







L2 机器学习、深度学习、生成式学习
机器学习 ≈ 让机器自动找一个函数
根据所找函数的的输出分类:
- regression----输出是一个数值
- 例如PM2.5的预测

- 例如PM2.5的预测
- classification----输出是一个类别
- 例如垃圾邮件的过滤
- 例如垃圾邮件的过滤
机器学习还有一个更困难的问题——structured Learning
即生成式学习 Generative Learning
找出函数的三步骤:
- 设定函数分类
- 候选函数的集合——称为Model
- 例如深度学习中类神经网络的集合:
- CNN,RNN,Transformer指的就是不同的函数式集合,用 H H H表示!
- 设定衡量标准
- 说明一个函数的好坏——称为Loss
- 用这个函数预测的结果与标准答案的差距,用 L ( f ) L(f) L(f)表示!
- 找出最好的函数
- 从 H H H中找到 L L L最小的函数——称为Optimization
- 例如使用Gradient Descent
- 用Backpropagation在类神经网络上找到最佳函数

Optimization
目标:从给定的
L
L
L与
H
H
H中找出最好的函数
f
∗
f^*
f∗
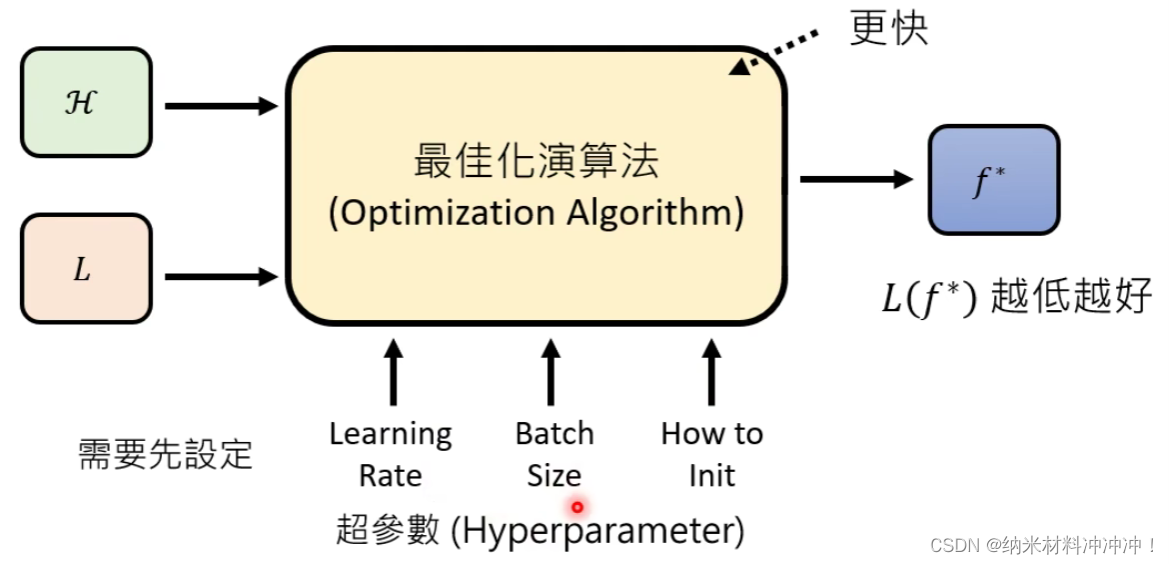
我们希望一个Optimization算法的具有以下优点:
- 能给出一个足够低的 L ( f ∗ ) L(f^*) L(f∗)
- 能给快的找到 f ∗ f^* f∗
- 对超参数不敏感
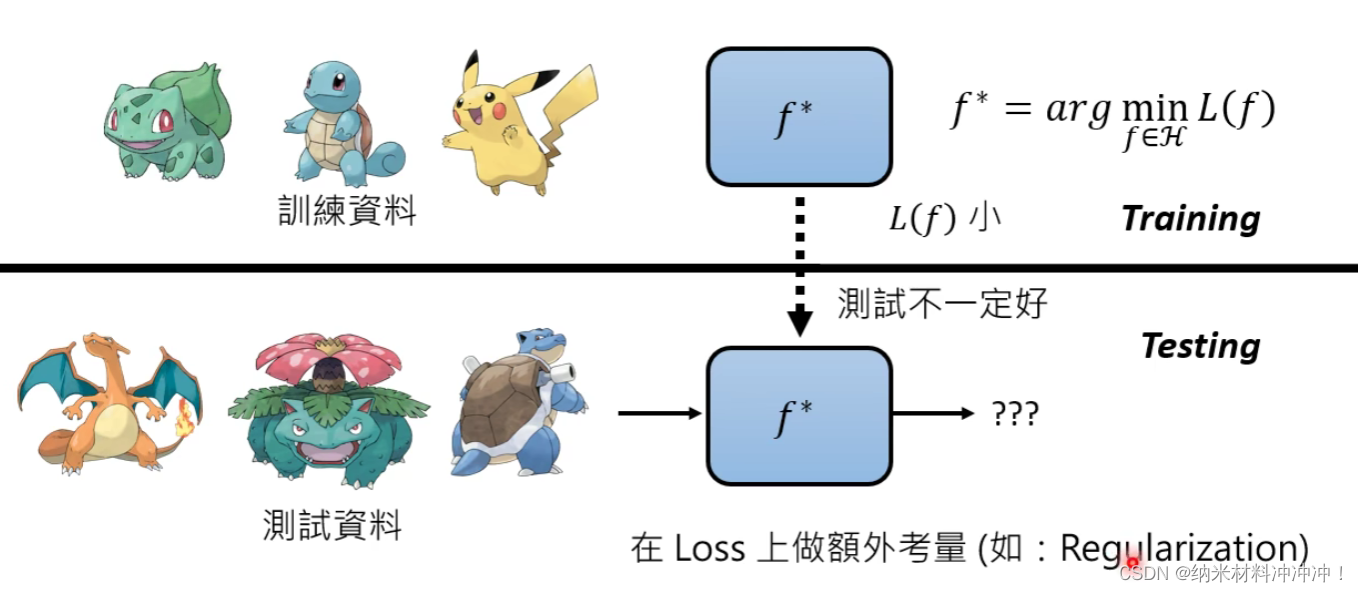
Loss Function
目标:我们需要找到一个衡量函数好坏的标准
在Training中
由于在Training中找到的好的函数在Test中不一定好
我们需要在Loss上做一些额外的考量,例如Regularization
Model
目标:选取一类备选函数,称为Model
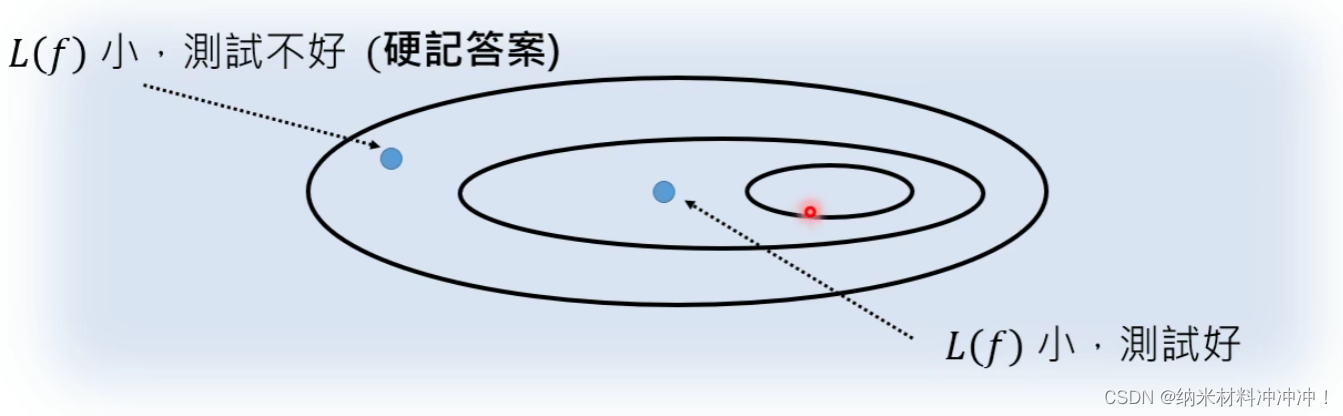
范围太大:可能导致我们找到一些训练集效果好,但测试集效果差的函数
范围太小:可能找不到满足要求的函数

生成式学习
生成具有结构的复杂物件
例如:
- 文本
- 以token为单位:
- 中文的token是字,一个汉字就是一个token
- 英文的饿token是word piece,一个英文单词可能有多个token
- 以token为单位:
- 影像
- 以pixel为单位
- 语音
- 16k取样频率,每秒有16000个取样点
各个击破的生成式策略 AutoRegressive(AR)
- 生成速度慢,难以并行
- 生成品质较高
- 常用于文字
一次到位的生成式策略 Non-AutoRegressive(NAR)
- 生成速度快,可以并行
- 生成品质差
- 常用语影像
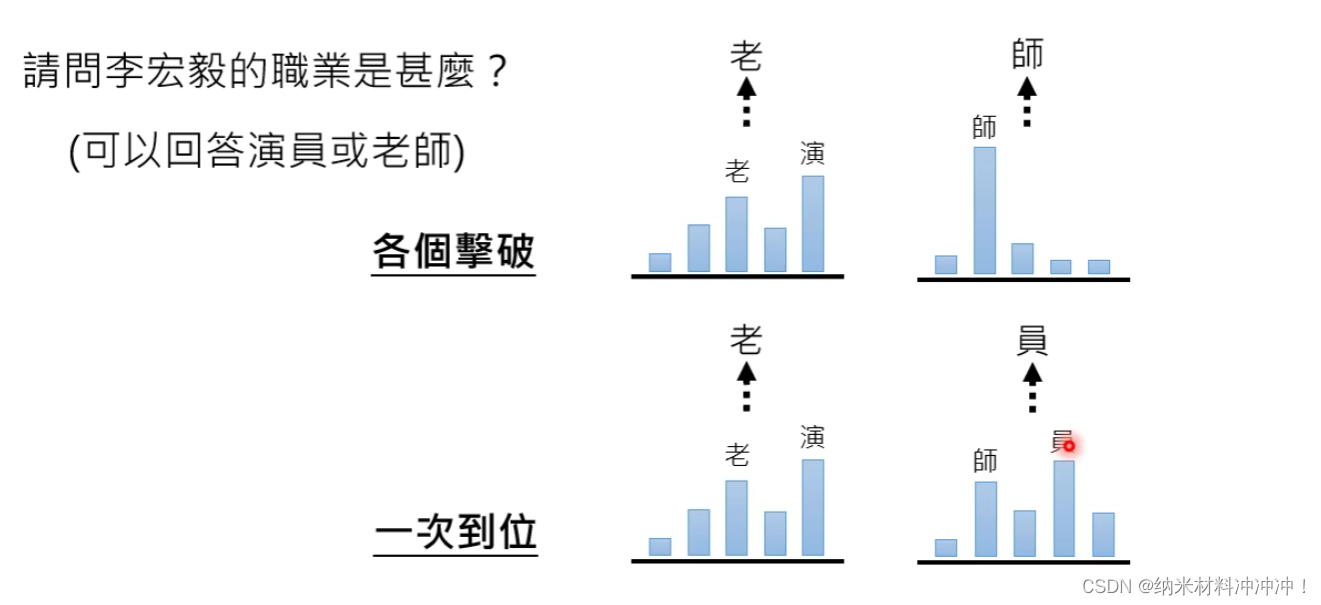
AR+NAR:

Deep Learning
历史:
- 1958: Perceptron(linear model)
- 1969: Perceptron has limitation
- 1980s: Multi-layer perceptron
- 1986: Backpropagation
- 1989: 1 hidden layer is good enough
- 2006: RBM initialization
- 2009: GPU
步骤:
- define a set of function
- goodness of function
- pick the best function
找到一组function
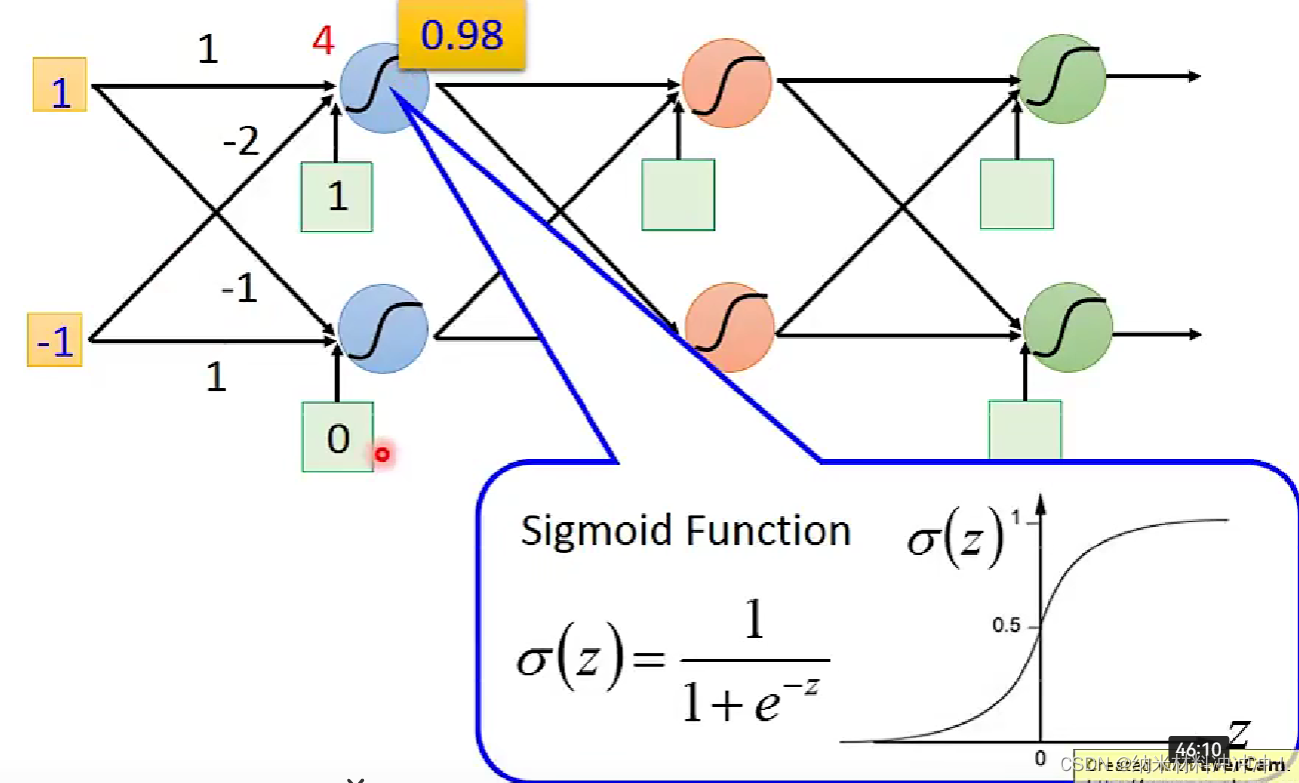
继续运算我们有:

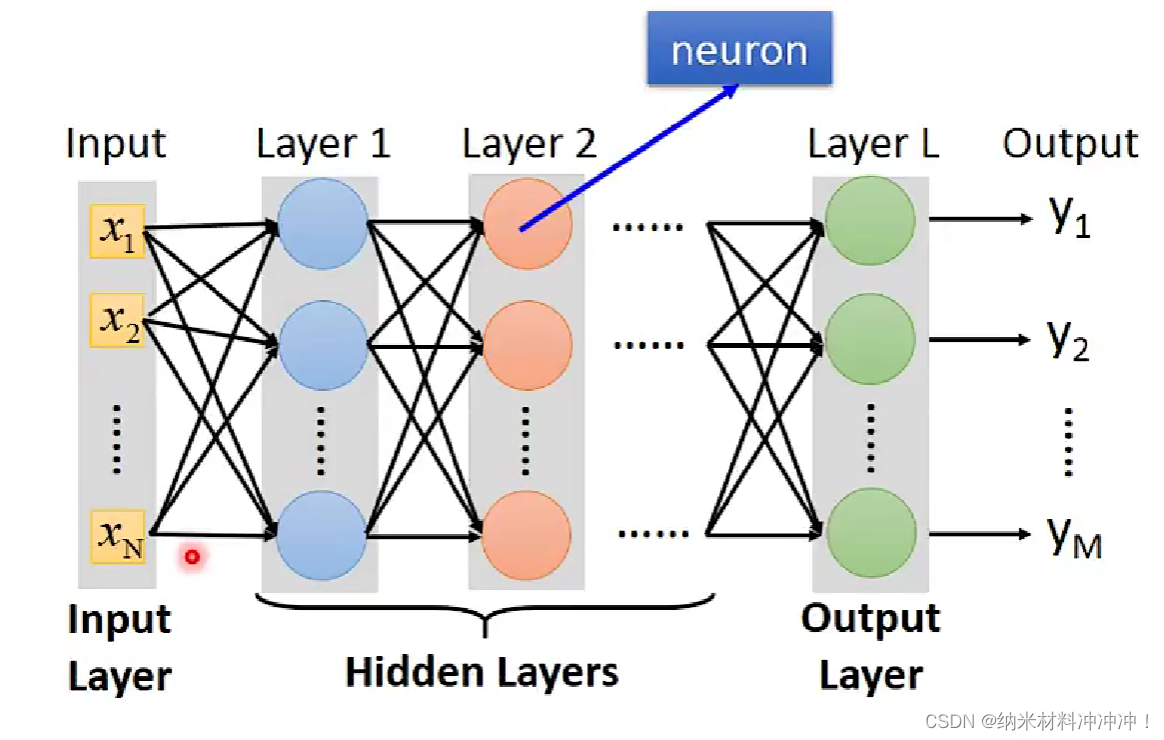
对于一个给定参数的neuron,我们可以将其看做就是一个function,一系列连接好的neuron(参数未确定)就是一个function set:

fully connected feedforward network:
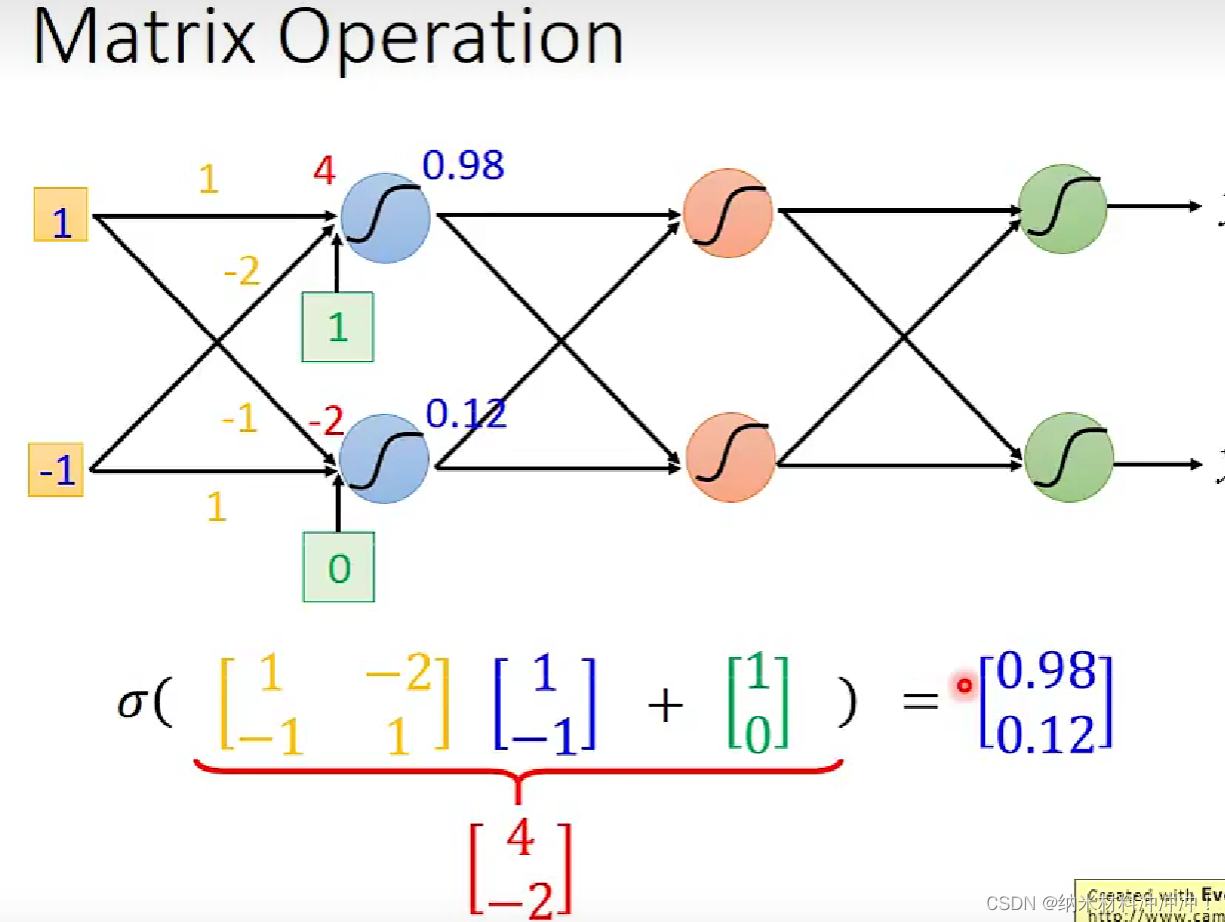
因此我们有:
σ
(
w
2
(
σ
(
w
1
x
+
b
1
)
)
+
b
2
)
\sigma(w^2(\sigma(w^1x+b^1))+b^2)
σ(w2(σ(w1x+b1))+b2)
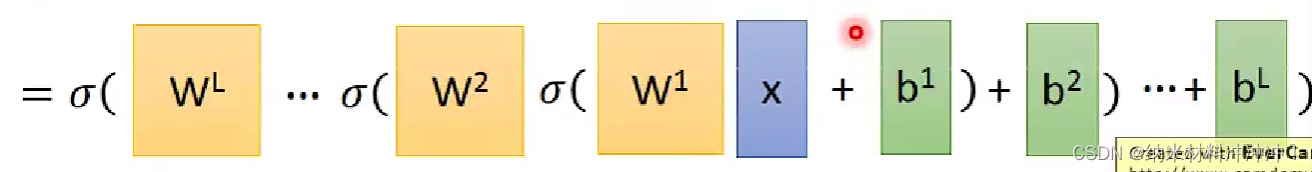
矩阵运算在GPU上的速度更快!
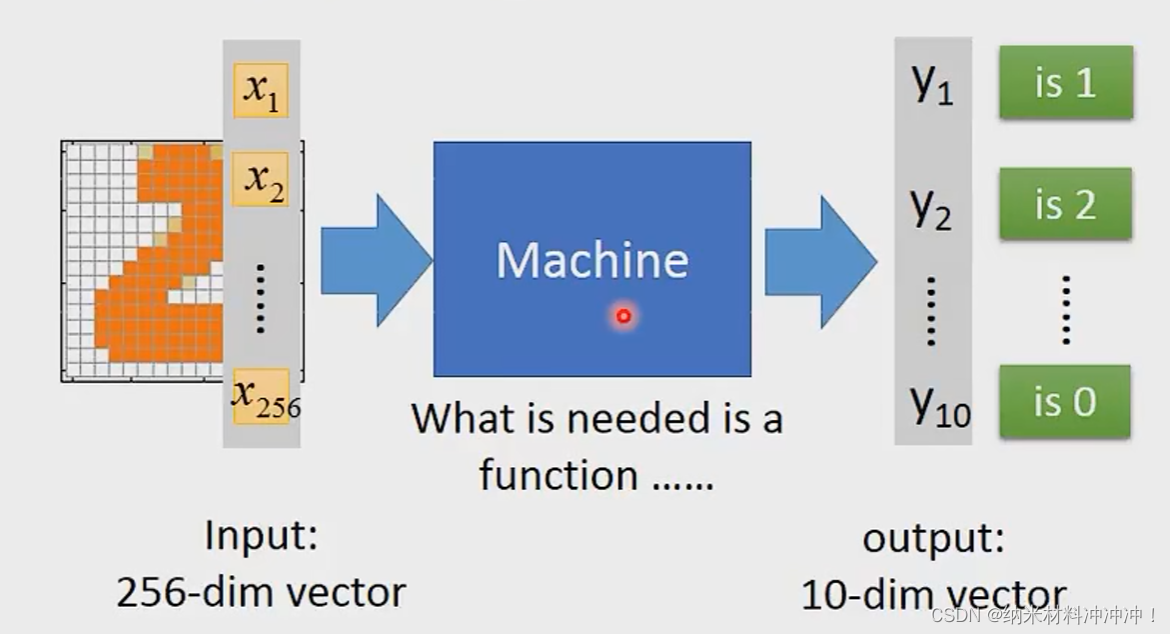
经过很多个hidden layers,最终得到一个向量,然后使用一层classifier输出结果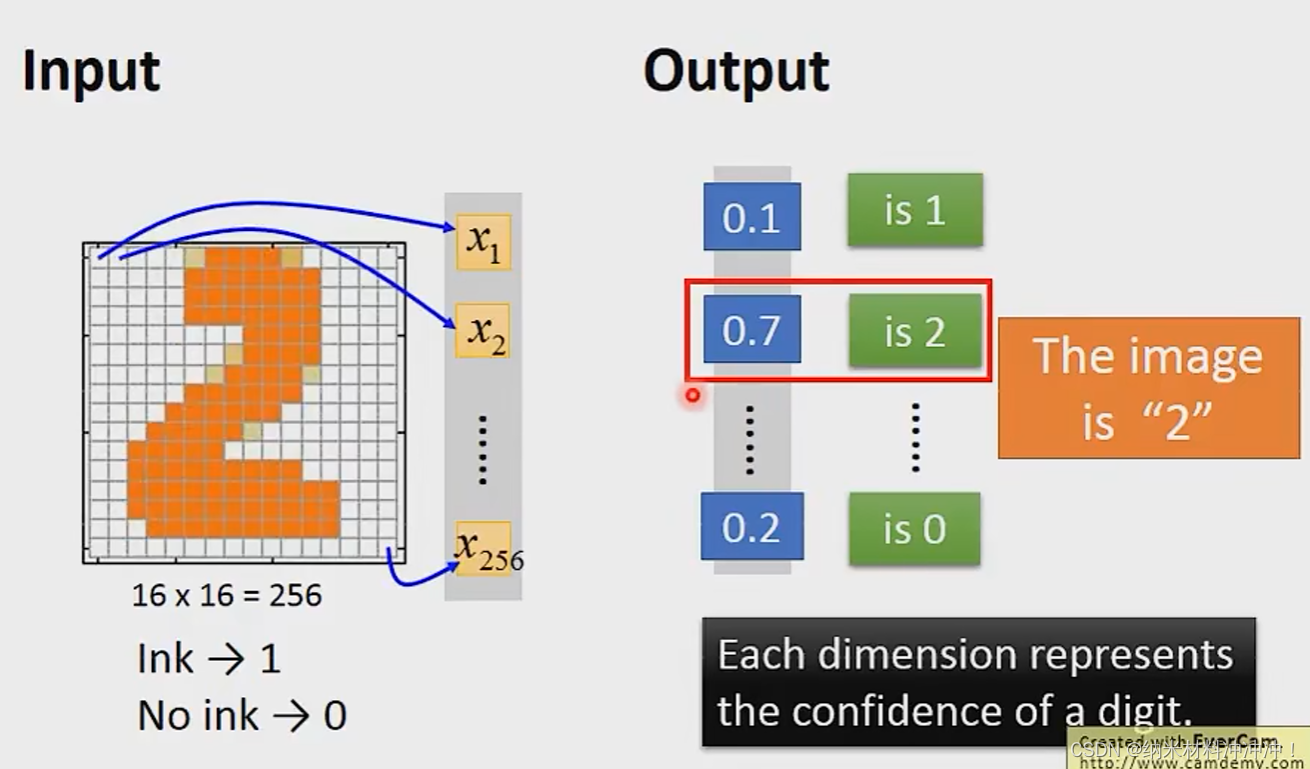
例如,我们最终输出一个10维向量,每个维度数值代表是0~9的概率:
如何找到一个好的network structure?
——玄学!
能否让machine自动找出一个work的structure?
——可以!但还不普及
能否自己设计一个network structure?
——可以,例如CNN
定义一个function的好坏?
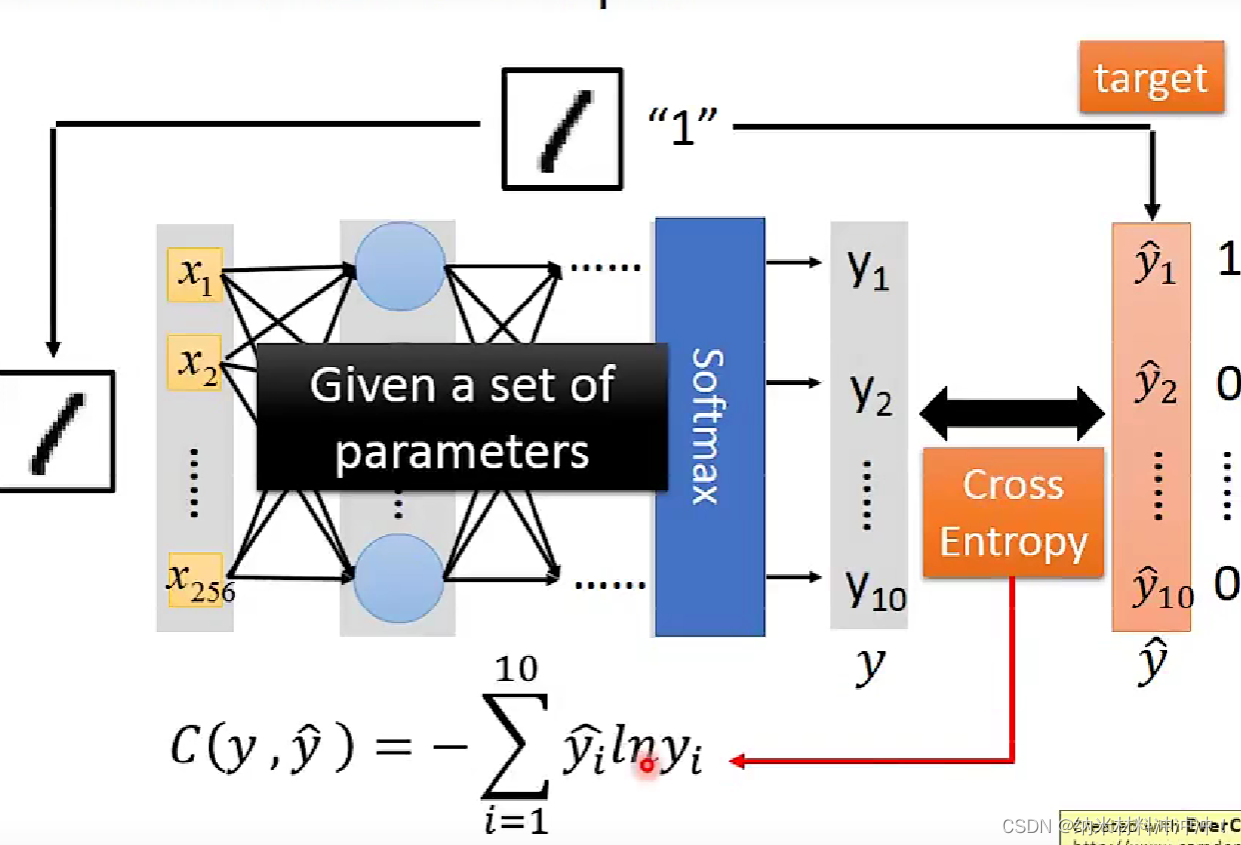
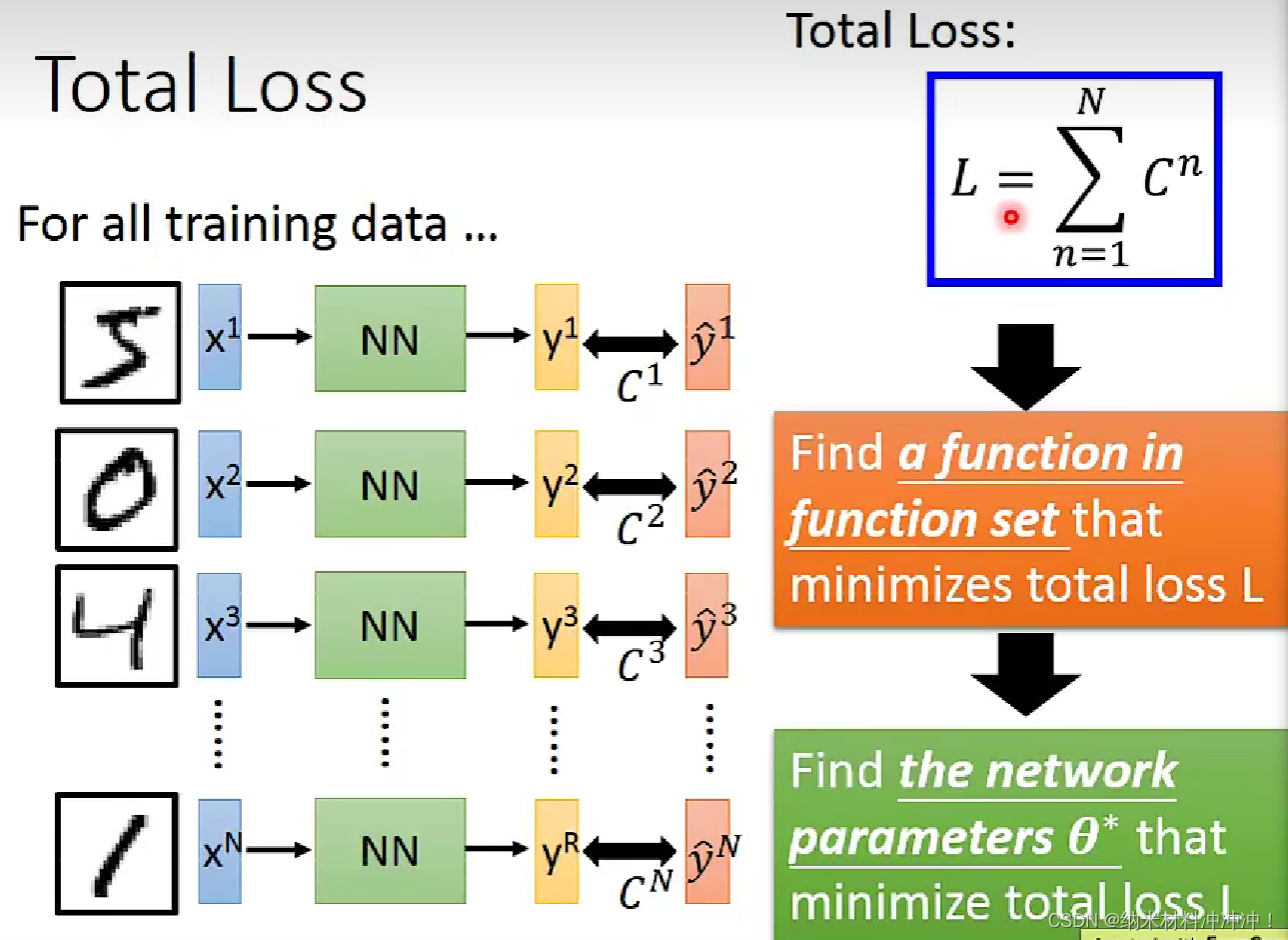
如何找到
θ
∗
\theta^*
θ∗?——gradient descent
使用Backpropagation计算微分
why deep learning?
更多的hidden layer必然会产生更好的结果嘛?
Gradient Descent
最优化:找到一个
θ
∗
\theta^*
θ∗使得:
θ
∗
=
a
r
g
m
i
n
L
(
θ
)
\theta^* = argminL(\theta)
θ∗=argminL(θ)
假设我们的
θ
\theta
θ由两个变量组成:
{
θ
1
,
θ
2
}
\{\theta_1, \theta_2 \}
{θ1,θ2}。
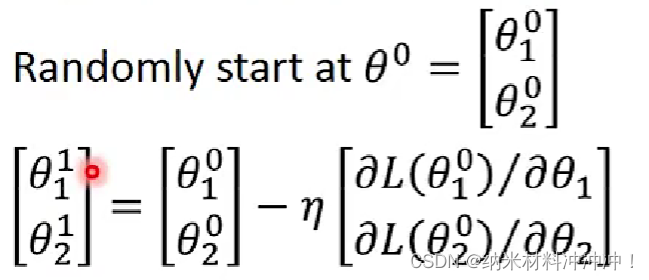
learning rate:我们用Loss值与learning rate作图:
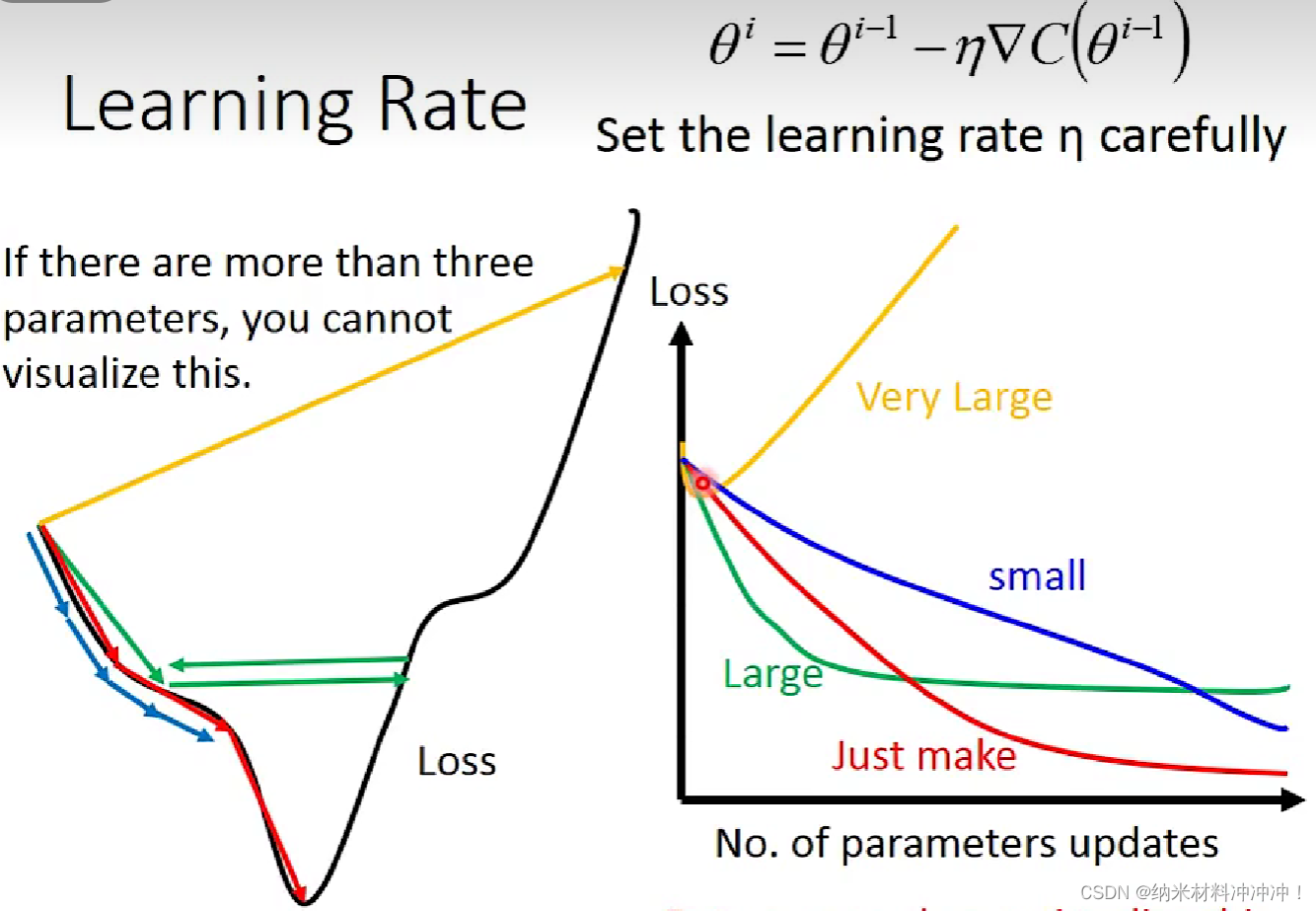
通常learning rate应该随着参数的update越来越小,例如可以使用decay:
η
t
=
η
t
+
1
\eta ^t = \frac{\eta}{\sqrt{t+1}}
ηt=t+1η
然而,每个参数的learning rate应该是不一样的,因此可以使用一些trick调优:
A
d
a
g
r
a
d
Adagrad
Adagrad:每个参数的learning rate都除以过去所有偏微分的平方根:

结合
d
e
c
a
y
decay
decay我们有:
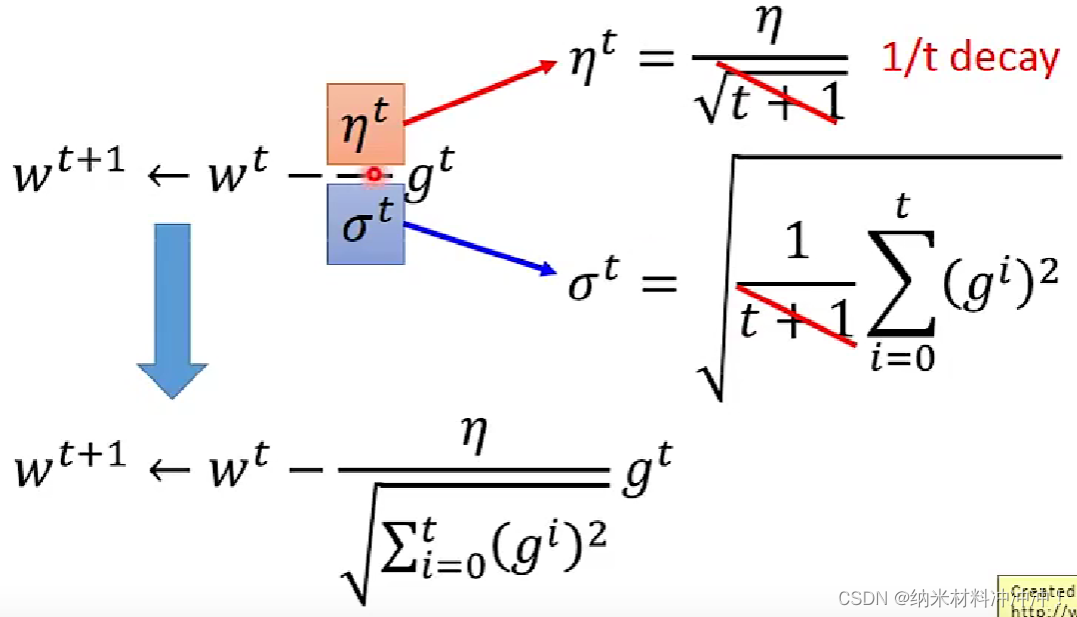
于是我们就有了两个修正后的gradient descent公式:

实际上adagrad评价的是某个维度上gradient的反差程度:反差越大参数更新的越快!

stochastic gradient descent
选取一个样本 x n x^n xn
feature scaling
假设我们有函数:
y
=
b
+
w
1
x
1
+
w
2
x
2
y = b + w_1x_1 + w_2x_2
y=b+w1x1+w2x2
如果两个feature 的取值范围不同,例如
x
1
x_1
x1的取值为0-9,
x
2
x_2
x2的取值为100~900
显然,相同大小的
w
2
w_2
w2对Loss的影响要大于
w
1
w_1
w1对Loss的影响!
可是这样对我们的gradient descent有什么影响?

- 会需要更多步,效率很低
常见的feature scaling方法:
- 均值为0,标准差为1:

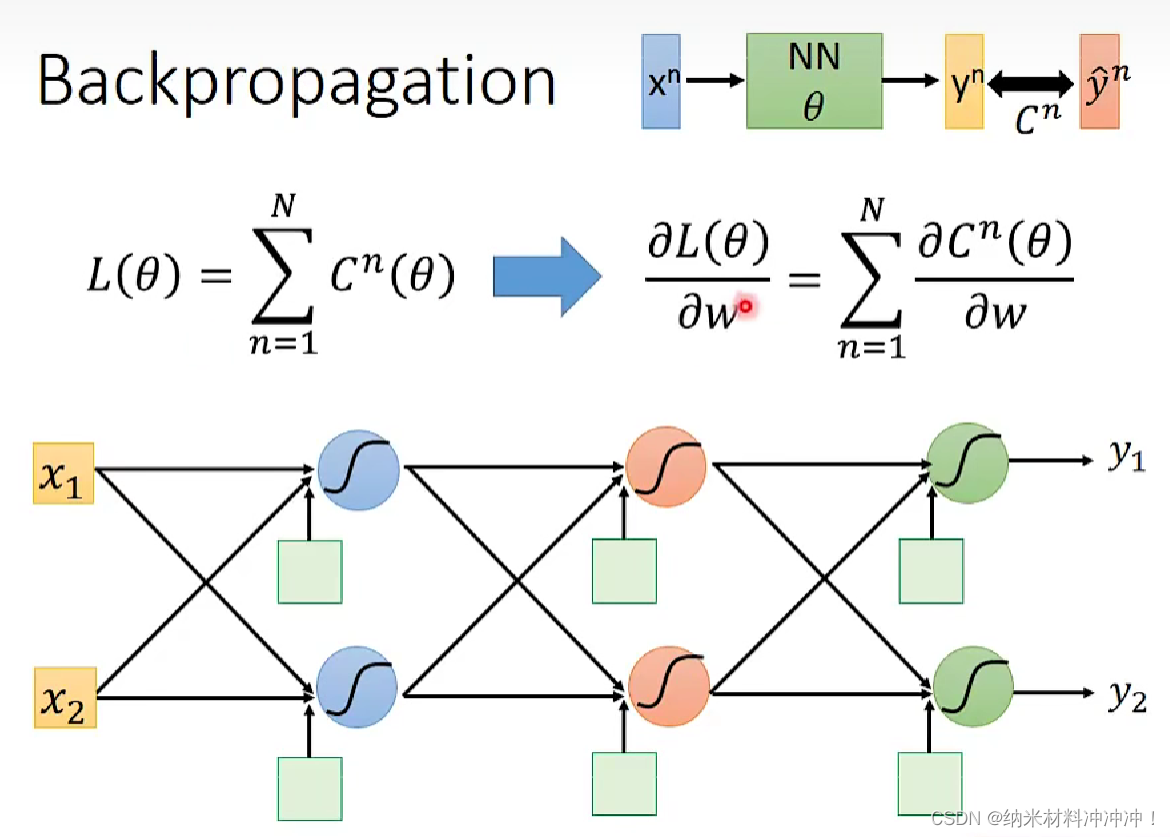
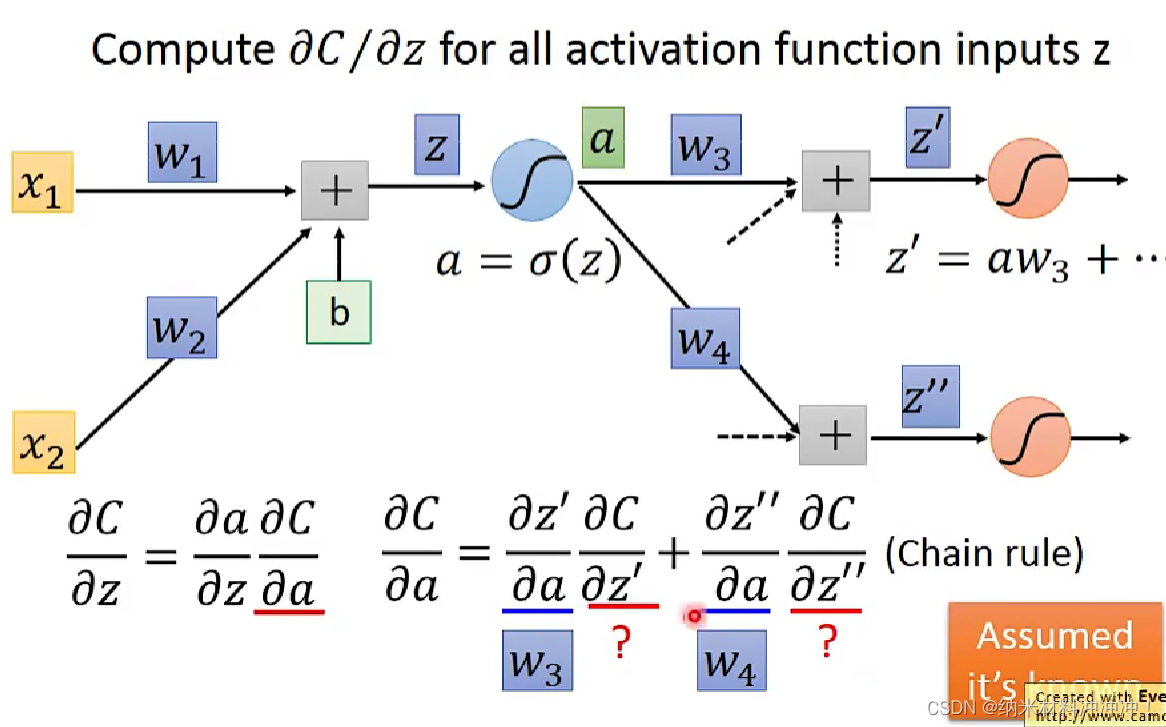
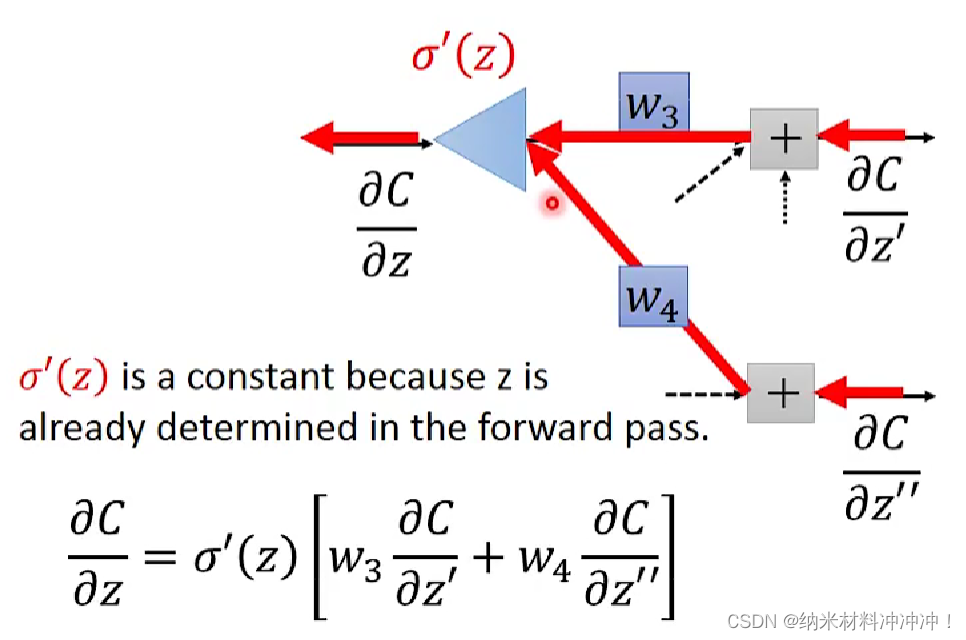
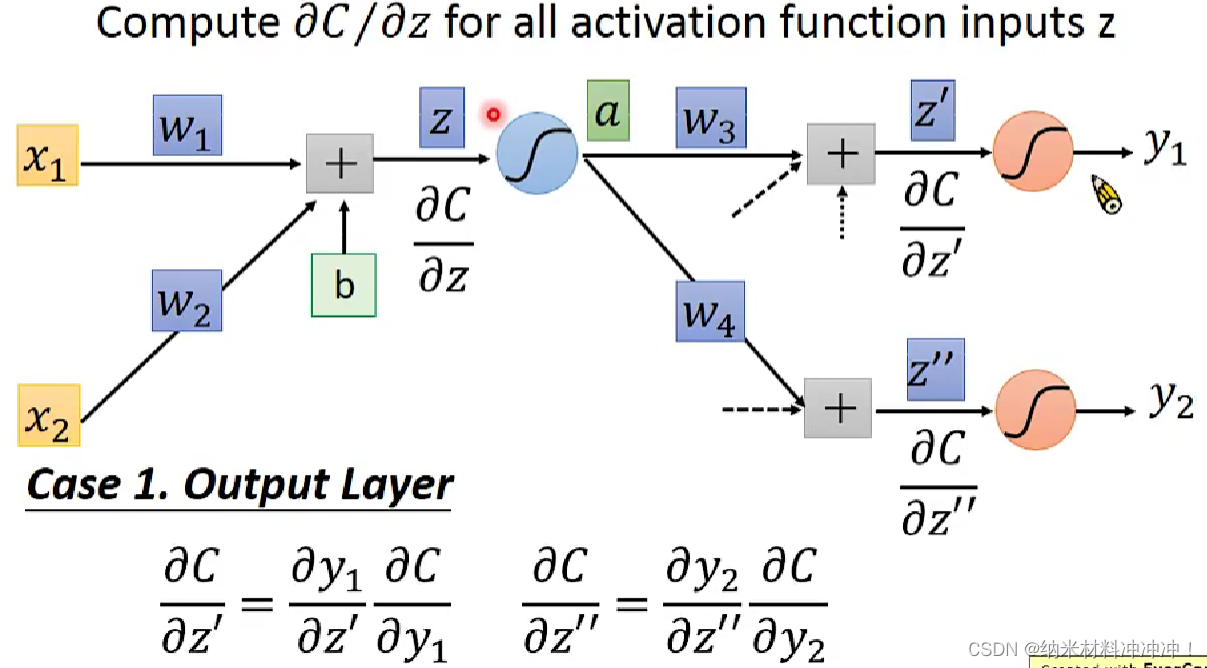
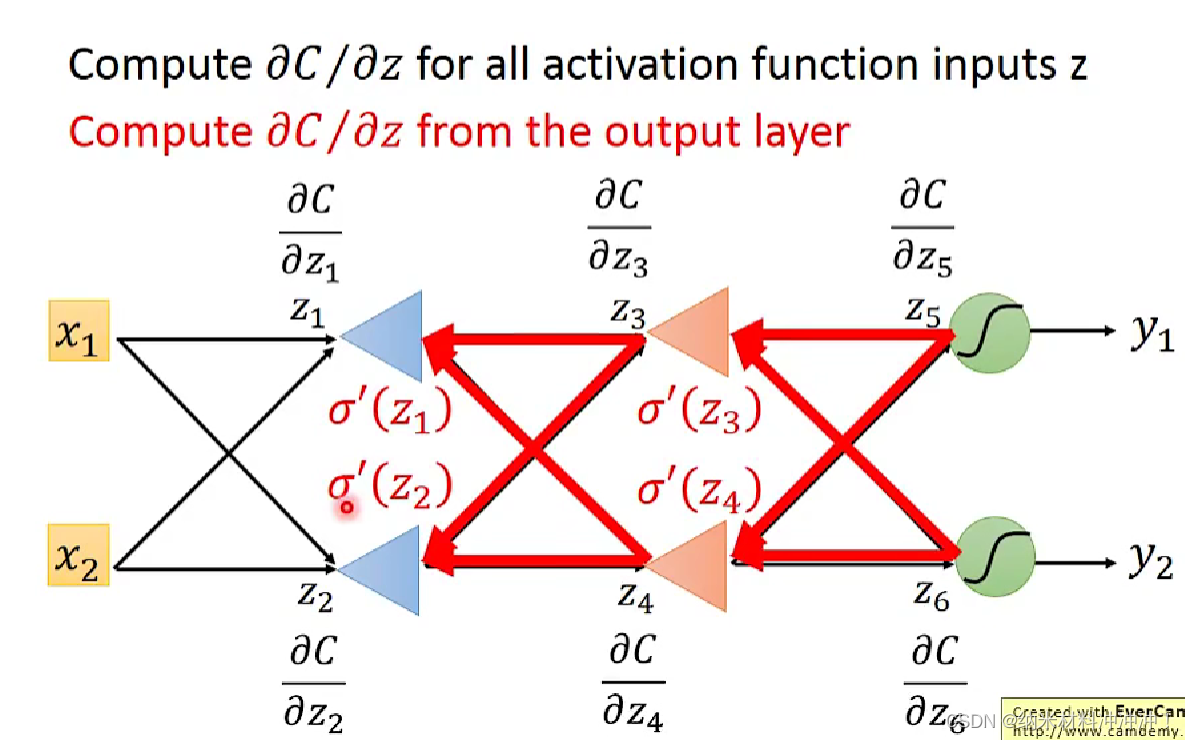
Backpropagation
如何使用gradient descent 训练一个 neuron network!
neuron network的方法:

- 随机选取一个 θ 0 \theta^0 θ0,然后计算梯度
- 根据梯度值与learning rate,得到一个新的 θ 1 \theta^1 θ1
- 以此类推,直到终止条件
问题: neuron network中的参数太多了!
我们可以用Backpropagation来计算gradient
对于neuron network,我们的loss function是交叉熵的和
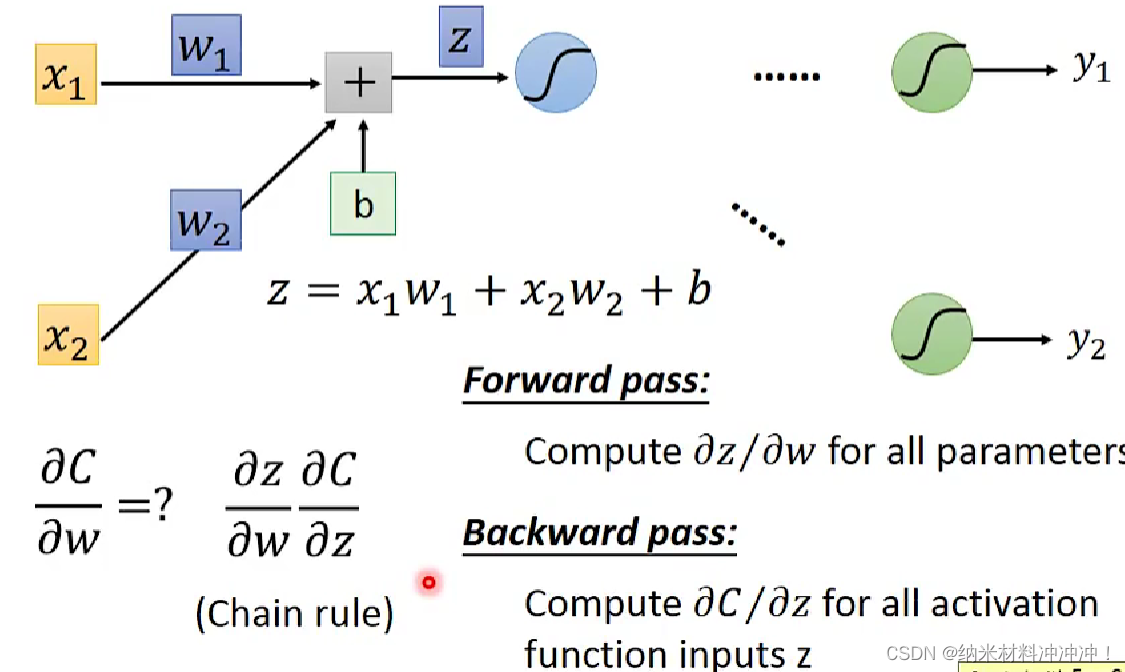
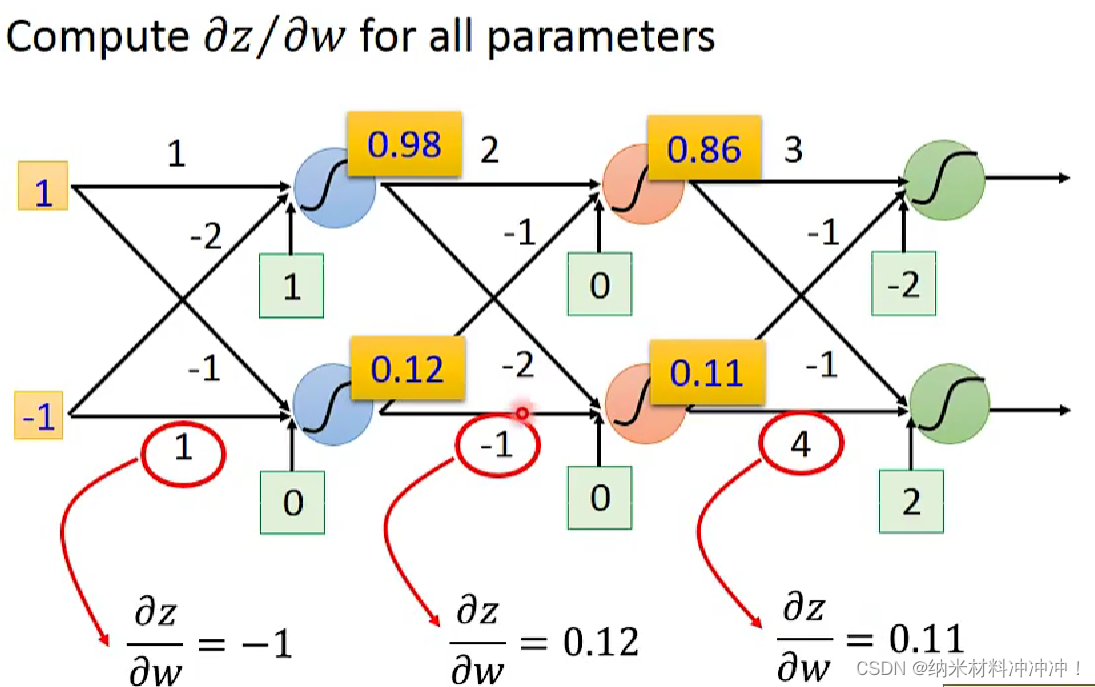
















 4886
4886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









