








OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
🎏目录
🎈1 Paddle环境
🎈2 数据集
🎄2.1 数据集介绍
🎄2.2 数据集解压
🎄2.3 数据集分割
🎄2.4 结果展示
🎈3 PaddleOCR部署
🎈4 模型
🎄4.1 预训练模型
🎄4.2 配置文件
🎈5 模型训练
🎄5.1 错误1
🎄5.2 错误2
对基于PaddleOCR实现中文场景文字识别进行学习,从环境配置,数据集,模型和训练等方面进行总结。
1 ✨Paddle环境
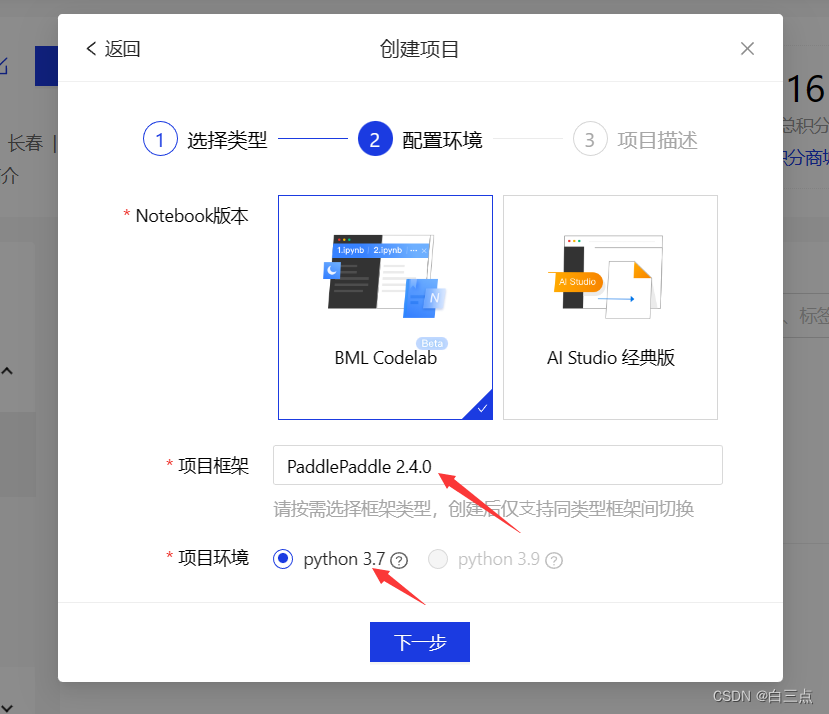
使用的是飞桨自带的notebook,试过很多环境,最终在PaddlePaddle 2.4.0和python3.7的环境中完成了训练:
✨2 数据集
2.1 🎃数据集介绍
数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。
数据目录结构如下(data文件夹下)::
data8429
train_images.tar.gz # 训练集和验证集
train.list # 标签文件
data84230
train_images.tar.gz # 测试集
2.2 🎃数据集解压
从上面可以看到,数据集为压缩包形式,需要进行解压。
%cd ~/data
!tar -zxf data8430/test_images.tar.gz
!tar -zxf data8429/train_images.tar.gz
2.3 🎃数据集分割
1️⃣参考文章:https://aistudio.baidu.com/aistudio/projectdetail/588846?channelType=0&channel=0
解压的train_images.tar.gz分割为训练集和验证集,比例是95:5。
%cd ~
import os
import random
# from zhtools.langconv import Converter
from zhconv import convert
word_list = []
datas = []
def is_chinese(uchar):
"""判断一个unicode是否是汉字"""
if uchar >= u'\u4e00' and uchar<=u'\u9fa5':
return True
else:
return False
def is_number(uchar):
"""判断一个unicode是否是半角数字"""
if uchar >= u'\u0030' and uchar<=u'\u0039':
return True
else:
return False
def is_english(uchar):
"""判断一个unicode是否是英文字母"""
if uchar >= u'\u0061' and uchar<=u'\u007a':
return True
else:
return False
def Q2B(uchar):
"""单个字符 全角转半角"""
inside_code = ord(uchar)
if inside_code == 0x3000:
inside_code = 0x0020
else:
inside_code -= 0xfee0
if inside_code < 0x0020 or inside_code > 0x7e: #转完之后不是半角字符返回原来的字符
return uchar
return chr(inside_code)
# 读取标注文件
with open('data/data8429/train.list', 'r', encoding='UTF-8') as f:
for line in f:
name, label = line[:-1].split('\t')[-2:]
label = label.replace(' ','')
label = convert(label, "zh-cn")
label.lower()
new_label = []
for word in label:
word = Q2B(word)
if is_chinese(word) or is_number(word) or is_english(word):
new_label.append(word)
if word not in word_list:
word_list.append(word)
if new_label!=[]:
datas.append('%s\t%s\n' % (os.path.join('train_images',name), ''.join(new_label)))
word_list.sort()
# 生成词表
with open('data/vocab.txt', 'w', encoding='UTF-8') as f:
for word in word_list:
f.write(word+'\n')
random.shuffle(datas)
split_num = int(len(datas)*0.95)
# 分割数据为训练和验证集
with open('data/train.txt', 'w', encoding='UTF-8') as f:
for line in datas[:split_num]:
f.write(line)
with open('data/dev.txt', 'w', encoding='UTF-8') as f:
for line in datas[split_num:]:
f.write(line)
在该环境中,出现了安装了zhtools但是无法识别的问题,因此,这里换成了zhconv库(原因未知)。
总结部分不常用的代码,其中三个判断函数:
is_chinese,判断一个unicode是否是汉字 => 汉字的unicode范围\u4e00 — \u9fa5:is_number,判断一个unicode是否是数字 => 数字的unicode范围\u0030 — \u0039is_english,判断一个unicode是否是英文字母 => 英文字母的的unicode范围\u0061 — \u007a
label = convert(label, "zh-cn")是利用的zhconv库将繁体字转化为简体字。
函数Q2B将全角转化为半角。
2.4 🎃结果展示
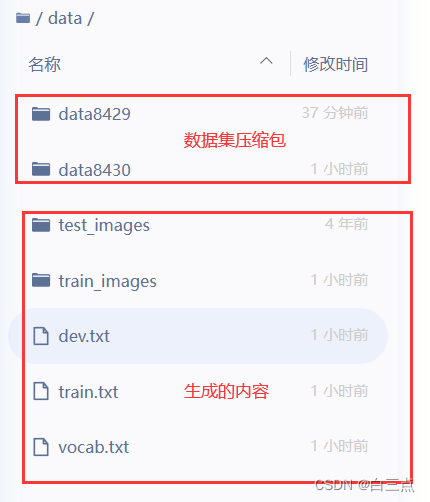
经过数据集解压和分割,生成的数据应该如下:
3 ✨部署PaddleOCR
拉取最新的PaddleOCR:
#下载paddleocr
%cd ~
!git clone https://gitee.com/paddlepaddle/PaddleOCR
安装相关依赖:
#安装相关依赖
%cd PaddleOCR
!pip install -r requirements.txt --user
%cd ~
如果没有--user会提示权限不足
4 ✨模型
4.1 🎃预训练模型
官方gitee中公布了支持的算法模型:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/algorithm_overview.md#/paddlepaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/recognition.md
如下表:
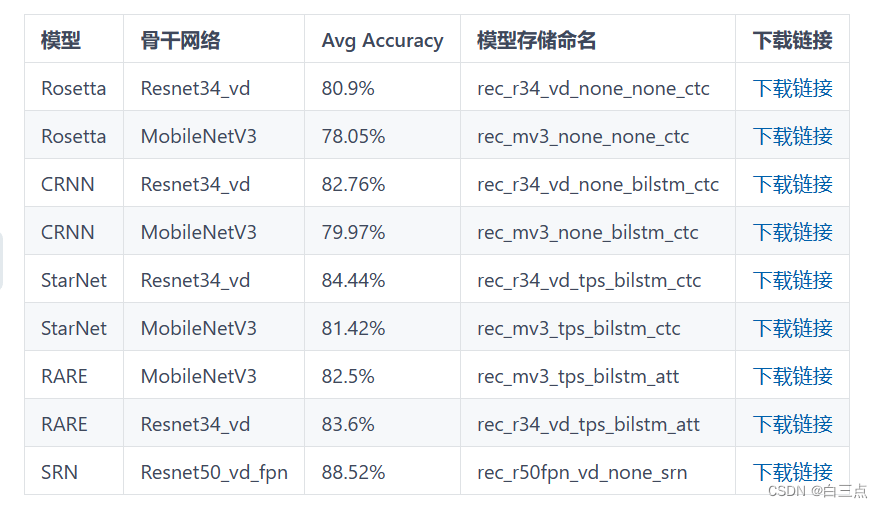
这里我们选择的是以MobileNet V3作为Backbone的CRNN。
CRNN的原理总结:https://blog.csdn.net/weixin_51691064/article/details/130208337?ydreferer=aHR0cHM6Ly9tcC5jc2RuLm5ldC9tcF9ibG9nL21hbmFnZS9hcnRpY2xlP3NwbT0xMDAwLjIxMTUuMzAwMS41NDQ4
拉取CRNN预训练模型
%cd ~/PaddleOCR
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mv3_none_bilstm_ctc_v2.0_train.tar
解压:
!tar -xf /home/aistudio/PaddleOCR/pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train.tar -C /home/aistudio/PaddleOCR/pretrain_models
4.2 🎃配置文件
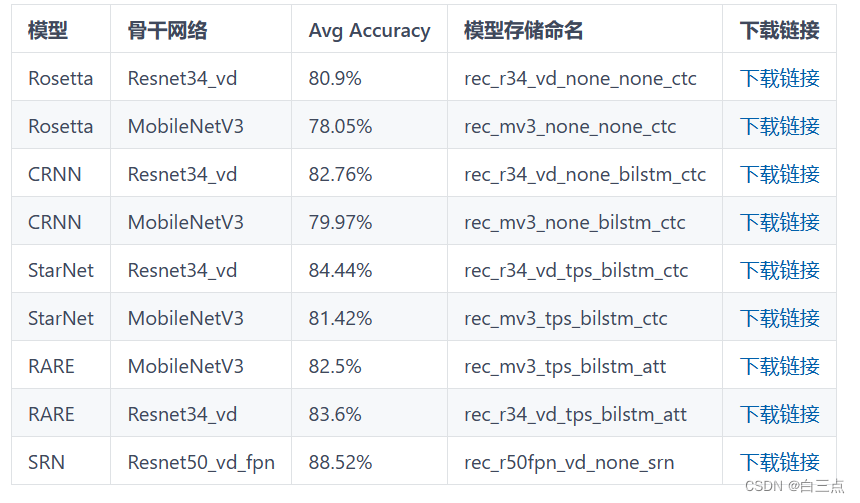
图表格中,MobileNet V3的CRNN的模型存储名称为rec_mv3_none_bilstm_ctc,其中包含了训练信息,比如epoch总数,数据集路径等…
该配置文件路径为PaddleOCR/configs/rec/rec_mv3_none_bilstm_ctc.ml,打开用下列内容替代:
Global:
debug: false
use_gpu: true
epoch_num: 200 # epoch总数
log_smooth_window: 20
print_batch_step: 10 # 没多少steo打印一次信息
save_model_dir: ./output/v3_en_mobile #模型保存路径
save_epoch_step: 3 # 多少次epoch保存一次模型及权重
eval_batch_step: [0, 500] # 设置模型评估间隔(多少step使用一次验证集)
cal_metric_during_train: true
pretrained_model: /home/aistudio/PaddleOCR/pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train/best_accuracy # 设置加载预训练模型路径
checkpoints: # 加载模型参数路径 用于中断后加载参数继续训练
save_inference_dir:
use_visualdl: True # 设置是否启用visualdl进行可视化
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/en_dict.txt # 设置字典路径
max_text_length: &max_text_length 25 # 设置文本最大长度
infer_mode: false
use_space_char: true # 设置是否识别空格
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3_en.txt #推理保存结果
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- SARLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data # 训练集路径
ext_op_transform_idx: 1
label_file_list: # 训练集标签
- /home/aistudio/data/train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 128
drop_last: true
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data # 验证集路径
label_file_list:
- /home/aistudio/data/dev.txt # 验证集标签
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4
特别注意的是训练集和验证集的图像数据其实还是在一个文件夹中,只是标签文件不同。标签文件中,每行都包含两个信息图像路径 label
5 ✨模型训练
%cd ~/PaddleOCR
# 设置PYTHONPATH路径
%env PYTHONPATH=$PYTHONPATH:.
# GPU单卡训练
%env CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py -c /home/aistudio/PaddleOCR/configs/rec/rec_mv3_none_bilstm_ctc.yml
-c指定配置文件。如果需要多卡训练,比如四张卡,%env CUDA_VISIBLE_DEVICES=0替换为%env CUDA_VISIBLE_DEVICES=0,1,2,3
5.1 🎃错误1
no module name pywt
解决办法:pip install PyWavelets
5.2 🎃错误2
[2023/04/29 09:56:32] ppocr ERROR: No Images in train dataset, please ensure
1. The images num in the train label_file_list should be larger than or equal with batch size.
2. The annotation file and path in the configuration file are provided normally.
配置文件中Train和Eval部分的问题,换成:
Train:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data
ext_op_transform_idx: 1
label_file_list:
- /home/aistudio/data/train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 128
drop_last: true
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data
label_file_list:
- /home/aistudio/data/dev.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4
其中路径自己切换

















 4745
4745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











