







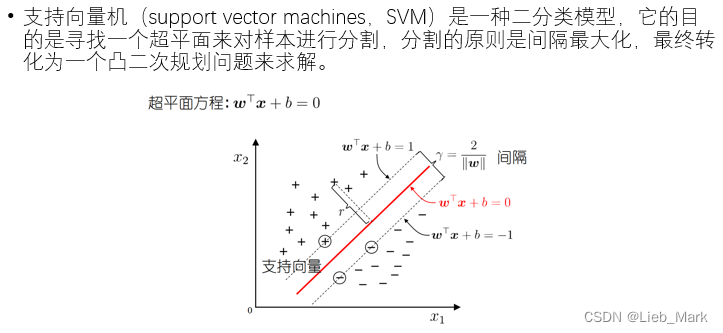
- 实验目的
1、了解SMO求解SVM的过程,调研简化版SMO算法的python实现
2、通过编程得到所给数据对应的SVM分割平面
3、将数据以及所得线性方程结果进行可视化
- 实验内容:
在《统计学习方法》中找到的smo算法的流程

下面是具体代码步骤:
1、首先要把数据集里的数据进行处理,使用np.loadtxt()把数据读入ndarray,把前两列和最后一列的标签分开,分别存储到data和lables中,并返回。
2、功能函数,som过程中选择第二个alpha,即alpha[j],因为是简化版的,不需要使用启发式优化,只需要随机选择一个和i不同的j即可。
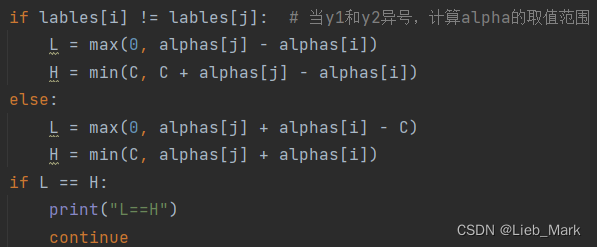
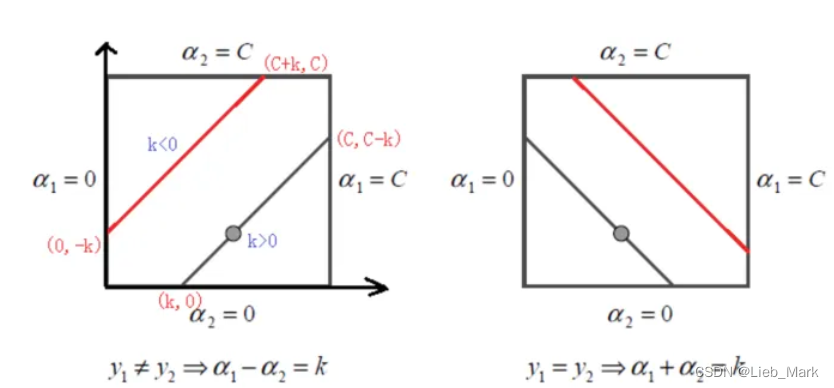
3、通过导数为0,有的限制条件,且![]() ,可以根据y1是否等于y2进行分情况讨论,得出二者的限制范围,当超出的时候要进行调整。
,可以根据y1是否等于y2进行分情况讨论,得出二者的限制范围,当超出的时候要进行调整。
当y1 != y2时
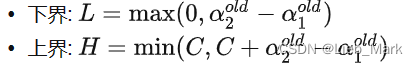
当y1 == y2时
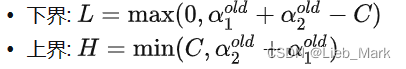
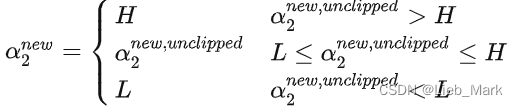
4、下面是最主要的smo函数,分开解释
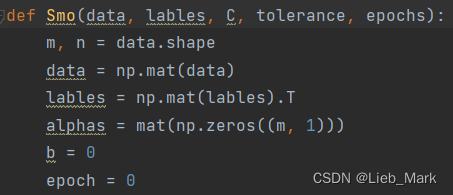
(1)首先是传参和初始化,传入的是特征值data,标签lables,惩罚常数C,容错率tolerance,取消前最大的循环次数epochs。将data,lables转为mat类型,方便后面矩阵运算。声明alphas和b,并置为0。
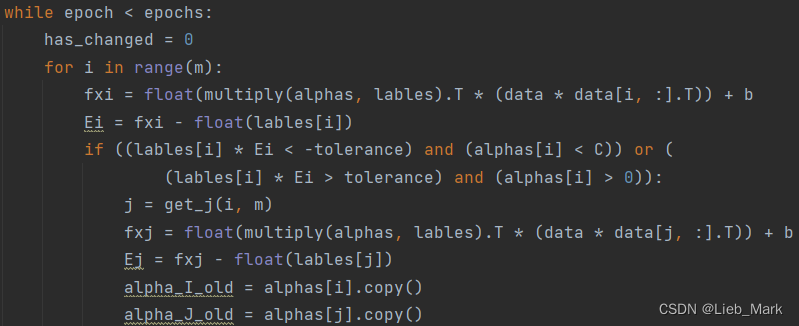
(2)函数是两层循环,最外层决定循环次数,第二层是遍历数据集中的每一个数据,再随机选取j,二者结合进行优化。
首先是根据SVM对数据点的预测值公式:![]() 计算出i点的预测值,并且和标签求差得到Ei。对后面选中的j进行同样的操作。
计算出i点的预测值,并且和标签求差得到Ei。对后面选中的j进行同样的操作。
接着是一个判定条件,如果不满足KKT条件,则需要优化,否则跳过,这里当时写的时候看了好久没看明白,在网上搜索到了资料,所以通过两种如果分类正确就一定不会出现的条件,就可以得到这个判断。

(3)这一步得到eta,-eta是二阶导数,通过数学知识得出,如果eta>=0,即二阶导<=0,没有极小值,无法优化,跳过。后面的a1new,a2new的计算同样要用到eta。

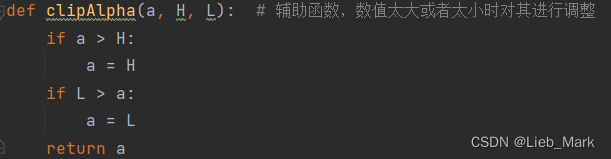
(4)这一步在clipAlpha函数那里解释了,根据多个限制条件,分情况讨论得出alpha的上下界
(5)使用推导出的公式![]() ,对alphas[j]进行优化,如果改动很小,则跳过。使用
,对alphas[j]进行优化,如果改动很小,则跳过。使用![]() 对alphas[i]进行更新。
对alphas[i]进行更新。

(6)使用公式![]() 和
和
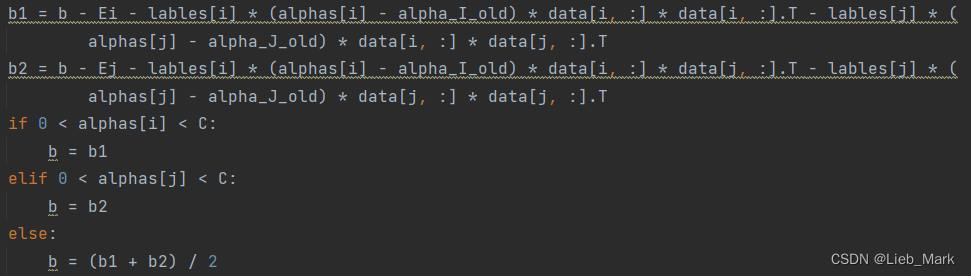
![]() 分别解出b1和b2,如果两个都是有效的,那么b1,b2的值是相等的。当两个乘子a1,a2都在边界上,且L != H时,b1,b2之间的值就是和KKT条件一直的阈值。SMO选择他们的中点作为新的阈值:即求均值。
分别解出b1和b2,如果两个都是有效的,那么b1,b2的值是相等的。当两个乘子a1,a2都在边界上,且L != H时,b1,b2之间的值就是和KKT条件一直的阈值。SMO选择他们的中点作为新的阈值:即求均值。
(7)只有100个alpha的误差都在范围之内,即都不再更新了,才能进入下一个递归,不然只能在100个alpha再次循环优化。最后返回alphas和b
5、由alphas和原数据得出w的值,为每个ai*yi*xi的和

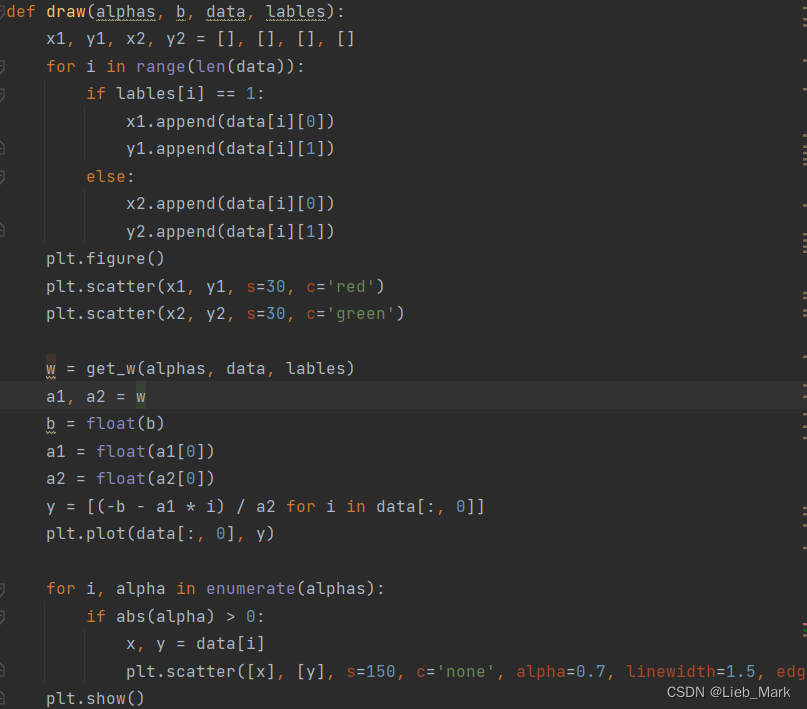
6、draw函数将得到的结果可视化。先将点根据标签分别加入两个列表中,然后使用scatter画出。之后画出SVM分割平面,调用get_w求出w,然后根据wT*x+b求出对应y值,使用plt.plot画出分割直线。最后圈出支持向量,根据支持向量满足0 < a < c,找出这样的点,使用scatter画出一个圆圈。
- 实验原理:










- 心得体会:
实验中遇到的问题及解决:
- 这章的内容相比前几章难度提升很多,且西瓜书上关于smo算法的内容很少,花费很多时间在b站、知乎等网站上学习相关内容。
- 实验中需要用到大量矩阵运算和连加求和等,非常容易出现矩阵维度不匹配等情况。通过输出矩阵shape或者在调试器中查看矩阵维度,看是否需要调换运算顺序或者进行转置。
- 对于KKT条件的应用掌握不够,如在下面这个判定:如果不满足KKT条件就进行更新,否则跳过。看了好久没看明白。包括如何根据alpha的值判断点的位置等问题。

在网上找到相应的解释



- 对超参数的选择不太清楚,根据网上的信息和自己试验,C选择60,tolerance选择0.01效果不错。
- Eta是二阶导数,可以确定是否有极值,数学这部分也有些遗忘,查阅得知,二阶导 < 0有极大值,> 0有极小值,= 0没有极值,可以根据这个进行剪枝,减少计算量。
心得体会:
这次实验是做的时间最长的一次,但是收获很多。在做实验的过程中对SVM的原理及推导进行了复习,弄清了SVM的原理、优点及解决的问题、对偶问题、KKT条件、核函数等内容。
同时也学习到了SMO算法的数学推导和具体流程,其中坐标上升每次通过更新多元函数中的一维,经过多次迭代直到收敛来达到优化函数的目的,每次只是做一维优化,所以每个循环中的优化过程的效率是很高的, 但是迭代的次数会比较多。每次只更新一对变量而固定其他变量。这种方法与之前的反向传播根据梯度更新的算法很不一样,学习到了这种新的思想。
除此以外,我还了解了非简化版的smo,选择第2个变量的过程为内层循环。假设在外层循环中已经找到第1个变量,现在要在内层循环中找第2个变量,第2个变量选择的标准是希望能使有足够大的变化,这样更新效率最高。虽然没有使用程序实现,但是学习到了这个方法和思想是十分有意义的。
通过代码实现SMO,在实践中对于知识进行了进一步的巩固,并且通过matplotlib进行可视化。巩固了所学知识,为以后的学习打下坚实的基础。
import numpy as np
from numpy import *
import matplotlib.pyplot as plt
def get_data(path):
dataset = np.loadtxt(path)
data = dataset[:, :2]
lables = dataset[:, -1]
return data, lables
def get_j(i, m):
j = int(random.uniform(0, m))
while (i == j):
j = int(random.uniform(0, m))
return j
def clipAlpha(a, H, L): # 辅助函数,数值太大或者太小时对其进行调整
if a > H:
a = H
if L > a:
a = L
return a
def Smo(data, lables, C, tolerance, epochs):
m, n = data.shape
data = np.mat(data)
lables = np.mat(lables).T
alphas = mat(np.zeros((m, 1)))
b = 0
epoch = 0
while epoch < epochs:
has_changed = 0
for i in range(m):
fxi = float(multiply(alphas, lables).T * (data * data[i, :].T)) + b
Ei = fxi - float(lables[i])
if ((lables[i] * Ei < -tolerance) and (alphas[i] < C)) or (
(lables[i] * Ei > tolerance) and (alphas[i] > 0)):
j = get_j(i, m)
fxj = float(multiply(alphas, lables).T * (data * data[j, :].T)) + b
Ej = fxj - float(lables[j])
alpha_I_old = alphas[i].copy()
alpha_J_old = alphas[j].copy()
K_ii, K_jj, K_ij = data[i, :] * data[i, :].T, data[j, :] * data[j, :].T, data[i, :] * data[j, :].T
eta = 2 * K_ij - K_ii - K_jj
if eta >= 0: # 二阶导
print("eta >= 0")
continue
if lables[i] != lables[j]: # 当y1和y2异号,计算alpha的取值范围
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
print("L==H")
continue
alphas[j] -= lables[j] * (Ei - Ej) / eta # 利用公式更新alpha[j]
alphas[j] = clipAlpha(alphas[j], H, L)
if (abs(alphas[j] - alpha_J_old) < 0.00001):
print("The change in j is not significant")
continue
alphas[i] += lables[j] * lables[i] * (alpha_J_old - alphas[j]) # 利用公式更新alphas[i]
b1 = b - Ei - lables[i] * (alphas[i] - alpha_I_old) * data[i, :] * data[i, :].T - lables[j] * (
alphas[j] - alpha_J_old) * data[i, :] * data[j, :].T
b2 = b - Ej - lables[i] * (alphas[i] - alpha_I_old) * data[i, :] * data[j, :].T - lables[j] * (
alphas[j] - alpha_J_old) * data[j, :] * data[j, :].T
if 0 < alphas[i] < C:
b = b1
elif 0 < alphas[j] < C:
b = b2
else:
b = (b1 + b2) / 2
has_changed += 1
print('iteration:{} i:{} num:{}'.format(epoch, i, has_changed))
if has_changed == 0:
epoch += 1
else:
epoch = 0
print('iteration number: {}'.format(epoch))
# print(alphas, b)
return alphas, b
def get_w(alphas, dataset, labels):
alphas, dataset, labels = np.array(alphas), np.array(dataset), np.array(labels)
yx = labels.reshape(1, -1).T * np.array([1, 1]) * dataset
w = np.dot(yx.T, alphas)
return w.tolist()
def draw(alphas, b, data, lables):
x1, y1, x2, y2 = [], [], [], []
for i in range(len(data)):
if lables[i] == 1:
x1.append(data[i][0])
y1.append(data[i][1])
else:
x2.append(data[i][0])
y2.append(data[i][1])
plt.figure()
plt.scatter(x1, y1, s=30, c='red')
plt.scatter(x2, y2, s=30, c='green')
w = get_w(alphas, data, lables)
a1, a2 = w
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y = [(-b - a1 * i) / a2 for i in data[:, 0]]
plt.plot(data[:, 0], y)
for i, alpha in enumerate(alphas):
if abs(alpha) > 0:
x, y = data[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolor='red')
plt.show()
if '__main__' == __name__:
data, lables = get_data(r"D:\pythonProject\Machine_learning\test5\dataset.txt")
# print(data, lables)
alphas, b = Smo(data, lables, 0.6, 0.001, 40)
# print(alphas.shape)
draw(alphas, b, data, lables)
















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









