







 本文详细介绍了Linux中MySQL的配置、数据类型、SQL操作、表设计原则(如范式理论)、CRUD操作、索引优化、分页查询和排序方法,以及如何提高查询效率。
本文详细介绍了Linux中MySQL的配置、数据类型、SQL操作、表设计原则(如范式理论)、CRUD操作、索引优化、分页查询和排序方法,以及如何提高查询效率。
一个库对应一个文件夹,一个文件夹对应表的结构,表的存储。还有init配置文件
Linux的配置文件是 .Cnf
开启:Mysql –h ip –p 端口 –u
浮点类型推荐使用deciomal类型(保存为字符串格式)
整数类型、浮点数类型、字符串类型
整形(M)表示证书显示的宽度
字符串(M)表示字符串的字节大小
二进制:BLOB字符串类型:表示允许长度0~65535,值的长度是+3字节
文本:TEXT
数据库中字符串都是用单引号括起来
日期时间类型
Enum和set :都是限制该字段只能取固定的值,但是枚举字段只能取一个唯一的值,而集合字段可以取任意个值
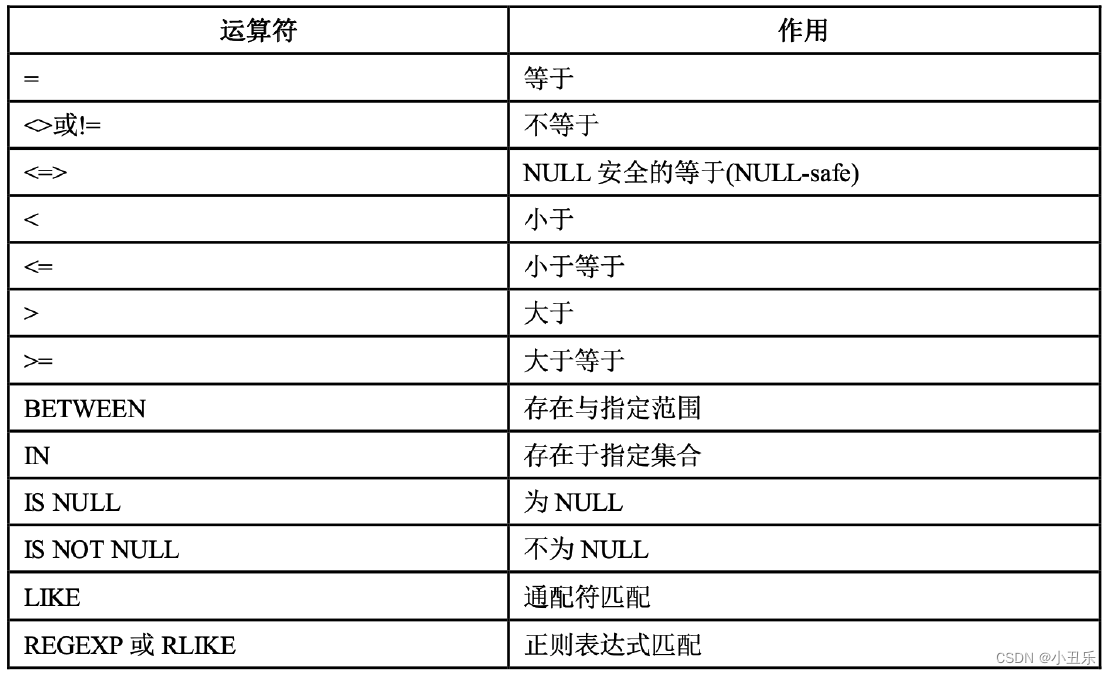
运算符


通配符
Like,* _ %

MySQL完整性约束
主键约素:primary key
自增健约束:auto_increament
唯一健约束:unique key
非空约束:not null
默认值约束: default
外键约束:foreign key
关系型数据库表设计
表设计需要表这个实体,表的实体之间的关系
1)一对一

2)一对多,多对多只要告诉我们表与表的关联,不管理表与表的冗余
特点:减少数据冗余(主要好处,其他好处由此附带的),消除异常(插入异常、更新异常、删除异常),让数据组织的更加和谐
数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的机率就大,SQL的效率就变低
第一范数(1NF):每一列保持原子特性,是基本数据项,不能再进行分割了
第二范式(2NF):属性完全依赖于主键——主要针对联合主健
非主属性完全依赖主关键字,如果不是完是全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
比如选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),(学号,课程名称)是联合主键,但是学分字段只和课程名称有关,和学号无关,相当于只依赖联合主键的其中一个字段,不符合第二范式
第三范式(3NF):属性不依赖与其他非主属性(要求一个数据库表中不包含已在其他表中已包含的非主关键字信息)
不全都依赖于主属性,且非主属性之间也存在相互依赖
BC范式:每个表只有一个候选健
第四范式:消除表中的多值依赖
MYSQL
SQL是结构化查询语句,是关系型数据库的通用语言
SQL主要划分以下3个类别:
DDL:数据定义语句
DML:数据操纵语句(用于添加、删除、更新和查询数据库记录,并检查数据的完整性)
DCL:数据控制语句:用于控制不同的许可和访问级别的语句。语句关键字包括grant、revoke
进入root用户: su root
Netstat –tanp 查看状态,mysql是否在开启状态
Exit退出root用户
Mysql –u root –p打开mysql
库操作
查询数据库:show databases
创建数据库:create database chatDB
删除数据库:drop database ChatDB
选择数据库:use ChatDB
表操作
选择库:use 库名
显示库表:show table
展示表结构:desc user;
删除表:drop table user;
查看建表sql:show create table user\G
CRUD操作(增加、修改、删除,查询)
insert增加
insert into user(name,age,sex)values(‘zhangsan’,20, ‘M’)
insert into user(nickname, name, age, sex) values('fixbug', 'zhang san', 22,
'M');
insert into user(nickname, name, age, sex) values('666', 'li si', 21, 'W'),
('888', 'gao yang', 20, 'M');
两种方式的插入数据的结果都是一样的,不同是?

每一条SQL指令都要进行一次tcp网络通信。区别就在这里(对应数据库链接池项目)
Update更新
Update user set age=23 where name =’ Zhang’
Delete删除
Delete from user where age=23
Select查询
回表:
select * from user; 利用*通配符来查找所有的字段
下划线_表示通配一个字符,%表示所有的字符
select id,nickname,name,age,sex from user;
select id,name from user;
select id,nickname,name,age,sex from user where sex='M' and age>=20 and age<=25;
select id,nickname,name,age,sex from user where sex='M' and age between 20 and
25;
select id,nickname,name,age,sex from user where sex='W' or age>=22;
select distinct name from user; //去重distinct
空值查询
is [not] null
select * from user where name is null;
带in子查询
select * from user where id in(10, 20, 30, 40, 50) 在这个列表里面的
select * from user where id not in(10, 20, 30, 40, 50)
select * from user where id in(select stu_id from grade where average>=60.0)
union合并查询
SELECT country FROM Websites UNION ALL SELECT country FROM apps ORDER BY
country;
分页查询
select id,nickname,name,age,sex from user limit 10;
select id,nickname,name,age,sex from user limit 10 of 2000; 和下面一句是一样的
select id,nickname,name,age,sex from user limit 2000,10;
后面10表示只显示整个表的前10个(理解为偏移0个)
2000,10 表示偏移2000个,然后在取10个

Limit解释:
Explain:查看
show create table user\G 展示表格元素特点
explain select * from user where name = 'WZ' 查看某个条件执行计划。有索引的执行次数都是一次。
但是explain是查看不到limit的执行的
聚合函数:count 、sum、 avg、max、min
分页操作:(分页显示效率较低)
定义一页显示多少行:Pagenum
Pageno:页码
Select * from limit (pageno-1)*pagenum, pagenum;
效率低的原因在于偏移
改进:select * from user where id>上页最后一条数据的id limit 20
在没有索引的情况下,利用limit可以提高数据提取的效率。这个效率受到偏移数据的影响
Order by排序
select id,nickname,name,age,sex from user where sex='M' and age>=20 and age<=25
order by age asc;
不写这个asc默认升序 asc为升序
select id,nickname,name,age,sex from user where sex='M' and age>=20 and age<=25
order by age desc; desc为降序
排序的原则是:如果前一个字段相同,按照第二个字段进行,以此类推
Using filesort(外排序)需要进行优化
Using index 用索引
Order by的性能不仅与字段是否为索引有关,还与select选的字段有关,因为牵扯到是否回表等有关:
特点:给查询的字段加索引,对字段是用一个字段过滤还是用多个字段过滤
















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









