以下是使用PyTorch实现Transformer和Self-Attention的示例代码:
## Self-Attention
```python
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (self.head_dim * heads == embed_size), "Embed size needs to be divisible by heads"
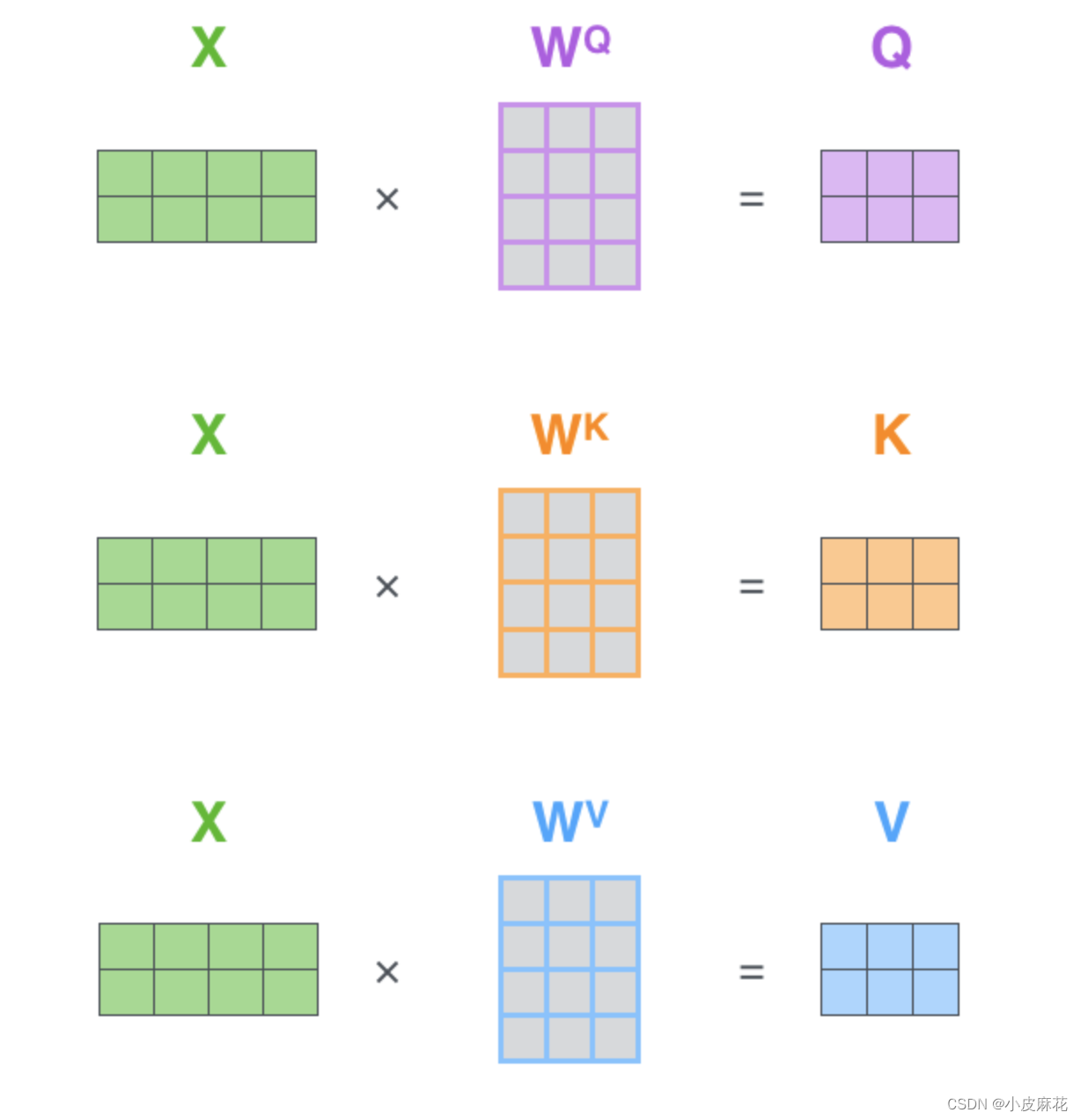
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, queries, mask):
# Get number of training examples
N = queries.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], queries.shape[1]
# Split embedding into self.heads pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = queries.reshape(N, query_len, self.heads, self.head_dim)
# Transpose to get dimensions batch_size * self.heads * seq_len * self.head_dim
values = values.permute(0, 2, 1, 3)
keys = keys.permute(0, 2, 1, 3)
queries = queries.permute(0, 2, 1, 3)
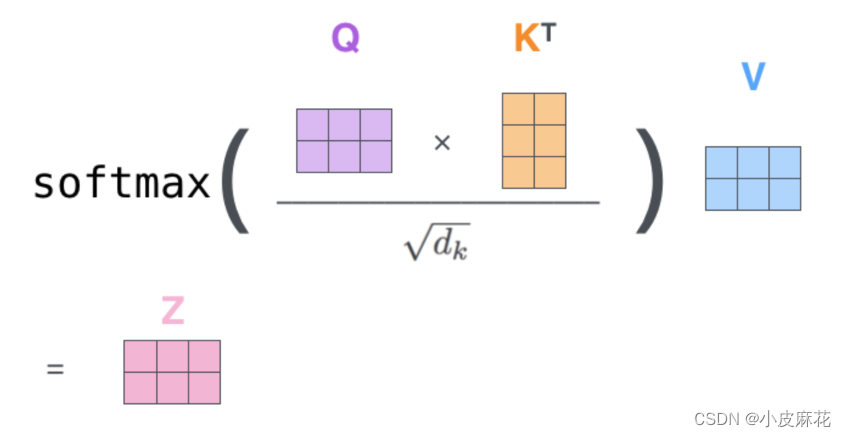
# Calculate energy
energy = torch.matmul(queries, keys.permute(0, 1, 3, 2))
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
# Apply softmax to get attention scores
attention = torch.softmax(energy / (self.embed_size ** (1/2)), dim=-1)
# Multiply attention scores with values
out = torch.matmul(attention, values)
# Concatenate and linearly transform output
out = out.permute(0, 2, 1, 3).reshape(N, query_len, self.heads * self.head_dim)
out = self.fc_out(out)
return out
```
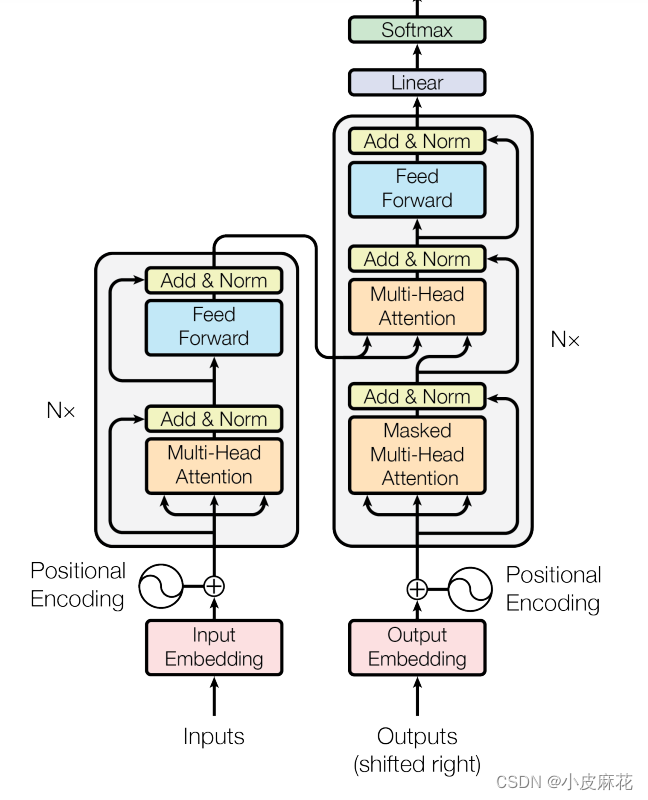
## Transformer
```python
import torch
import torch.nn as nn
from torch.nn.modules.activation import MultiheadAttention
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, dropout, forward_expansion):
super(TransformerBlock, self).__init__()
self.attention = MultiheadAttention(embed_dim=embed_size, num_heads=heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size)
)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention_output, _ = self.attention(query, key, value, attn_mask=mask)
x = self.dropout(self.norm1(attention_output + query))
forward_output = self.feed_forward(x)
out = self.dropout(self.norm2(forward_output + x))
return out
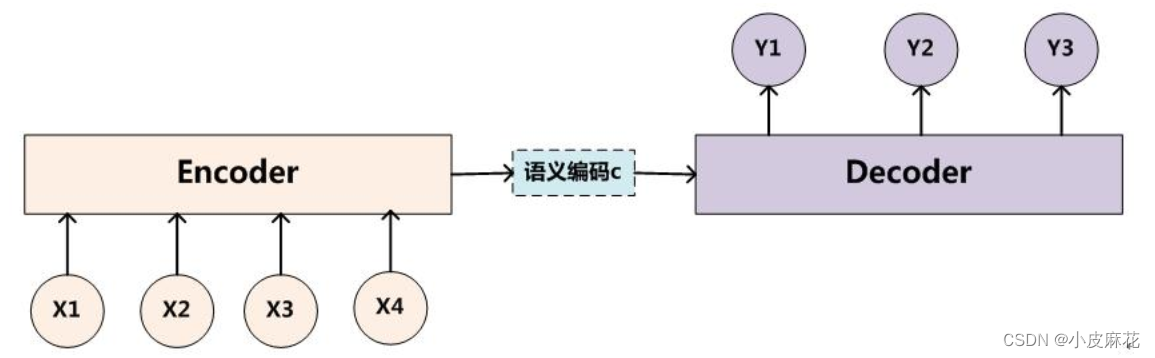
class Encoder(nn.Module):
def __init__(self, src_vocab_size, embed_size, num_layers, heads, device, forward_expansion, dropout, max_length):
super(Encoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList([
TransformerBlock(embed_size, heads, dropout, forward_expansion) for _ in range(num_layers)
])
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
return out
class DecoderBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout, device):
super(DecoderBlock, self).__init__()
self.norm = nn.LayerNorm(embed_size)
self.attention = MultiheadAttention(embed_size, heads)
self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)
self.dropout = nn.Dropout(dropout)
def forward(self, x, value, key, src_mask, trg_mask):
attention_output, _ = self.attention(x, x, x, attn_mask=trg_mask)
query = self.dropout(self.norm(attention_output + x))
out = self.transformer_block(value, key, query, src_mask)
return out
class Decoder(nn.Module):
def __init__(self, trg_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, device, max_length):
super(Decoder, self).__init__()
self.embed_size = embed_size
self.device = device
self.word_embedding = nn.Embedding(trg_vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList([
DecoderBlock(embed_size, heads, forward_expansion, dropout, device) for _ in range(num_layers)
])
self.fc_out = nn.Linear(embed_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_out, src_mask, trg_mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)
x = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
x = layer(x, enc_out, enc_out, src_mask, trg_mask)
out = self.fc_out(x)
return out
```
这些代码可以用于实现Transformer和Self-Attention模型。但这只是示例,你需要根据你的数据和任务来调整这些代码中的各种超参数和结构。






















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









