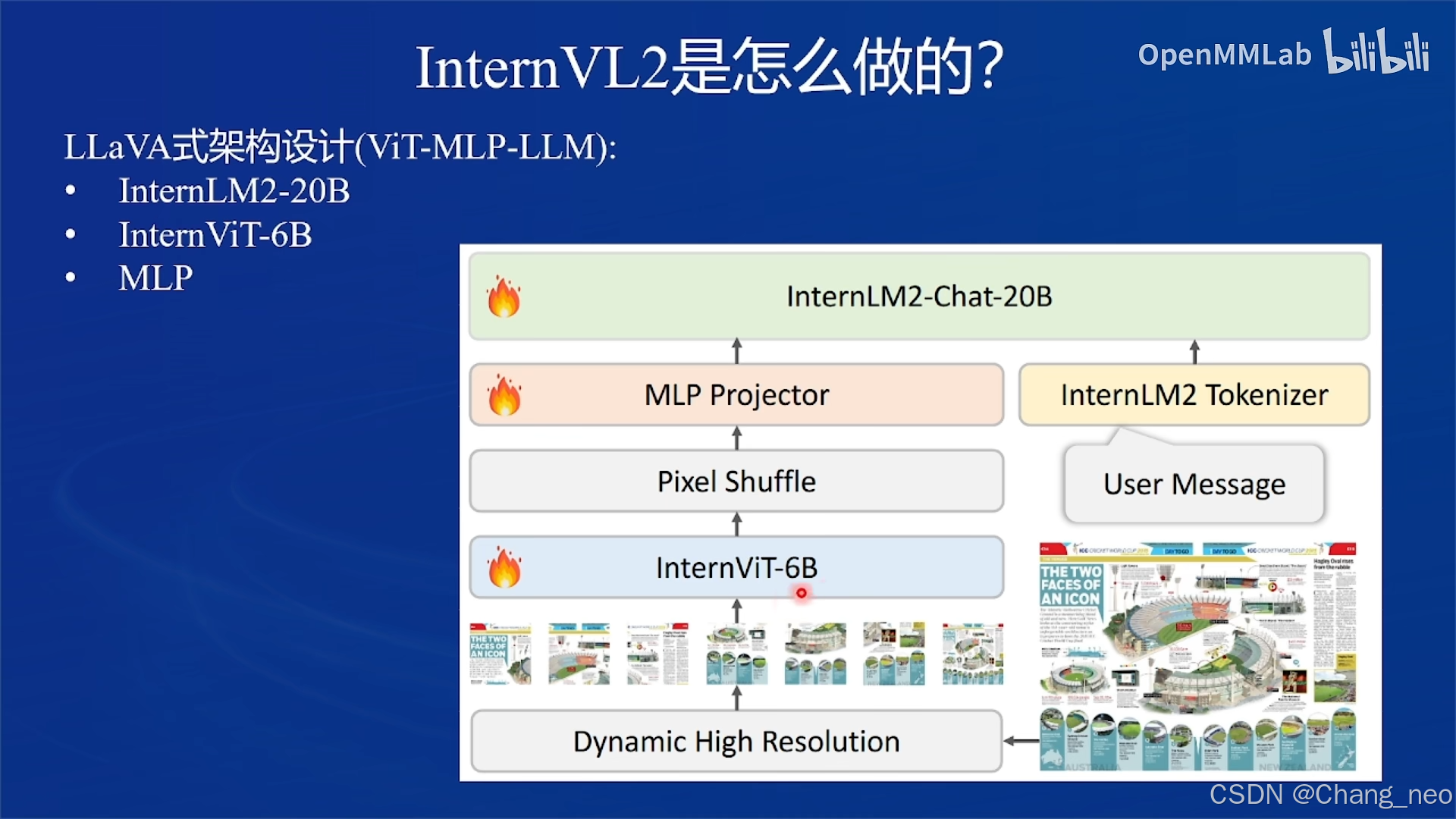
InternVL2采用了LLaVA式的架构(ViT-MLP-LLM):
InternLM2-20B
InternViT-6B
MLP
1.InternViT

InternViT相比原来不到1B的ViT,其参数量扩展到了6B。在做图文本匹配的对比学习时,InternViT选择直接对齐LLM而不是CLIP中的text encoder。在不同版本中分别做了以下创新
InternViT-6B-448px-V1.2
倒数第四层特征最有用,砍掉后三层,共45层
分辨率从224扩展到448
与LLM联合训练时,在captioning和OCR数据集上训练获取高分辨率和OCR能力
InternViT-6B-448px-V1.5
动态分辨率,最多12个tile
更高质量的数据
2.Pixel Shuffle
InternViT与MLP Projector之间还有一个Pixel Shuffle。这是由于视觉相对语言本身就有很大成分的冗余。

Why: 448×448的图,patch大小为14×14,得到32×32=1024个patch,即视觉插入1024个token。这些信息有较大冗余消耗较多的计算资源,对长的多模态上下文拓展不利。
What: Pixel shufle技术来自超分那边,是把不同通道的特征拿出来,拼到一个通道上,从(N,Cxr2,H,W)转化为(N,C,H xr,W xr)。r是上采样因子。
How: 这里把采样因子设为0.5,就可以把(4096×0.5×0.5, 32, 32)的图像特征转化为(4096, 32×0.5, 32×0.5),下采样到256个token了
3.Dynamic High Resolution
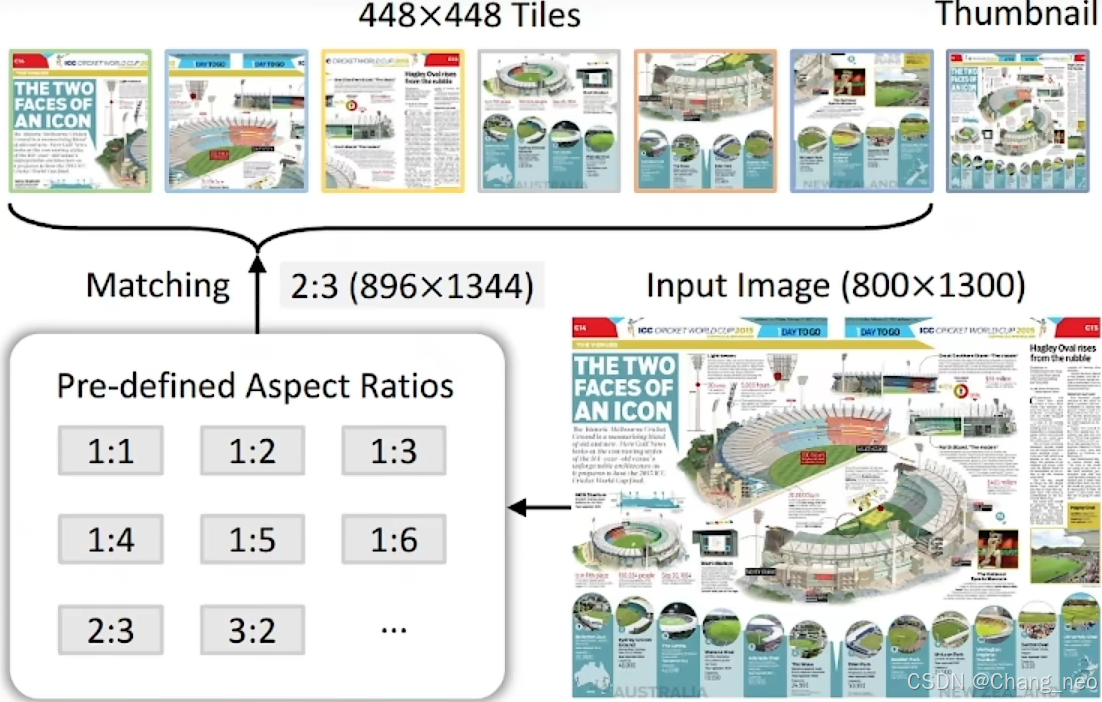
Pre-defined Aspect Ratios:考虑到计算资源,设置最多12个tile。就有35种长宽比的排列组合(m×n, m, n<12, 12+6+4+3+2+2+6).
Match and split: 选择最接近的长宽比,resize过去,切片成448×448的tiles。
Thumbnail: 某些任务需要全局信息,为了更好的感知全局信息,把原图resize一块喂给LLM到448×448。
4.Multitask output

利用VisionLLMv2的技术,初始化了一些任务特化embedding(图像生成、分割、检测)添加了一些任务路由token
训练下游任务特化embedding,生成路由token时,把任务embedding拼在路由embedding后面,送给LLM拿到hidden state
把hidden state送给路由到的解码器中,生成图像/bounding box/masks
三、LMDeploy部署多模态大模型
1.环境配置
conda create -n lmdeploy python=3.10 -y
conda activate lmdeploy
pip install lmdeploy gradio==4.44.1 timm==1.0.9
2.获取项目仓库
git clone https://github.com/Control-derek/InternVL2-Tutorial.git
cd InternVL2-Tutorial
3.运行demo
conda activate lmdeploy
python demo.py
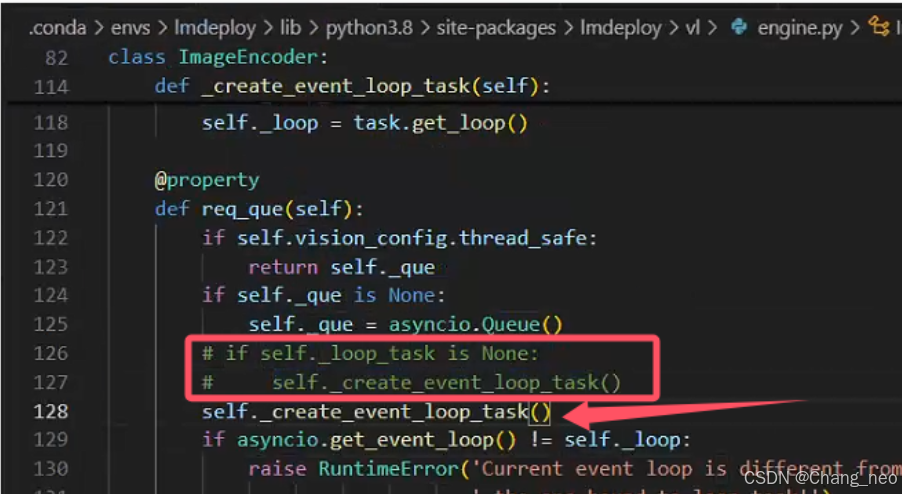
注意,为了使得多轮对话正常进行。我们进行以下操作,屏蔽报错的engine.py的126,127行,添加self._create_event_loop_task()
此外,一定要记得进行端口映射。
4.运行结果
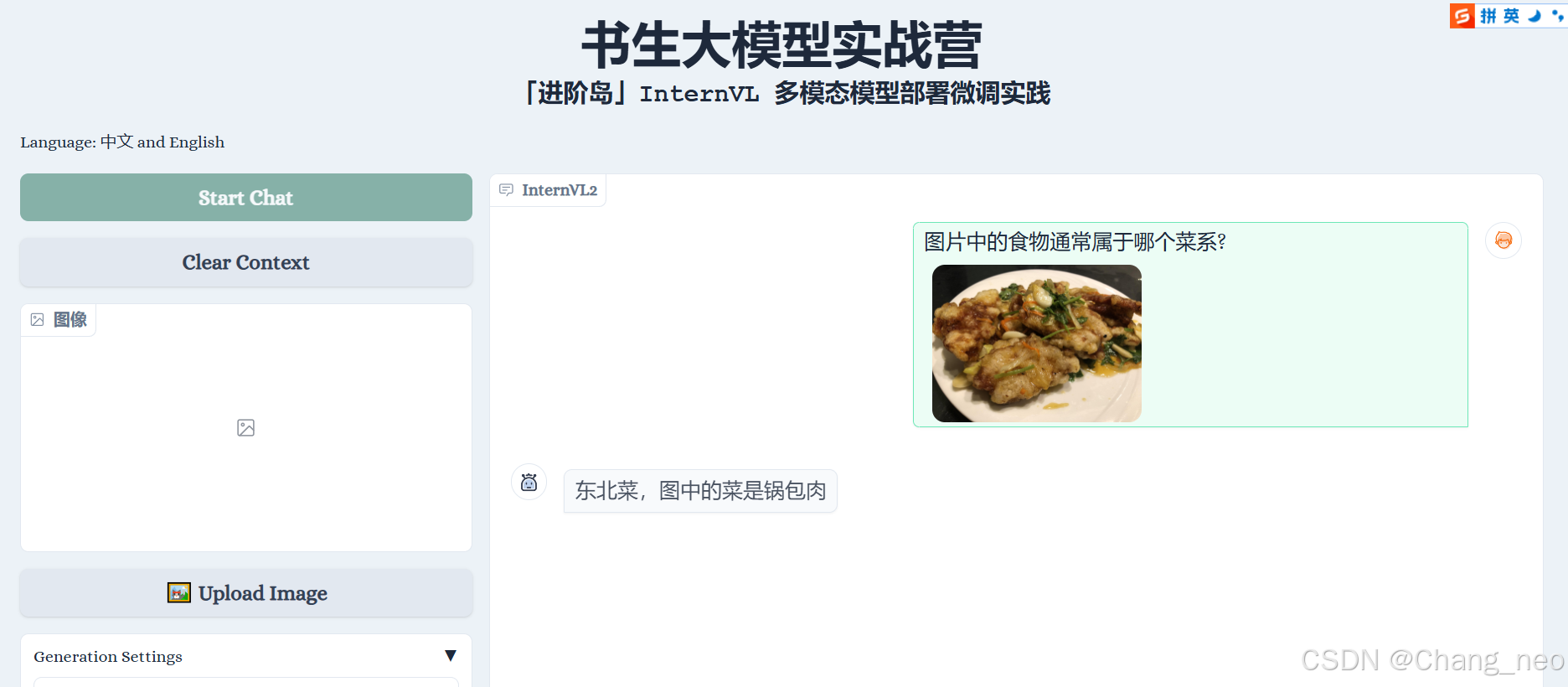
会看到如下界面:
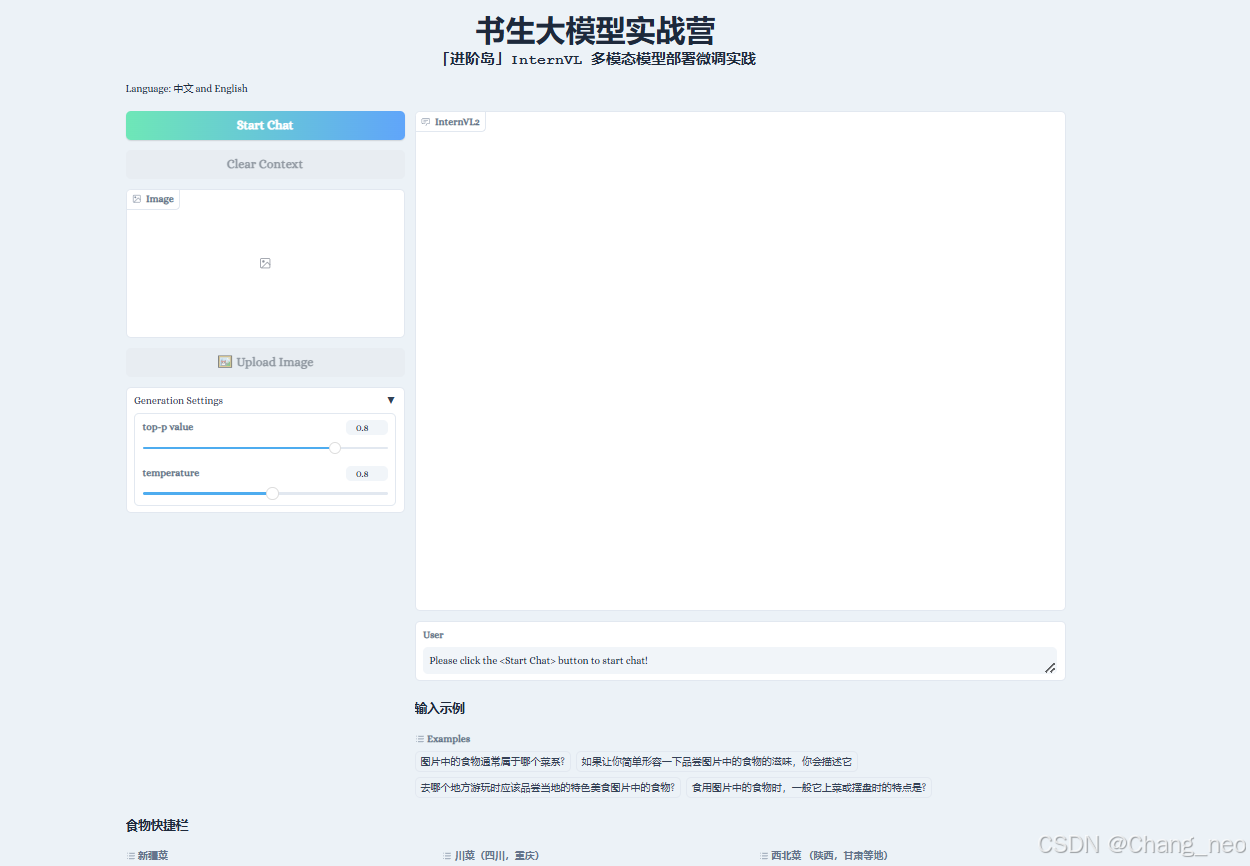
点击Start Chat即可开始聊天,下方食物快捷栏可以快速输入图片,输入示例可以快速输入文字。输入完毕后,按enter键即可发送。(注意操作顺序)
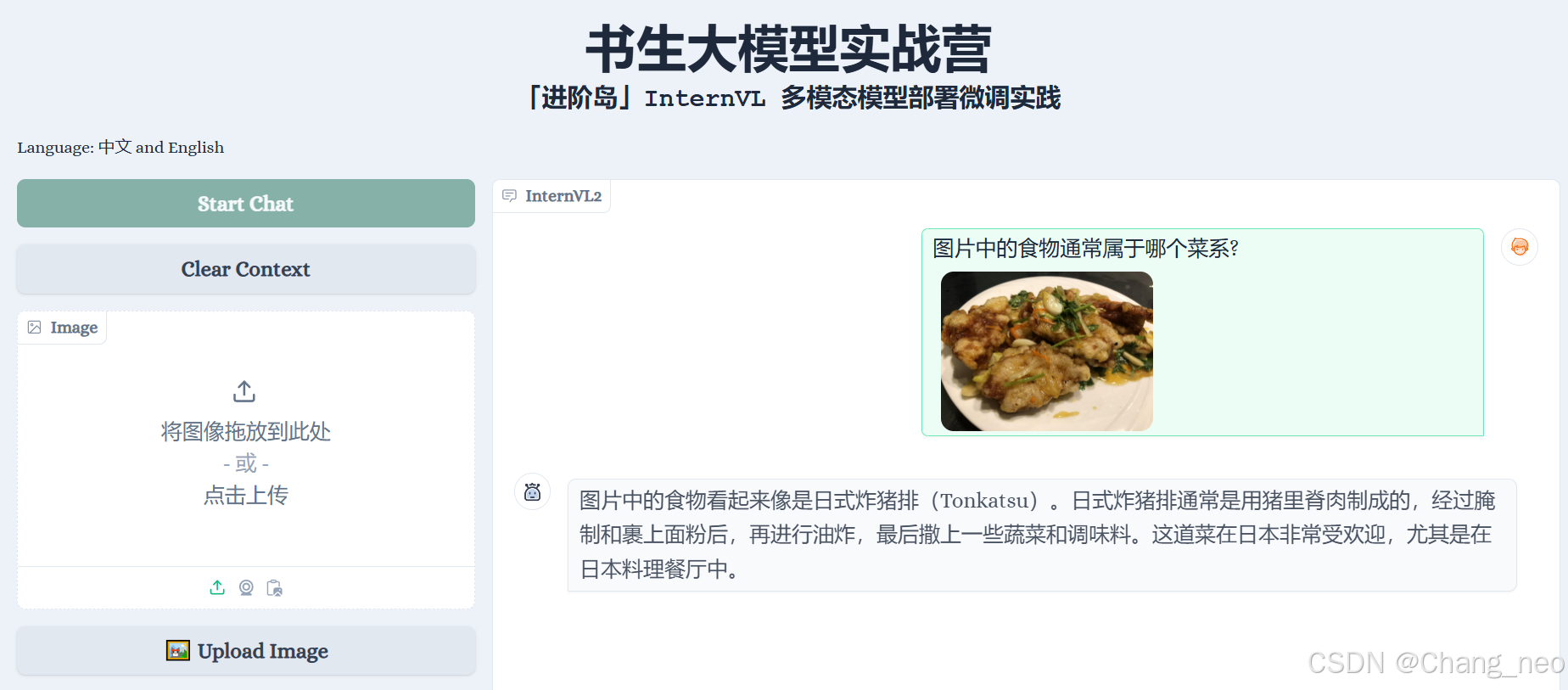
不能认识锅包肉。错的离谱。
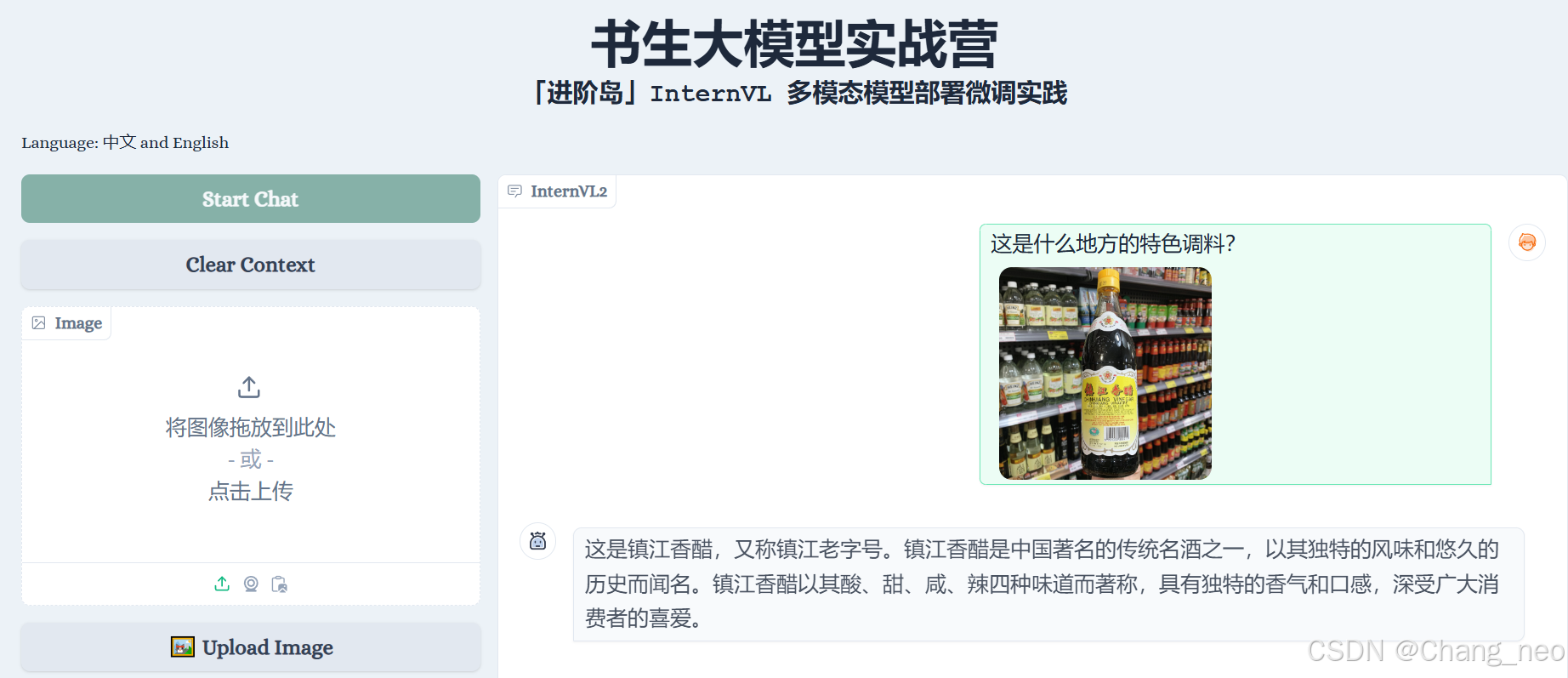
带有名字的能识别。看来具有一定的ocr识别能力。
四、XTuner微调实践
1.准备基本配置文件
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
pip install -U 'xtuner[deepspeed]' timm==1.0.9
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install transformers==4.39.0
cd root/xtuner
conda activate xtuner-env # 或者是你自命名的训练环境
#原始internvl的微调配置文件在路径./xtuner/configs/internvl/v2下,假设上面克隆的仓库在/root/InternVL2-Tutorial,复制配置文件到目标目录下:
cp /root/InternVL2-Tutorial/xtuner_config/internvl_v2_internlm2_2b_lora_finetune_food.py /root/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py
利用处理好的FoodieQA数据集,/root/share/datasets/FoodieQA
2.微调
xtuner train path/to/internvl_v2_internlm2_2b_lora_finetune_food.py --deepspeed deepspeed_zero2

3.权重转换
把模型checkpoint的格式转化为便于测试的格式:
python /root/finetune/xtuner/xtuner/configs/internvl/v1_5/convert_to_official.py /root/finetune/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py ./work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/iter_640.pth ./work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/lr35_ep10/
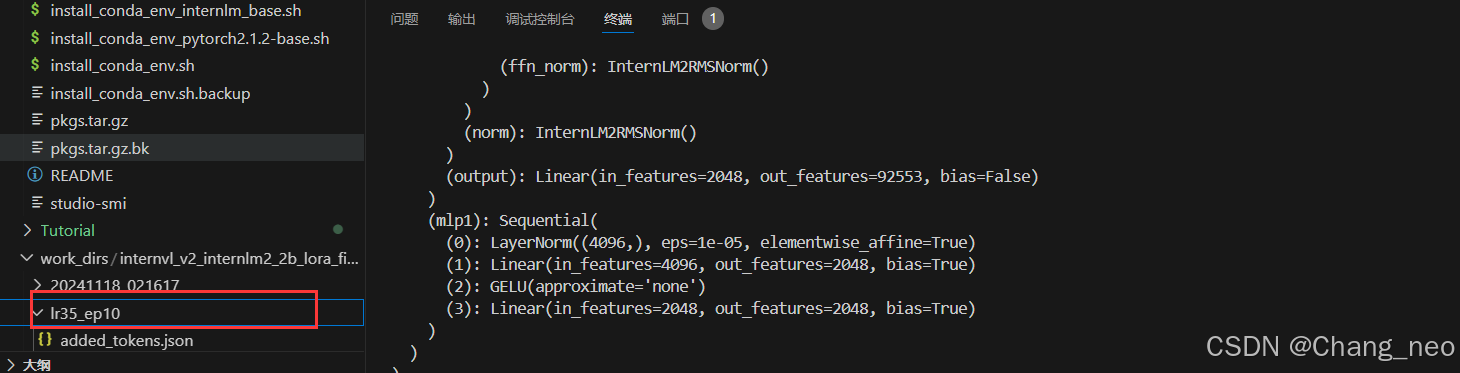
4.与AI美食家玩耍🎉
修改MODEL_PATH为刚刚转换后保存的模型路径:
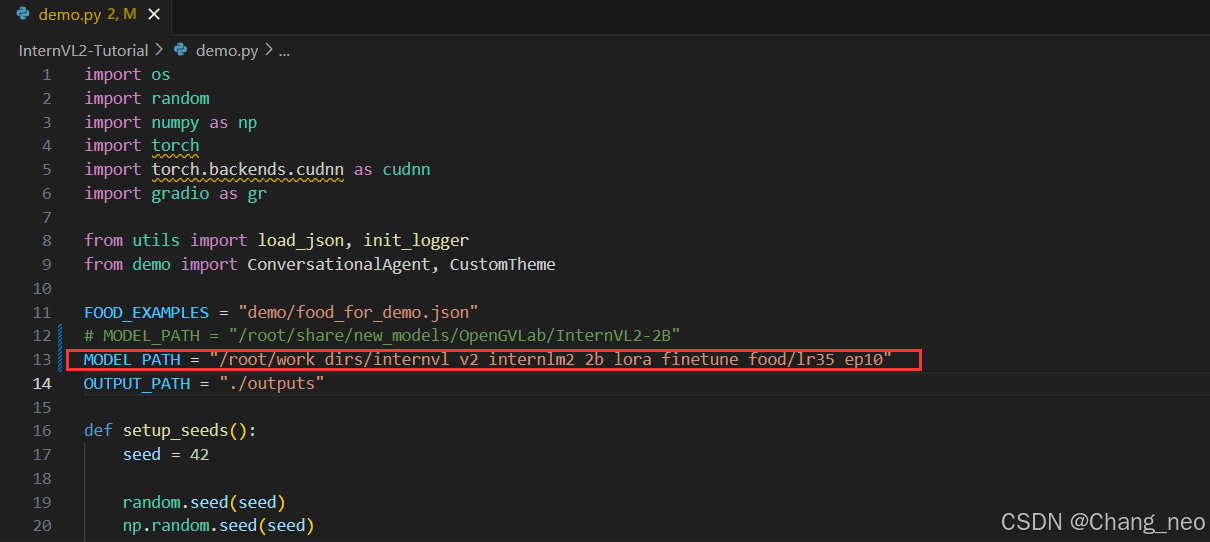
cd /root/InternVL2-Tutorial
conda activate lmdeploy
python demo.py
微调成功,正确识别。
优秀学员作业
总结
尝试了lmdeploy部署多模态模型。利用美食图文数据集微调了InternVL2-2B。

















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









