







过拟合和欠拟合
过拟合:从训练集中提取的样本特征过多,即模型的参数过多;导致模型在训练集上效果很好,在测试集很差。
欠拟合:与过拟合相反,且在训练集和测试集上效果都差
识别方法:从训练集中随机选取一部分样本作为一个验证集,采用k折交叉验证的方式,用训练集训练模型的同时在验证集上测试算法结果。在不干预拟合下,随着模型拟合能力的增强,错误率在训练集上逐渐减小,而在验证集上先减小再增大。
当两者的误差率都较大时,属于欠拟合状态;
当验证集误差率达到最低点,说明拟合效果最好,其由最低点增大时,处于过拟合状态。
选择模型的标准是使得测试误差达到最小
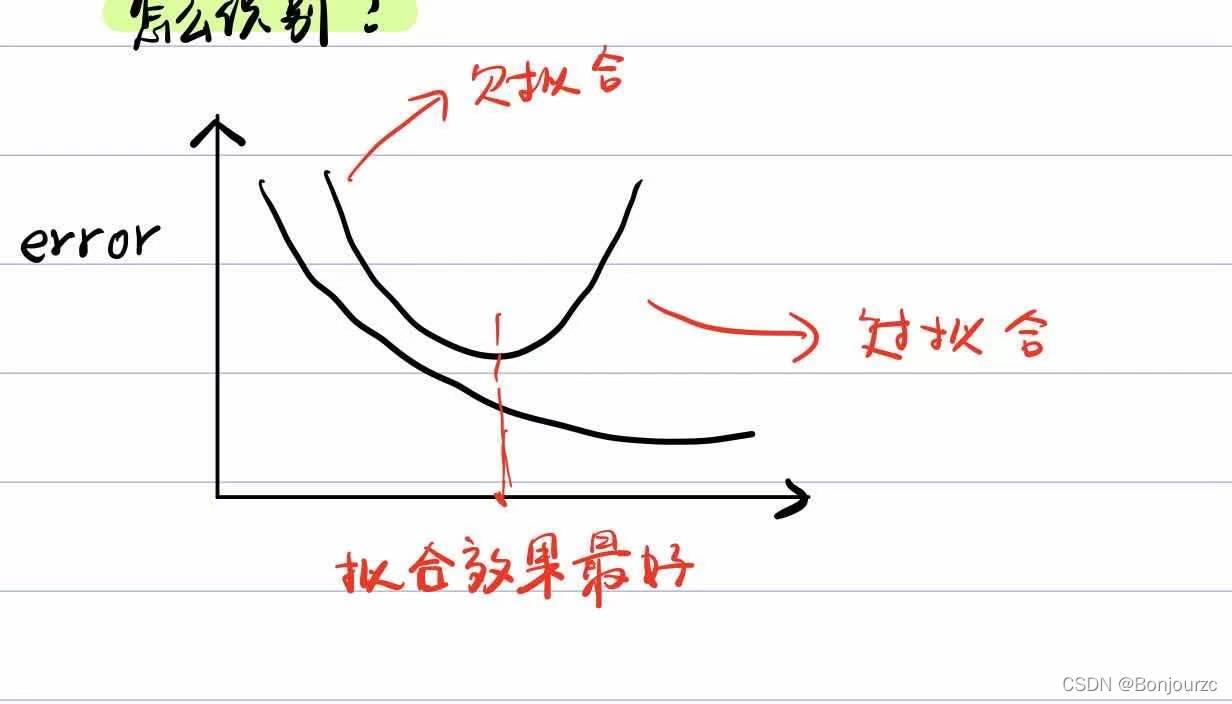
模型选择
解决/防止过拟合的方法:
目的是减少参数
1.正则化(regulation)
实现结构风险最小化的策略
即选择出经验风险与模型复杂度同时较小的模型

正则化项一般是模型复杂度的单调递增函数,可以是模型参数向量w的范数。
L1范数进行特征筛选,可以使得正则化项中的某些参数直接为0,最终选择一个稀疏模型。稀疏指的是非0参数的个数很少
L2范数防止过拟合,平方项尽可能为0,使得模型会越来越简单,但不会为0,故不会起到特征筛选的作用。加个1/2,是为了计算方便,求导可以约掉
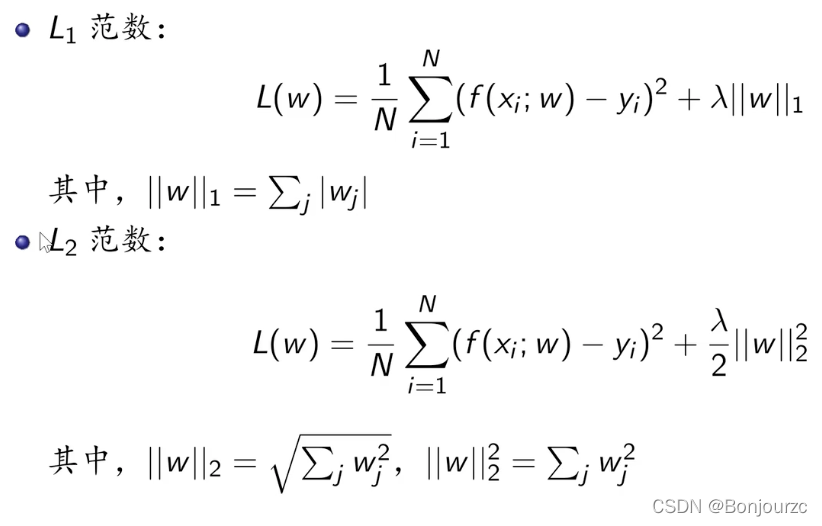
假如我们采用梯度下降算法将模型中的损失函数不断减少,那么最终损失函数不断趋近0,一定会在一定范围内求出最优解。正则化的作用是保证损失函数永不为0,经过不断优化后损失函数依然存在
以下是正则化后的损失函数,m是样本数,lambda是正则化系数,用来权衡经验风险和模型复杂度;当lambda过大时,后面部分权重增大,会导致损失函数过大,导致欠拟合,当lambda过小时,甚至为0,导致过拟合。
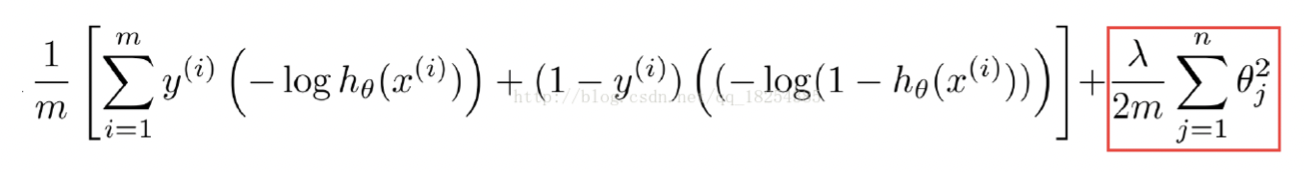
2.减少神经网络深度或者采用dropout的方法
减少神经网络的深度,参数自然减小
采用dropout的方法,是当一组参数经过某一层神经元的时候,让参数只经过一部分神经元进行计算。
3.提前停止训练,减少训练的迭代次数
4.增大训练样本的规模
5.交叉验证
数据充足的情况下,将数据集随机分为训练集,验证集,测试集
训练集用来训练模型
验证集用来选择模型(选出对验证集具有最小预测误差的模型)
测试集用来评估模型好坏
样本数据不充足情况下,采用交叉验证方法
简单交叉验证:将数据随机分为训练集和测试集(选出对测试集具有最小预测误差的模型)
k折交叉验证:将数据随机分为k个互不相交、大小相同的子集,以k-1个子集作为训练集,剩下的一个子集作为测试集。将这一过程的K种选择重复进行,选出k次测评中平均测量误差最小的模型。
留1交叉验证:k=样本容量,数据极度缺乏时使用
算法
指的是学习模型的具体计算方法
统计学习或者叫机器学习是根据学习策略,基于训练数据集,从假设空间中选取最优模型,最后考虑用什么算法求解出最优模型。
统计学习问题归结为最优化问题,统计学习的算法就是最优化问题的算法。
若该统计学习问题具有显式解析解,算法简易
但通常并不存在解析解,故需要采用数值计算方法 找到全局最优解,比如梯度下降法。
模型评估:训练误差与测试误差
训练误差:是模型Y关于训练数据集的平均损失,对已知数据的预测能力
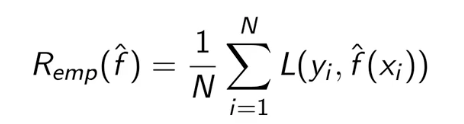
测试误差:是模型Y关于测试数据集的平均损失,未知
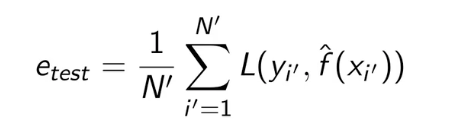
误差率: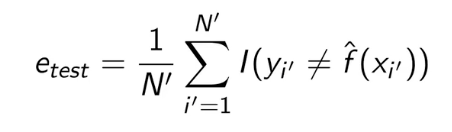
准确率:
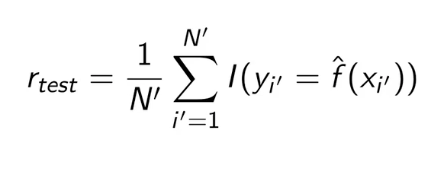
误差率+准确率=1















 5779
5779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









