







前言:
由于上轮学习中,感觉到OCR库挺好玩的,但没有了解很多,这次找到另一本书《Python网络爬虫权威指南》,在这里有比较多的相关内容能够了解到。它从好几个方面进行讲解。
模块:
-
OCR库的概述
-
安装pytesseract
-
结合PIL使用pytesseract
from PIL import Image import pytesseract-
读取文字 返回OCR结果
image = Image.open('picture/code2.jpg') print(pytesseract.image_to_string(image)) # print(pytesseract.image_to_string(image), lang='fra') # 法语文本 -
估计每个字符的边界的像素位置
result2 = pytesseract.image_to_boxes(image) """ OUTPUT: w 8 5 23 14 0 4 22 5 33 17 0 C 33 5 46 17 0 Z 43 5 58 17 0 """
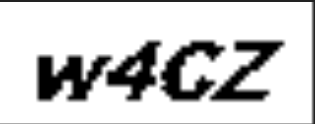
-
置信分数、页数、行数、像素位置数据等等…
result3 = pytesseract.image_to_data(image) """ OUTPUT: level page_num block_num par_num line_num word_num left top width height conf text 1 1 0 0 0 0 0 0 64 25 -1 2 1 1 0 0 0 8 8 50 12 -1 3 1 1 1 0 0 8 8 50 12 -1 4 1 1 1 1 0 8 8 50 12 -1 5 1 1 1 1 1 8 8 50 12 27 w4CZ """ -
输出字典 or 在不能够进行UTF-8解码的时候输出字节字符串
from pytesseract import Output result1_out = pytesseract.image_to_string(image, output_type=Output.DICT) # 参数中 加上lang='chi_sim' 识别简体中文,但是感觉效果并不是很好 print(result1_out) """ OUTPUT:可以发现识别过程中,还是有杂质的 {'text': 'w4CZ\n\x0c'} """ result2_out = pytesseract.image_to_string(image, output_type=Output.BYTES) print(result2_out) """ OUTPUT: b'w4CZ\n\x0c' """
-
书中提到,pytesseract库很方便,但仍然实现不了Tesseract的部分功能;因此书中回将其和,命令行Tesseract结合起来,并从Python通过subprocess库触发Tesseract。最好熟悉所有这些方法。
-
-
处理格式规范的文字(标准字体、清晰、整齐、不超出图片范围)
-
利用阈值过滤器清晰图片
如果背景不干净,使得比较难以识别,就要python脚本进行清洗图片。
另外:那些带有标题的、大片空白的图片都应该进行预处理
# 这串代码在上一篇出现过,不过有略微不同,这个过滤器更加方便,使用匿名函数lambda image = image.point(lambda x:0 if x < 130 else 255) """ OUTPUT:上边的图就是了 """ # 这样会更加清晰 # 使用pillow 库 预处理图片会使得效果更好 -
自动调整图像
上方的阈值:130 是作为离想的阈值来将图像像素调整为黑色或者白色。但并不适用所有图像,当图像多的时候,不能够一一调整。
如何选择比较好的阈值:根据Tesseract能够读取的字符\字符串数量和置信值的某种组合衡量。
迭代算法(具体那种算法会因应用不同而有差异)
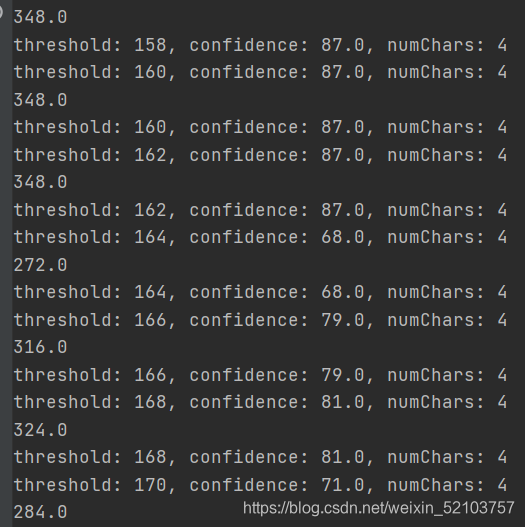
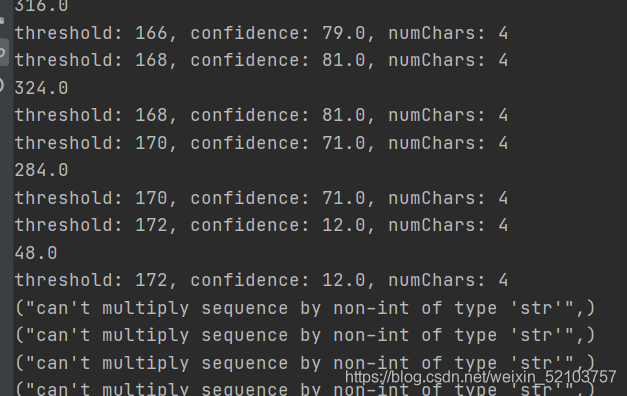
改代码对书中源代码进行小改动: 1、封装;2、异常处理;3、增加置信率和字符串个数的乘积数值显示
""" 思路: 给阈值范围[80, a2, step] 从一个不干净的图片开始,利用 80 作为阈值返回图像对象 for 改变阈值 将此对象通过Tesseract运行,计算每个识别字符串的平均置信值(通过字符串中字符的数量统计,以及识别字符数量) 输出数据 选择最优组合 """ from PIL import Image from pytesseract import Output import pytesseract import numpy as np class ImagePreprocess(object): def __init__(self, start=130, step=2, end=180): self.start = start self.end = end self.step = step def cleanFile(self, threshold=None, filePath=None): assert threshold is not None,"threshold should be set" # 断言 image = Image.open(filePath) # 打开图片 image = image.convert('L') # 转灰度 这一点对于后边的二值化处理会有影响 return image.point(lambda x:0 if x < threshold else 255) # 返回二值化处理的图片 def getConfidence(self, image=None): # 获取图片的各类数据,主要是用到图片识别出来的 文本text 置信值 data = pytesseract.image_to_data(image, output_type=Output.DICT) text = data['text'] confidences = [] numChars = [] for i in range(len(text)): # 这里每一个字符串都会有自己的一个置信值,空则为-1 if int(data['conf'][i]) > -1: confidences.append(data['conf'][i]) # 记录置信值 numChars.append((len(text[i]))) # 记录字符串长度 # 返回加权置信值(利用字符串长度作为权重) 和 识别的字符串个数 try: return np.average(confidences, weights=numChars), sum(numChars) except: return "ERROR HERE", "ERROR HERE" def generator_excute(self, image=None): assert image is not None,"image_path should be set" # 执行函数 for threshold in range(self.start, self.end, self.step): new_image = self.cleanFile(threshold, image) scores = self.getConfidence(new_image) try: print("threshold: "+str(threshold)+", confidence: "+str(scores[0])+", numChars: "+str(scores[1]),'\n'+str(scores[0]*scores[1])) # 打印乘积 except Exception as R: print(R.args) if __name__ == '__main__': mission = ImagePreprocess() # 初始化一个类 mission.generator_excute('picture/code.jpg') # 执行 这里换了图片 """ OUTPUT:见图片 """ """ 解析: 由此可以发现,有时候依旧不能再局部最佳(至少很不错的)阈值设置中得到正确的文字预测 而有时,字符长度多的也不一定是最优阈值设置,因为可能图像中的随机噪声被解释成了实际不存在的字符 如果置信值比较高,缺少的字符长度极少(猜测:要看与原文的字符个数的占比),才是局部最优(至少是很不错的)阈值 那么如何进行采取呢? 这里的阈值选择法科恩那个是置信率*字符量的乘积的最大值。或者是其他指标 为了减少时间复杂度选择到理想阈值 1、可能会选择比较合适的阈值区间,例如:130~180之间进行迭代 2、步长先放大到20,根据一个明显的数值峰来改变阈值的初始值和结束值并且调小步长(也就是利用贪心来寻找最佳阈值) """

-
- 省略 在网站图片中抓取文字 的小节。
---
在下一节,将会记录
- 读取验证码与训练Tesseract
- 读取验证码并提交答案















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











