





原文:Amit Chaudhary. “Self Supervised Representation Learning in NLP.” https://amitness.com/2020/05/self-supervised-learning-nlp (2020).
近年来,自监督学习在CV领域取得了惊人的进展,但它在NLP领域流行已经有很长一段时间了。自90年代以来,甚至在“自监督学习”被称为“自监督学习”之前,语言模型就已经存在。2013年的Word2Vec论文推广了自监督学习这一范式。NLP领域的许多问题因为自监督方法的出现而取得了快速发展。
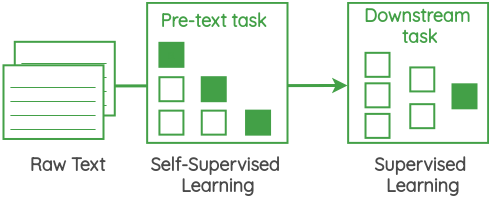
自监督方法的核心是一个被称为“代理任务”的框架,它允许我们使用无标签数据本身来生成标签,而无需进行人工数据标注,然后采用有监督的形式来解决无监督的问题。自监督学习的代理任务旨在从大量无标签数据中学习到有用表示,这些表示可以用于各种下游任务。这里的“代理任务”有时也被称为“辅助任务”或“预训练任务”。本文将重点介绍自监督学习的各种代理任务的主要思想,而不是它们的实现细节。
1 中心词预测(Center Word Prediction)
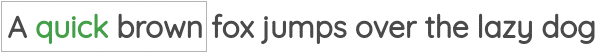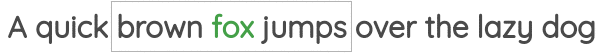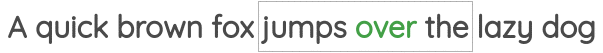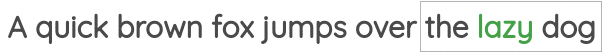

如图所示,我们取一定窗口大小的文本,并根据周围的单词预测中心词。在这里,我们取的窗口大小为1,因此在中心词的两侧各有一个单词。Word2Vec论文中的“连续词袋”用的就是这种方法。
2 邻近词预测(Neighbor Word Prediction)
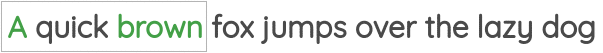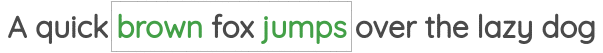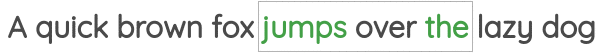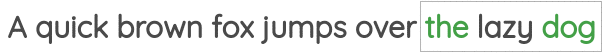
如图所示,我们取一定窗口大小的文本,并根据中心词预测周围的单词。Word2Vec论文中的“Skip Gram”用的就是这种方法。
3 邻近句预测(Neighbor Sentence Prediction)
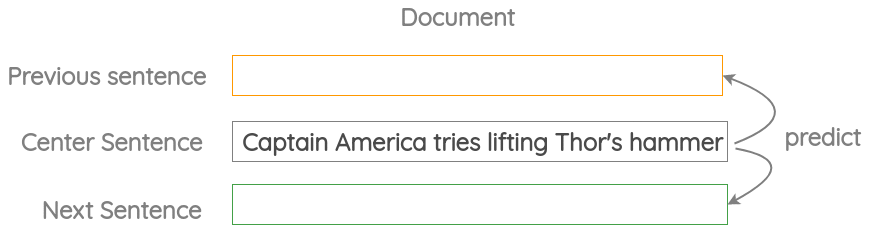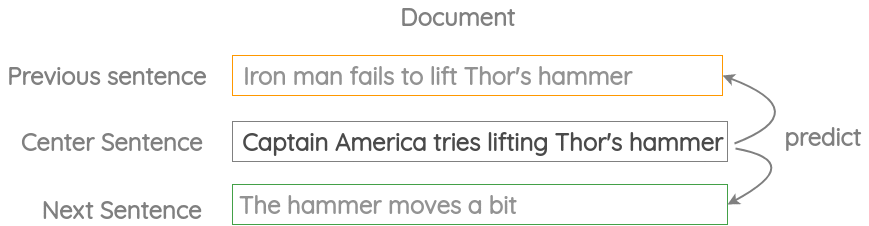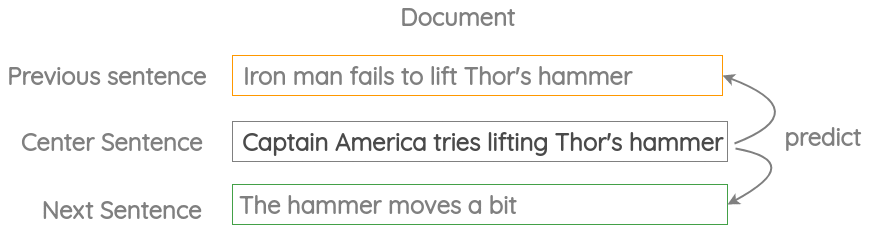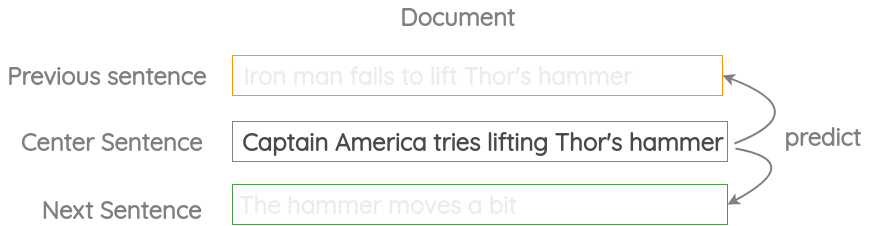
如图所示,我们取三个连续的句子,给定中心句,生成前一个句子和下一个句子,类似于之前的“Skip Gram”方法。Skip-Thought Vectors论文中使用了这个代理任务。
4 自回归语言建模(Auto-regressive Language Modeling)

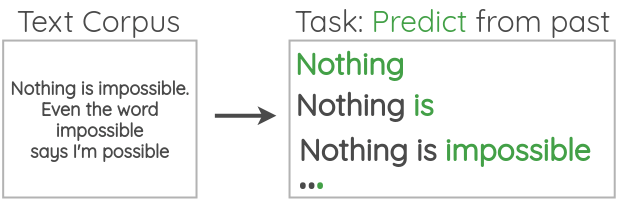

如图所示,我们获取大量无标签的文本语料库,并根据前面的单词来预测下一个单词,方向是从左向右。当然,我们也可以根据后面的单词来预测前面的单词,方向是从右向左。GPT等许多论文都用到了这个代理任务。
5 掩码语言建模(Masked Language Modeling)

如图所示,我们随机掩码掉文本中的部分单词,并设置一个代理任务来预测它们。与自回归语言建模相比,掩码语言建模可以使用掩码单词的上下文进行预测。BERT、RoBERTa和ALBERT等论文都用到了这个代理任务。
6 下一句预测(Next Sentence Prediction)


如图所示,我们从文档中取一个句子,再取它的下一个句子,与其形成一对连续的句子,然后随机抽取一个句子,与其形成另一对不连续的句子,最后针对这两对句子是否连续进行分类。BERT使用这个代理任务来提高下游任务的性能,这些下游任务需要理解句子的关系,比如自然语言推理和问答。然而,后来的研究对其有效性提出了质疑。
7 句子顺序预测(Sentence Order Prediction)


如图所示,我们从文档中取一对连续的句子,然后调换这两个句子的顺序形成另一对不连续的句子,最后针对这两对句子的顺序是否正确进行分类。在ALBERT论文中,它被用来代替“下一句预测”任务。
8 句子排列(Sentence Permutation)
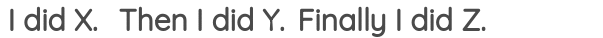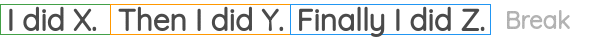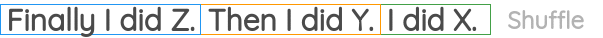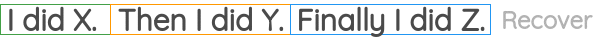
如图所示,我们从语料库中选取一段连续的文本,随机打乱句子的顺序,然后设置一个代理任务,目标是恢复句子的原始顺序。BART论文将该任务用作预训练任务之一。
9 句子顺序调换(Document Rotation)

如图所示,我们随机选择文档中的一个单词作为旋转点,接着旋转文档,使这个单词成为起始词,然后设置一个代理任务,目标是从这个旋转的版本中恢复原来的文档。直觉上,这个代理任务将训练模型识别文档的开头。在BART论文中,它被用作预训练任务之一。
10 表情符号预测(Emoji Prediction)
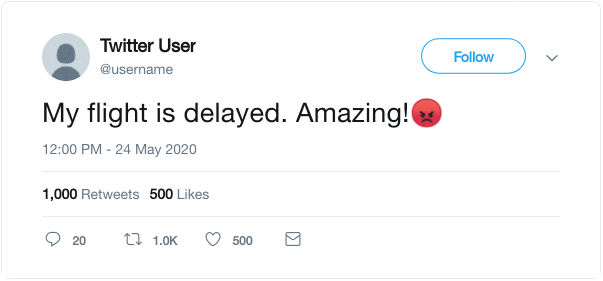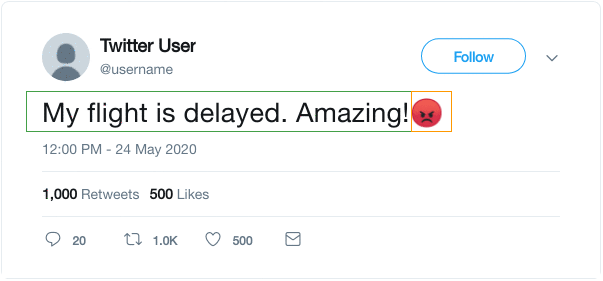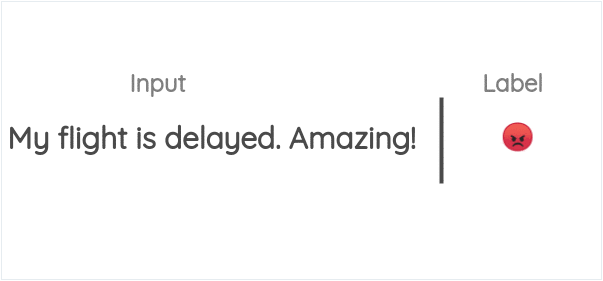
如图所示,我们使用推文中的表情符号作为标签,并制定一个有监督的任务,针对给定的文本预测表情符号。DeepMoji利用这个代理任务,在12亿条推文上对模型进行了预训练,然后在情感分析、仇恨言论检测和侮辱检测等与情感相关的下游任务中对其进行了微调。
11 间隔句生成(Gap Sentence Generation)
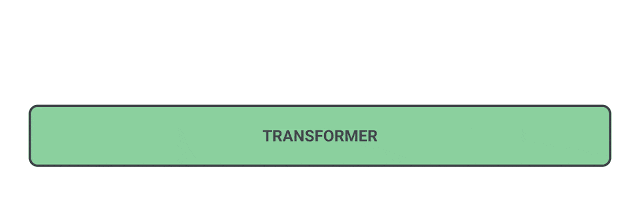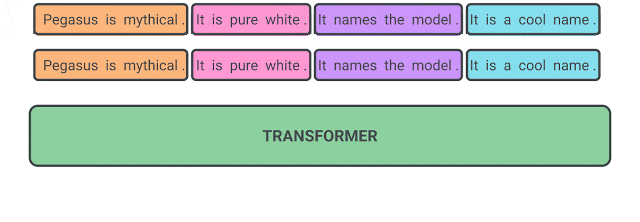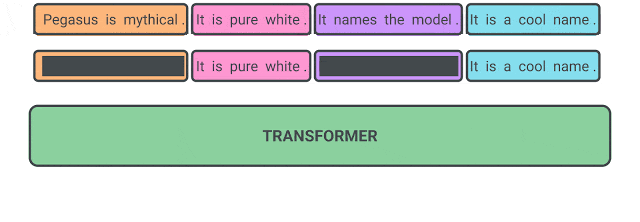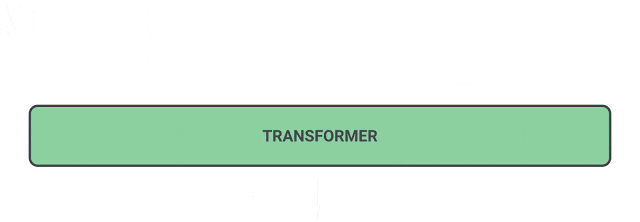
如图所示,间隔句生成任务是在PEGASUS论文中提出的,旨在提高下游任务的摘要总结性能, 其主要思想是,获取一个文档并掩盖重要的句子,然后训练模型生成缺失的句子。
12 参考文献
1. Ryan Kiros, et al. “Skip-Thought Vectors”
2. Tomas Mikolov, et al. “Efficient Estimation of Word Representations in Vector Space”
3. Alec Radford, et al. “Improving Language Understanding by Generative Pre-Training”
4. Jacob Devlin, et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”
5. Yinhan Liu, et al. “RoBERTa: A Robustly Optimized BERT Pretraining Approach”
6. Zhenzhong Lan, et al. “ALBERT: A Lite BERT for Self-supervised Learning of Language Representations”
7. Mike Lewis, et al. “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension”
8. Bjarke Felbo, et al. “Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm”
多模态人工智能
为人类文明进步而努力奋斗^_^↑
50篇原创内容
欢迎关注“多模态人工智能”公众号,一起进步^_^↑















 3016
3016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









