







 该文详细介绍了使用AlexNet和ResNet50卷积神经网络模型进行裂缝识别的深度学习实践,包括数据集选择、模型构建、超参数调整及模型可视化的GradCAM算法。尽管调整了学习率、批次大小和迭代次数,模型的准确率仍停留在0.7到0.8之间,表明数据集的质量可能影响了模型性能。RestNet50在模型注意力定位上表现优于AlexNet。
该文详细介绍了使用AlexNet和ResNet50卷积神经网络模型进行裂缝识别的深度学习实践,包括数据集选择、模型构建、超参数调整及模型可视化的GradCAM算法。尽管调整了学习率、批次大小和迭代次数,模型的准确率仍停留在0.7到0.8之间,表明数据集的质量可能影响了模型性能。RestNet50在模型注意力定位上表现优于AlexNet。
深度学习实践——卷积神经网络实践:裂缝识别
系列实验
深度学习实践——卷积神经网络实践:裂缝识别
深度学习实践——循环神经网络实践
深度学习实践——模型部署优化实践
深度学习实践——模型推理优化练习
深度学习实践——卷积神经网络实践:裂缝识别
代码位于可见于https://download.csdn.net/download/weixin_51735061/88131376?spm=1001.2014.3001.5503
0 概况
方法: 实验主要通过python中的pytorch环境进行,利用了pycharm与jupyter notebook来编写代码。对于数据集,我选择了墙面裂缝数据集。基本模型选择了AlexNet,而高一级模型选择了RestNet50。模型的可视化诊断选择了CAM算法。实验主要通过调整参数的方法来进行。
步骤:
- 编辑训练代码与下载数据集
- 利用AlexNet模型进行训练并调整参数以取得较好结果
- 利用RestNet50模型进行训练并调整参数以取得较好结果
- 使用CAM算法进行可视化诊断
1 AlexNet分类
1.1 数据集选取
裂缝是一个建筑物中必有的现象,有些裂缝十分地小,需要放大很多倍才能观看到,而有些裂缝却是十分大以至于肉眼可见。一般来说大裂缝是建筑物损坏的体现,研究建筑物的裂缝具有一定的意义。传统的裂缝发现方法是通过目测进行的,而如今进入了机器学习飞速发展的时代,那么是否可以将裂缝识别交给机器呢?因此此次实验的数据集我选择了与本专业相关的裂缝数据集,数据集文件结构如下图所示。
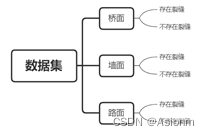
基本上此分类问题为二分类问题,数据集总共提供了5.6万张桥面、墙面、路面带裂缝与不带裂缝的数据集。由于计算机资源有限,我选择了墙面的数据集并对数据进行了平衡处理最后使用了7000张图片进行训练,墙面的部分数据如下图所示。

数据集引用:
https://www.sciencedirect.com/science/article/pii/S2352340918314082
1.2 模型构建
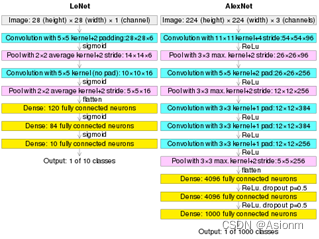
在这里我选择了12年的AlexNet作为卷积神经网络的架构,AlexNet是对LeNet的延伸,如下图为两者的网络架构图。AlexNet相比于LeNet对图片的尺寸进行了提高,同时加多了三个卷积层,同时网络复杂度均有所提高。
对于AlexNet我直接选择了pytorch里的AlexNet模型,开始时我选择了带有pretrained权重的模型,但是后面发现pretrained对训练出来的结果不利所以将pretrained改为了False其导入方式如下:
import torchvision.models as models
my_alexnet = models.alexnet(pretrained=False)
由于alexnet默认输出的有1000个种类,而裂缝数据集只有两个类别,所以需要首先更改alexnet的输出类别,其更改方式如下:
由于alexnet默认输出的有1000个种类,而裂缝数据集只有两个类别,所以需要首先更改alexnet的输出类别,其更改方式如下:
# 定位输出层位置
n_inputs = my_alexnet.classifier[6].in_features
# 输出两个种类
last_layer = nn.Linear(n_inputs, 2)
my_alexnet.classifier[6] = last_layer
微调好alexnet后,对图像进行预处理首先先修改图像的尺寸以符合模型要求,然后对图像进行裁剪进行标准化处理等。在预处理完后,剩下的就是参数调整,包括学习率、迭代次数、优化器、损失函数等等,以及结果可视化。为了更好地调整参数与可视化结果,我在本人上学期大作业的代码基础上进行了调整,得到的程序的功能图如下。
程序的构成主要如下类图所示
1.3 超参数调整
1 基础超参数
epochs为50,batch_size为32,学习率为0.1,优化器为SGD优化器,损失函数为交叉熵。基础参数训练出来的结果如下:
-
损失曲线
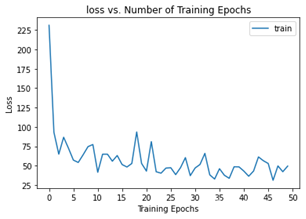
损失曲线指的是在不同epochs次数时对应的损失指,这里的损失值是训练集的损失值。下图为损失曲线图。
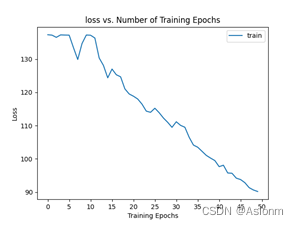
-
准确率、精确率、召回率、F1值
这里的准确率、精确率、召回率、F1值指的是测试集的值,这里的测试集从7000张数据集中产生。一开始时将完整的数据集以4:1的比例分为了两份,占比为4的为训练集,为1的是测试集。测试集不参与训练的过程,所以训练出来的模型对测试集进行预测的结果具有一定的评价意义,而下面即是结果图。
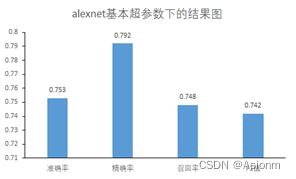
-
部分预测图像
部分预测图像是指训练出来的模型对测试集进行预测后打上标签的图像,这里取了20张进行展示,其中标红的表示识别错误,标绿的表示识别正确。
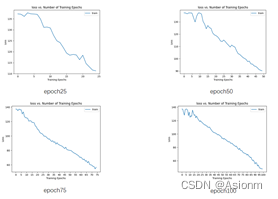
2 改变Epoch次数
查阅资料后发现,epoch次数与训练的结果具有很大的联系,因为epoch的次数越大梯度下降的次数也就越多那么权重更新地幅度也应该越大。一般来说epoch次数越大其拟合效果会越好,但是同时epoch若超过一定的范围会照成过拟合。由于epoch对结果的影响较大,所以此处选择了epoch次数作为调整的超参数之一,以下为epoch次数分别为25、50、75、100的调整结果:
-
损失曲线
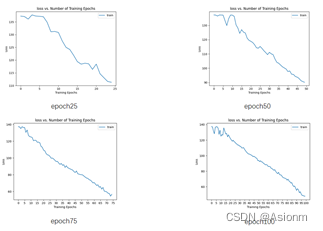
对比不同epoch次数的曲线图可以知道,随着epoch次数的增加其损失值也会随之减小,但是其减小的速率也随着次数的增加而减小。 -
准确率、精确率、召回率、F1值
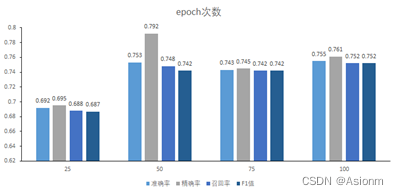
从上图可知在epoch次数为25时准确率是比较小的,而在50及以上时准确率得到了一定的提升。这说明epoch次数在一定范围内越大会使得准确率越高。然而当次数达到50以后准确率的提高不大,甚至出现了降低的现象,个人认为这可能与模型以及其他参数存在关系。而可能是这些关系阻止了准确率再次得到较大的提升。
3 改变batch size
batch_size对模型的稳定性具有一定的影响,batch_size越大其稳定性会越好训练时间也会较短,但是如果超出一定范围会使得模型的泛化能力下降。而如果batch_size较小那么就会使得梯度下降的稳定性较差让随机性越大,模型效果也会较差。由于batch_size对模型有一定的影响,所以这里我选择了batch_size作为调整的超参数之一。将batch_size分为16、32、48、64四组进行调整,其结果如下:
- 损失曲线
由图像可知随着batch size的增加,损失值也会跟着减小。这可能是由于一批的数量再不断变大而使得训练的效果更好。而图中出现批数大小越大使得曲线越不稳定的现象其实是因为刻度范围的问题,而这也可以看出batch size越大那么其一开始的损失值就会越小。 - 准确率、精确率、召回率、F1值

由上图结果可知,效果最好的出现再batsize为16的时候,而按照理论上说应该batch size较大的效果会比较好,然而这里却出现了相反的现象,当batch size达到64时其效果是最差的。这可能与batch size较大时的泛化能力较差有关。
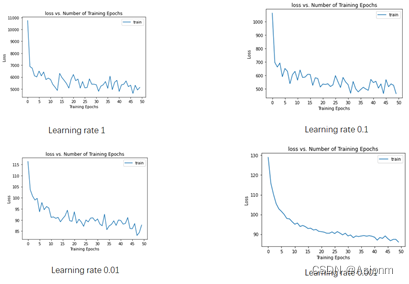
4 改变学习率
学习率对模型的收敛具有一定的影响,一般来说学习率越大模型收敛就会越快。然而如果学习率过大,那么也会造成不利的影响,因为过大会使得下降得过快而使得模型走歪路而很难找到正确的道路。现在将学习率分为1、0.1、0.01、0.001四组进行调整,其结果如下:
-
损失曲线
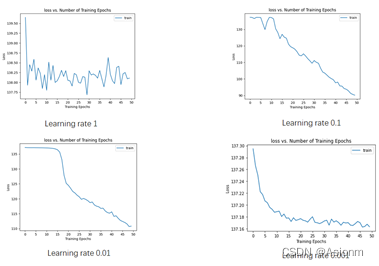 从上图可以看出,当学习率较大时比如上面的1,那么训练时埋得步长也越大,其损失值下降也越快,但是同时也会因为这样而走错了道路,使得不断折返而不断在一个损失值范围内,而无法再往低处走。而当学习率较小时,其曲线会较为平缓,但同时速度也会较慢。
从上图可以看出,当学习率较大时比如上面的1,那么训练时埋得步长也越大,其损失值下降也越快,但是同时也会因为这样而走错了道路,使得不断折返而不断在一个损失值范围内,而无法再往低处走。而当学习率较小时,其曲线会较为平缓,但同时速度也会较慢。 -
准确率、精确率、召回率、F1值
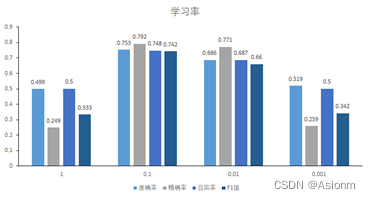
从上面的结果可以看出学习率过大与过小都是不好的,只有再一定范围内才是较好的选择。
2 RestNet50分类
2.1 模型构建
鉴于RestNet50的网络结构更复杂,深度更深,其效果理论上会越好,所以我选择了RestNet50作为高一级的模型于AlexNet进行比较。对于RestNet我直接使用了Pytorch进行调取,下面为调取的代码,
my_resnet50 = models.resnet50(pretrained=True)
# 将resnet50最后一层输出的类别数,改为ant-bee数据集的类别数,修改后改成梯度计算会恢复为默认的True
fc_inputs = my_resnet50.fc.in_features
my_resnet50.fc = nn.Sequential(nn.Linear(fc_inputs, len(self.classes)))
# 以上操作相当于固定网络全连接层之前的参数,只训练全连接层的参数
其中对其输出层进行了修改以符合数据集的特征。
2.2 超参数调整
为了与alexnet形成对比,所以超参数的调整也与alexnet的一致。
1 基础超参数:
epochs为50,batch_size为32,学习率为0.1,优化器为SGD优化器,损失函数为交叉熵。基础参数训练出来的结果如下:
-
损失曲线
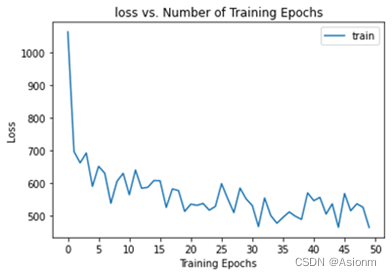
-
准确率、精确率、召回率、F1值
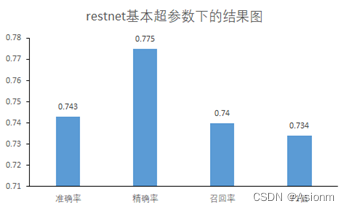
-
部分预测图像

2 改变Epoch次数
- 损失曲线
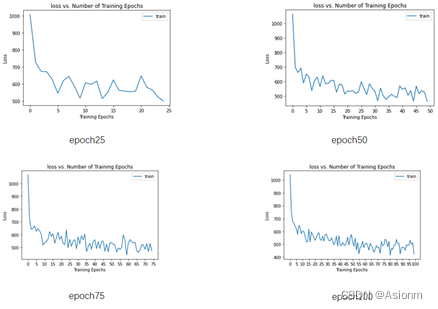
从上面的损失曲线图可知,随着Epoch次数的增加其损失值也会越小,其结果基本与AlexNet一致。 - 准确率、精确率、召回率、F1值
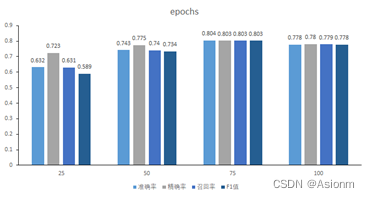
由上面结果可知,随着epoch的增加其准确率也会越高,但是当到达一定值后准确率却会降低。
3 改变Batchsize
-
损失曲线
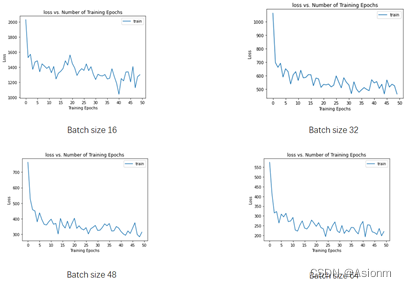
-
准确率、精确率、召回率、F1值
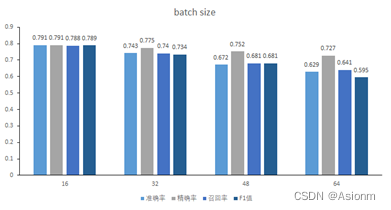
4 改变学习率
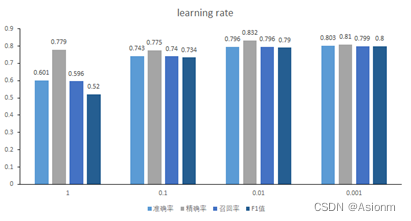
-
损失曲线
-
准确率、精确率、召回率、F1值
2.3 AlexNet与RestNet50的比较
在基础超参数的情况下,将resnet-50与alexnet进行比较,其结果如下:
- 损失曲线
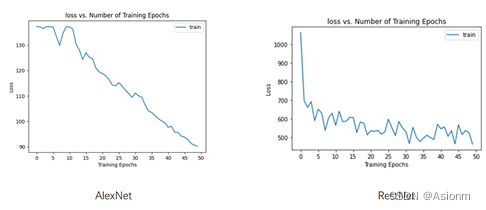
可以看到AlexNet所对应的损失值较小,都是收敛未完全,而RestNet损失值却很大,收敛较快但是稳定性较差。 - 准确率、精确率、召回率、F1值
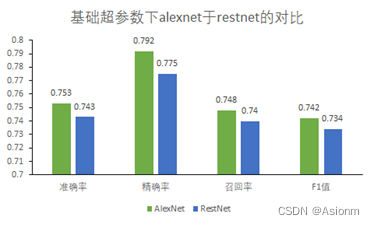
可以看到作为高级模型的resnet与alexnet对比相差不多,甚至resnet还差于alexnet。而除去基础超参数,在epoch为75时存在restnet准确率为0.8的,这也可能是基础超参数情况下resnet的参数并不太好照成了这种现象。然而观察两个模型的结果可以发现,其准确率一直都是很低的,当一开始使用alexnet时认为这可能与alexnet模型有关,但是当使用restnet这个更高级的神经网络时其结果变化不大还是很低,那么其原因可能出现与其他原因。首先应该可以排除基本的参数原因,因为参数都以不同的数值进行调试,但是其结果均不是很好。因此我从数据集中寻找原因,观察预测的数据如下所示,

可以发现判断错误的一般都是将裂缝墙体判断为无裂缝的,而仔细观察图像可以发现,判断无裂缝错误的裂缝图像的裂缝都是十分小的。甚至人眼判别都难以判别,而对于机器可能这也是其难度之一,因此造成了准确率整体偏低的现象。在发现此问题后,我观察了路面裂缝的数据集,发现其比墙面裂缝数据集较为好识别,所以我将两者在基础参数的前提下重新进行了训练,得到以下的结果:
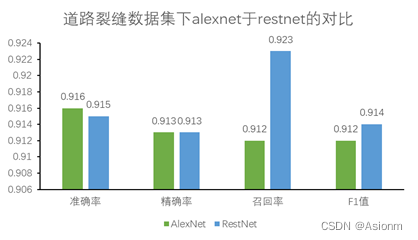
可以看到道路裂缝的准确率可以达到90%,确实比墙面的高很多,而这也证明了墙面数据集存在一定的问题。
3. 模型可视化诊断——grad_cam算法
对于模型的可视化诊断我选择了梯度权重激活图算法grad-cam,此算法能够反映出模型内部主要是靠识别哪个位置来进行分类的,也就是其注重点是如何。为了检测模型是否注意正确,现了选取三张图片,分别用前面的基本超参数下的AlexNet与ResNet对其进行预测然后对其使用Grad_CAM算法生成类激活图。下面为算法生成的结果:
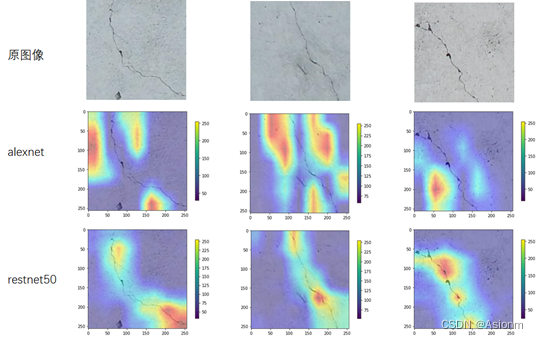
理论上来说若要识别裂缝,那么注重点肯定是在裂缝处的。而从上图可以看到,restnet50模型的CAM图明显优于alexnet的,restnet的集中位置更靠近于裂缝中,而alexnet却只是在裂缝中徘徊并未完全地对准裂缝。虽然得到的模型中两者的准确率基本差不多,但是restnet的精确性更加地好。
实验结论:
本次实验中构建了AlexNet和RestNet网络模型对裂缝数据集进行训练,并调整超参数以达到较好效果。两个网络模型的测试结果表明其在调整一系列参数如学习率、epoch次数、batchsize后准确率依然在0.7到0.8中徘徊,效果并不佳。而在比较参数为不同值的调整时,发现其规律基本与理论相符合,比如说学习率在某个范围内才是最优的。最后在利用grad_cam算法对模型进行可视化诊断时发现restnet50对裂缝的注意程度优于alexnet的,restnet50的注意点集中于裂缝处,而alexnet却只是在裂缝附近。
对于模型训练出来的效果较差,个人认为这可能与数据集有关。在观察数据集后发现,墙面裂缝的数据集的裂缝并不明显甚至人眼也难以观测出来。于是我选用了较为明显的道路裂缝数据集以检验我的想发是否正确。在经过测试后,发现路面裂缝数据集训练出来的模型准确率可以达到0.85-0.9之间,而这也说明了这确实与数据集有一定关系。


















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









