





原文:Fedus, William, Barret Zoph and Noam M. Shazeer. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” ArXiv abs/2101.03961 (2021).
1. Abstract
在深度学习中,模型通常对所有输入复用相同的参数。混合专家(MoE)模型对此不屑一顾,而是为每个输入的示例选择不同的参数。结果形成了一个稀疏激活的模型——参数数量惊人——但计算成本不变。尽管MoE取得了一些显著的成功,但由于复杂度、通信成本和训练不稳定等原因,它的广泛应用受到了阻碍。我们采用Switch Transformer来解决这些问题。我们简化了MoE路由算法,设计了直观的改进模型,降低了通信和计算成本,减轻了训练的不稳定性。我们首次展示了大型稀疏模型可以用较低精度的格式进行训练。我们设计了基于T5-Base和T5-Large的模型,以在相同计算资源的情况下,使预训练速度提高7倍。最后,我们在爬取的大型且干净的语料库上,预训练了多达万亿参数的模型,提高了语言模型的规模,并实现了比T5-XXL模型快4倍的提速。
2. Method, Experiment and Result
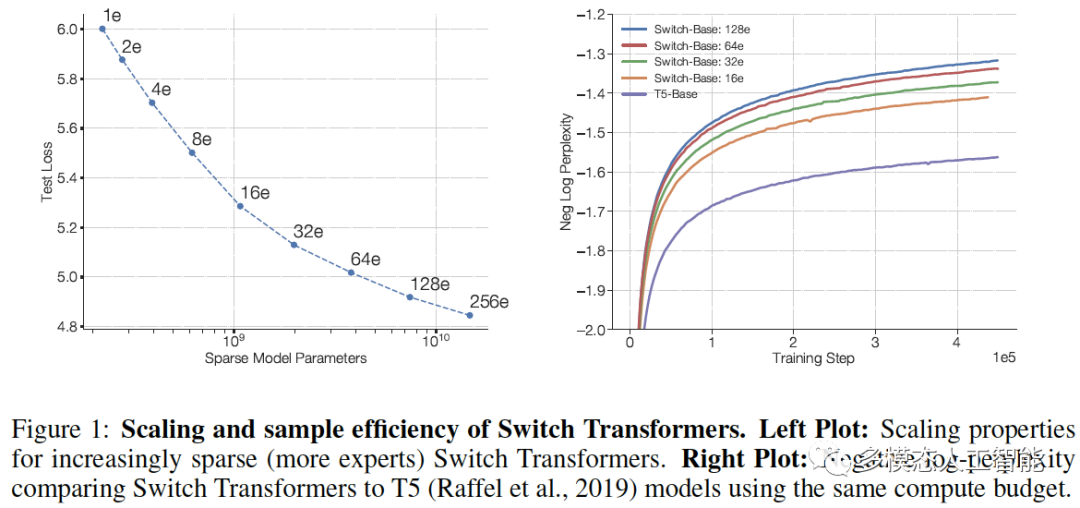
图1. Switch Transformers的扩展和采样效率。
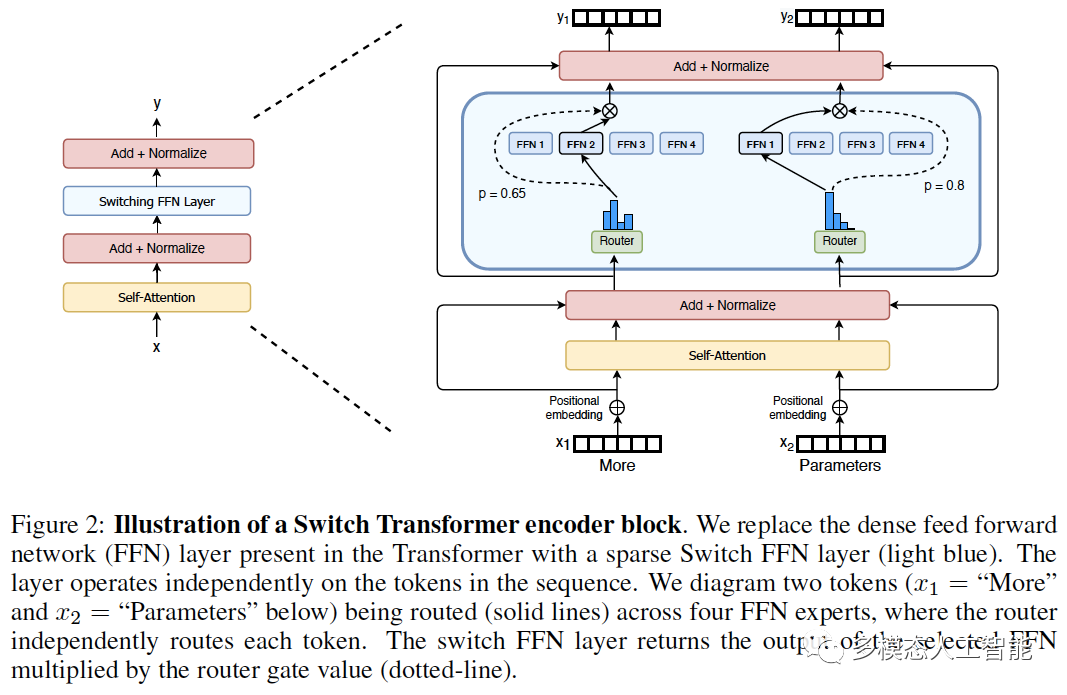
图2. Switch Transformer编码器块。我们将Transformer中的密集前馈网络(FFN)层替换为稀疏Switch FFN层(浅蓝色)。该层独立地对序列中的tokens进行操作。我们绘制了两个tokens(x1和x2)穿过四个FFN专家模型,其中路由器独立路由每个tokens。Switch FFN层返回所选FFN的输出与路由器权重值的乘积。
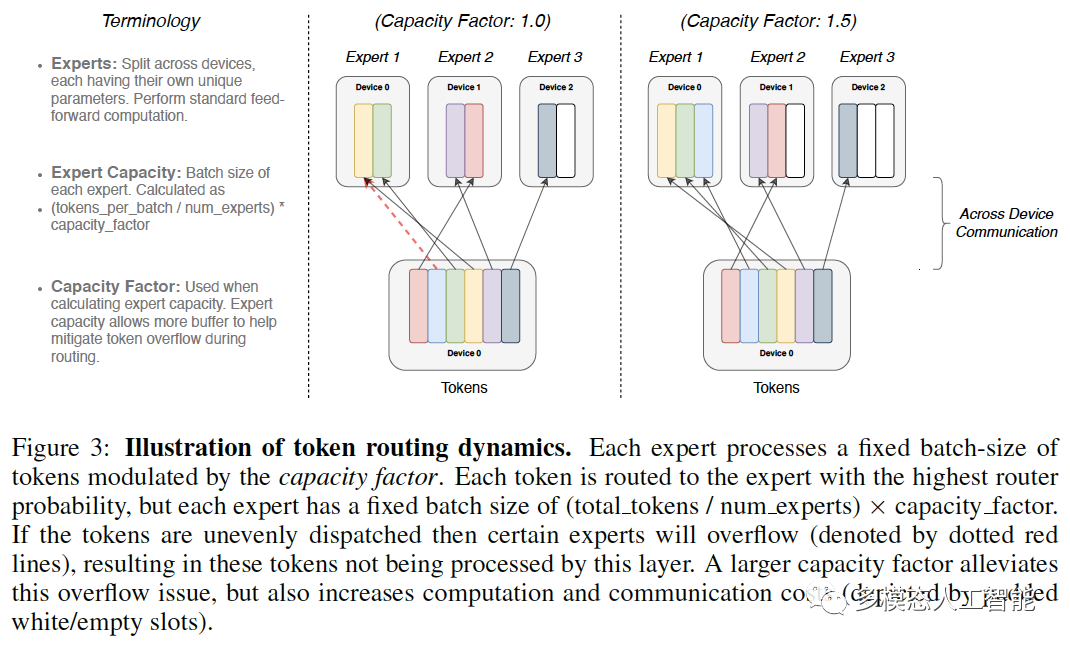
图3. 每个专家处理由容量因子调制的固定批量tokens,每个token都被路由到路由器概率最高的专家,但每个专家都有固定的批量大小:(tokens总数/专家数量)×容量因子。如果tokens分配不均,则某些专家将溢出(用红色虚线表示),导致该层无法处理这些tokens。较大的容量因子可以缓解这种溢出问题,但也会增加计算和通信成本。
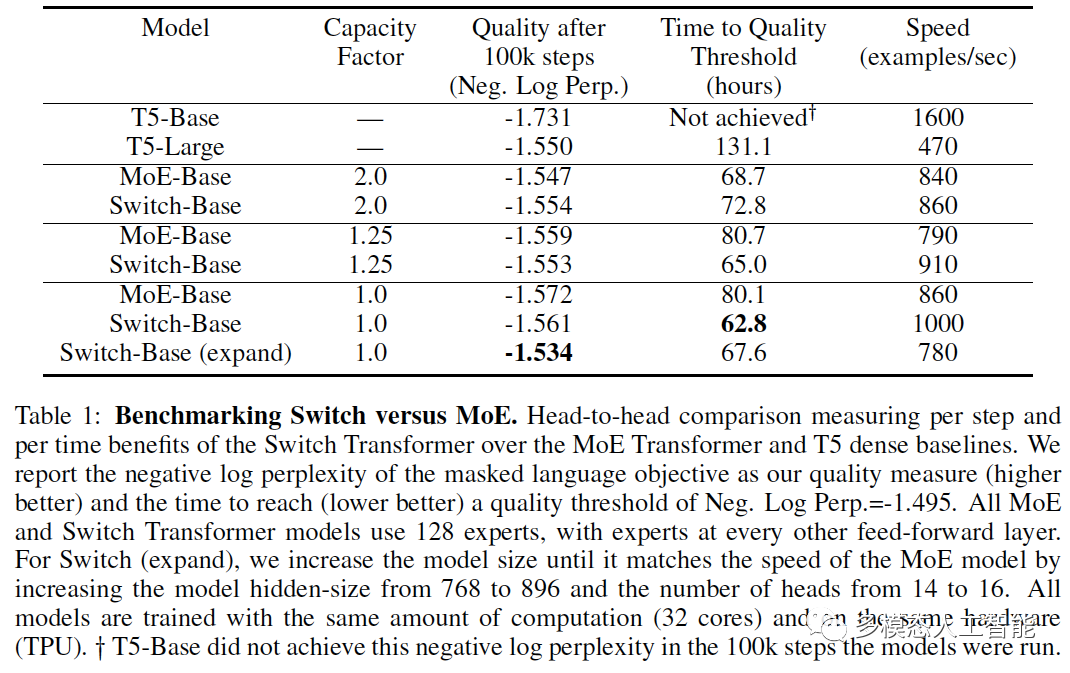
表1. 对Switch和MoE进行基准测试。
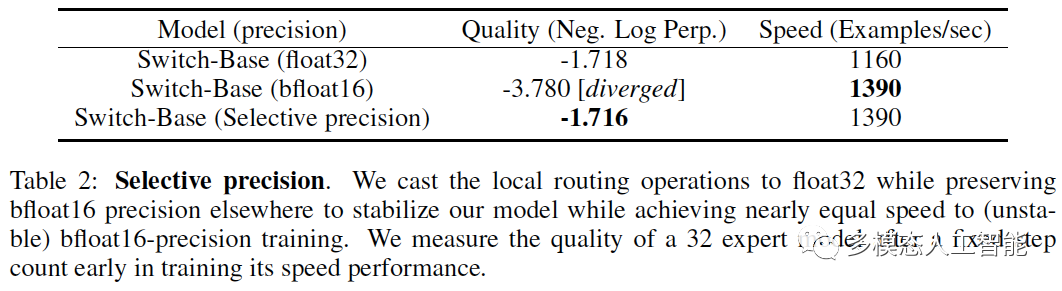
表2. 选择精度。我们将本地路由操作转换为float32,同时在其他地方保留bfloat16精度,以稳定我们的模型,同时实现与(不稳定的)bfloat16精度训练几乎相同的速度。
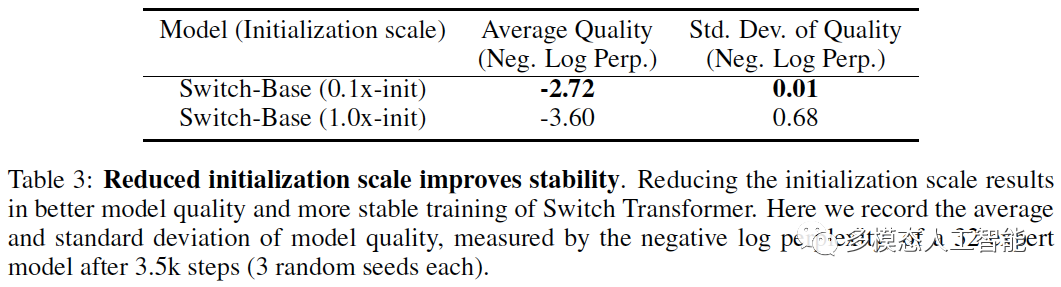
表3. 初始化规模的减小有利于改善模型的质量,提高Switch Transformer的训练稳定性。
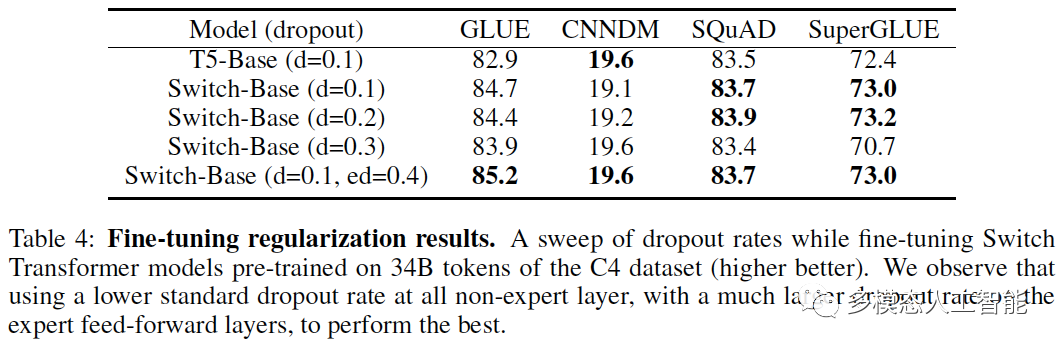
表4. 微调正则化结果。我们观察到,在所有非专家层使用较低的标准丢弃率,而在专家前馈层使用较大的丢弃率,可以实现最佳性能。

图4. Switch Transformer的扩展属性。左图:左上角的点对应于223M参数的T5-Base模型。从左上角移动到右下角,我们将专家数量从2、4、8增加一倍,以此类推,直到拥有14.7B参数、256个专家模型的右下角的点。右图:密集基线模型用紫色线表示,Switch-Base模型的采样效率有所提高。
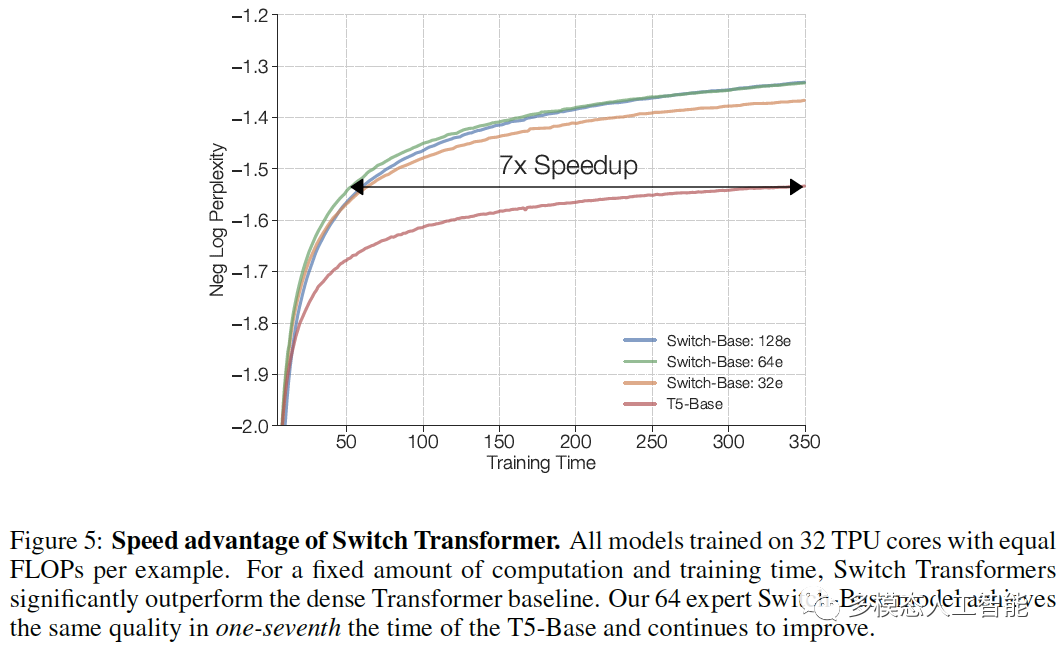
图5. Switch Transformer的速度优势。对于固定的计算量和训练时间,Switch Transformers的性能明显优于密集Transformer基线模型。包含64个专家的Switch-Base模型在T5-Base的七分之一时间内达到了相同的质量,并持续改进。
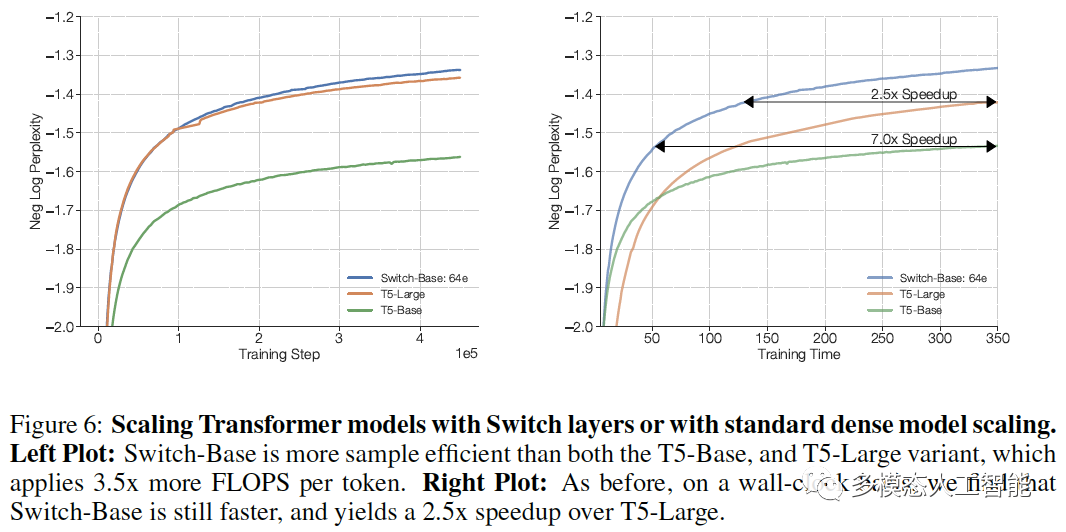
图6. Switch-Base比T5-Base和T5-Large更有效率。
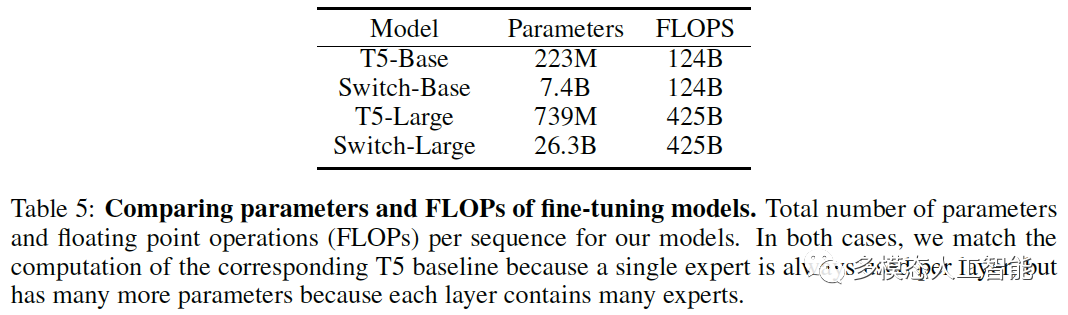
表5. 微调模型参数和浮点数的比较。
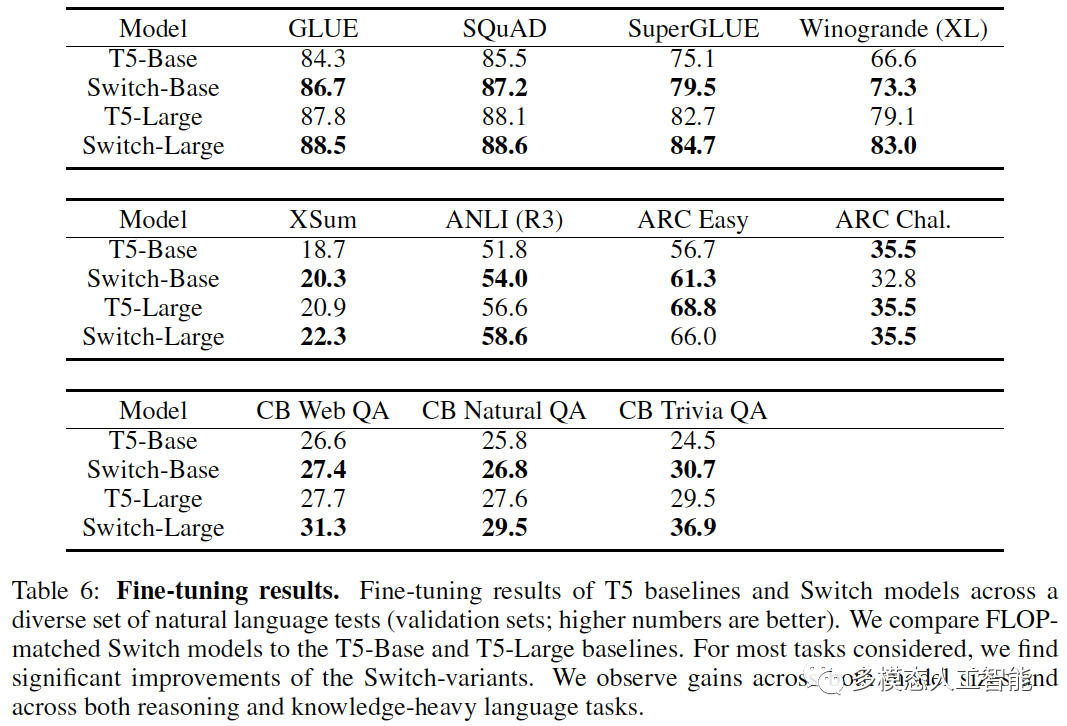
表6. T5基线模型和Switch模型在各种自然语言测试中的微调结果。我们将Switch模型与T5-Base和T5-Large基线模型进行比较。对于大多数任务,我们发现Switch变体模型有显著的改进。
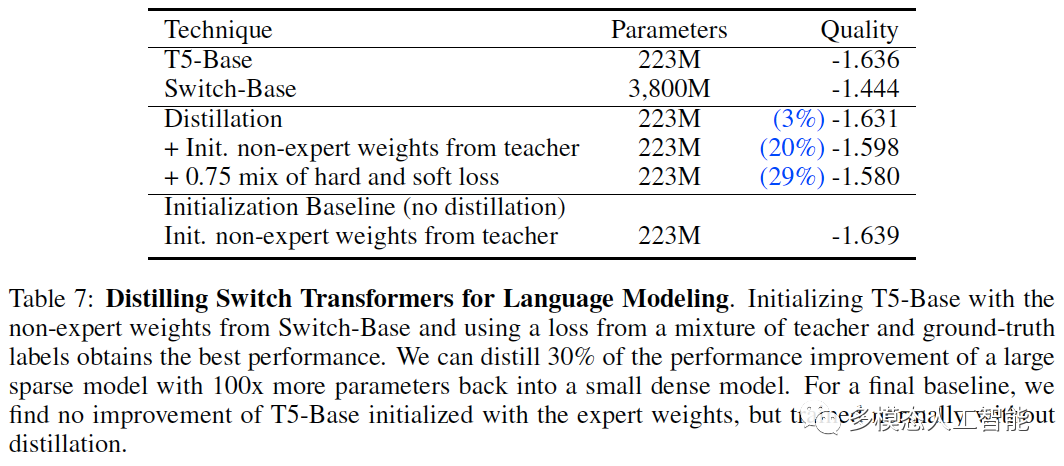
表7. 用于语言建模的蒸馏Switch Transformers。使用Switch-Base非专家权重初始化T5-Base,并使用teacher和ground-truth混合标签的损失,可以获得最佳性能。
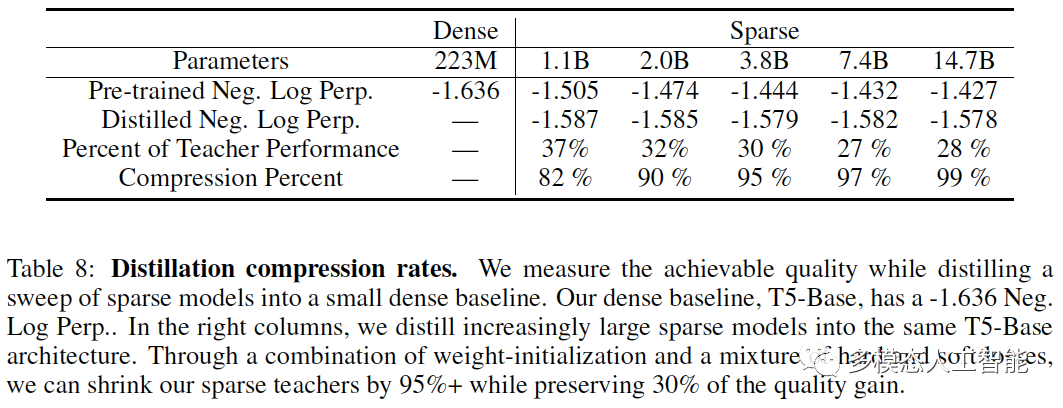
表8. 蒸馏压缩率。在右栏中,我们将越来越大的稀疏模型蒸馏到相同的T5-Base架构中。通过权重初始化和软硬损失的结合,我们可以将稀疏的教师数量减少95%以上,同时保留30%的质量增益。
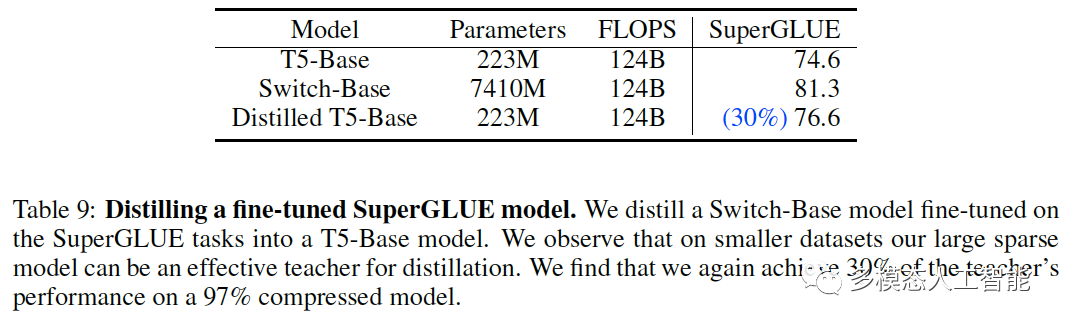
表9. 蒸馏微调过的SuperGLUE模型。我们将一个在SuperGLUE任务上微调的Switch-Base模型蒸馏到T5-Base模型。我们观察到,在较小的数据集上,我们的大型稀疏模型可以成为蒸馏的有效teacher。
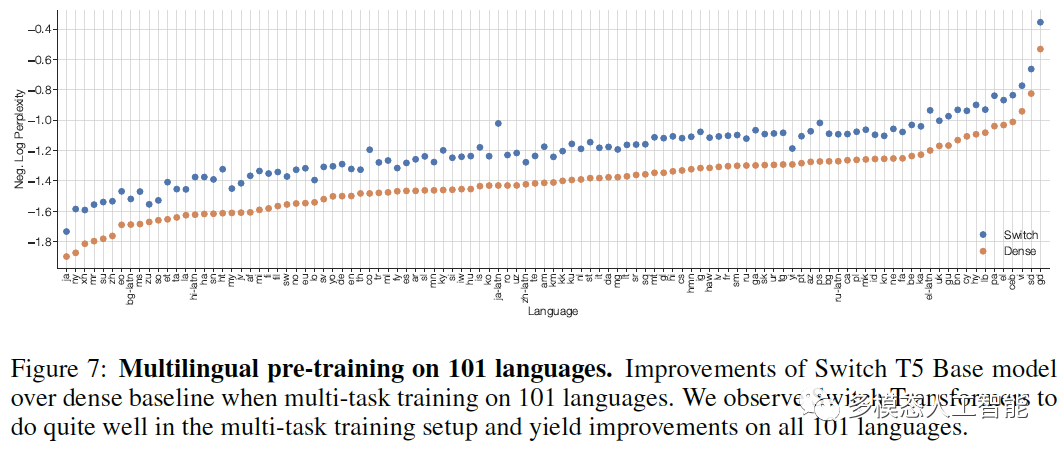
图7. 在101种语言上进行多语言预训练。我们观察到Switch Transformer在多任务训练方面表现很好,并且在所有101种语言上都有提高。
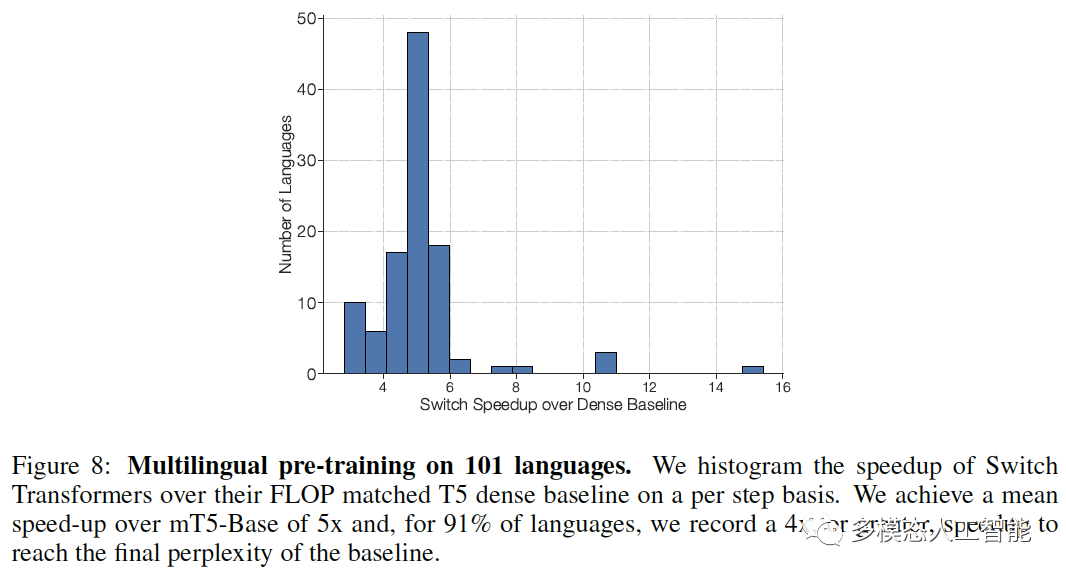
图8. 在101种语言上进行多语言预训练。我们的平均加速比mT5-Base提高了5倍,对于91%的语言,我们记录了4倍或更高的加速。

图9. 数据和权重的划分策略。4×4虚线网格表示16个核心,阴影正方形表示该核心上的模型权重或tokens批量。第一行:模型权重如何跨核心分配。第二行:数据批量如何跨核心分配。
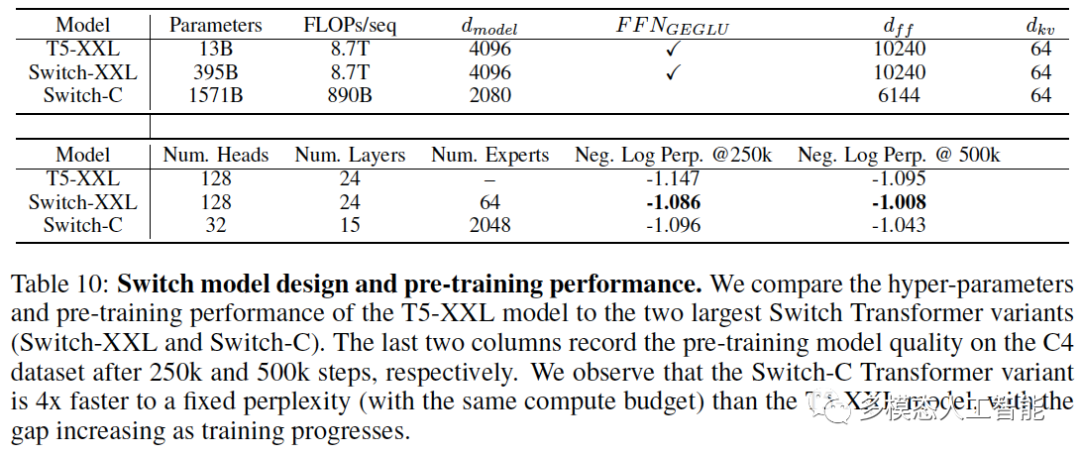
表10. Switch模型的设计和预训练性能。我们观察到Switch-C Transformer变种比T5-XXL模型快4倍(在相同的计算预算下),并且随着训练的进行,差距还在增加。
3. Conclusion / Discussion
Switch Transformers是可扩展的、有效的自然语言学习者。我们简化了MoE,以生成一个易于理解、训练稳定、样本效率大大高于同等大小密集模型的架构。我们发现,这些模型在不同的自然语言任务和不同的训练机制中都表现出色,包括预训练、微调和多任务训练。这些进步使得训练具有数千亿到万亿参数的模型成为可能,并且相对于密集的T5基线模型实现了显著的加速。我们希望我们的工作能够推动稀疏模型成为有效的架构,并鼓励研究人员在自然语言任务中考虑这些灵活的模型。
关注“多模态人工智能”公众号,一起进步!

















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









