








该任务基于图像分类网络Alex实现。
🎏目录
🎈1 train脚本
🎄1.1 设备
🎄1.2 数据集
🎉1.2.1 图像增强
🎉1.2.2 MMAFEDB表情识别数据集介绍
🎉1.2.3 重载DataSet
🎉1.2.4 DataLoader打包
🎄1.3 模型
🎄1.4 优化器和损失函数
🎄1.5 模型及参数的加载和保存
🎉1.5.1 模型的加载和保存
🎉1.5.2 权重的加载和保存
🎄1.6 模型评估
🎈2 重载DataSet(代码)
🎈3 一些注意点
✨1 train脚本
从设备,数据集,模型,优化器,损失函数,进度条,模型评估和参数保存等方面进行总结说明。
🌭1.1 设备
cpu或者单卡gpu:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
多卡gpu待补充…
🍕1.2 数据集
这部分包含数据增强,重载DataSet类,DataLoader打包三项操作,下面一一介绍:
🎆 1.2.1 图像增强
表情识别属于分类任务,数据预处理比较简单:
ToTensor将数据转化为Tensor数据。RandomResizedCrop将图像裁剪到224的大小(这是网络要求的)。RandomHorizontalFlip增强图像的泛化性。Normalize归一化使得数据的分布更加均匀,减少模型学到数据分布的可能性。
data_transform = {
"train": transforms.Compose([
transforms.ToTensor(),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
"val": transforms.Compose([
transforms.ToTensor(),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
需要注意的是,cv2打开的图像数据类型是numpy,不能进行ToTensor之外的图像增强操作。因此,该步必须放在第一个。
🍔1.2.2 MMAFEDB表情识别数据集介绍
百度网盘(5pi5)
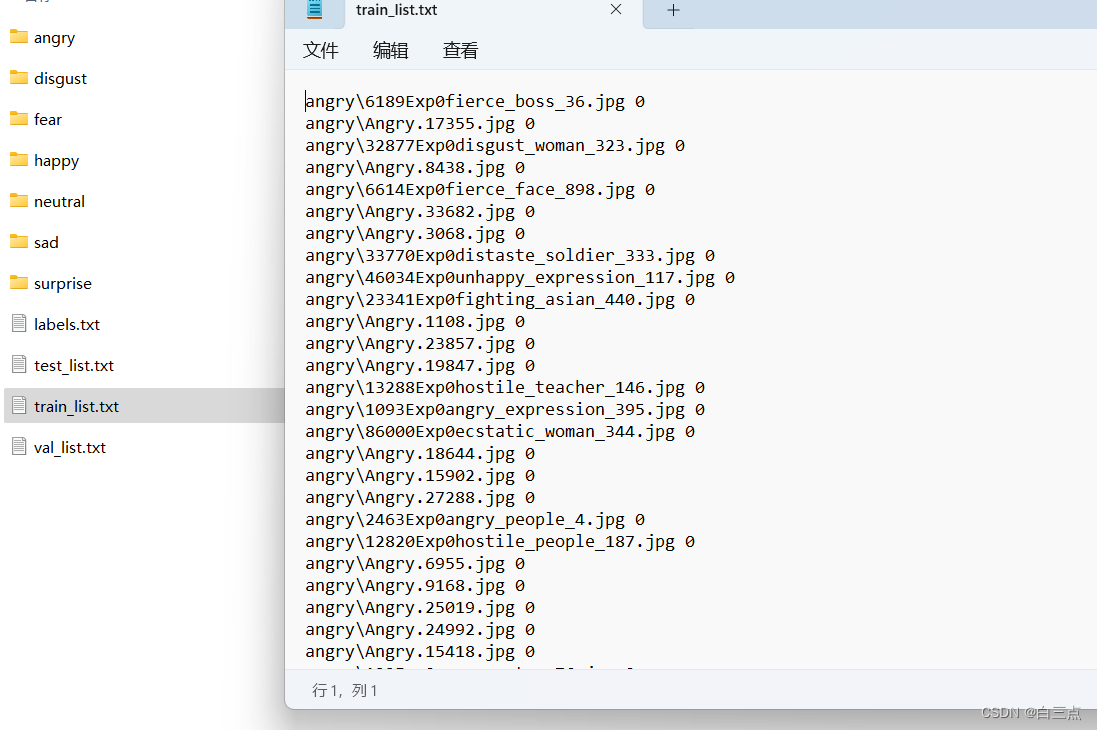
下载数据集并解压后,内容如下:
labels.txt:标签种类train_list.txt,val_list.txt,val_list.txt:分别是训练数据,验证数据和测试数据,每条内容未图像路径 标签- 各文件夹名称即分类标签,内部是该分类的图像数据。
🌭1.2.3 重载DataSet
点击此处进入之前总结过的自定义数据集的总结
处理MMAFEDB的详细代码见第二节。导入数据集代码为:
train_dataset = MMAFEDB(root_path, is_type="train", transform=data_transform["train"])
val_dataset = MMAFEDB(root_path, is_type="eval", transform=data_transform["val"])
其中root_path为txt文件的父路径。is_type可选参数,为"train"或"eval"或"test",即导入的是什么数据。transform是图像增强操作。
🎃1.2.4 DataLoader打包
假设已经创建DataSet的重载类,即数据集导入完成。打包操作为:
# 打包
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=512,
shuffle=True,
# num_workers=nw,
)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=512,
shuffle=True
)
更具体的参数见1.2.3链接第二节
🎄1.3 模型
分类模型有很多:Alex,GooleNet,ResNet,MobileNet…这里选用AlexNet,其它后续也会进行尝试,待补充…
🎈1.4 优化器和损失函数
损失函数的一些总结
优化器待补充…梯度下降算法推荐看刘建平老师的博客
这里是使用了Pytorch包装好的Adam优化器和交叉熵损失函数:
optimizer = torch.optim.Adam(model.parameters(), lr=0.0002) # 总结
loss_function = torch.nn.CrossEntropyLoss()
✨1.5 模型及参数的加载和保存
🍕1.5.1 模型的加载和保存
保存模型用到torch.save(model, save_dir)函数,其中model是自定义的模型对象,save_dir是保存路径:
save_dir = "" # 保存路径,自定义
torch.save(model, save_dir)
而加载该模型应该是:
torch.load(save_path) # save_path是保存的模型的路径
🎆1.5.2 权重的加载和保存
保存权重分为两步:获取权重和保存参数:
model.state_dict()获取参数:
paramters = model.state_dict()
torch.save保存:
torch.save(paramters, save_path) # save_path是保存路径,自定义
加载模型,仍然用torch.load:
paramters = torch.load(save_path) # save_path是权重文件的保存路径
只是后面,我们需要用load_state_dict将参数赋予模型:
model.load_state_dict(paramters)
🍔1.6 模型评估
这里先简单采用正确率:
# 验证部分
model.eval()
acc = 0.0
best_acc = 0.0
with torch.no_grad():
for i, data in enumerate(val_loader):
img, label = data
output = model(img.to(device))
pred = torch.max(output, dim=1)[1]
acc += torch.eq(pred, label.to(device)).sum().item() # TODO 1 累加batch个中预测和标签一致的数量
acc = acc / len(val_dataset) # TODO 2 所有数据acc累加除所有数据的数量
print("acc: {}".format(acc))
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), "./weights/best.pth")
代码中两行注释即正确率的计算方法。
需要注意的是,len(val_dataset)即可得到所有数据的数量,在其它任务中肯定会用到。
✨2 重载DataSet(代码)
from torch.utils.data import Dataset
import os
import cv2
from torchvision import transforms
import torch
class MMAFEDB(Dataset):
def __init__(self, path: str, is_type: str, transform=None):
"""
:param path: Parent path of the dataset
:param transform:
"""
assert os.path.exists(path), "no path:{}".format(path)
self.path = path
self.type = is_type
self.transform = transform
self.img_path = []
self.label = []
self.load_path()
def __len__(self):
return len(self.img_path)
def __getitem__(self, index):
img_path = self.img_path[index]
label = self.label[index]
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if self.transform is not None:
img = self.transform(img)
label = torch.as_tensor(int(label))
return img, label
def load_path(self):
try:
if self.type == "train":
with open(os.path.join(self.path, "train_list.txt"), "r", encoding="utf-8") as file:
lines = file.readlines()
elif self.type == "eval":
with open(os.path.join(self.path, "val_list.txt"), "r", encoding="utf-8") as file:
lines = file.readlines()
elif self.type == "test":
with open(os.path.join(self.path, "test_list.txt"), "r", encoding="utf-8") as file:
lines = file.readlines()
except FileExistsError as e:
print(e)
for line in lines:
img_path, cl = line.split()
img_path = os.path.join(self.path, img_path)
self.img_path.append(img_path)
self.label.append(cl)
if __name__ == "__main__":
data_transform = {
"train": transforms.Compose([
transforms.ToTensor(),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
"val": "",
}
dataset = MMAFEDB("E:/DataSet/MMAFEDB", is_type="train", transform=data_transform["train"])
for data in dataset:
print(2)
if __name__ == "__main__"中是用以测试的代码,首要关注MMAFEDB类:
load_path函数将txt文件中的图片数据路径和label提取出来,存入self.img_path和self.label中
__getitem__函数通过index,提取一张图像和对应label。然后进行图像增强操作(img = self.transform(img)),通过label = torch.as_tensor(int(label))将label的数据类型转化为Tensor。这里主要用as_tensor而不是to_tensor,主要是因为to_tensor会将数据除255,as_tensor数据保持不变。因此to_Tensor用于image,给image进行归一化。as_Tensor用于label,保持原有标签。
✨ 4 一些注意点
- 模型to设备时不用多赋予一次值,即不用
model = model.to(device),只需要执行model.to(device)即可。 - 训练前优化器权重要清零
optimizer.zero_grad() - 利用model和loss_functional计算式,设备必须统一,数据类型也必须是张量。
model.train()和model.eval()作用是开启/关闭dropout和BN操作,如果没有使用与否没有区别。with torch.no_grad()关闭自动求导,验证时必须开启。

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











