







线性回归与逻辑回归LR
线性回归
回归是监督学习的一个重要问题,回归用于预测输入变量和输出变量之间的关系。回归模型是表示输入变量到输出变量之间映射的函数。
回归问题的学习等价于函数拟合:使用一条函数曲线使其很好的拟合已知函数且很好的预测未知数据。
回归问题按照输入变量的个数可以分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型,可以分为线性回归和非线性回归。
一元回归:
y
=
a
x
+
b
y = ax + b
y=ax+b
多元回归:
h
0
(
x
)
=
∑
i
=
0
n
θ
i
x
i
=
θ
T
x
h_{0}(x)= \sum _{i=0}^{n}\theta _{i}x_{i}= \theta ^{T}x
h0(x)=∑i=0nθixi=θTx
应用场合
线性回归的应用场合大多是回归分析,一般不用在分类问题上,原因可以概括为一下两个:
1)回归模型是连续模型,即预测出的值都是连续值(实数值),非离散值;
2)线性回归在整个实数域内敏感度一致,预测结果受样本噪声的影响比较大。
求解
最小二乘法
假设模型结果与测量值误差满足,均值为0的高斯分布,即正态分布。这个假设是靠谱的,符合一般客观统计规律。
设
ϵ
i
=
y
i
−
h
θ
(
x
i
)
\epsilon _i = y_i-h_{\theta}(x_i)
ϵi=yi−hθ(xi)
p
(
ϵ
i
)
=
p
(
y
i
∣
x
i
;
θ
)
=
1
2
π
δ
e
x
p
(
−
(
y
i
−
h
θ
(
x
i
)
)
2
2
δ
2
)
p(\epsilon _i ) = p(y_{i}|x_{i};\theta)=\frac{1}{\sqrt{2\pi}\delta}exp(-\frac{( y_i-h_{\theta}(x_i))^2}{2\delta ^2})
p(ϵi)=p(yi∣xi;θ)=2πδ1exp(−2δ2(yi−hθ(xi))2)
似然函数:
L
(
θ
)
=
∏
i
=
1
m
p
(
y
i
∣
x
i
;
θ
)
L(\theta)= \prod _{i=1}^{m}p(y_{i}|x_{i};\theta)
L(θ)=i=1∏mp(yi∣xi;θ)
取对数: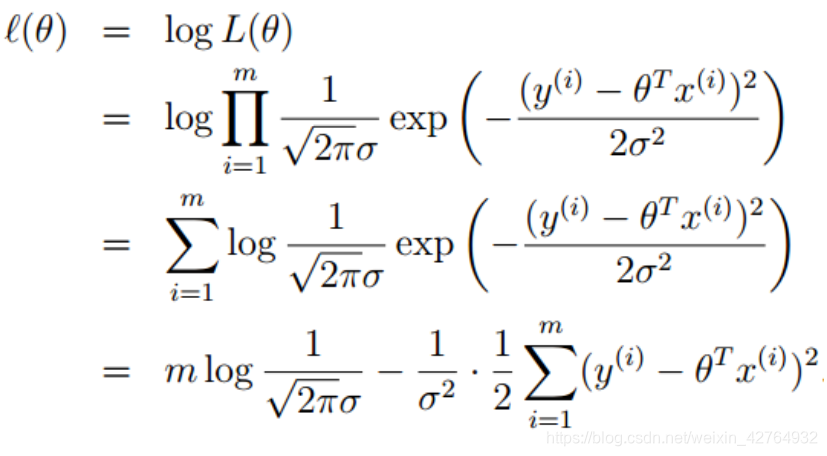
需要极大似然估计,即最后一项的后半部分最小,即得到损失函数:
损失函数:平方损失函数
J
(
θ
)
=
1
2
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
=
1
2
(
X
θ
−
y
)
T
(
X
θ
−
y
)
J(\theta)= \frac{1}{2}\sum _{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2}=\frac{1}{2}(X \theta -y)^{T}(X \theta -y)
J(θ)=21i=1∑m(hθ(x(i))−y(i))2=21(Xθ−y)T(Xθ−y)
最小化目标函数: 由于目标函数连续,那么
θ
\theta
θ 取值一定为目标函数的驻点,所以我们求导寻找驻点。
求导可得:
∇
θ
J
(
θ
)
=
∇
θ
(
1
2
(
X
θ
−
y
)
T
(
X
θ
−
y
)
)
=
∇
θ
(
1
2
(
θ
T
X
T
−
y
T
)
(
X
θ
−
y
)
)
=
∇
θ
(
1
2
(
θ
T
X
T
X
θ
−
θ
T
X
T
y
−
y
T
X
θ
+
y
T
y
)
)
=
1
2
(
2
X
T
X
θ
−
X
T
y
−
(
y
T
X
)
T
)
=
X
T
X
θ
−
X
T
y
\nabla_{\theta}J(\theta)=\nabla_{\theta}(\frac{1}{2}(X \theta -y)^{T}(X \theta -y))= \nabla _{\theta}(\frac{1}{2}(\theta ^{T}X^{T}-y^{T})(X \theta -y)) \\ =\nabla_{\theta}(\frac{1}{2}(\theta ^{T}X^{T}X \theta - \theta ^{T}X^{T}y-y^{T}X \theta +y^{T}y)) \\ =\frac{1}{2}(2X^{T}X \theta -X^{T}y-(y^{T}X)^{T})=X^{T}X \theta -X^{T}y
∇θJ(θ)=∇θ(21(Xθ−y)T(Xθ−y))=∇θ(21(θTXT−yT)(Xθ−y))=∇θ(21(θTXTXθ−θTXTy−yTXθ+yTy))=21(2XTXθ−XTy−(yTX)T)=XTXθ−XTy
矩阵求导可参考:
标量、向量与矩阵的求导https://blog.csdn.net/weixin_42764932/article/details/113107265
向量、矩阵求导的重要公式https://blog.csdn.net/weixin_42764932/article/details/113107962
解得: θ = ( X T X ) − 1 X T y \theta=(X^{T}X)^{-1}X^{T}y θ=(XTX)−1XTy
然鹅有解的前提是 X T X X^{T}X XTX是可逆的
梯度下降法
θ
=
θ
−
α
⋅
∂
J
(
θ
)
∂
θ
\theta= \theta - \alpha \cdot \frac{\partial J(\theta)}{\partial \theta}
θ=θ−α⋅∂θ∂J(θ)
∂
∂
θ
j
J
(
θ
)
=
∂
∂
θ
j
1
2
(
h
θ
(
x
)
−
y
)
2
=
(
h
θ
(
x
)
−
y
)
x
j
\frac{\partial}{\partial \theta _{j}}J(\theta)= \frac{\partial}{\partial \theta _{j}}\frac{1}{2}(h_{\theta}(x)-y)^{2}=(h_{\theta}(x)-y)x_{j}
∂θj∂J(θ)=∂θj∂21(hθ(x)−y)2=(hθ(x)−y)xj
-
BGD:所有n个样本的平均损失
-
SGD:单个样本处理
-
mini-batch:多个样本处理
由于在线性回归中,目标函数收敛而且为凸函数,是有一个极值点,所以局部最小值就是全局最小值。
加入正则化
前面说了解析解是 θ = ( X T X ) − 1 X T y \theta=(X^{T}X)^{-1}X^{T}y θ=(XTX)−1XTy
并且有解的前提是 X T X X^{T}X XTX是可逆的
若 X T X X^{T}X XTX不可逆或为了防止过拟合,我们可以增加lambda扰动 θ = ( X T X + λ I ) − 1 X T y \theta=(X^{T}X+ \lambda I)^{-1}X^{T}y θ=(XTX+λI)−1XTy
按着求解过程倒回去,可以得到带有正则化项的损失函数
从另一个角度来看,这相当与给我们的线性回归参数增加一个惩罚因子,这是必要的,我们数据是有干扰的,不正则的话有可能数据对于训练集拟合的特别好,但是对于新数据的预测误差很大。
加入 L1 或 L2 正则化,让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。
可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什幺影响,一种流行的说法是『抗扰动能力强』。
岭回归Ridge regression
岭回归(ridge regression)其实就是在标准线性回归的基础上加入L2 正则化(regularization)
J
=
1
2
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∑
j
=
1
n
θ
j
2
J= \frac{1}{2}\sum _{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2}+ \lambda \sum _{j=1}^{n}\theta _{j}^{2}
J=21i=1∑m(hθ(x(i))−y(i))2+λj=1∑nθj2
L2约束就是一个圆,
要求的就是在约束的条件下寻找最小的损失。所以其实就是找约束的图形和等值线的交点。
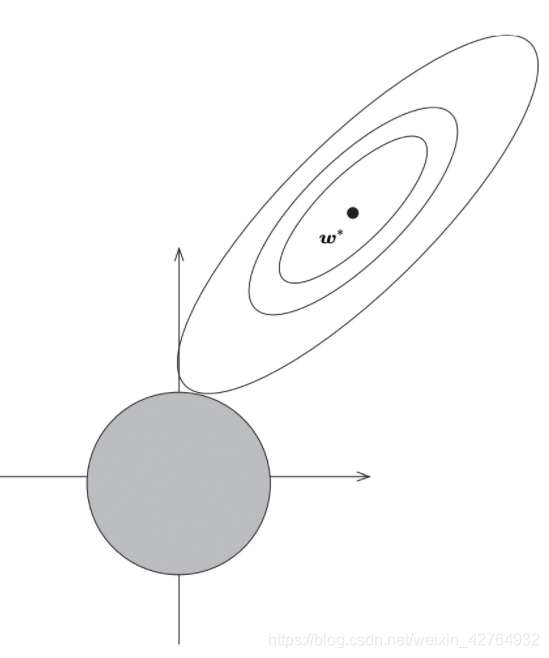
ridge 更容易使得权重接近 0,但由于交点在坐标轴(某维度值为零)的概率较小,所以没有让参数稀疏化的作用,但可以让参数变小,减缓过拟合。
lasso回归lasso regression
lasso回归其实就是在标准线性回归的基础上加入L1 正则化(regularization)
J
=
1
2
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
∣
∣
w
∣
∣
1
J=\frac{1}{2}\sum _{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^{2}+ \lambda ||w||_{1}
J=21i=1∑m(hθ(x(i))−y(i))2+λ∣∣w∣∣1
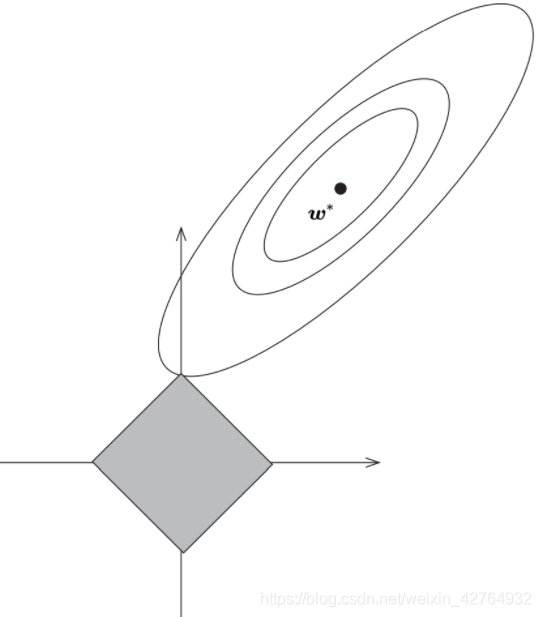
而L1损失的交点更容易在坐标轴上,所以更容易让参数稀疏化
正是由于 lasso 容易使得部分权重取 0,所以可以用其做 feature selection,lasso 的名字就指出了它是一个 selection operator。权重为 0 的 feature 对回归问题没有贡献,直接去掉权重为 0 的 feature,模型的输出值不变。
从贝叶斯角度理解这俩回归
给定观察数据D, 贝叶斯方法通过最大化后验概率估计参数w。
p(D|w)是似然函数(likelihood function): 参数向量w的情况下,观测数据D出现的概率
p(w)是参数向量的先验概率(prior)
对于似然函数部分有:
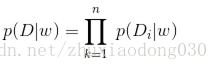
对后验概率取对数有
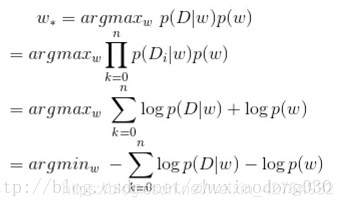
当先验概率分布满足正态分布的时候
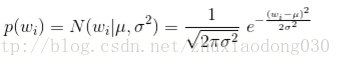
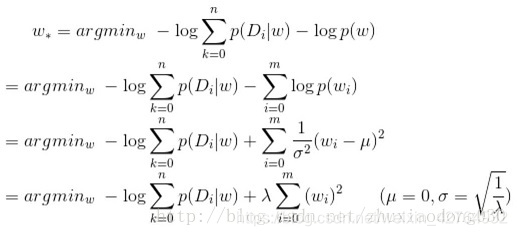
可以看到,似然函数部分对应于损失函数(经验风险),而先验概率部分对应于正则项。L2正则,等价于参数w的先验概率分布满足正态分布。
当先验概率分布满足拉普拉斯分布的时候
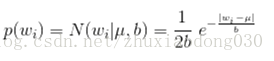
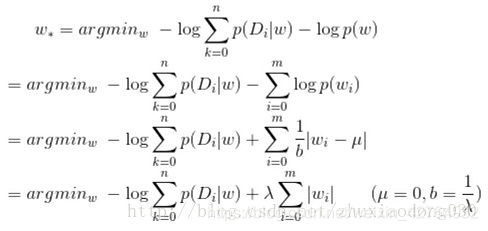
L1正则,等价于参数w的先验概率分布满足拉普拉斯分布。
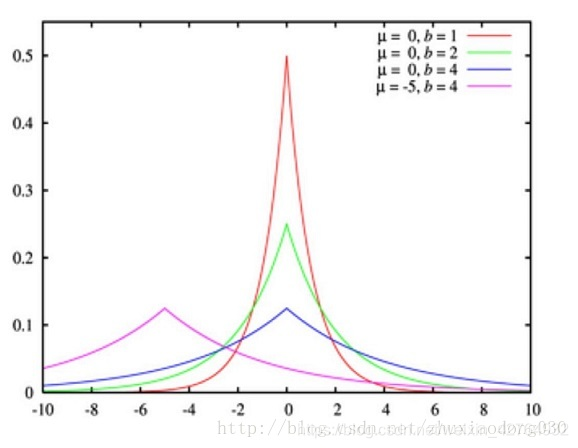
对比拉普拉斯分布和高斯分布,可以看到拉普拉斯分布在0值附近突出;而高斯分布在0值附近分布平缓,两边分布稀疏。对应地,L1正则倾向于产生稀疏模型,L2正则对权值高的参数惩罚重。
逻辑回归LR
逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型。
LR本质上还是线性回归,其实仅为在线性回归的基础上,套用了一个逻辑函数sigmoid。
逻辑曲线在z=0时,十分敏感,在z>>0或z<<0处,都不敏感,将预测值限定为(0,1)。
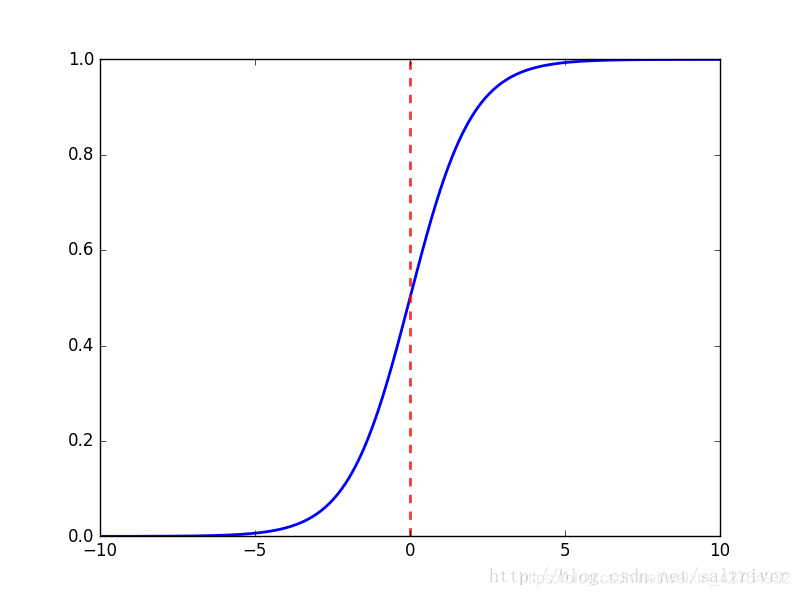
逻辑回归不是回归,是分类
交叉熵损失(极大似然损失)
满足二项分布
p
(
y
=
1
∣
x
;
w
)
=
π
(
x
)
,
p
(
y
=
0
∣
x
;
w
)
=
1
−
π
(
x
)
p(y=1|x;w)= \pi(x),p(y=0|x;w)=1- \pi(x)
p(y=1∣x;w)=π(x),p(y=0∣x;w)=1−π(x)
{
p
(
y
=
1
∣
x
;
w
)
=
e
x
p
(
w
T
x
)
1
+
e
x
p
(
w
T
x
)
p
(
y
=
0
∣
x
;
w
)
=
1
1
+
e
x
p
(
w
T
x
)
\left\{ \begin{matrix} p(y=1|x;w)= \frac{exp(w^{T}x)}{1+exp(w^{T}x)}\\ \\p(y=0|x;w)= \frac{1}{1+exp(w^{T}x)}\\ \end{matrix} \right.
⎩⎪⎨⎪⎧p(y=1∣x;w)=1+exp(wTx)exp(wTx)p(y=0∣x;w)=1+exp(wTx)1
则对于单个样本,其后验概率为:
p
(
y
i
∣
x
i
;
w
)
=
(
e
x
p
(
w
T
x
i
)
1
+
e
x
p
(
w
T
x
i
)
)
y
i
(
1
1
+
e
x
p
(
w
T
x
i
)
)
1
−
y
i
p(y_{i}|x_{i};w)=(\frac{exp(w^{T}x_{i})}{1+exp(w^{T}x_{i})})^{y_{i}}(\frac{1}{1+exp(w^{T}x_{i})})^{1-y_{i}}
p(yi∣xi;w)=(1+exp(wTxi)exp(wTxi))yi(1+exp(wTxi)1)1−yi
似然函数:
L
(
w
)
=
∏
i
=
1
m
p
(
y
i
∣
x
i
;
w
)
=
∏
i
=
1
m
(
π
(
x
i
)
)
y
i
(
1
−
π
(
x
i
)
)
1
−
y
i
L(w)= \prod _{i=1}^{m}p(y_{i}|x_{i};w)=\prod _{i=1}^{m}( \pi(x_i))^{y_i}(1-\pi(x_i))^{1-y_i}
L(w)=i=1∏mp(yi∣xi;w)=i=1∏m(π(xi))yi(1−π(xi))1−yi
对数似然函数:
l
o
g
(
L
(
W
)
)
=
∑
i
=
1
m
(
y
i
l
o
g
π
(
x
i
)
+
(
1
−
y
i
)
l
o
g
(
1
−
π
(
x
i
)
)
)
log(L(W)) = \sum_{i=1}^{m}(y_i log \pi(x_i) + (1-y_i)log(1- \pi(x_i)))
log(L(W))=i=1∑m(yilogπ(xi)+(1−yi)log(1−π(xi)))
对对数似然函数求最大值,得到
w
w
w 的极大似然估计值
w
′
w'
w′
梯度下降法
损失函数:
J ( W ) = − 1 m ( ∑ i = 1 m ( y i l o g π ( x i ) + ( 1 − y i ) l o g ( 1 − π ( x i ) ) ) ) J(W) =-\frac{1}{m}( \sum_{i=1}^{m}(y_i log \pi(x_i) + (1-y_i)log(1- \pi(x_i)))) J(W)=−m1(i=1∑m(yilogπ(xi)+(1−yi)log(1−π(xi))))
优缺点
优点:
1)预测结果是介于0和1之间的概率
2)可以适用于连续性和类别性自变量
3)容易使用和解释
缺点:
1)对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
2)预测结果呈“S”型,因此从kog(odds)向概率转化的过程是非线性的,在两端随着log(odds)值的变化,概率变化很小,边际值太小,slope太小,而中间概率的变化很大,很敏感,导致很多区间的变量变化对目标概率的影响没有区分度,无法确定阈值。
区别与联系以及其他常见问题
- 线性回归,采用的是平方损失函数。而逻辑回归采用的是 对数 损失函数
- 过拟合问题问题起源?如何解决?
模型太复杂,参数过多,特征数目过多。
方法:
1) 减少特征的数量,有人工选择,或者采用模型选择算法
2) 正则化,即保留所有特征,但降低参数的值的影响。正则化的优点是,特征很多时,每个特征都会有一个合适的影响因子。

















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









