







文章目录
一、算法简介
朴素贝叶斯法(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。
👇👇👇
朴素贝叶斯是基于概率论的分类算法。

带你理解朴素贝叶斯分类算法/知乎@忆臻
摘录👇👇👇
对的!这也就是为什么朴素贝叶斯分类有朴素一词的来源,朴素贝叶斯算法是假设各个特征之间相互独立,那么这个等式就成立了!
24个,计算机扫描统计还可以,但是现实生活中,往往有非常多的特征,每一个特征的取值也是非常之多,那么通过统计来估计后面概率的值,变得几乎不可做,这也是为什么需要假设特征之间独立的原因。
我们就需要在嫁的条件下,去找四种特征全满足分别是不帅,性格不好,身高矮,不上进的人的个数,这样的话,由于数据的稀疏性,很容易统计到0的情况。 这样是不合适的。
根据上面俩个原因,朴素贝叶斯法对条件概率分布做了条件独立性的假设,由于这是一个较强的假设,朴素贝叶斯也由此得名。这一假设使得朴素贝叶斯法变得简单,但有时会牺牲一定的分类准确率。
二、算法优缺点
朴素贝叶斯的主要优点有:
-
朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
-
对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
-
对缺失数据不太敏感,算法也比较简单,常用于文本分类。
朴素贝叶斯的主要缺点有:
-
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
-
需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
-
由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
-
对输入数据的表达形式很敏感。
三、应用场景
暂无
四、示例代码
C++(未精读)
C++ 朴素贝叶斯模型(Naive Bayesian Model,NBM)实现, 西瓜实验数据集 基于周志华老师机器学习/CSDN@Elijah_Yi
Java(须微调)
Python(ChitGPT微调:西瓜数据3.0-[‘密度’][‘含糖量’],∵转object类型也报错KeyError,索性删除属性)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
#数据集
def createDataSet():
"""
创建测试的数据集,里面的数值中具有连续值
:return:
"""
dataSet = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
# 特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感','类别']
# 特征对应的所有可能的情况
labels_full = {}
for i in range(len(labels)):
labelList = [example[i] for example in dataSet]
uniqueLabel = set(labelList)
labels_full[labels[i]] = uniqueLabel
return dataSet, labels, labels_full
#实例化
data, labels, labels_full = createDataSet()
#list转dataframe
df = pd.DataFrame(data, columns=labels)
#df['密度'] = df['密度'].astype(str)
#df['含糖率'] = df['含糖率'].astype(str)
# 划分训练集和测试集
train_data, test_data = train_test_split(df, test_size=0.3, random_state=1)
# 计算P(c),即先验概率,好瓜/总数,坏瓜/总数(待测数据集中)
def calc_pc(train_data):
pc = {}
for i in train_data['类别'].unique():
pc[i] = (train_data['类别']==i).sum() / train_data.shape[0]
return pc
# 计算P(x|c),即条件概率,例:pxc[好瓜][属性(色泽)]= {'浅白': 0.25, '乌黑': 0.25, '青绿': 0.5} 1/4 1/4 2/4
def calc_pxc(train_data):
pxc = {}
for c in train_data['类别'].unique():
pxc[c] = {}
for column in train_data.columns[:-1]:
pxc[c][column] = {}
for value in train_data[column].unique():
pxc[c][column][value] = \
((train_data[column]==value) & (train_data['类别']==c)).sum() \
/ (train_data['类别']==c).sum()
return pxc
# 计算P(x),即某个属性占待测数据集总数,px['色泽']['青绿']=5/11=0.45454545454545453
def calc_px(train_data):
px = {}
for column in train_data.columns[:-1]:
px[column] = {}
for value in train_data[column].unique():
px[column][value] = (train_data[column]==value).sum() / train_data.shape[0]
return px
# 计算train_data的P(c)、P(x|c)和P(x)
pc = calc_pc(train_data)
pxc = calc_pxc(train_data)
px = calc_px(train_data)
# 对被测试集进行分类
def classify(test_data, pc, pxc, px):
y_pred = []
for i in test_data.index: #测试集Index=3, 13, 7, 2, 6, 10
p = {}
for c in pc.keys(): #c='好瓜' c='坏瓜'
p[c] = pc[c] #pc['好瓜']=4/11=0.3636(训练集)
#p['好瓜']=0.36 p['坏瓜']=0.63
for column in test_data.columns[:-1]: #每个属性名
p[c] *= pxc[c][column][test_data.loc[i, column]] / px[column][test_data.loc[i, column]]
#test_data.loc[i,column]=取出该索引对应的属性值
#pc *= pxc/px
y_pred.append(max(p, key=p.get))
return y_pred
# 对测试集进行分类,参数是train_data的。
y_pred = classify(test_data, pc, pxc, px)
# 计算分类准确率
acc = (y_pred==test_data['类别']).sum() / test_data.shape[0]
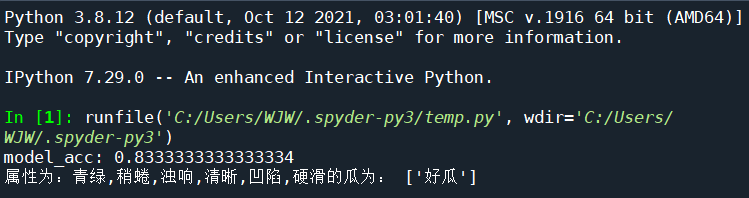
print('model_acc:', acc)
#青绿,稍蜷,浊响,清晰,凹陷,硬滑
data_need_pred = [['青绿', '稍蜷', '浊响', '清晰', '凹陷', '硬滑']]
labels_need_pred = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
df_need_pred = pd.DataFrame(data_need_pred, columns=labels_need_pred)
c_need_pred = classify(df_need_pred, pc, pxc, px)
print('属性为:青绿,稍蜷,浊响,清晰,凹陷,硬滑的瓜为:',c_need_pred)
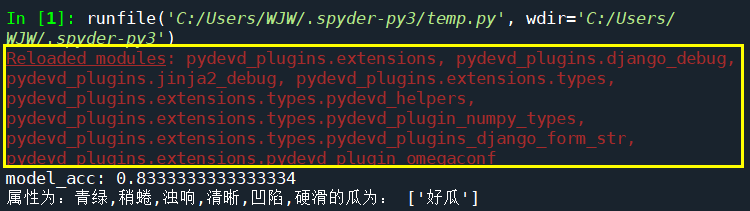
❌一个小报错:Reloaded modules:
Spyder 中 Reloaded modules错误的解决方法/CSDN@w王大妞👇
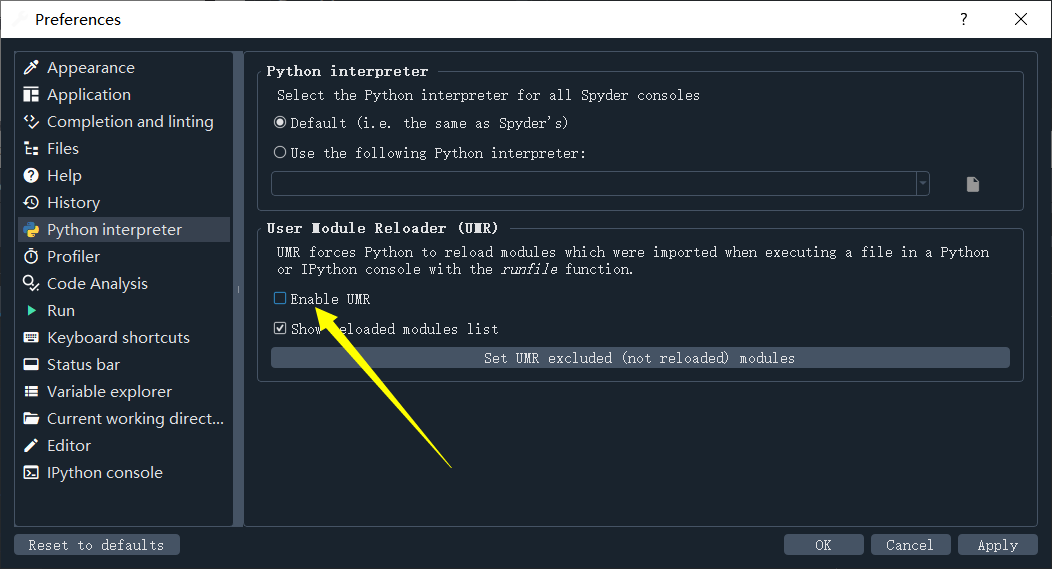
Tools->Preferences->Python interpreter->User Module Reloader (UMR),将Enable UMR的选项取消
Reference
👇👇👇暂时没反应过来















 649
649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









