






目录
6.sort by 和 order by 的区别 其他两种排序?
10.请谈一下Hive的特点,Hive和RDBMS有什么异同?
13.Hive中追加导入数据的4种方式是什么?请写出简要语法
1.hive内部表和外部表的区别
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse), 外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上 的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存 放在这里);
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
2.Hive有索引吗
Hive支持索引(3.0版本之前),但是Hive的索引与关系型数据库中的索引并不相同。并且 Hive索引提供的功能很有限,效率也并不高,因此Hive索引很少使用。
索引适用的场景:
适用于不更新的静态字段。以免总是重建索引数据。每次建立、更新数据后,都要重建索 引以构建索引表。
3.运维如何对hive进行调度
将hive的sql定义在脚本当中;
使用azkaban或者oozie进行任务的调度;
监控任务调度页面。
4.ORC、Parquet等列式存储的优点

存储压缩方面 ORC压缩比例最优 Parquet压缩性能最优
两者是压缩中比较好的,使用ORC读取的行远小于Parquet,所以使用ORC作为存储,可以借助元数据过滤掉更多不需要的数据,查询时需要的集群资源比Parquet更少
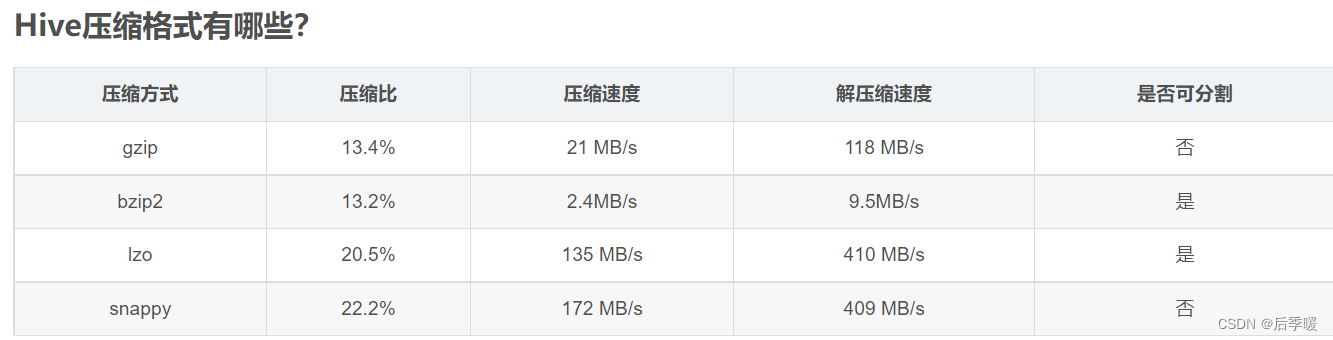

在实际生产中,使用Parquet存储,lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。
但是,如果数据量并不大(预测不会有超大文件,若干G以上)的情况下,使用ORC存储,snappy压缩的效率还是非常高的。
5.为什么要对数据仓库分层
用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据。如果不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。
6.sort by 和 order by 的区别 其他两种排序?
sort by是组内有序 如果reduce数量为1 则和全局排序一样。
作用:每个Reducer内部进行排序,对全局结果集来说不是排序。
sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
order by为全局排序 适用于只有一个reducer
distribute by通常和sort by一起用 保证最后输出的是分区内排好序的
如果distribute by和sort by的字段相同 则可以只用一个cluster by来代替
7.数据倾斜
Hive数据倾斜常见场景及解决方案(超全!!!)_后季暖的博客-CSDN博客_hive的数据倾斜场景
8.Hive 小文件过多怎么解决
使用 hive 自带的 concatenate 命令,自动合并小文件
调整参数减少Map数量
减少Reduce的数量
使用hadoop的archive将小文件归档
9.Hive的两张表关联,使用MapReduce怎么实现?
如果其中有一张表为小表,直接使用map端join的方式(map端加载小表)进行聚合。
如果两张都是大表,那么采用联合key,联合key的第一个组成部分是join on中的公共字段,第二部分是一个flag,0代表表A,1代表表B,由此让Reduce区分客户信息和订单信息;在Mapper中同时处理两张表的信息,将join on公共字段相同的数据划分到同一个分区中,进而传递到一个Reduce中,然后在Reduce中实现聚合。
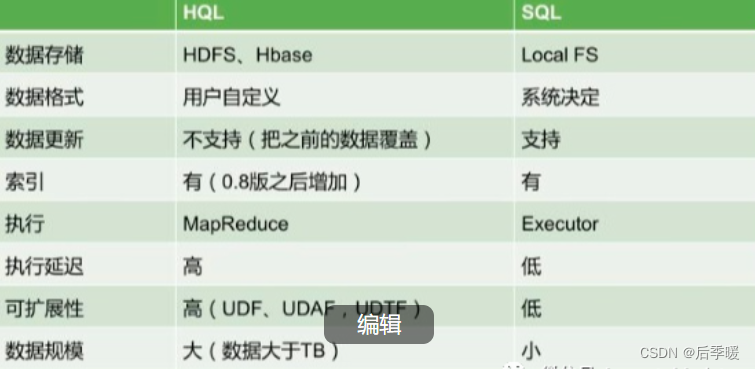
10.请谈一下Hive的特点,Hive和RDBMS有什么异同?
11.Hive的函数:UDF、UDAF、UDTF的区别?
-
UDF:单行进入,单行输出
-
UDAF:多行进入,单行输出
-
UDTF:单行输入,多行输出
12.说说对Hive桶表的理解?
桶表是对数据某个字段进行哈希取值,然后放到不同文件中存储。
数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和reduce任务个数相同。
桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
13.Hive中追加导入数据的4种方式是什么?请写出简要语法
从本地导入: load data local inpath ‘/home/1.txt’ (overwrite)into table student;
从Hdfs导入: load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
查询导入: create table student1 as select * from student;(也可以具体查询某项数据)
查询结果导入:insert (overwrite)into table staff select * from track_log;
14.谈谈侧视图?
Hive建表(三)侧视图(Lateral View)_天ヾ道℡酬勤的博客-CSDN博客_hive侧视图
15.Union和Union all:
(1)Union:对两个结果集进行并集操作,去除重复行,同时进行默认规则的排序。
(2)Union all:对两个结果集进行并集操作,不去除重复行,不进行排序。
16.常用窗口函数
OVER():用于指定分析函数工作时的数据窗口大小,这个数据窗口大小可能会随着行的变而变化;
CURRENT ROW:当前行;
n PRECEDING:往前n行数据;
n FOLLOWING:往后n行数据;
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点;
LAG(col,n,default_val):往前第n行数据;
LEAD(col,n, default_val):往后第n行数据;
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。这个函数需要注意:n必须为int类型。
17.谈谈UDF、UDAF、UDTF?
当Hive自带的函数无法满足我们的业务处理需求时,hive允许我们自定义函数来满足需求。
根据自定义函数的类别分为以下三种:
UDF:User-Defined-Function,用户自定义函数,数据是一进一出,功能类似于大多数数学函数或者字符串处理函数;
UDAF:User-Defined Aggregation Function,用户自定义聚合函数,数据是多进一出,功能类似于 count/max/min;
UDTF:User-Defined Table-Generating Functions,用户自定义表生成函数,数据是一进多处,功能类似于lateral view explore();
-
自定义UDF函数
- 继承org.apache.hadoop.hive.ql.UDF函数;
- 重写evaluate方法,evaluate方法支持重载。
18.hive做过什么优化?
19.用HiveSQL计算连续天数问题的方法
以下例子注意 如果一天能登录多次 应当将row_number换成dense_rank!!
Hive计算最大连续登陆天数_尚硅谷铁粉的博客-CSDN博客_hive 连续登陆最长天数一、背景在网站平台类业务需求中用户的「最大登陆天数」,需求比较普遍。原始数据:u0001 2019-10-10u0001 2019-10-11u0001 2019-10-12u0001 2019-10-14u0001 2019-10-15u0001 2019-10-17u0001 2019-10-18u0001 2019-10-19u0001 2019-10-20u0002 2019-10-20说明:数据是简化版,两列分别是user_id,log_in_date。现实情况需要从 https://blog.csdn.net/zjjcchina/article/details/121264726
https://blog.csdn.net/zjjcchina/article/details/121264726
hadoop面试题链接:大数据常见面试题 Hadoop篇(1)_后季暖的博客-CSDN博客
mysql面试题链接:大数据面试重点之mysql篇_后季暖的博客-CSDN博客
















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











