







若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。当然最重要的是订阅跟随“鲁班模锤”。
FlashAttention属于AI加速器,要读懂它需要先具备Transformer的背景知识以及注意力机制,最后才到FlashAttention。随着大模型优化技术的层出不穷,里面的kernel fusion技术将会越来越频繁的被提及,例如在Mamba中也被用于加速。因此借着FlashAttention的这个机会更加深入的了解下GPU。

Transformer
在理解FlashAttention之前,先来回顾下Transformer Block。先来看个抽象版本,然后再来看个可视化的版本。重点是要让读者温习下自注意力矩阵的运算过程。
读者还是需要熟悉Block(Layer)这个概念,比如Mamba Block,每种Block都会有对应的逻辑块。
|
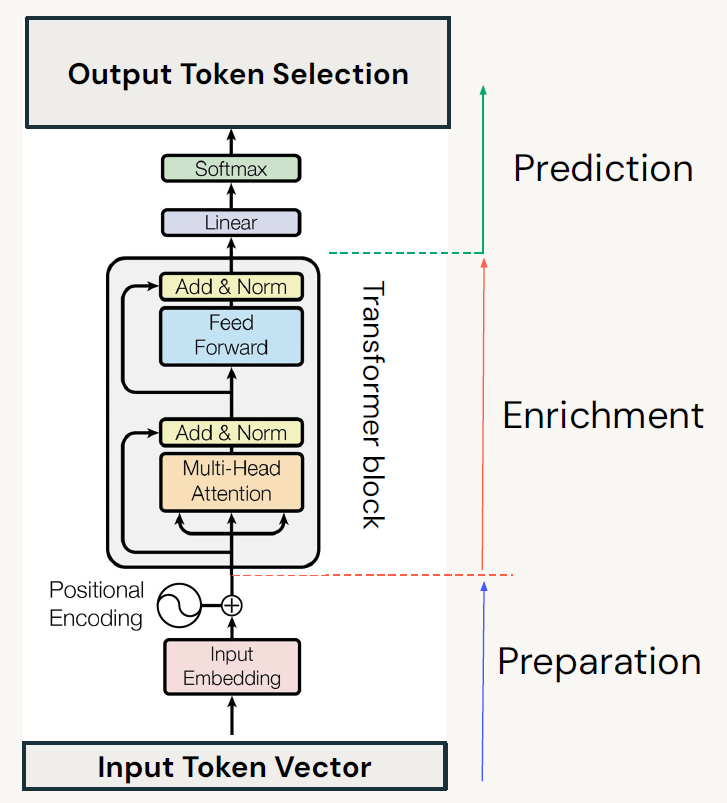
| 左图为简化过的Transformer模型,输入的Token进行Embedding和Pos Embedding之后进入注意力机制模块,然后通过FFN输出结果,最后通过线性层输出下一个词的概率。 |
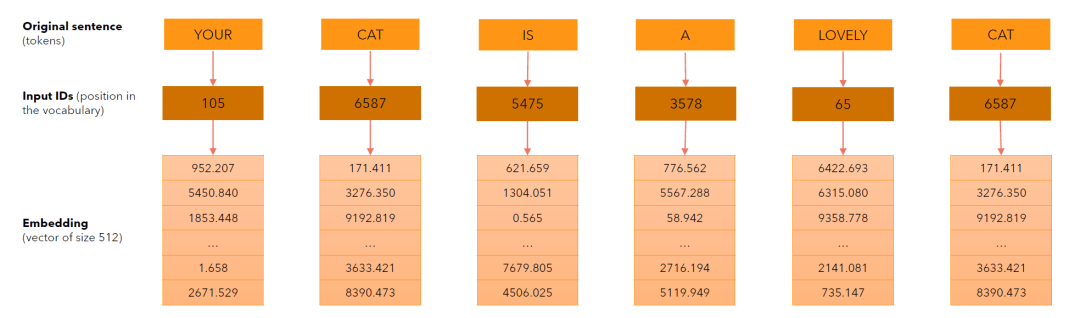
为了后面在介绍FlashAttention更加的丝滑,这里举个例子让读者有更深的印象。这里输入为“your cat is A lovely cat”,假设刚好被切分为6个Token,之后对Token进行Embedding,每个单词被Embedding为512维的向量。
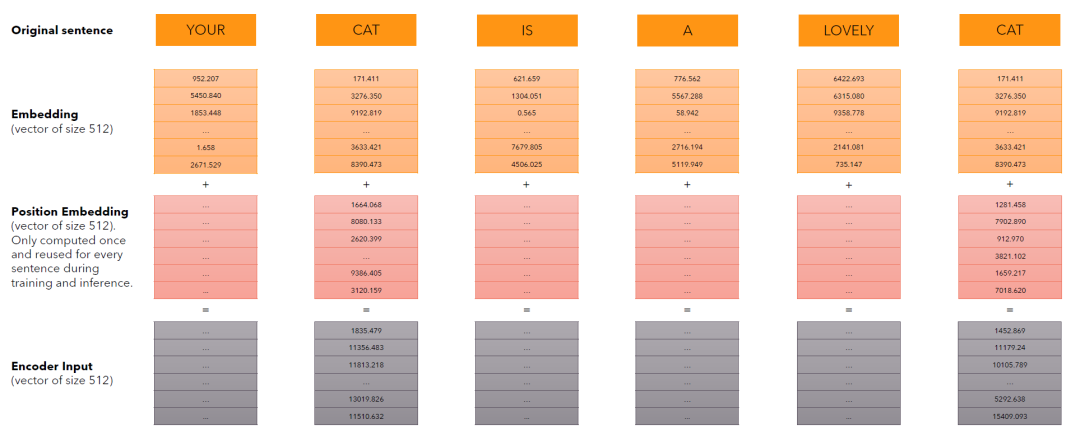
Embedding之后的向量需要和位置向量(维度也是512维,目的是为了让Token带上位置信息)相加,形成编码输入(encode input)。
这个时候输入为(6,512),6个token对应的编码,每个编码512维。然后开始进行注意力机制的运算。这些输入(6, 512)都和三个矩阵相乘后得到Q,K,V三个矩阵。将Q和K的装置矩阵相乘,再通过softmax函数就可以得到如下6*6的矩阵。
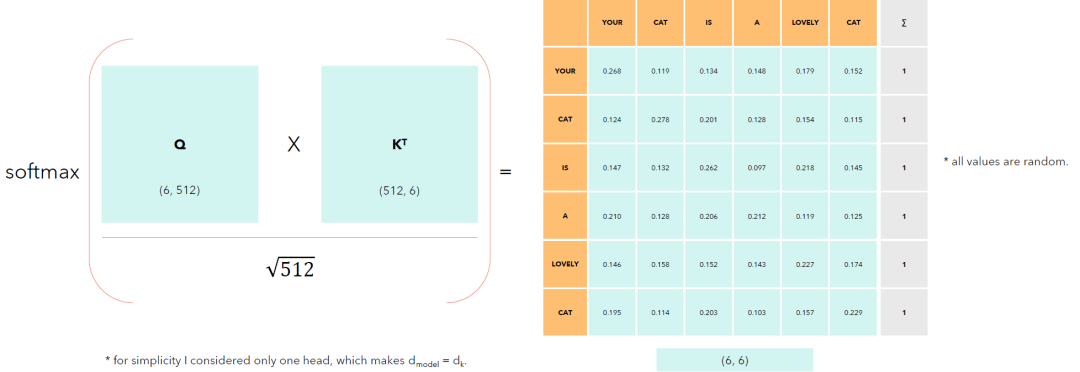
最后将这个中间结果和V相乘就可以得到自注意力矩阵。
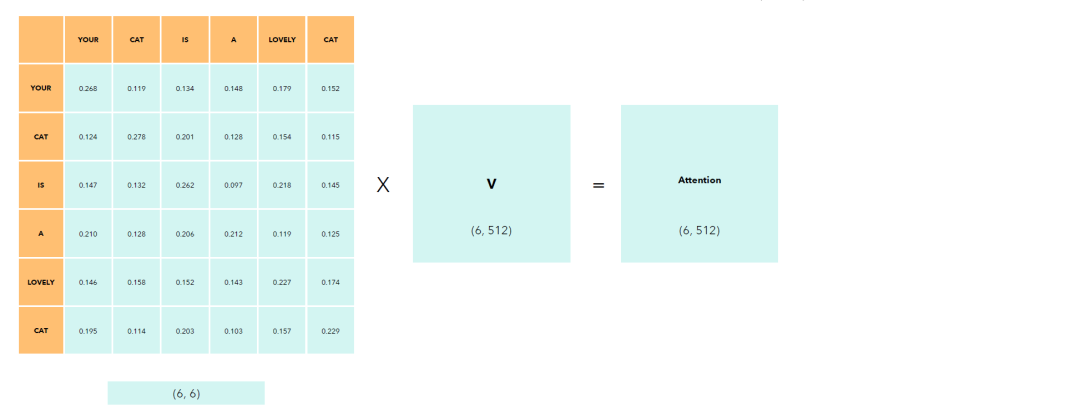

注意力机制
自注意力机制是Transformer的灵魂,读者只要记住Q(query),K(Key),V(Value)即可。Query可以是自身,也可以是外部。大白话的意思就是,用Q和每个Token的K对比,然后按照计算出来的权重把V加成到最后。
|
|
|
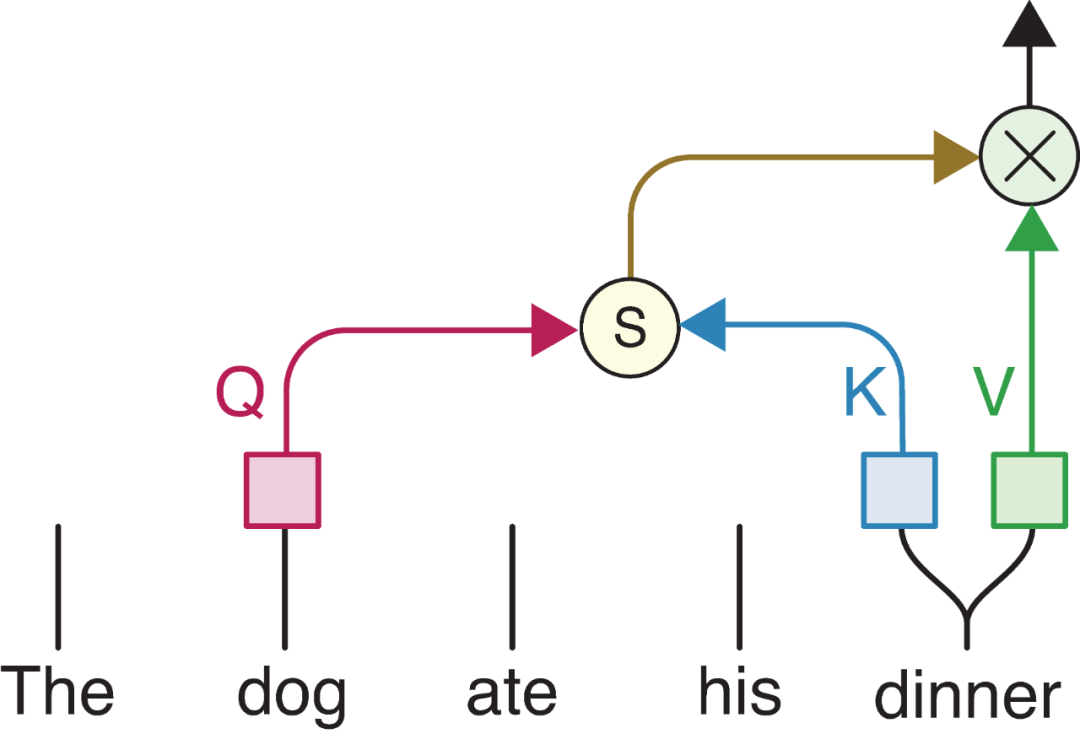
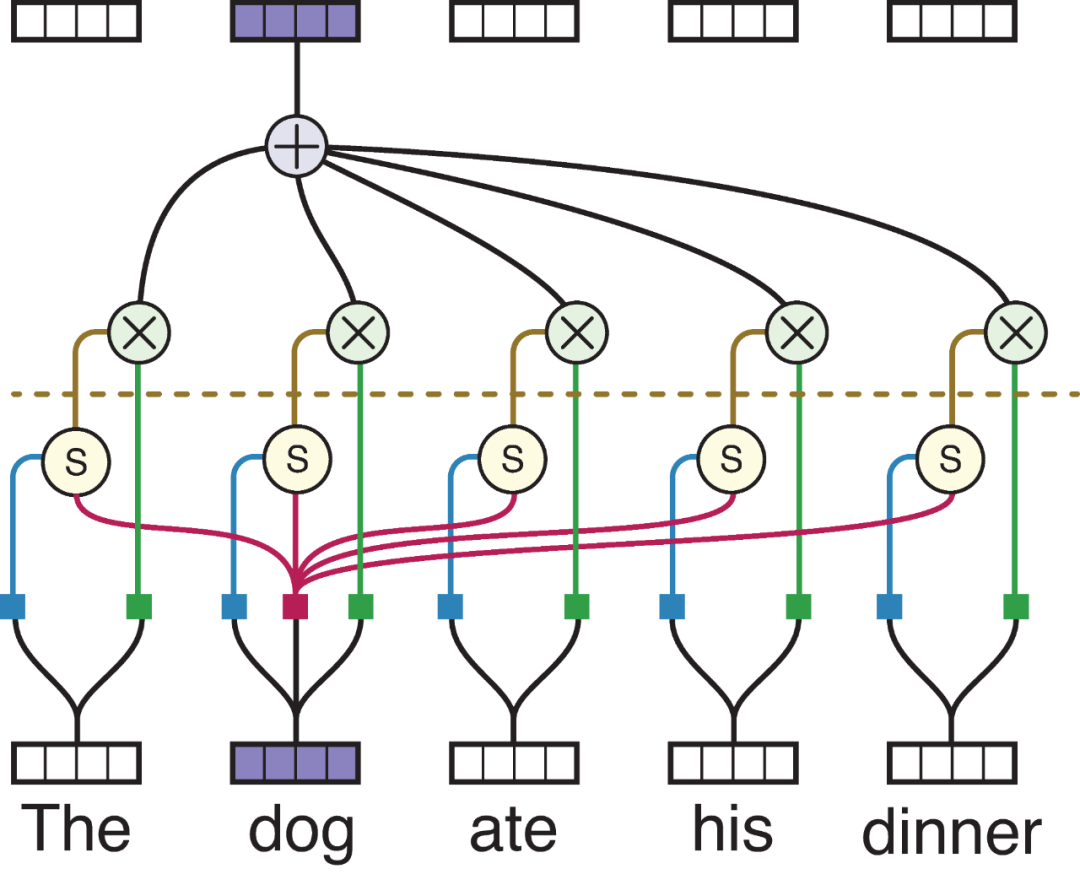
要是Q来至于自身的句子,则将每个Token(单词)和其他重复做一遍运算,就可以得新输出,而新输出则代表着输入有哪些信息是值得关注的。
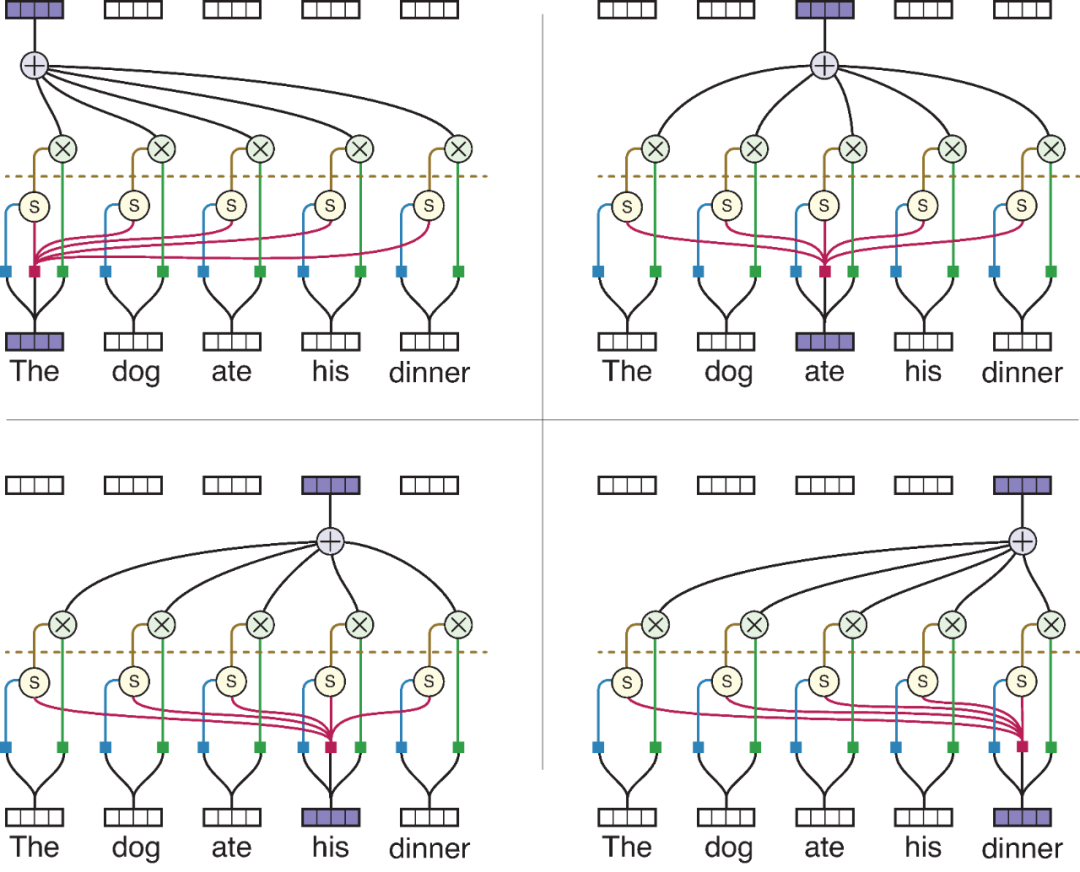

内存卡点
|
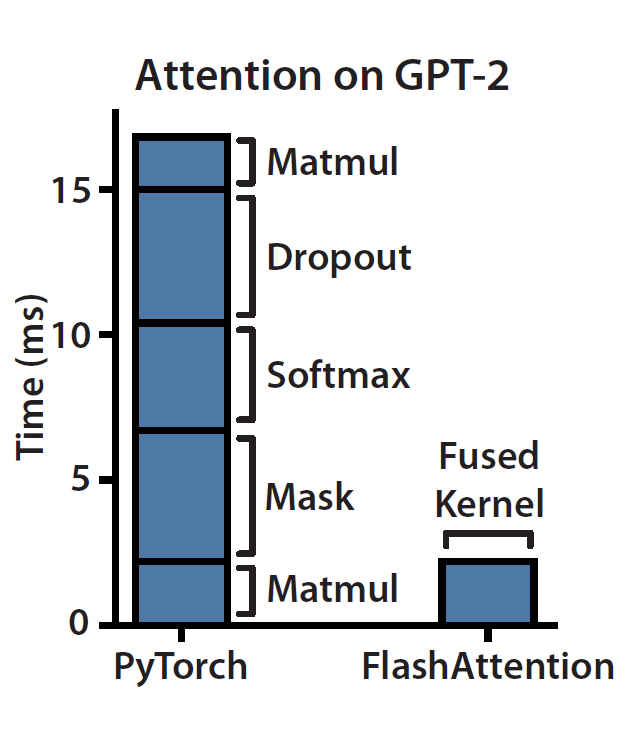
| 研究人员通过在GPT-2的Attention运算进行分析,发现矩阵运算和Softmax的计算占据了大量的时间。注意力机制的运算复杂度为 |
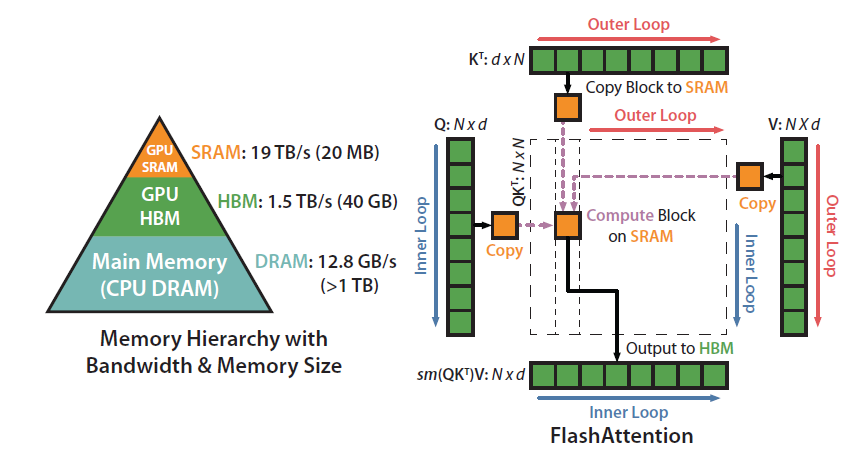
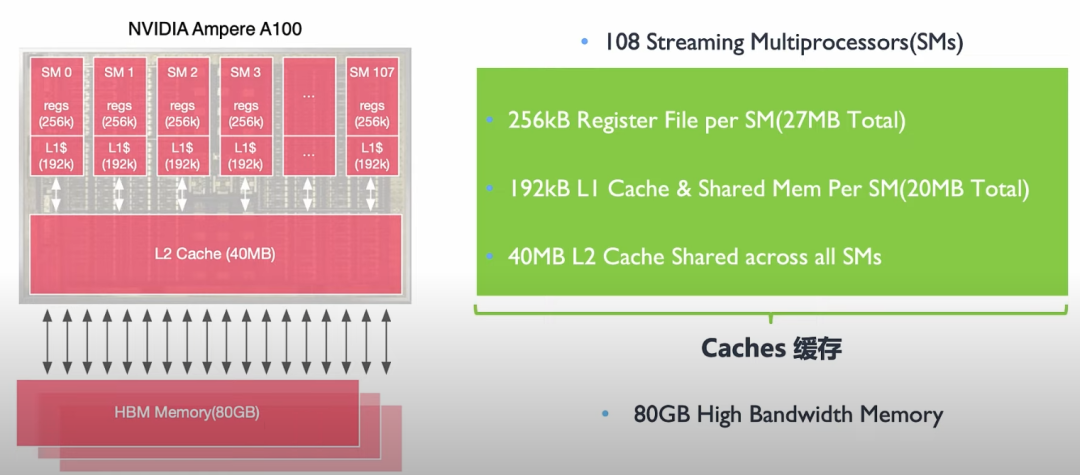
GPU的结构和运算模型要是不清楚的话,请到<泛AI平台架构设计二>温习功课。A100拥有40-80GB的HBM,带宽为1.5-2.0TB/s,108个流式处理器各自有192KB的SRAM,带宽约为19TB/s。因此如何减少HBM的读取,而直接在SRAM中运算,速度会提升不少。
那么正常情况下,注意力机制是如何加载运算的,下面的伪代码揭示了答案。QKV都在HBM,要计算的时候读入SRAM,运算结束写入HBM,如此反复的折腾。

这里多了两个矩阵S和P,一个是上文的
,一个是通过softmax的归一化矩阵。都是N*N维度的(N为Token的长度)
因此最容易相对的优化方法就是避免这种来回的数据搬运。那么”kernel fusion”浮出了水面,大白话的意思就是把多个操作合并成一个。
|
|
|


这里和Mamba提到的优化思路一致,将多次需要在HBM和SRAM来回搬运数据的操作合并。如右图所示,优化后只需要在HBM和SRAM直接来回搬运一次。
若要计算的是矩阵的行softmax,则需要计算某个元素和它同一行的所有其它元素的权重,进行归一化。假如某一行的向量是z,那么softmax(z)的第i元素为:
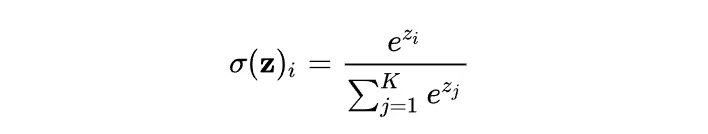
这个过程的卡点在这个分母的求解(求和)。为了计算第i个token对其它所有token的Attention Score,则需要计算i和这一行所有的其他j的Score,然后按行进行累加的softmax运算。
SRAM的容量很有限,而序列长度N(Token的数量)通常是以k来计算,刚才的例子只有6个token,而现实中4k和8k是比较常见的,有些能到64k、128k乃至无限容量。这种规模的矩阵是无法全部加载进SRAM进行一次性运算而提速的。
小知识:由于
很容易溢出, 比如FP16支持范围是
∼65504,当
≥ 11的时候,

Softmax求解重构
FlashAttention将应用两种成熟技术(Tiling、Recompute)来解决这个挑战。Tiling在于通过算法重新改写softmax的求解过程。
算法过程如下:假设需要求解的softmax值,先将这组数据分成3个(或者N个)小组x(1),x(2),x(3)。其中x(1)=
,x(2)=
,x(3)=
。
通过下面运算允许将长的序列分为N组,两两迭代计算,进而得出最终的数值。是不是让你想到之前Mamba的并行扫描。
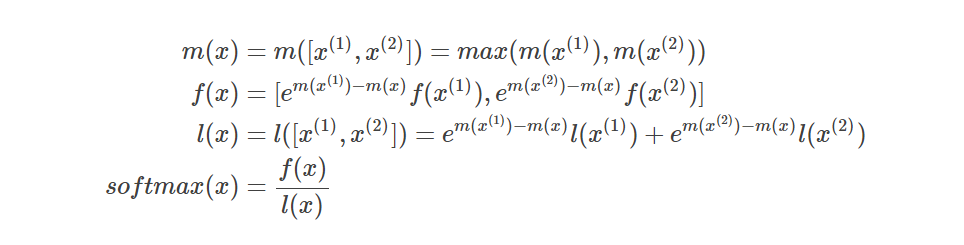
m(x)求出序列的最大值,是个标量,而f(x)是一个向量。
看个具体实例:
-
先计算各自小组的l值和f值。
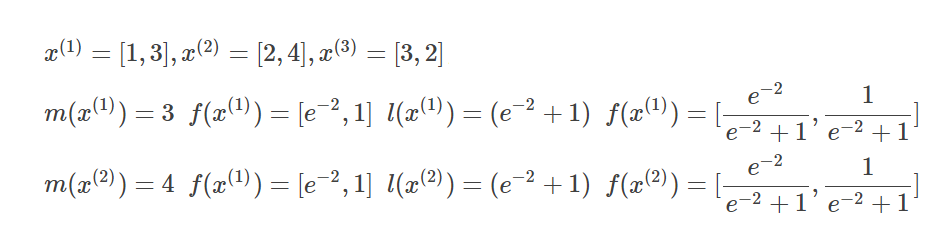
-
第1组和第2组的m值和f值迭代计算,得到新的f值和l值

-
将第2步结果和第3组再次进行迭代计算
如此直至结束,这样一来只要跟踪额外的统计信息𝑚(𝑥)和 ℓ(𝑥),就能够将Q,K,V进行分块计算,得到最终的结果O。另外还有个好处,通过存储输出O和softmax归一化统计量𝑚(𝑥)和 ℓ(𝑥),就可以重新计算注意力矩阵S和P,避免存储中间值S和P而导致的反复读取。下篇再来细讲具体的过程。

















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









