






1、逻辑回归与线性回归有什么不同?
①应用领域
线性回归:常常用于解决回归问题。其目标常常是预测一个连续输出结果(比如房价、销售额、销量等等)。线性回归试图建立一个关系,以最小化观测值与预测值之间的差异。
逻辑回归:常常用于解决分类问题。其目标是将输入数据分为两个或者多个类别。
②输出
线性回归:输出是一个连续的数值,可以是任意的实数。线性回归模型的公式是:

逻辑回归:输出是一个介于0到1之间的概率值。逻辑回归使用逻辑函数(也就是Sigmoid函数)去计算概率值。其公式是:

③目标
线性回归:目标是找到一条最佳拟合线,以最小化实际观测值(说白了就是实际值)与预测值之间的误差平方和。
逻辑回归:目标是找到最佳参数beta,以最大化观测数据属于正类别或者负类别的概率,从而能够进行分类。
2、逻辑回归如何处理二分类任务?如何处理多分类任务?
处理二分类问题:
处理二分类问题的步骤:
1、数据准备:获取带有标签的训练数据集,其中每个样本都有一个二元类别标签,通常为0或1。
2、特征工程:根据问题的性质选择和提取适当的特征,以作为模型的输入。
3、模型训练:使用逻辑回归模型,建立一个线性组合的模型,然后通过逻辑函数将其映射到[0, 1]范围内的概率。训练模型时,通过最大化似然函数来拟合模型参数。
4、预测和分类:对于新的未标记样本,使用训练好的模型进行预测。通常,模型会输出一个概率值,然后可以根据阈值(通常为0.5)将概率转化为二元类别,例如,如果概率大于阈值,则将样本分为正类别(1),否则分为负类别(0)。
5、评估模型性能:使用适当的性能指标(如准确率、精确度、召回率、F1分数、ROC曲线和AUC)来评估模型的性能。
处理多分类问题:
机器学习笔记(四)---- 逻辑回归的多分类 - 华为云官方博客 - 博客园 (cnblogs.com)
(这篇文章讲的挺好,看完后凭自己的感受又重述一遍)
首先抛开逻辑回归不谈,当我们遇到一个多分类问题的时候,有两种策略:
Ⅰ:使用能够直接解决多分类问题的模型。比如K近邻,决策树;
Ⅱ:利用多个二分类学习器去解决多分类问题;
等下详细且重点的介绍一下第二种策略!!!
现在回到逻辑回归,有两种方法能够使用逻辑回归去解决多分类问题:
Ⅰ:将多分类任务拆解成多个二分类任务,利用逻辑回归分类器进行投票求解;
Ⅱ:对传统的逻辑回归模型进行改造,使之变为softmax回归模型(即变成了一种特殊的逻辑回归模型);
① OvO(一对一,One vs One):假如数据D中有N个类别,将N个类别进行两两配对,产生N(N-1)/2 个二分类器,在预测中,将测试样本输入这N(N-1)/2 个二分类器中得到相应个数的预测结果,然后再将被预测结果数最多的(Voting)作为最终分类结果。
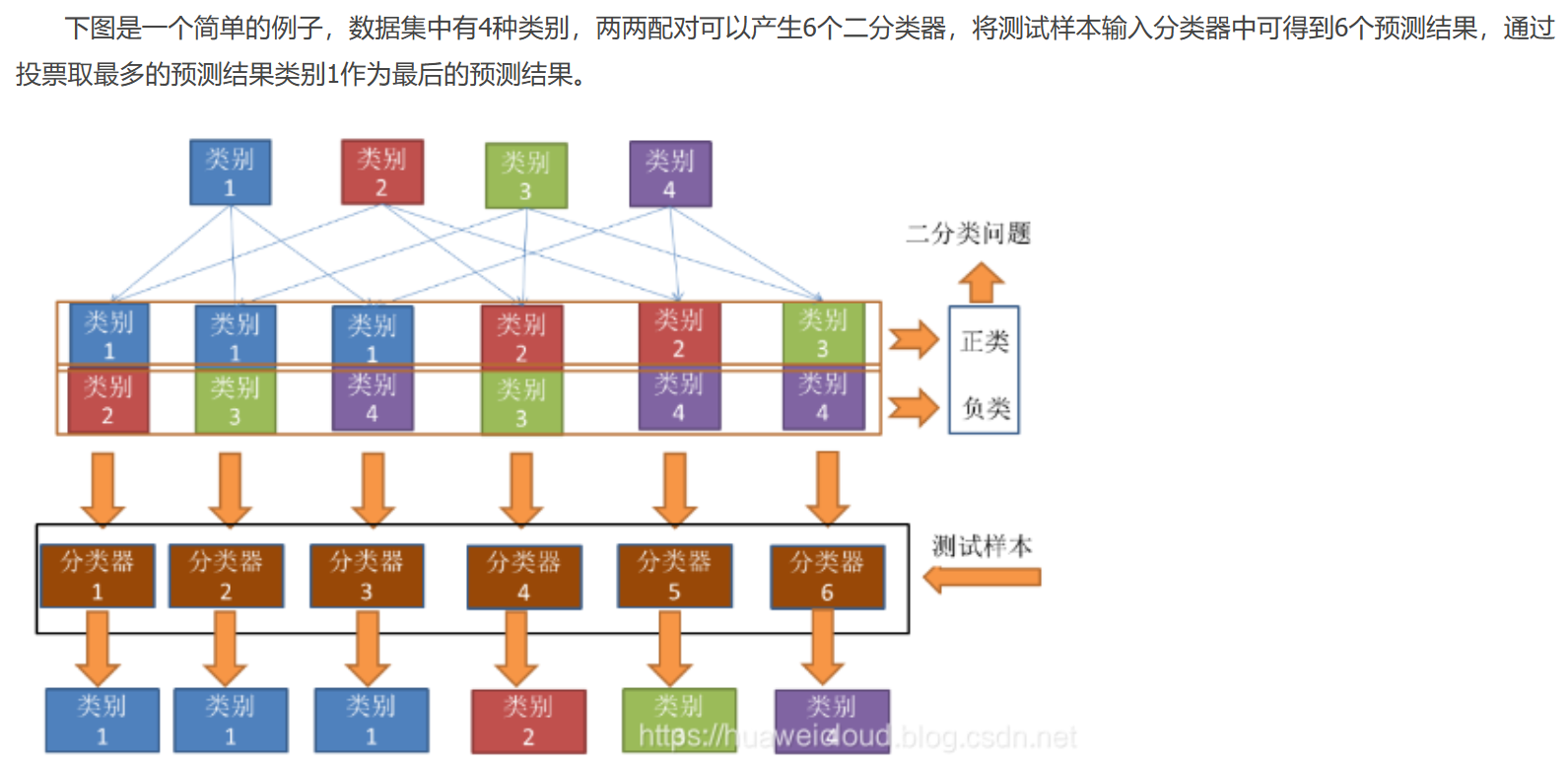
②OvR(一对其余,One vs Rest): 将一个类别作为正例,其余所有类别作为反例,这样N个类别可以产生N个二分类器,将测试样本输入这些二分类器中中得到N个预测结果,如果仅有一个分类器预测为正类,则将对应的预测结果作为最终预测结果。如果有多个分类器预测为正类,则选择置信度最大的类别作为最终分类结果。

从验证结果上来看,OvO策略和OvR策略类似,在大多数情况分类效果差不多(小数据量和少类别的情况下可能OvO效果更好),OvO训练的分类器数目比OvR多,所以OvO的存储开销和训练时间通常比OvR更大,但由于训练时,OvR的每个分类器需要用到所有训练样例,而OvO的每个分类器只用到两个类别的样例,所以在大数据集和类别较多的情况下,OvO的训练时间开销比OvR更小。
③Softmax回归:也称为多类别逻辑回归或多项式回归。Softmax回归将多个类别之间的关系建模为一个多类别概率分布。它使用Softmax函数来将线性组合的输入映射到K个类别的概率分布,其中K是类别的数量。训练Softmax回归模型时,通常使用交叉熵损失函数。
处理多分类问题时,通常选择Softmax回归方法,因为它可以直接建模多类别之间的关系,并且在一次训练中学习所有类别的参数。一对多方法可能需要更多的模型和更多的训练时间,但在某些情况下也可以有效地处理多分类问题。
无论是处理二分类问题还是多分类问题,逻辑回归都是一个强大且常用的分类算法,可以根据问题的性质和数据集的大小来选择适当的方法。
3、什么是Sigmoid函数?它在逻辑回归中的作用是什么?
Sigmoid函数,也称为逻辑函数(Logistic Function),是一种常用的S型函数,公式如下:

作用:
Ⅰ:将线性组合转化为概率:逻辑回归模型通过将输入特征的线性组合()传递给Sigmoid函数,将其转化为一个介于0和1之间的概率值。
Ⅱ:平滑性:Sigmoid函数是光滑的S型曲线,具有连续导数。这使得逻辑回归模型易于优化,可以使用梯度下降等优化算法来找到最佳参数。
4、逻辑回归模型的参数是什么?如何训练这些参数?
具体来说,逻辑回归模型的参数如下:
1、权重(系数):对应于每个输入特征的权重,用于衡量该特征对预测的影响。每个特征都有一个对应的权重参数。
2、截距(偏置项):表示模型的基准输出,即当所有特征的值都为零时,模型的输出值。
训练逻辑回归模型的过程通常涉及以下步骤:
1、数据准备:获取带有标签的训练数据集,其中包括输入特征和相应的类别标签(通常为0或1)。
2、特征工程:选择和提取适当的特征,并进行必要的特征预处理(例如,标准化、缺失值处理等)。
3、模型初始化:初始化模型的权重和截距(通常为零或小随机值)。
4、定义损失函数:通常使用交叉熵损失函数(对数损失函数)来衡量模型预测的概率与实际标签之间的差异。
5、优化算法:选择一个优化算法,通常是梯度下降(Gradient Descent)或其变种,用于最小化损失函数并更新模型的参数(权重和截距)。优化算法会沿着损失函数的梯度方向更新参数,使损失逐渐减小。
6、训练模型:迭代运行优化算法,通过将训练数据传递给模型,计算梯度并更新参数。训练过程通常需要多个迭代轮次,直到收敛到最佳参数。
7、评估模型:使用独立的验证集或测试集来评估模型的性能。通常使用性能指标(如准确率、精确度、召回率、F1分数等)来评估模型的分类性能。
8、调整超参数:根据模型性能进行超参数调优,例如学习率、正则化参数等。
9、模型应用:一旦训练完毕并满意性能,可以使用该模型来进行新样本的分类预测。
10、可解释性分析(可选):根据模型的参数权重,可以进行特征重要性分析,以了解哪些特征对模型的预测最具影响力。














 5830
5830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









