







泛化能力
指的是学习方法的泛化能力,而不是学习到的模型的泛化能力。
是学习所得到模型对于新数据的预测能力,是学习方法本质上重要的性质
我们一般会采用测试数据集评价学习方法的泛化能力,但是这种评价只依赖于测试数据集,所以得出的评价结果可能是不可靠的。
故统计学习方法试图从理论上对学习方法的泛化能力进行分析。
泛化误差
反应了学习方法的泛化能力,是学习所得到的模型对于新数据预测的误差,其实就是所学习到的模型的期望风险。
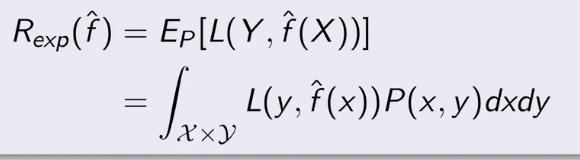
泛化误差越小的模型越有效。
二维随机变量的数学期望?
泛化误差上界
学习方法的泛化能力的研究通常是通过研究泛化误差的概率上界进行的。通过比较两种学习方法的泛化误差上界来比较他们的优劣。

不等式左边是泛化误差;右边是泛化误差上界,第一项是训练误差,d是假设空间中函数个数,N是样本容量
为什么不用泛化误差?因为泛化误差上界具有优良性质。
假设空间容量就是可能取得模型个数
生成模型和判别模型
generative model:由数据先学习联合分布概率,进而根据条件概率公式得到条件概率分布
典型的生成模型有:朴素贝叶斯法、隐马尔可夫模型
discriminative model:由数据直接学习决策函数或者条件概率分布
典型的判别模型有:k近邻法、感知机、决策树等

监督学习的应用
分类问题
标注问题
回归问题
F1score是精确率和召回率的调和均值

输出变量是有限个取值的时候是分类问题
输入和输出变量是变量序列的时候是标注问题
输入和输出变量是连续变量的时候是回归问题















 3819
3819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









