







 SPPNet由何凯明提出,通过固定尺寸的池化层解决CNN输入尺寸问题,而YOLO系列中的SPP结构更侧重于特征图级别的局部与全局特征融合。SPPF是YOLOV5中的改进版,减少了计算量,提高了模型速度。
SPPNet由何凯明提出,通过固定尺寸的池化层解决CNN输入尺寸问题,而YOLO系列中的SPP结构更侧重于特征图级别的局部与全局特征融合。SPPF是YOLOV5中的改进版,减少了计算量,提高了模型速度。

在卷积神经网络中我们经常看到固定输入的设计,但是有的时候难以控制,何凯明大神的论文SPPNet中的SPP结构解决了该问题。
后续在YOLO系列中也出现了SPP结构及改进的结构,但是作用与最初的SPP结构却是不同的。
🎏目录
🎈1 SPPNet中的SPP
🎈2 YOLO中的SPP/SPPF
🎄2.1 SPP
🎄2.2 SPPF
✨1 SPPNet中的SPP
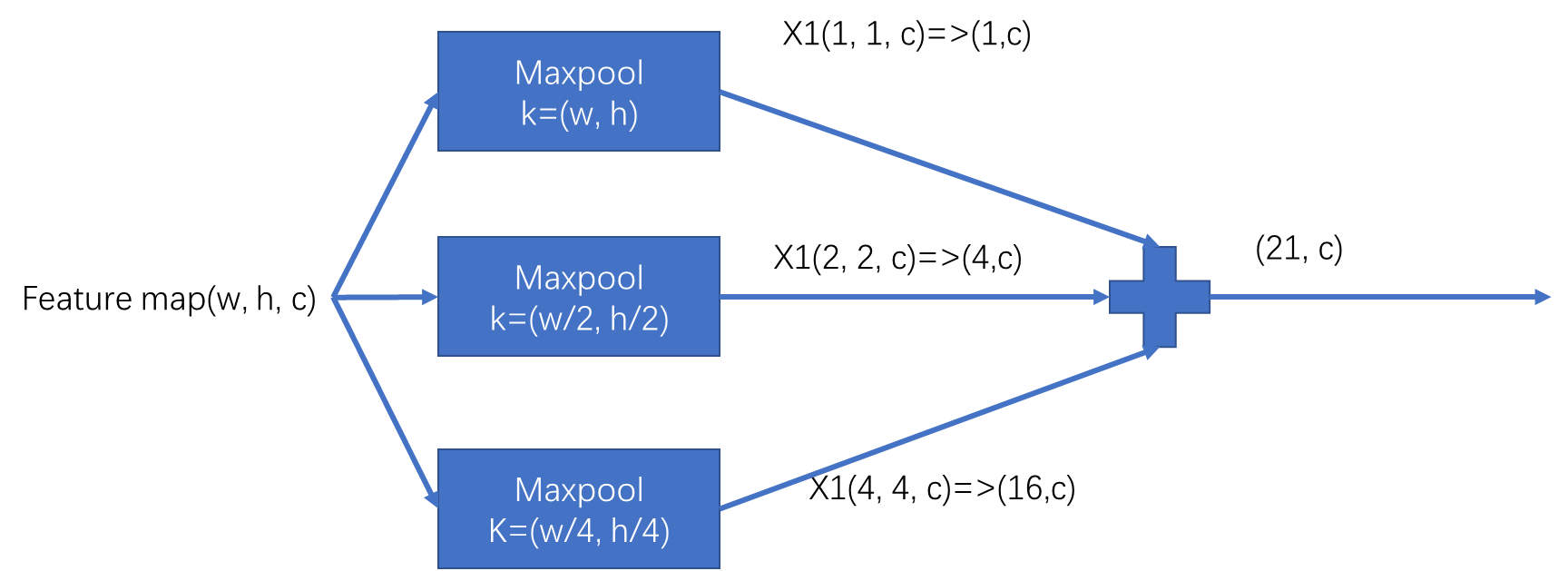
原始SPP结构如下图所示:
下面默认通道数不变
首先输入Feature map(w,h,c)需要经过三个池化层:
k=(w, h, c)的池化层相当于将对整个图像取一次最大化操作,输出为(1, 1, c)的特征图。k=(w/2, h/2, c)的池化层相当于将整个图像平均划分为4分,每一份取一次最大化操作,输出为(2, 2, c)的特征图。k=(w/4, h/4, c)的池化层相当于将整个图像平均划分为16分,每一份取一次最大化操作,输出为(4, 4, c)的特征图。
然后将三个池化操作分别进行维度变换,再进行拼接操作。最终产生维度为(21, c)的向量。
通过上述两个步骤,可以看到我们的输入(w, h, c)不管如何变化,最终的输出都是(21, c)。
这里更多的是提供了一个思想,在不同网络中采用了不同的尝试,比如利用卷积层代替池化层等等…
✨2 YOLO中的SPP/SPPF
与上面何凯明大神提出的不同,这里的SPP虽然也叫SPP,但是作用更多的是实现局部特征和全局特征的featherMap级别的融合。
🥓2.1 SPP
下面忽略了通道数的变化
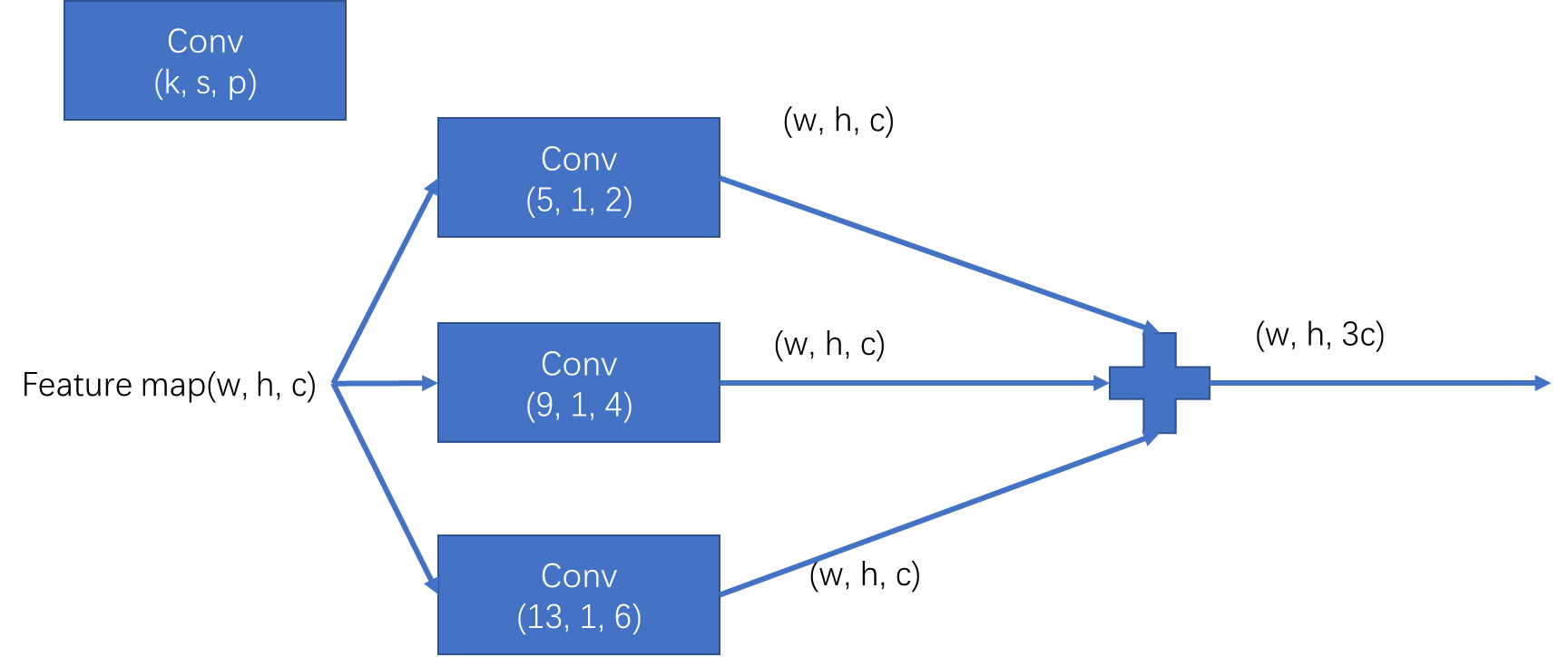
其中k(kernel_size)为卷积核尺寸。s(stride)为步长,p(padding)为在所有边界增加值。
可以看到与上面介绍的何凯明大神提出的SPP是不同的,输入Feature map(w, h, c)经过三次卷积操作像素并没有发生改变,作用更多的是实现局部特征和全局特征的featherMap级别的融合。
YOLO中的代码
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)): # 5,9,13分别是三个卷积操作的卷积核大小
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning忽略警告
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
💫2.2 SPPF
SPPF由yolo系列中的SPP结构改进而来,目的没有变化,只是从SPP改进为SPPF后,模型的计算量变小了很多,模型速度提升。
YOLOV5中的SPPF结构:
忽略了通道数的变化
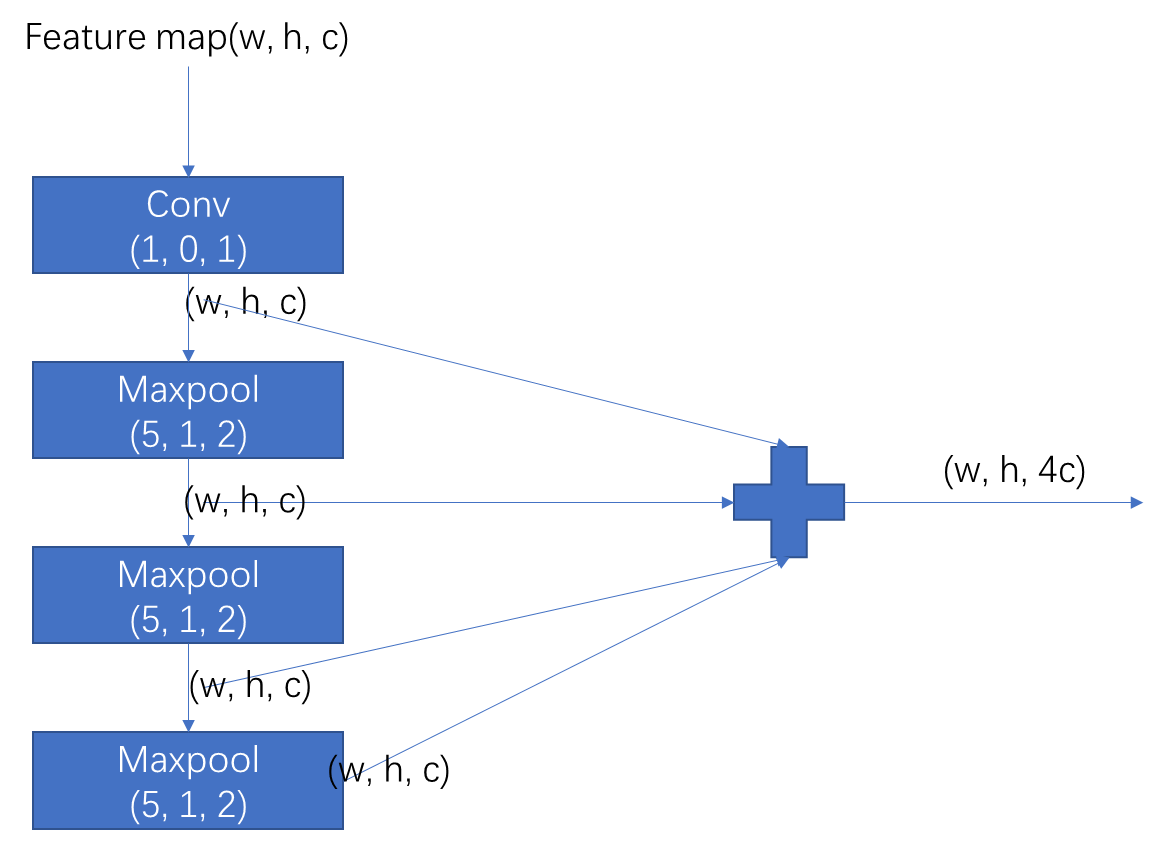
其中Conv和Maxpool中第一个数(kernel_size)为卷积核尺寸。第二个数(stride)为步长,第三个数(padding)为在所有边界增加值。
YOLO V5代码:
class SPPF(nn.Module):
"""
This code referenced to https://github.com/ultralytics/yolov5
"""
def __init__(self, in_dim, out_dim, expand_ratio=0.5, pooling_size=5, act_type='lrelu', norm_type='BN'):
super().__init__()
inter_dim = int(in_dim * expand_ratio)
self.out_dim = out_dim
self.cv1 = Conv(in_dim, inter_dim, k=1, act_type=act_type, norm_type=norm_type)
self.cv2 = Conv(inter_dim * 4, out_dim, k=1, act_type=act_type, norm_type=norm_type)
self.m = nn.MaxPool2d(kernel_size=pooling_size, stride=1, padding=pooling_size // 2)
def forward(self, x):
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
从代码中可以看到其中进行的三次池化操作用到的均是统一个池化核。



















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











