







1. 论文信息
-
论文标题: Implicit Diffusion Models for Continuous Super-Resolution
-
作者/团队: Sicheng Gao, Xuhui Liu, Bohan Zeng, Sheng Xu, Yanjing Li, Xiaoyan Luo…
-
发表会议/期刊: CVPR-2023
2. 代码来源
-
官方代码库: GitHub - Ree1s/IDM
3. 环境与配置
-
操作系统:Linux服务器 - Ubnutu 20.04.4(系统架构 x86_64)
-
第三方软件:XShell / Xftp(上传文件到服务器,可从XShell进入)
-
Python版本:Python 3.7.10
-
深度学习框架:PyTorch 1.12.0 + CUDA 11.3
-
CUDA/cuDNN版本:CUDA 11.3 / cuDNN 8.9.7.29
-
GCC版本:7.5.0(来源:Ubuntu 7.5.0-6ubuntu2)
-
服务器硬件配置:
- RAM:62GB
- 磁盘总容量:
- 系统盘:7.3TB (已用 1.4TB,可用 5.5TB)
- 数据盘:7.3TB (已用 3.9TB,可用 3.1TB)
- GPU:
- 型号: NVIDIA GeForce GTX 1080 Ti
- 数量: 3 块
- 每块显存: 11GB
- 驱动版本: 550.67
- 算力:6.1
4. 复现步骤
4.1 准备代码
4.1.1 下载源代码
方法一:下载到本地,再上传服务器
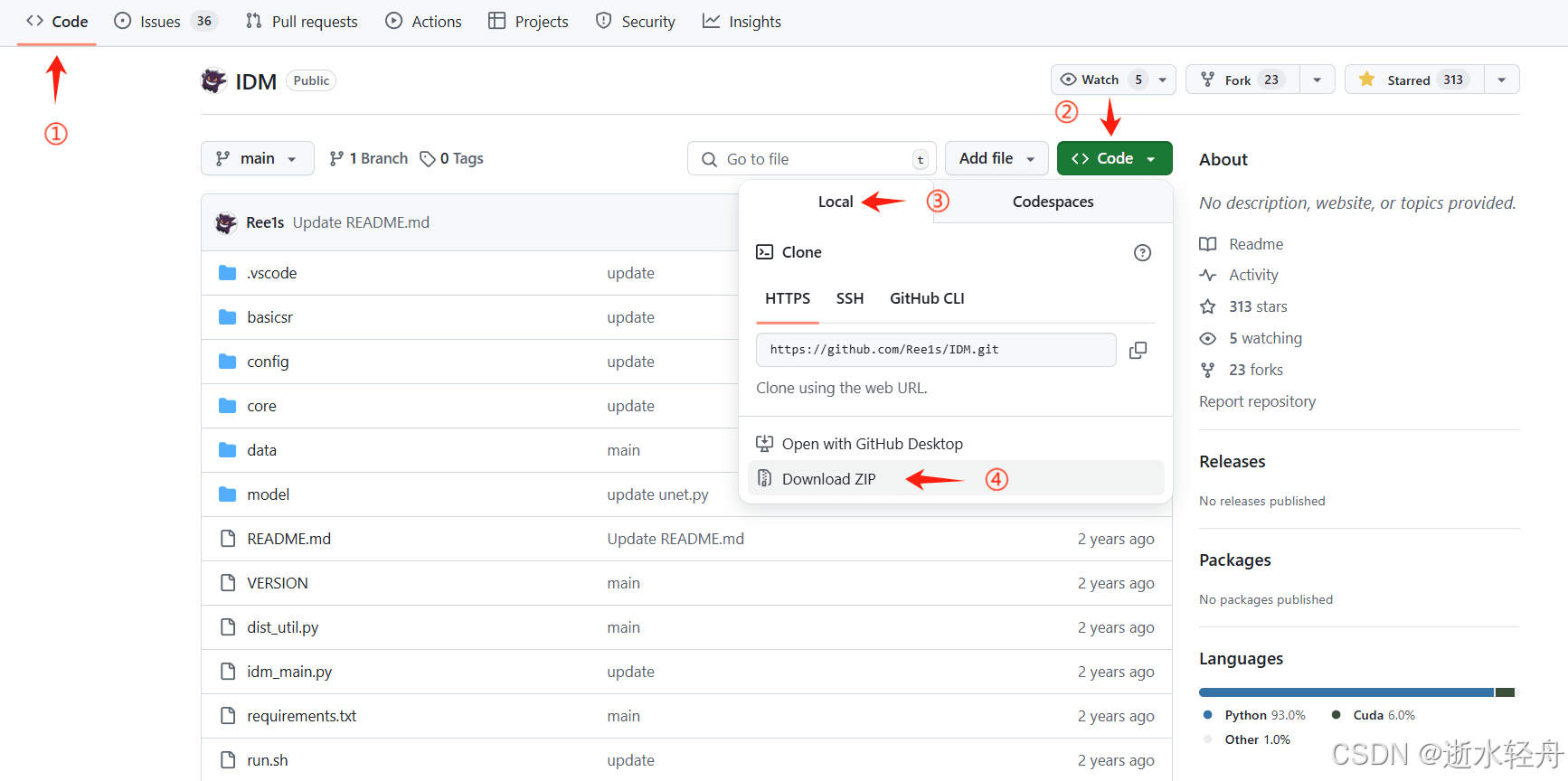
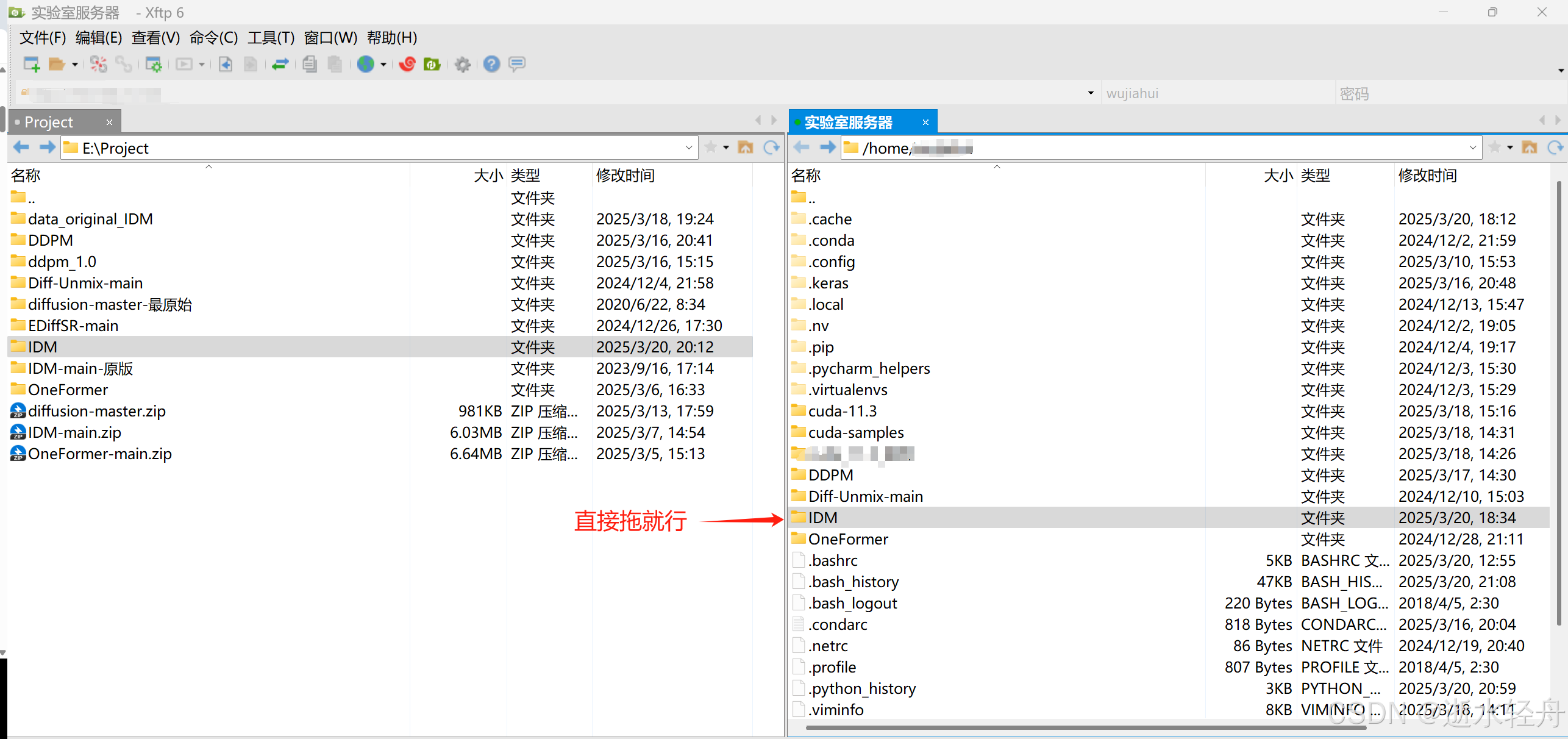
方法二:直接克隆到服务器
git clone https://github.com/Ree1s/IDM.git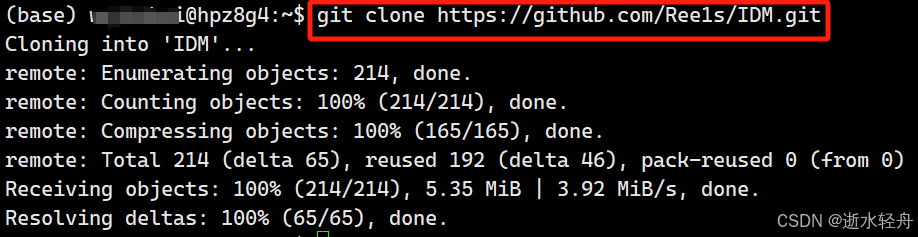
# 切到项目目录下
cd IDM4.1.2 代码调整
4.1.2.1 config\df2k_liifsr3_x4.json
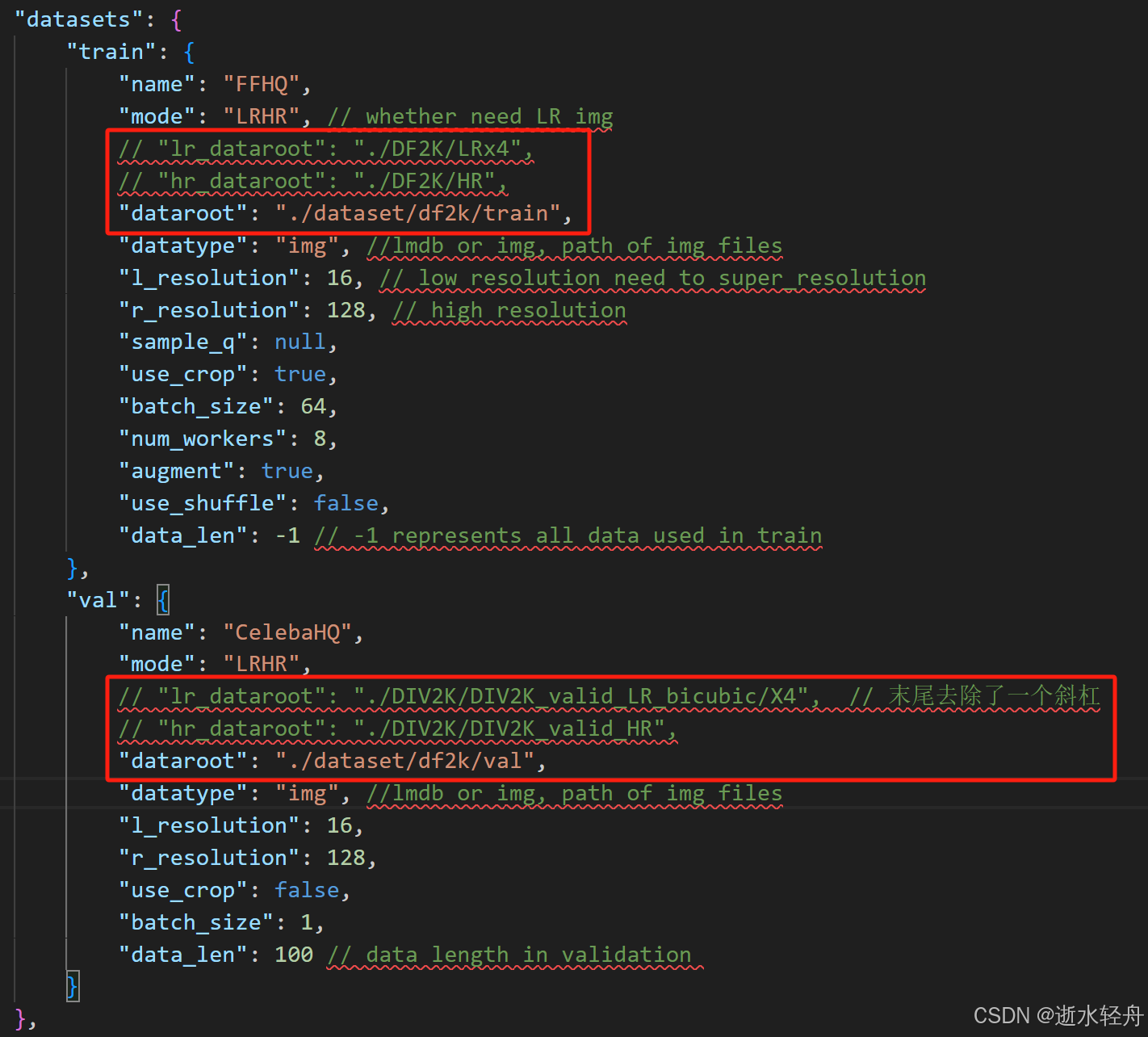
我是出于以下两个原因改的:
1)原来的数据存放目录太复杂了;
2)到后面运行时抛出异常 dataroot 的值为 None,经检查发现传递的参数 dataset_opt 包含 lr_dataroot 与 hr_dataroot,但没有 dataroot,因为df2k_liifsr3_x4.json文件里没有定义 dataroot,而 config\ffhq_liifsr3_scaler_16_128.json 与 config\cat_liifsr3_x16.json 文件里都有 dataroot。
但是我还没具体研究过后面的模型训练时如何使用这些数据的,所以我并不确定是否对训练与评估结果没有丝毫影响。
4.1.2.2 run.sh
run.sh 文件内容以及需要注意更改的参数如下:
# 需要更改的参数:
# · GPU数量: CUDA_VISIBLE_DEVICES、--nproc_per_node(注意自己可用的GPU数量)
# · 配置文件(-c): ?.json(注意对应数据集)
# · 恢复训练(-r): checkpoints/df2k?(注意对应数据集)
# 原指令更改:python -m torch.distributed.launch ——> torchrun
# train
CUDA_VISIBLE_DEVICES=0,1,2 torchrun --nproc_per_node=3 --master_port=12392 idm_main.py -p train -c config/df2k_liifsr3_x4.json -r checkpoints/df2k
# val
CUDA_VISIBLE_DEVICES=0 torchrun --nproc_per_node=1 --master_port=12392 idm_main.py -p val -c config/df2k_liifsr3_x4.json -r checkpoints/df2k我是拆成 run_df2k.sh 与 run_ffhq.sh 或对应其他数据集的.sh文件,仅仅是为了方便直接运行,不用再频繁修改而已。
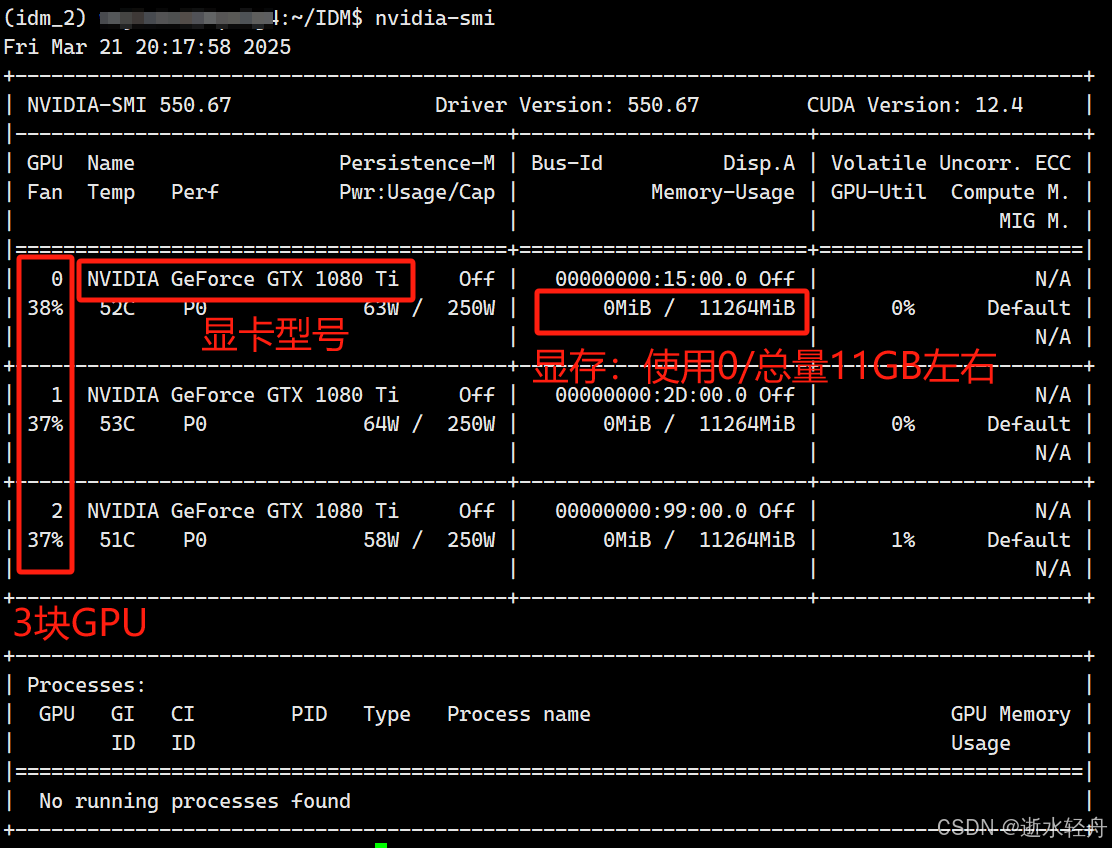
注:可以使用 nvidia-smi 查看 GPU 块数以及显存大小。
4.1.2.3 data\prepare_data.py
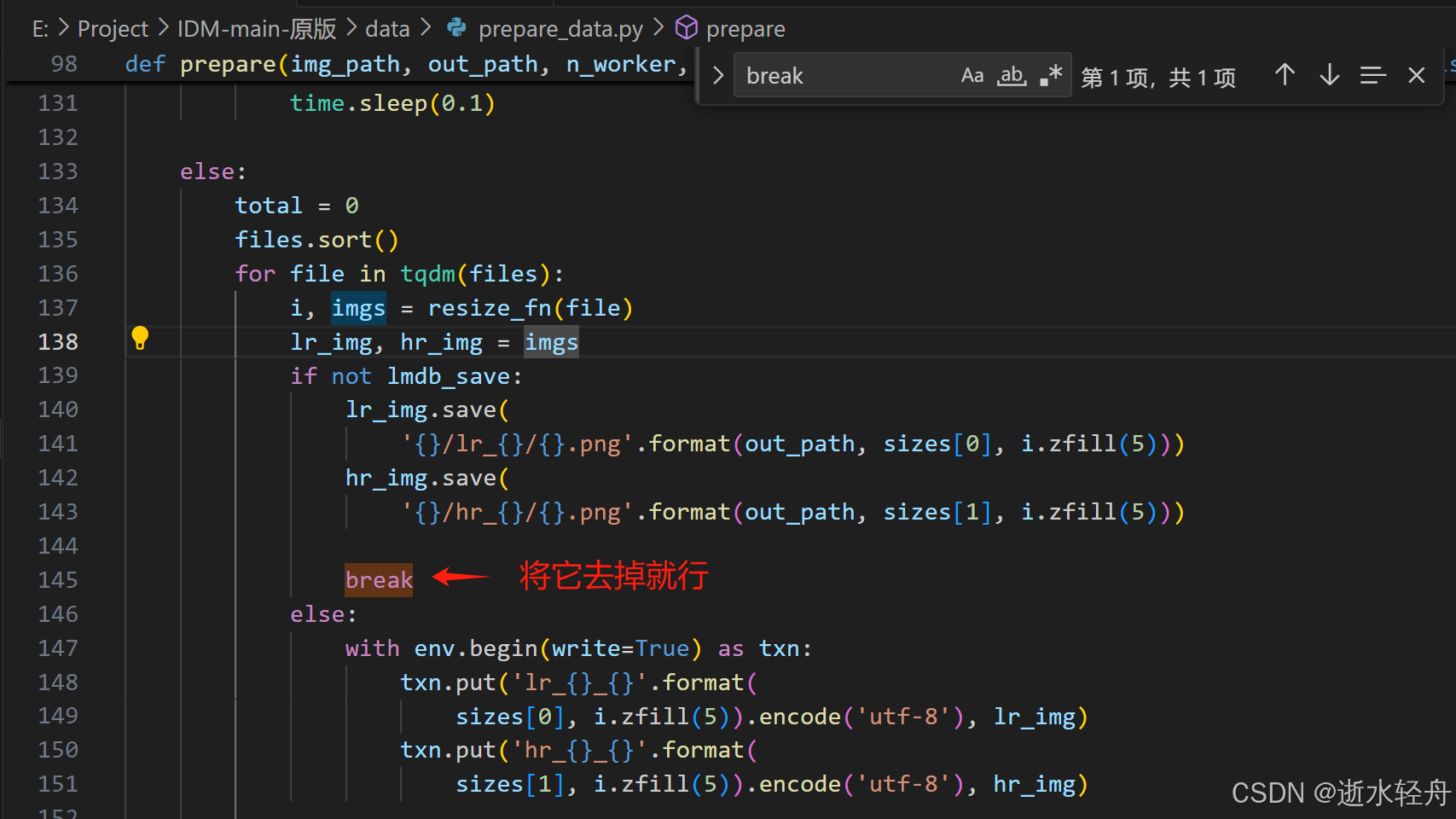
(1)解决 break 问题
如下图所示,去掉 break 就行。
(2)磁盘空间不足时(可选)
原 prepare_data.py 文件中有句代码如下:
env = lmdb.open(out_path, map_size=1024 ** 4, readahead=False)其中 map_size 指定了需要预留 1TB 的存储空间,所以要注意自己的空间够不够,不够的话,这里可以改大小,比如改成 1024 ** 3 * 512(512GB),但具体的运行结果我不太清楚,我只试过可以生成指定大小的.mdb文件。
再看代码,这个应该只是生成 .mdb 文件时需要那么大的空间,我后来在服务器上不以 .mdb 文件保存时,处理后的图片总共也就几百 MB 而已。
4.1.2.4 basicsr\ops\fused act\fused act.py 与 model\ops\fused_act\fused_act.py
这两文件是一样的。
将 BASICSR_JIT = os.getenv('BASICSR_JIT') 之前将 BASICSR_JIT 设为True,否则会影响后面 CUDA 拓展的重编译。具体修改如下:
import os
import torch
from torch import nn
from torch.autograd import Function
os.environ['BASICSR_JIT'] = 'True' # 在 BASICSR_JIT 取值之前,先设为True
BASICSR_JIT = os.getenv('BASICSR_JIT')
if BASICSR_JIT == 'True':
...4.2 配置环境
4.2.1 准备 CUDA
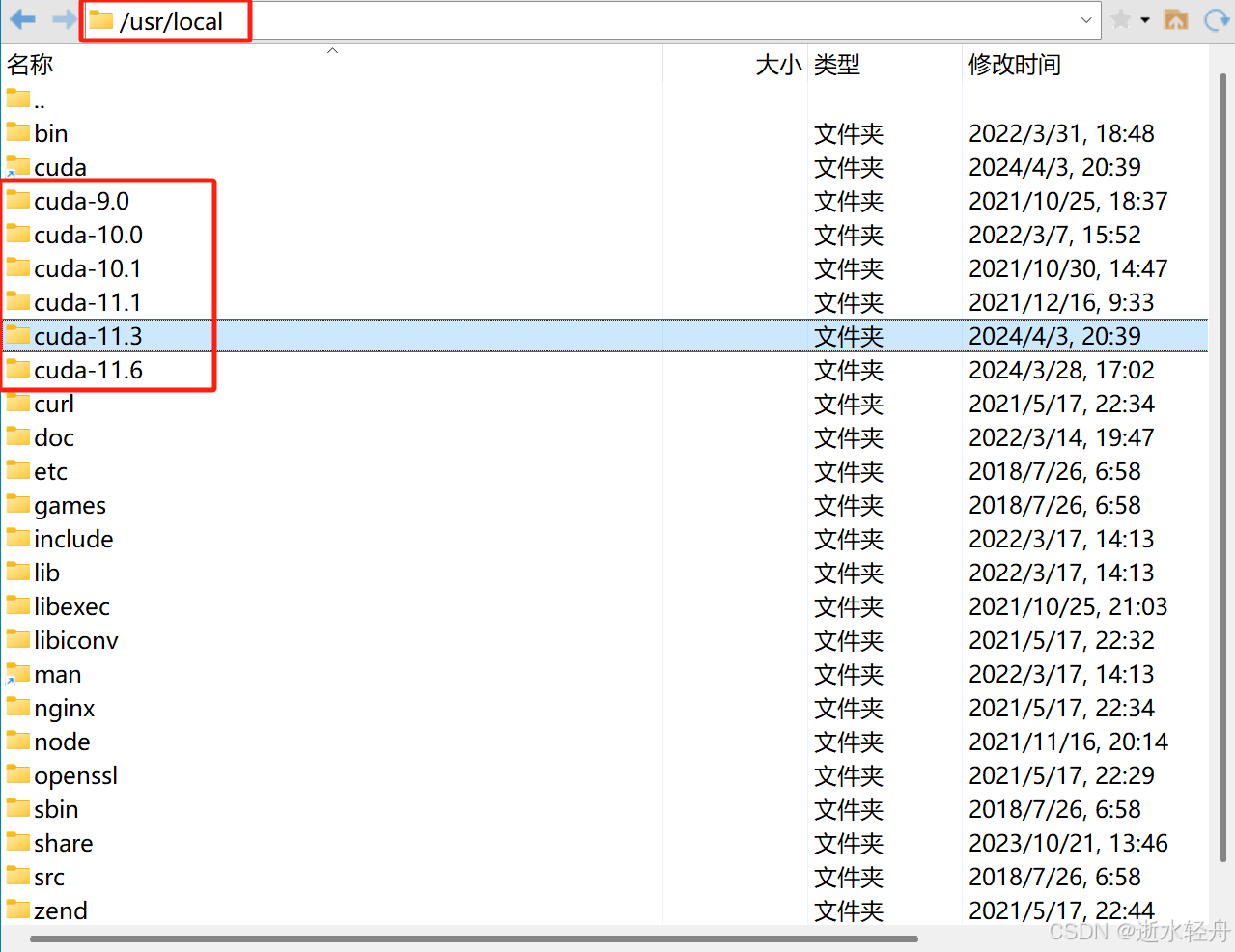
(1)检查有没有 CUDA 或者 CUDA 版本符不符合要求
方法一:使用命令查询,nvcc --version 或者 nvcc -V
方法二:查看目录
(2)安装 CUDA
没有 CUDA 的或者 CUDA 版本不符合要求,可以根据这篇文章进行安装。我是安装在自己的用户目录下,避免与 root 环境冲突,也不受 root 权限的限制。此外,我只安装了 CUDA Toolkit,并没有安装 CUDA Samples。
(3)添加 CUDA 的环境变量
在用户目录下的 .bashrc 文件开头添加以下内容(Xftp 软件中可以通过右键之后使用记事本编辑):
# 添加 CUDA 11.3 的环境变量
export PATH=/home/(用户名)/cuda-11.3/bin:$PATH
export LD_LIBRARY_PATH=/home/(用户名)/cuda-11.3/lib64:$LD_LIBRARY_PATH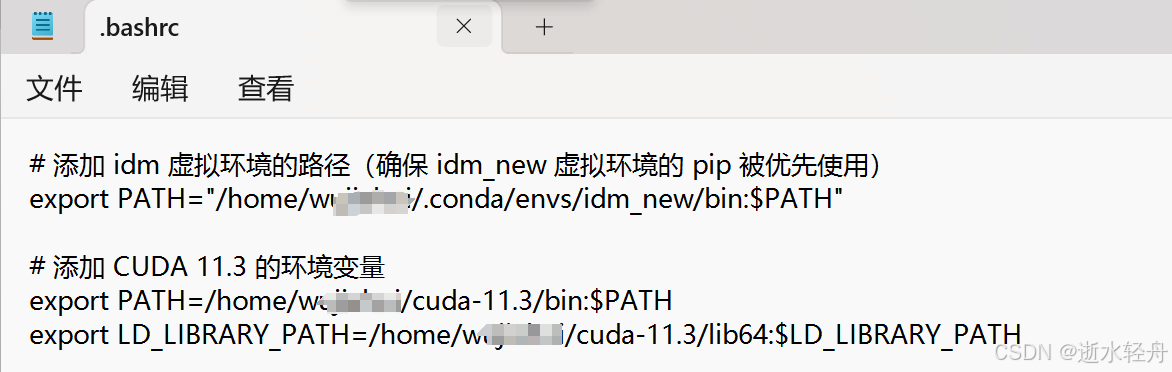
注:
(1).bashrc 文件可以设置使用指定的 CUDA,从而实现在有多个 CUDA 时灵活切换使用的 CUDA;此外,也可以设置优先使用的pip路径等。
(2)使用 which nvcc 与 which pip 可以查看自己当前使用的是哪里的 CUDA 与 pip 等。
(3)如果设置使用自己用户目录下的 pip 也有可能解决 pip install 没有权限的问题。
(4)要注意,更改 .bashrc 文件之后,记得 source ~/.bashrc 激活 .bashrc 文件,并重新进入虚拟环境。
这些点其实很容易忘记,我就犯过这种错误,比如 source ~/.bashrc 之后,其实自动跳回了 base 环境,但是我没注意到,结果一直报错,我还各种咨询 AI,搞了半天才发现自己没有进入自己的虚拟环境。还有像忘记切到项目目录下,但巧的是当前目录下有一样的文件(requirements.txt),所以也不报找不到的错误,我也是搞了很久才发现自己这个愚蠢的错误。
4.2.2 创建虚拟环境
conda create -n idm python=3.7.10 # 创建名为idm、python版本为3.7.10的虚拟环境
conda activate idm # 进入虚拟环境4.2.3 安装PyTorch
(1)安装指令
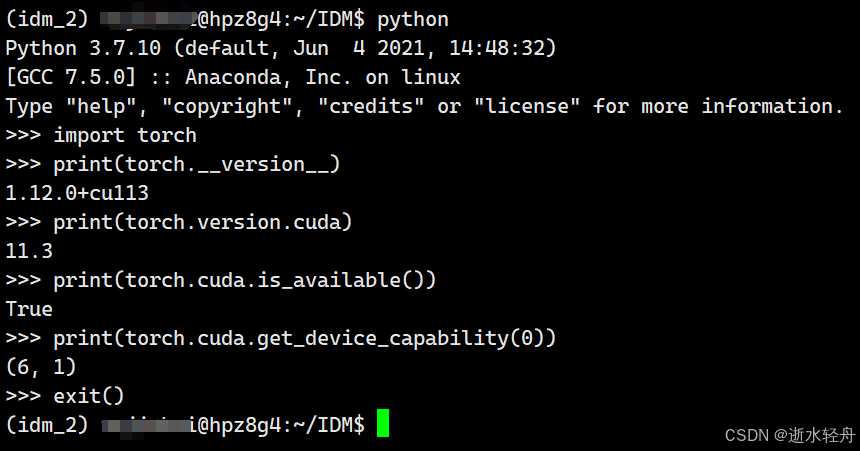
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 -f https://download.pytorch.org/whl/torch_stable.html(2)检查 PyTorch 与 CUDA 版本:保证安装的 PyTorch 版本和 CUDA 版本是兼容的,且能正常使用。
输入‘python’命令,进入 Python 交互式环境:

再输入以下内容:
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.cuda.is_available())
print(torch.cuda.get_device_capability(0)) # 第一块 GPU 算力注:我最开始只关注前三个输出正常,但后来发现无法输出 GPU 算力,才知道我以为的正常其实并不能正常使用,所以还是全都试一下比较保险。
4.2.4 安装第三方库
(1)安装指令如下:
pip install -r requirements.txt
python setup.py develop # 会重编译 CUDA 拓展 (2)确保 CUDA 扩展(如 fused_act_ext 和 upfirdn2d_ext)已正确加载。
先输入‘python’命令,进入 Python 交互式环境,再输入以下内容:
from basicsr.ops.fused_act import fused_act_ext
print(fused_act_ext)
from model.ops.fused_act import fused_act_ext
print(fused_act_ext)4.3 数据与检查点准备
-
数据集下载: DIV2K Dataset

注:我目前只用过高分辨率的DIV2K,其他的可以从官方代码仓库获取下载链接。四种数据集我都尝试下载过,但我只下载成功了DIV2K和CelebaHQ,Flick2K下载不了,FFHQ能下载程序文件,但是用程序下载代码时出错,也是下载不了。
-
数据处理:
# 调整大小获取高分辨率和低分辨率的图片 python data/prepare_data.py --path [dataset root] --out [output root] --size 16,128
【说明】
(1)[dataset root]:替换成刚刚下载解压的原数据的路径。
(2)[output root]:替换成要将处理好的图片输出的位置。
(3)我将官方给的指令的末尾的-l去掉了,-l表示将处理后的数据集中以.mdb文件的形式存储,而我在后面训练模型时出现抛出异常,说是需要.jpg或.png格式的图片。
例如:
python data/prepare_data.py --path /home/(用户名)/IDM/dataset/df2k/train/DIV2K_train_HR --out /home/(用户名)/IDM/dataset/df2k/train/hr --size 16,128-
检查点下载:checkpoint
4.4 项目结构(数据与检查点的存放位置)
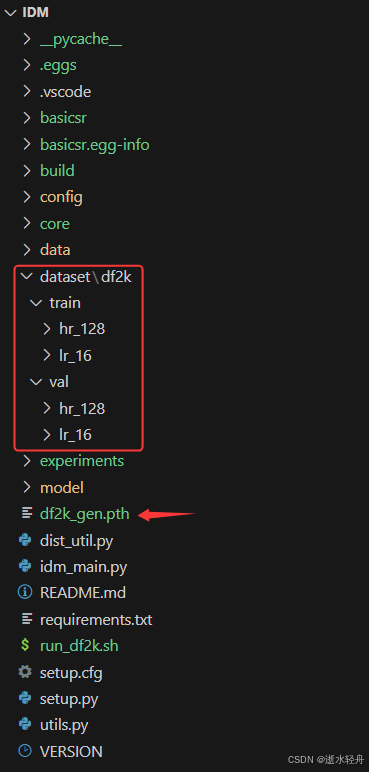
注:主要是 dataset 文件夹和检查点 .pth 文件的存放位置,其他非原本就有的文件都是在代码运行过程中产生的,不需要自己手动建。
4.5 模型训练与评估
(1)执行如下指令:
sh run.sh
# 我是:
sh run_df2k.sh注:我在本地跑时,这句指令无法执行,这个时候可以直接将.sh文件里的指令直接复制出来一句一句地执行。
(2)项目开始跑起来:(终于开始动了,记录这一伟大时刻!) ꉂ(ˊᗜˋ*)
(3)运行结果:

5. 踩过的坑
我最开始是在本地部署的。
5.1 数据集无法下载
(1)Flick2K数据集无法下载。
(2)FFHQ数据下载问题:运行“python download_ffhq.py --json --images” ,无法连接主机,尝试断开代理、启用代理并修改端口都不行。
5.2 磁盘空间不足

错误结果还有乱码,但豆包仍然给出了分析,说是在使用 LMDB(Lightning Memory-Mapped Database)数据库时,指定的路径 E:/Project/IDM/data/DIV2K_train_HR/outputs_16_128 所在的磁盘空间不足,无法满足 LMDB 操作的需求。

我怕把空间改小之后会不够用,于是转去了服务器上复现,但是在服务器上实在没有进展之后我又回到本地了,按照豆包给出的建议改成了512G(修改方法在4.4.2.3),然后正常运行了一半,遇到的问题如下。
5.3 对数据处理后的输出文件夹没有写入权限
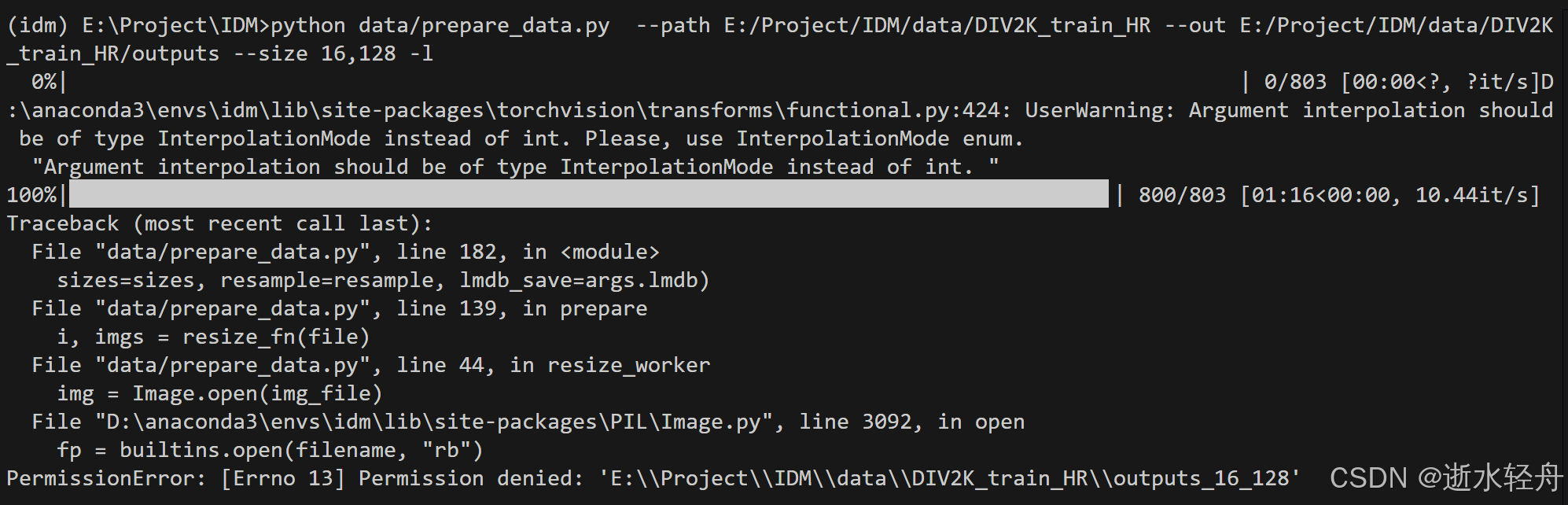
错误提示表示是对 outputs_16_128 文件夹没有写入权限,导致无法正常执行数据存储或文件操作。我想是因为这个文件夹是上次运行失败的输出文件,在创建时被限定了权限,所以我将原本的 outputs_16_128 文件夹删除了,然后重新执行指令,就运行成功了。
注:这个数据集真挺大的,八百多 GB 的空间一下子就都用完了,所以我当时只处理了 DIV2K_train_HR 和 DIV2K_valid_HR 数据集,但这里生成的是 .mdb 文件。(后来在服务器上不以 .mdb 文件保存时,处理后的图片总共也就几百 MB 而已。)


后面又改到服务器上运行了。
5.4 数据处理意外停止

进度0%就结束了?我本来以为是没有运行,但打开输出文件夹发现只处理了一张图片。询问豆包 AI 编程发现是 prepare_data.py 中有 break 语句影响了持续处理的进程,也想起在 GitHub 上的 Issues 中确实有人提出以及解答过这个问题,尝试去掉 break 之后,再次运行就好了。
(具体见4.2.2.3)
5.5 pip install 没有权限
“Defaulting to user installation because normal site-packages is not writeable”
尝试如下指令:
python -m pip install ...5.6 'No such file or directory' 路径错误
“Processing /croot/brotli-split_1714483155106/work
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: '/croot/brotli-split_1714483155106/work'”
没有切到项目目录下,指令里的 requirements.txt 指向的是项目上一级目录下的同名文件。
5.7 未找到 CUDA
运行“python setup.py develop”指令时,抛出如下异常:
No CUDA runtime is found, using CUDA HOME='CUDA HOME:/usr/local/cuda'
Compiling fused act_ext without CUDA
Compiling upfirdn2d ext without CUDA
我当时的解决方法如下:
(1)检查并 source ~/.bashrc,发现抛出异常 -sh: e: command not found,而检查 .bashrc 文件发现其中有一行单独的"e":
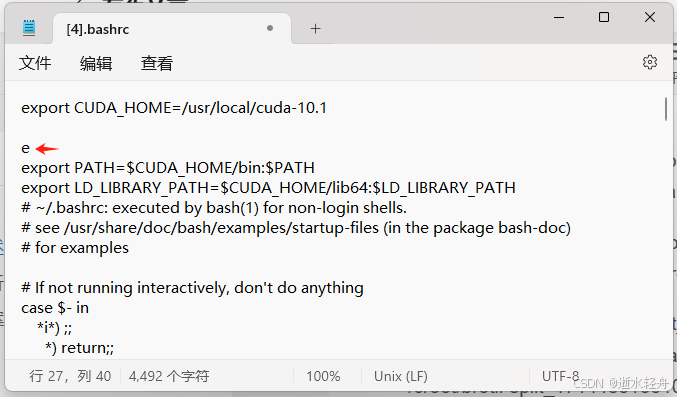
(2)删除 .bashrc 文件中单独一行的"e",然后 source ~/.bashrc,再重新运行指令。
注:现在再看感觉很简单,但当时还不熟悉,这个问题也是花了点时间才解决的。
5.8 无法安装某个 Python 包
5.8.1 权限问题
可以试试 python -m pip install ...
5.8.2 找不到对应版本
(1)可以试试添加镜像源,就是在 pip install 指令后面加上 -i [镜像源],常用的镜像源有:
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
例如:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/(2)检查是不是开了加速器、梯子、代理等,能关的都关了,这些也会影响 pip 下载。
5.8.3 使用 .whl 文件手动安装(没办法时)
(1)到 PyPI 官网搜索 Python 包名,再找到对应的版本,记得 python、操作系统、系统架构要核对准确!不是最新版本的可以在 Release history 里面找。然后点击 Download files,选择对应版本的 .whl 文件下载。
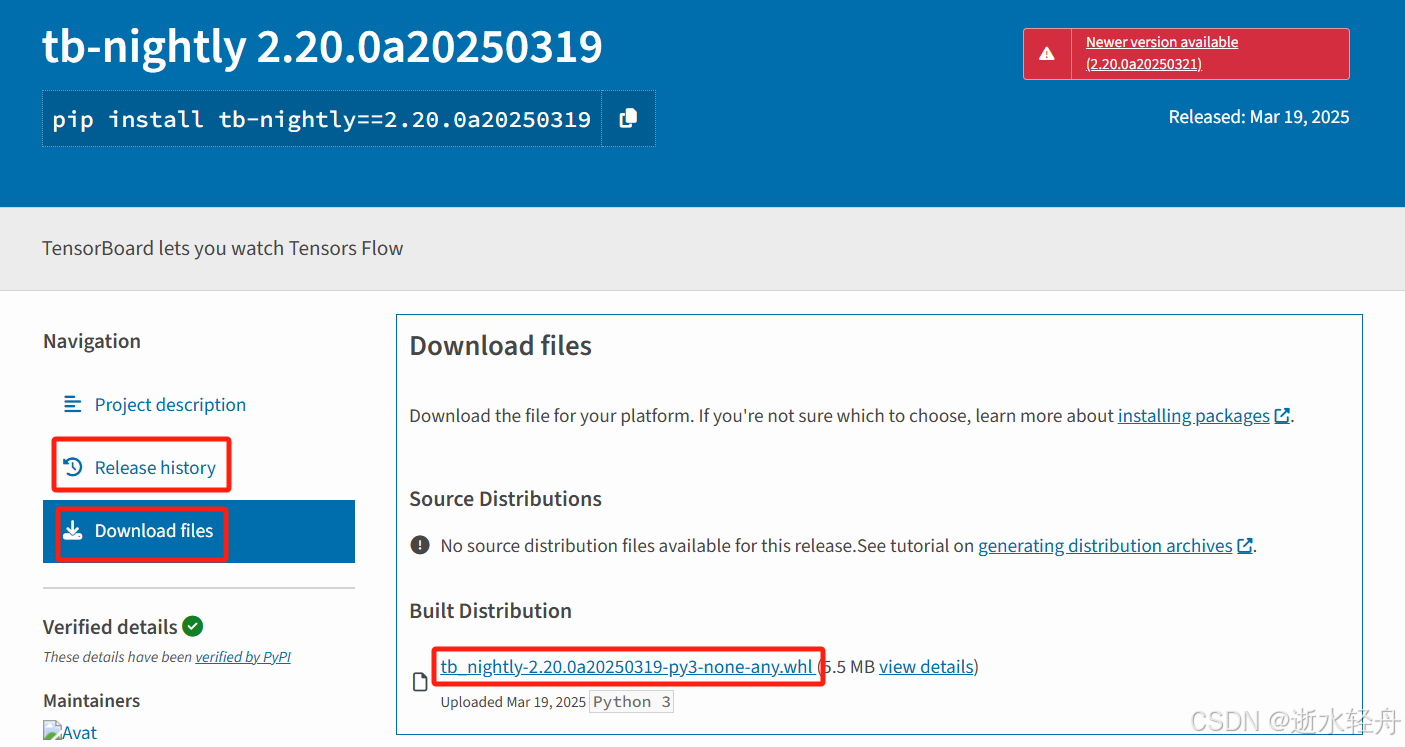
有时候会是像这种,下载链接中看不出支持 python 多少版本的,这个时候往下翻,会看到要求 Python >= 3.9。
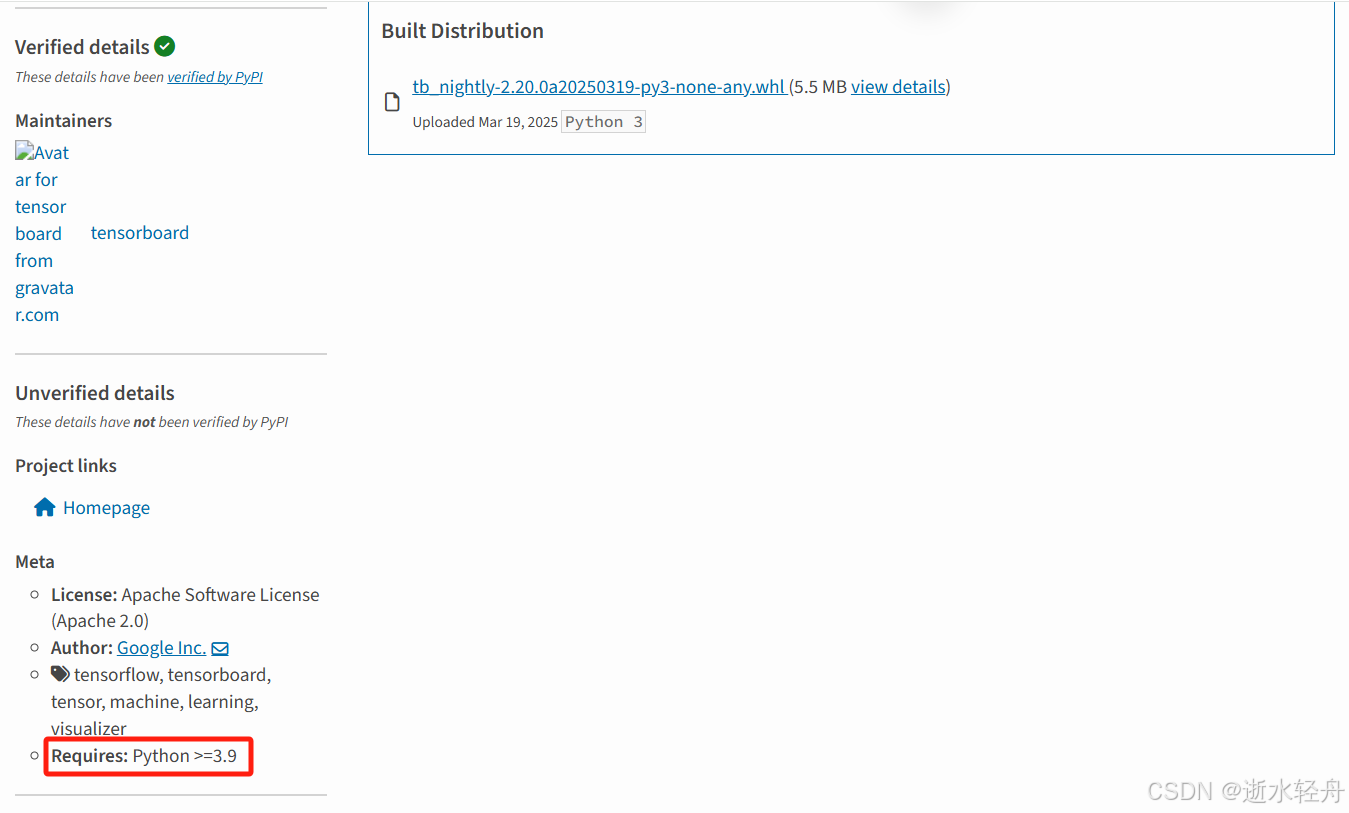
(2)下载 .whl 文件放到项目目录下,或者切到该文件所在位置,再或者在运行指令时带上具体的路径,总之保证能找到 .whl 文件。然后运行如下指令:
pip install tb_nightly-2.20.0a20250319-py3-none-any.whl
# 或者
pip install [tb_nightly-2.20.0a20250319-py3-none-any.whl 文件的相对路径/绝对路径]5.9 下载的第三方库 python 版本不对、与 CUDA 不兼容
5.9.1 与 CUDA 不兼容
指定版本,比如:
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 -f https://download.pytorch.org/whl/torch_stable.html5.9.2 python 版本不对
(1)这个时候要注意不要用镜像源,因为使用镜像源会优先从镜像源去下载,下载的 python 版本很有可能发生错误。
(2)但有时候,明明没有指定镜像源,为什么还是不对?像这样:

其实,仔细看会发现,上面还是出现了镜像源,像这里就出现了阿里云的镜像源:

这是因为使用了 pip.conf 设置了默认的镜像源,我们可以更改 pip.conf 配置文件,删去或者注释掉。
5.10 卸载 Python 包,卸不干净
明明装了 numpy 却抛出异常说找不到,或者卸载时也说没有之类的情况,有可能是 /home/(用户名)/.conda/envs/idm/lib/python3.7/site-packages 目录下有和该 Python 包相关的文件或文件夹没有删干净,可以手动删除干净,以及用 pip cache purge 清除缓存之后,再重新下载。
5.11 PyTorch 版本和自定义 CUDA 扩展的兼容问题
中间抛出异常:RuntimeError:Unrecognized tensor type ID:PythonTLSSnapshot,且错误发生在自定义的 fused_act 模块中(路径:/home/(用户名)/IDM/model/ops/fused_act/fused_act_ext.cpython-37m-x86_64-linux-gnu.so)。
这个问题与 PyTorch 版本和自定义 CUDA 扩展的兼容性 有关。估计是因为我中间重新安装了 PyTorch,版本有改变,从而导致这个问题。解决方法如下:
(1)进入自定义 CUDA 扩展目录:
cd /home/(用户名)/IDM/basicsr/ops/fused_act
# 以及
cd /home/(用户名)/IDM/model/ops/fused_act注:我是后来在验证自己的复现方法时,才发现两个地方有一样的 fused_act.py 文件。
(2)删除旧的编译文件:
rm -rf build/ *.so *.egg-info(3)重新执行如下指令:
python setup.py develop注:我当时直接 python fused_act.py 没有反应,最后是下载 ninja 包之后,运行项目根目录下的 setup.py 文件重编译成功的。可以用如下指令,检查项目中是否生成 .so 文件:
find /home/wujiahui/IDM -name "*.so" # ops/fused_act 目录下是否生成 .so 文件(如 fused_act_ext.cpython-37m-x86_64-linux-gnu.so5.12 PyTorch 与 GPU 算力问题(算力、CUDA、Pytorch对应问题)
RuntimeError: CUDA error: no kernel image is available for execution on the device
问 DeepSeek,DeepSeek 说是 PyTorch 没有为 GPU 计算能力预编译对应的内核。虽然之前用过 torch1.12.0,当时运行也是出问题,才改回了 README.md 中说的1.11.0版本的,但我突然想起这两天仔细观察过下载时进度条上方的下载链接,发现虽然都是 1.11.0 版本的 torch,但是用不同的镜像源或者其他情形下,显示匹配的有时是 python3.9 的,有时是 python3.7 的,也就是下载链接后面是 cp39 还是 cp37,这只是我后来才注意到的,所以上次用 torch1.12.0 的时候可能下载错了。
所以,我最终的解决方法是将 torch 升级到 1.12.0,再试一次!果然,再确定下载的 torch 版本没问题后,运行就正常了。
pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 -f https://download.pytorch.org/whl/torch_stable.html
注:这种情况下,可以检查自己的 GPU 算力,查询能用的 CUDA、PyTorch 版本等。
(1)查显卡算力:输入‘python’命令,进入 Python 交互式环境,再输入以下内容。
import torch
print(torch.cuda.get_device_capability(0)) # 第一块 GPU 算力(2)算力对应的 CUDA 版本:
5.13 其它
强制下载,比如 numpy:pip install --force-reinstall --no-deps numpy==1.21.6,有时候虽然显示安装成功,但是有时候不是真的安装上了,所以要检查 /home/(用户名)/.conda/envs/idm/lib/python3.7/site-packages 目录下的文件,或者使用 pip list | grep numpy 来检查是否有这个包。
6. 辅助工具
6.1 豆包 - AI编程
这是我从一开始就一直在用的工具,可以上传代码与 GitHub 连接,从而针对性地帮你解决问题,但也不是所有问题都能解决。
6.2 VS Code - Roo Code插件
在使用 VS Code 编辑器时,Roo Code 插件可以直接帮我修改代码,而且使用 VS Code LM API 是免费的,但是只能对某些终端自动输入指令和运行,有些还是要手动复制粘贴的,而且它对一般的交流语言理解力没那么强。
我也只是使用了一小段时间,因为除了可以自动帮忙改代码,其他的感觉也没那么好用,有些问题它也解决不了,甚至有问题直接给了个“您觉得呢?”……
而且我没看懂的,它也不会换种方式表达,只是机械地重复。
6.3 DeepSeek
后来开始用的,在联网的状态下其实也可以给它 GitHub 链接,从而针对性地解决问题。虽然用的时候个人觉得挺好的,但使用还不多,也没和豆包做过对比,还不好下结论。
同样也是没有帮我解决所有问题。而且无法上传所有的本地修改后的代码。
6.4 其他
其他使用过的工具还有 CSDN、百度以及 GitHub 的 Issues 等,这些都是找别人的经验而已,只能基于已有的经验,所以很有限。
其中 GitHub 的 Issues 是针对自己要跑的项目的,所以可能更有针对性,但是实际上我能用到的不多。
也可以在这些平台上发布自己的问题,但想要得到回复,时间间隔估计会很长。
7. 感受
这是我成功复现的第一个代码。上学期虽然也尝试过复现代码,但是当时试一阵没一阵的,最后没复现出来也没在意。
但这学期大概从3月7号开始到现在,是我第一次集中精力去复现代码,我尝试复现的也不止这一个,中间有几天是在复现其他的,因为觉得那个想要复现的可能性更低,我就又回到了这个代码。而且我反复地从本地迁到服务器,又从服务器迁回本地,环境搭了又卸,卸了又搭的,从 cmd 换到 bash,再换到 prompt,也从头开始了好几次。虽然有做记录,但是笔记做得还是不够细致,有些问题和学习到的东西我已经混乱了,忘记到底是在什么情况下了。所以,上面所写的“踩过的坑”也只是其中一部分而已。这也表明有一个好习惯多重要,而我还在培养中。
复现这个代码,前前后后奋斗了有两个星期左右,有好几次觉得都快成功了,可还是遇到各种各样的问题。我也曾不明白到底哪里有问题,也有低落的时候,但好在我基本上只是在绞尽脑汁地思考:接下来怎么办?基于今天的结果,我明天能做什么?还有什么工具是我没用的?还有什么是我忘记或者没考虑到的?好在我不会产生焦虑,好在我终于在不断跌倒中有所成长。
这段时间过得挺紧张的,但更准确地说应该是充实。我只是在自己认为该学习的时间忙科研,其他时间,比如回到宿舍时自己的休闲时间、睡觉的时间等,我可以较好地抽离出来,专注地做自己想做的事,好好地休息和丰富自己。
*** 1、只想解决问题的办法,不为没有办法而焦虑。 2、脚步可以匆匆,心绪需要从容。 3、尽人事,听天命。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









