







第二章 Hadoop集群搭建
2.1 Linux系统环境准备

1.安装jdk


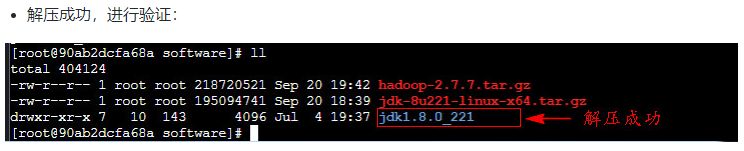

所以如果我们需要经常运行的命令,比如之后经常用到的 hadoop、hdfs等,我们可以将他们的路径全都放在 PATH 里面,这样运行比较方便。


vim /etc/profile
export JAVA_HOME=/root/software/jdk1.8.0_221 # 配置Java的安装目录
export PATH=$PATH:$JAVA_HOME/bin # 在原PATH的基础上加入JDK的bin目录

source /etc/profile #让配置文件立即生效
java -version #查看JDK版本





/usr/sbin/sshd
netstat -tnulp

ssh-keygen
##或者
ssh-keygen -t rsa
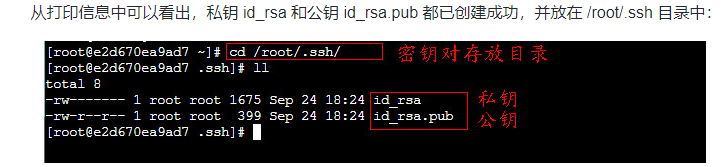
cd /root/.ssh
ll

cp id_rsa.pub authorized_keys
ll

chmod 600 authorized_keys

ssh localhost
ssh #主机名
ssh #ip号

2.2 HDFS伪分布式集群搭建
Hadoop 是 Apache 基金会面向全球开源的产品之一,任何用户都可以从 Apache Hadoop 官网http://archive.apache.org/dist/hadoop/common/下载使用。本门课程将以当下较为稳定的 hadoop2.7.7 版本为例,详细讲解 Hadoop 的安装。所以我们下载 hadoop-2.7.7.tar.gz 即可。
1:集群简介
Hadoop 集群具体来说包含两个集群:HDFS 集群和YARN 集群,两者逻辑上分离,但物理上常在一起。 另外,对于 Hadoop 的集群来讲,可以分为两大类角色:master 和 slave。
(1)HDFS 集群:负责海量数据的存储,集群中的角色主要有:NameNode(一个,master)、DataNode(若干,slave)和** SecondaryNameNode**(一个)。
(2)YARN 集群:负责海量数据运算时的资源调度,集群中的角色主要有: ResourceManager(一个,master) 和 NodeManager(若干,slave)。
为什么没有 MapReduce 集群呢?MapReduce 是什么呢?
它其实是一个应用程序开发包,也就是一堆 Java 的 jar 包,不需要安装。
安装hadoop

tar -zxvf hadoop-2.7.7.tar.gz
ll

2. 配置Hadoop系统变量
(1) 首先打开/etc/profile文件(系统环境变量:对所有用户有效):
vim /etc/profile
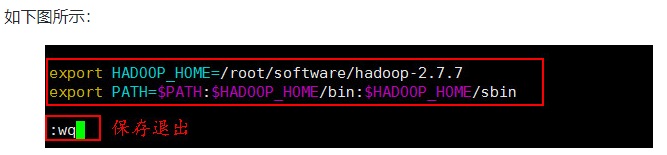
- 在文件底部添加如下内容:
# 配置Hadoop的安装目录
export HADOOP_HOME=/root/software/hadoop-2.7.7
# 在原PATH的基础上加入Hadoop的bin和sbin目录
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注意:
export 是把这两个变量导出为全局变量。
大小写必须严格区分。
另外:
**bin:**存放操作Hadoop相关服务(HDFS、YARN)的脚本,但是通常使用sbin目录下的脚本。
**sbin:**该目录存放Hadoop管理脚本,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
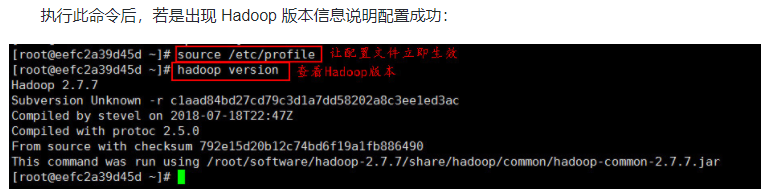
(3)让配置文件立即生效,使用如下命令:
source /etc/profile
(4)检测 Hadoop 环境变量是否设置成功,使用如下命令查看 Hadoop 版本:
hadoop version


Hadoop 提供的默认配置文件 core-default.xml、hdfs-default.xml、mapred-default.xml 和 yarn-default.xml 中的参数非常之多,这里不便一一展示说明。读者在具体使用时可以通过访问 Hadoop官方文档https://hadoop.apache.org/docs/r2.7.7/,进入到文档最底部的 Configuration 部分进行学习和查看。

3.1 配置环境变量hadoop-env.sh
因为 Hadoop 的各守护进程依赖于 JAVA_HOME 环境变量,所以需要修改“hadoop-env.sh”环境变量文件中的 JAVA_HOME 的值。
首先需要复制一下本机安装的 JDK 的实际位置(避免写错最好不要手写),可以使用下列方式打印 JDK 的安装目录:
echo $JAVA_HOME
语法解析:
echo:输出命令
$:引用环境变量的值
JAVA_HOME:环境变量
效果图如下所示:

复制完成,使用如下命令打开 hadoop-env.sh 文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/hadoop-env.sh
找到 JAVA_HOME 参数位置,修改为本机安装的 JDK 的实际位置:

3.2 配置核心组件core-site.xml
该文件**是 Hadoop 的核心配置文件,其目的是配置 HDFS 地址、端口号,以及临时文件目录。**使用如下命令打开 “core-site.xml” 文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/core-site.xml
将下面的配置内容添加到 中间:
<!-- HDFS集群中NameNode的URI(包括协议、主机名称、端口号),默认为 file:/// -->
<property>
<name>fs.defaultFS</name>
<!-- 用于指定NameNode的地址 -->
<value>hdfs://localhost:9000</value>
</property>
<!-- Hadoop运行时产生文件的临时存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopData/temp</value>
</property>

3.3 配置文件系统hdfs-site.xml
该文件主要用于配置 HDFS 相关的属性,例如复制因子(即数据块的副本数)、NameNode 和 DataNode 用于存储数据的目录等。在完全分布式模式下,默认数据块副本是 3 份。 使用如下命令打开“hdfs-site.xml”文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
将下面的配置内容添加到 中间:
<!-- NameNode在本地文件系统中持久存储命名空间和事务日志的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoopData/name</value>
</property>
<!-- DataNode在本地文件系统中存放块的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoopData/data</value>
</property>
<!-- 数据块副本的数量,默认为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>

3.4 配置slaves文件
该文件用于记录 Hadoop 集群所有从节点(HDFS 的 DataNode 和 YARN 的 NodeManager 所在主机)的主机名,用来配合一键启动脚本启动集群从节点(并且还需要保证关联节点配置了 SSH 免密登录)。
打开该配置文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/slaves
我们看到其默认内容为localhost,因为我们搭建的是伪分布式集群,就只有一台主机,所以从节点也需要放在此主机上,所以此配置文件无需修改。
任务5:HDFS 集群测试
5.1 格式化文件系统
具体指令如下:
hdfs namenode -format

若是未出现 “successfully formatted” 信息,就需要查看指令是否正确,或者之前 HDFS 集群的安装和配置是否正确,若是正确,则需要删除所有主机的 “/root/hadoopData” 文件夹,重新执行格式化命令,对 HDFS 集群进行格式化。
另外需要特别注意的是,上述格式化指令只需要在HDFS集群初次启动前执行即可,后续重复启动就不再需要执行格式化了。
2. 脚本一键启动和关闭
启动集群最常使用的方式是使用脚本一键启动,前提是需要配置 SSH 免密登录。
在本机上使用如下方式一键启动 HDFS 集群:
start-dfs.sh

打印信息:
在本机上启动了 NameNode 守护进程
在本机上启动了 DataNode 守护进程
在配置的一个特定节点0.0.0.0(本机)上启动 SecondaryNameNode 守护进程
我们可以一键启动 HDFS 集群,同样也可以一键关闭 HDFS 集群,只需要将 start 改为 stop 即可,即stop-dfs.sh。
5.3 查看进程启动情况
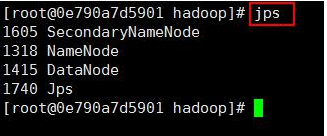
在本机执行 jps 命令,在打印结果中会看到 4 个进程,分别是 NameNode、SecondaryNameNode、Jps、和DataNode,如果出现了这 4 个进程表示进程启动成功。如下图所示:
jps
5.4 通过UI查看 HDFS 运行状态
HDFS 集群正常启动后,它默认开放了50070端口,用于监控HDFS集群。通过UI可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。
通过本机的浏览器访问http://localhost:50070或http://本机IP地址:50070查看 HDFS 集群状态,效果如下图所示:

2.3 YARN伪分布式集群搭建

1.1 配置环境变量yarn-env.sh
该文件是 YARN 框架运行环境的配置,同样需要修改 JDK 所在位置。我们可以使用如下命令打开“yarn-env.sh”文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-env.sh
找到JAVA_HOME参数位置,将前面的#去掉,将其值修改为本机安装的JDK的实际位置:

1.2 配置计算框架mapred-site.xml
该文件是 MapReduce 的核心配置文件,用于指定MapReduce运行时框架。此处应该指定 yarn,另外的可用值还有 local (本地的作业运行器)和 classic(MR1运行模式),默认为 local。
在 $HADOOP_HOME/etc/hadoop/ 目录中默认没有该文件,需要先通过如下命令将文件复制并重命名为 “mapred-site.xml”:
cp mapred-site.xml.template mapred-site.xml
效果如下图所示:

接着,打开 “mapred-site.xml” 文件进行修改:
vim /root/software/hadoop-2.7.7/etc/hadoop/mapred-site.xml
将下面的配置内容添加到 中间:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
效果如下图所示:

1.3 配置YARN系统yarn-site.xml
本文件是YARN 框架的核心配置文件,用于配置 YARN 进程及 YARN 的相关属性。
首先需要指定 ResourceManager 守护进程所在主机,默认为0.0.0.0,即当前设备,所以这里我们无需再次指定;其次需要设置 NodeManager 上运行的辅助服务,需配置成 mapreduce_shuffle 才可运行 MapReduce 程序。
使用如下命名打开该配置文件:
vim /root/software/hadoop-2.7.7/etc/hadoop/yarn-site.xml
将下面的配置内容添加到 中间:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
效果如下图所示:

任务2:YARN 集群测试
2.1 启动和关闭 YARN 集群
在启动 YARN 集群之前,需要保证 HDFS 集群处于启动状态。若是 HDFS 集群没有启动,我们可以使用脚本一键启动的方式启动 HDFS 集群。命令如下所示:
start-dfs.sh
效果图如下所示:

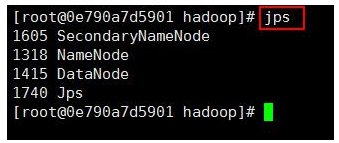
HDFS集群服务启动完成之后,我们可以通过 jps 指令查看各个服务进程启动情况,效果图如下所示:
针对 YARN 集群的启动,启动方式同样有两种,一种是单节点逐个启动;另一种是使用脚本一键启动。
- 单节点逐个启动和关闭
单节点逐个启动的方式,需要参照以下方式逐个启动 YARN 集群服务需要的相关服务进程,具体步骤如下:
(1)在本机上使用以下指令启动 ResourceManager 进程:
yarn-daemon.sh start resourcemanager
(2)在本机上使用以下指令启动 NodeManager 进程:
yarn-daemon.sh start nodemanager
另外,当需要停止相关服务进程时,只需要将上述指令中的start更改为stop即可。
2. 脚本一键启动和关闭
启动集群最常使用的方式是使用脚本一键启动,前提是需要配置 SSH 免密登录。
在本机上使用如下方式一键启动 YARN 集群:
start-yarn.sh

2.2 查看进程启动情况
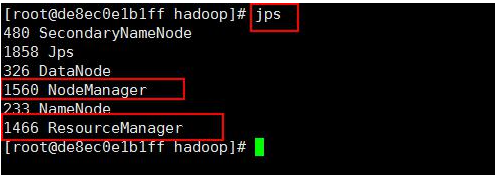
在本机执行 jps 命令,在打印结果中多了 2 个进程,分别是 ResourceManager 和 NodeManager,如果出现了这 2 个进程表示进程启动成功。如下图所示:
2.3 通过UI查看 YARN 运行状态
YARN 集群正常启动后,它默认开放了8088端口,用于监控 YARN 集群。通过 UI 可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。
通过本机的浏览器访问http://localhost:8088或http://本机IP地址:8088查看 YARN 集群状态,效果如下图所示:

2.4 Hadoop集群初体验
任务1:启动 Hadoop 集群
在本平台上,虽然已经为大家搭建好了 Hadoop 伪分布式集群,但是并没有启动,所以在使用集群之前,需要依次启动 HDFS 集群和 YARN 集群,这里我们使用脚本一键启动的方式启动。命令如下所示:
(1)HDFS集群
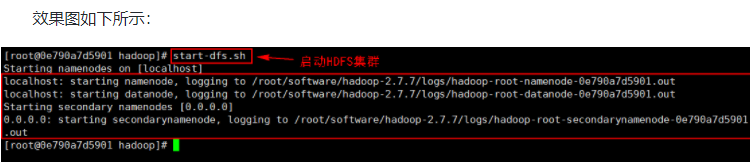
在本机上使用如下方式一键启动HDFS集群:
start-dfs.sh
(2)YARN集群
在本机上使用如下方式一键启动YARN集群:
start-yarn.sh

任务2:查看进程启动情况
在本机上执行 jps 命令,在打印结果中会看到 6 个进程,分别是 NodeManager、SecondaryNameNode 、ResourceManager、Jps、DataNode 和 NameNode,如果出现了这 6 个进程表示进程启动成功。如下图所示:
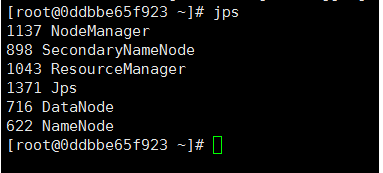
任务3:WordCount 单词统计案例
(1)首先,通过本机的浏览器访问 http://localhost:50070 或 http://本机IP地址:50070 打开 HDFS 的 Web UI 界面。其次,选择 Utilities——》Browse the file system 查看文件系统里的数据文件,可以看到新建的 HDFS 上没有任何数据文件,如下图所示:

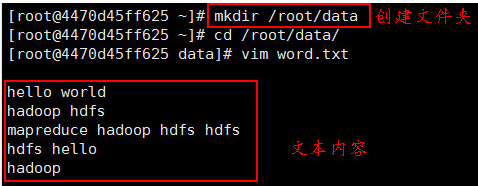
(2)在本机的/root目录下,新建一个名为 data 的文件夹,然后再执行 “vim word.txt” 指令新建一个 word.txt 文本文件,并编写一些单词内容,如下图所示:
(3)接着,在 HDFS 上创建 /wordcount/input 目录,并将 word.txt 文件上传至该目录下,具体指令如下所示:
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /root/data/word.txt /wordcount/input

上述指令是 Hadoop 提供的进行文件系统操作的 HDFS Shell 相关指令,此处不必深究具体使用,在下一章会进行详细说明。
执行完上述指令后,再次查看 HDFS 的 Web UI 界面,会发现 /wordcount/input 目录创建成功并上传了指定的 word.txt 文件,如下图所示:

(4)进入$HADOOP_HOME/share/hadoop/mapreduce/ 目录下,使用ll指令查看文件夹内容,如下图所示:

从上图可以看出,在该文件夹下自带了很多 Hadoop 的 MapReduce 示例程序。其中,hadoop-mapreduce-examples-2.7.7.jar 包中包含了计算单词个数、计算PI值等功能的程序。
因此,这里可以直接使用 hadoop-mapreduce-examples-2.7.7.jar 示例包,对 HDFS 上的 word.txt 文件进行单词统计,在 jar 包位置执行如下命令:
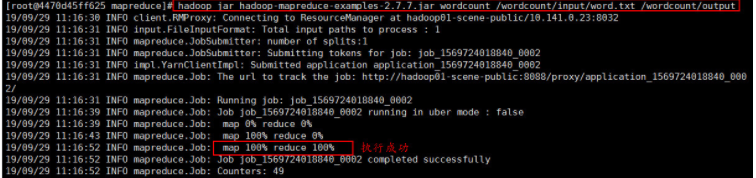
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /wordcount/input/word.txt /wordcount/output
上述指令中:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar :表示执行一个Hadoop的jar包程序;
wordcount:表示执行jar包程序中的单词统计功能;
/wordcount/input/word.txt:表示进行单词统计的HDFS文件路径;
/wordcount/output:表示进行单词统计后的输出HDFS结果路径。
执行完上述指令后,示例包中的 MapReduce 程序开始执行,效果图如下所示:
也可以通过YARN集群的Web UI界面查看运行状态,在本机的浏览器上访问 http://localhost:8088 或 http://本机IP地址:8088 。效果图如下所示:

(5)在“单词统计”示例程序执行成功后,再次刷新并查看 HDFS 的 Web UI 界面,效果如下图所示: 
从上图可以看出,MapReduce 程序执行成功后,在 HDFS 上自动创建了指定的输出目录 /wordcount/output,并且输出了 _SUCCESS 和 part-r-00000 结果文件。其中, _SUCCESS 文件用于表示此次任务成功执行的标识,而 part-r-00000 表示单词统计的结果。
(6)接着,我们使用 HDFS Shell 的相关指令查看 part-r-00000 的内容,具体指令如下所示:

任务4:PI 案例
进入 $HADOOP_HOME/share/hadoop/mapreduce/ 目录下,使用如下指令计算 PI 值:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 5 5
上述指令中:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar :表示执行一个Hadoop的jar包程序;
pi:表示执行jar包程序中计算PI值的功能;
第1个5:表示运行10次map任务;
第2个5:表示每个map任务,投掷的次数。
执行完上述指令后,示例包中的 MapReduce 程序开始执行,效果图如下所示:

从上图可以看出,MapReduce 程序执行成功后,计算出了 PI 值。但是我们发现其计算结果与实际 PI 值有一定的偏差,若是想要计算更精切的 PI 值,我们可以将执行命令中的2个数值增大:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 100 10000

sudo apt install htop
sudo apt install atop
sudo apt install top
















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











