







初学者可能无法直接找到视频的url,因为b站采取的是音频和视频分开的模式(.m4s).
找到url
这里我先随便找一个url
https://www.bilibili.com/video/BV15x41167kg?from=search&seid=2782960511092264812&spm_id_from=333.337.0.0
删减一下:
https://www.bilibili.com/video/BV15x41167kg
开打chrome开发者工具,播放视频的同时,发现以下包被慢慢加载出来了。
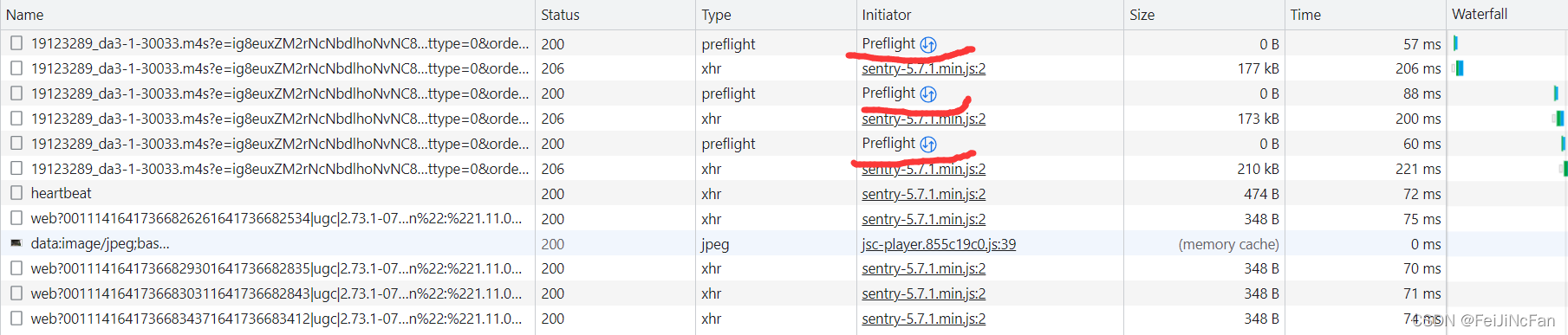
然后点击这个包,分析一下。
https://upos-sz-mirrorkodo.bilivideo.com/upgcxcode/89/32/19123289/19123289_da3-1-30033.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1641743855&gen=playurlv2&os=kodobv&oi=3078708767&trid=0de42e0be49a4dc69609cb1035cbf0cbu&platform=pc&upsig=2850f621cc720503c5852104e95d1b27&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=699964101&bvc=vod&nettype=0&orderid=0,3&agrr=0&bw=33019&logo=80000000
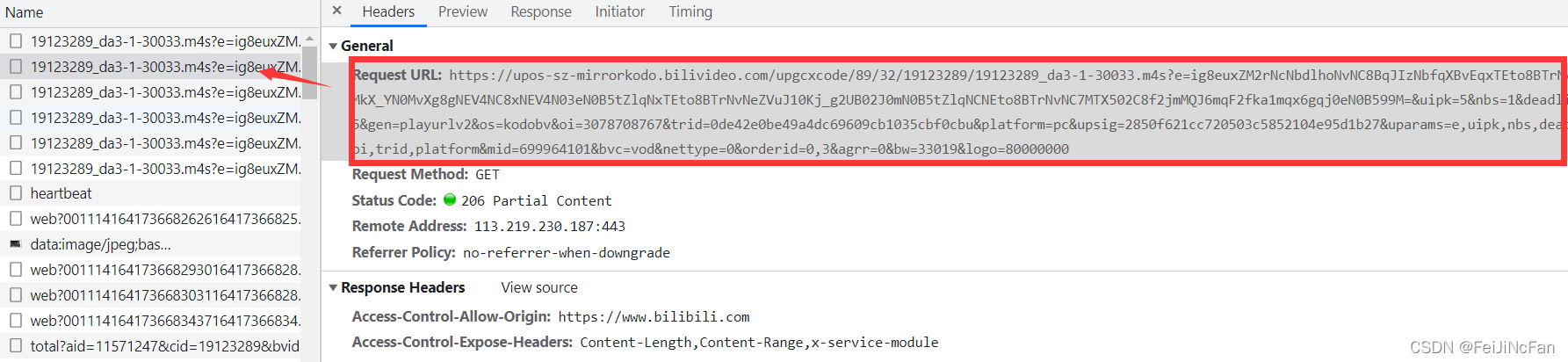

直接访问对应的url,会显示不存在,但是我们很清楚就是从这个url请求得到的视频数据
这样的话其实只要在headers里添加referer字段就行了。
接下来进行全局搜索:
https://upos-sz-mirrorkodo.bilivideo.com/
结果如下:

跟进。
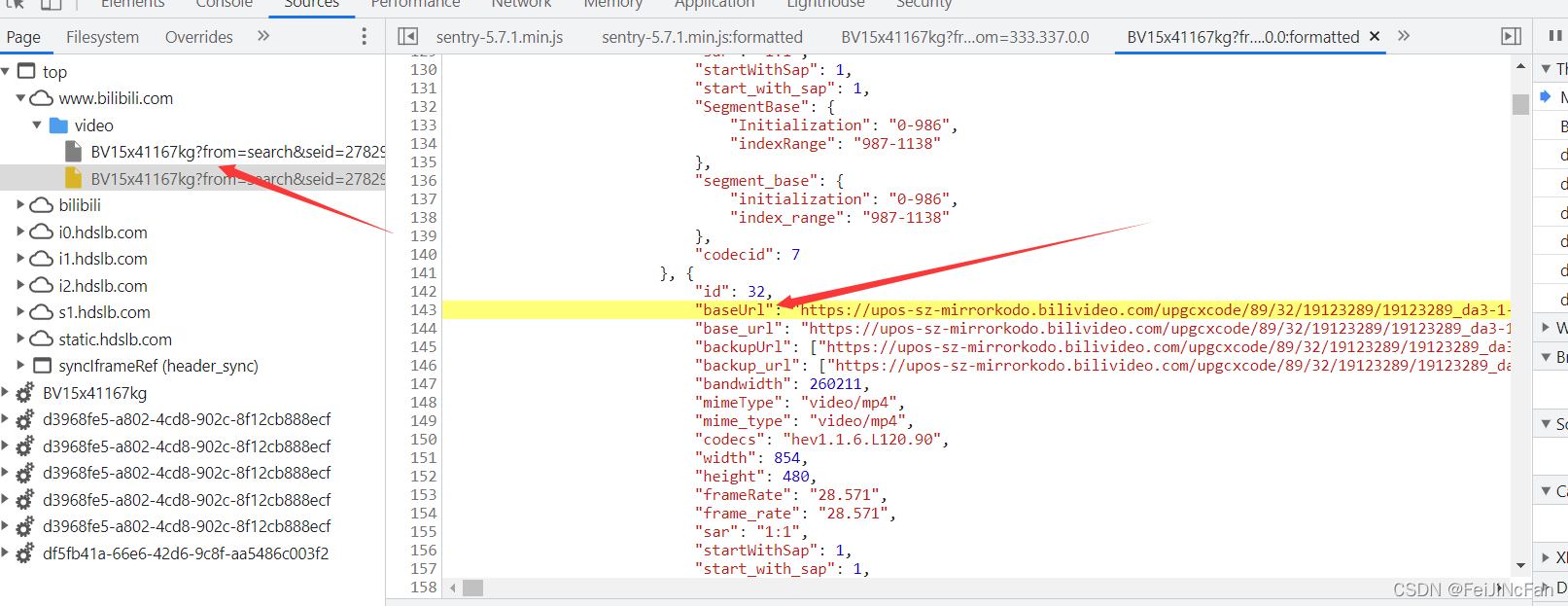
将相关的代码格式化一下。
格式化网址:https://www.sojson.com/simple_json.html
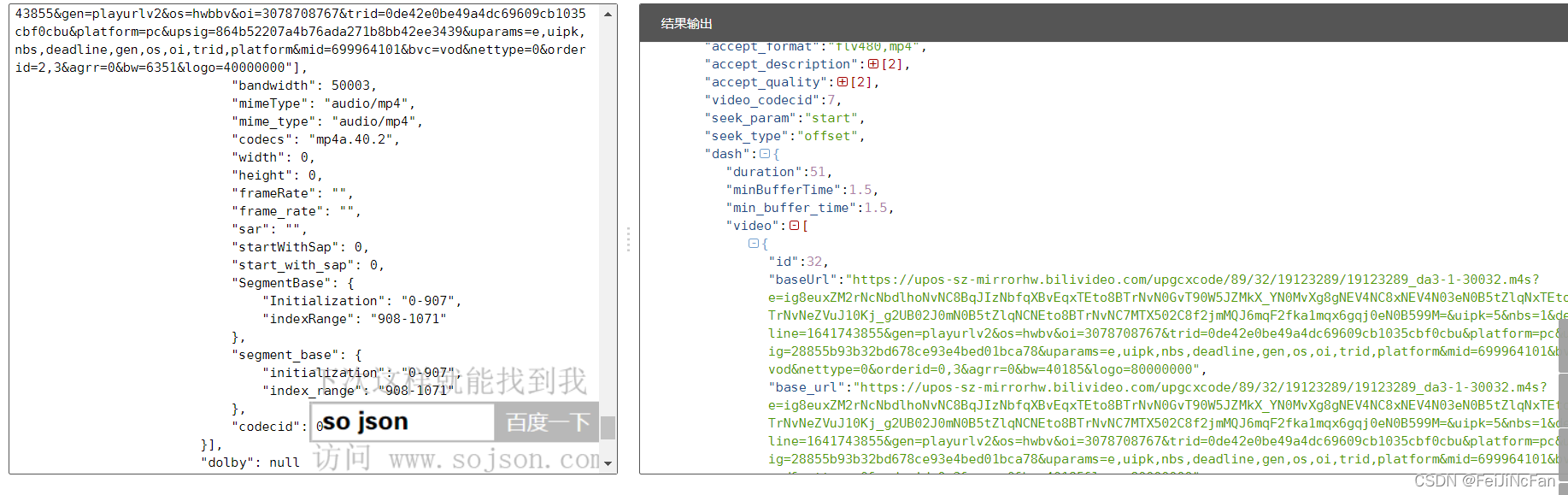

这样就足够清楚了。
思路就是提取video,audio的baseUrl然后请求相应的数据,保存。
代码如下:
import requests,re,json
def getVideo_and_Audio_Url(start_url,headers):
response=requests.get(start_url,headers).content.decode()
playinfo = re.findall("__playinfo__=(.*?)</script>",response)[0]
data_json = json.loads(playinfo)
video_url = data_json["data"]["dash"]["video"][0]["base_url"]
audio_url = data_json["data"]["dash"]["audio"][0]["base_url"]
return video_url,audio_url
def download_video_and_audio(video_url,audio_url):
video_content = requests.get(video_url,headers=headers).content
audio_content = requests.get(audio_url,headers=headers).content
with open("video.mp4","wb") as f:
f.write(video_content)
with open("audio.mp3","wb") as f:
f.write(audio_content)
print("下载完成")
if __name__ == '__main__':
start_url = "https://www.bilibili.com/video/BV15x41167kg"
headers = {
"Referer": "https://www.bilibili.com/video/BV15x41167kg?from=search&seid=2782960511092264812&spm_id_from=333.337.0.0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
video,audio = getVideo_and_Audio_Url(start_url,headers=headers)
download_video_and_audio(video,audio)
运行完代码的结果:
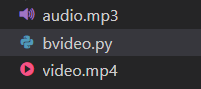

确实完成了目前。
接下里需要将得到的音频和视频合成,当然也需要提取视频的名字。
使用ffmpeg即可。(需要配置环境)
cmd = r"ffmpeg -i {}/{}.mp4 -i {}/{}.mp3 -c:v copy -c:a aac -strict experimental {}/{}.mp4".format(os_path,vTitle,os_path,vTitle,os_path,vTitle_0)
subprocess.run(cmd,shell=True)

完成!

















 3647
3647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









