






一、Transformer 的诞生背景
1.1 传统序列模型
在这个模型出现之前,主流的模型是基于循环神经网络架构( RNN ),特别是长短期记忆网络(LSTM)和门控循环单元网络(GRN)。这些模型在语言建模和机器翻译问题中,已经被牢固确立是最先进的方法。
然而,RNN架构存在一个显著的缺陷:在处理长序列时,存在信息丢失的风险,因为所有信息被压缩到一个向量中,增加了信息损失的风险。此外,解码器从这一向量中提取信息也很复杂。
为了解决这些问题,注意力机制被提出,并首先在RNN架构中使用,通过允许模型在处理信息时专注于关键部分,忽略不相关信息,从而提高处理效率和准确性。尽管注意力机制最初是为了改善RNN的性能而提出的,但它最终成为了Transformer模型的核心机制,彻底改变了深度学习的格局。
1.2 大神提出了颠覆式的注意力机制

Ashish Vaswani阿西什·瓦斯瓦尼
印度裔计算机科学家,专注于深度学习领域,2016年作为研究科学家加入谷歌大脑团队。
- 论文里程碑:2017 年谷歌大脑团队的该作者发表论文《Attention Is All You Need》(注意力就是一切),首次提出了注意力机制,该论文被引用了6万次,用了该结构的一半就做出了ChatGPT。
- 性能突破:在英德翻译任务上完全超越其他模型。
二、Transformer 核心架构解析
2.1架构图展示
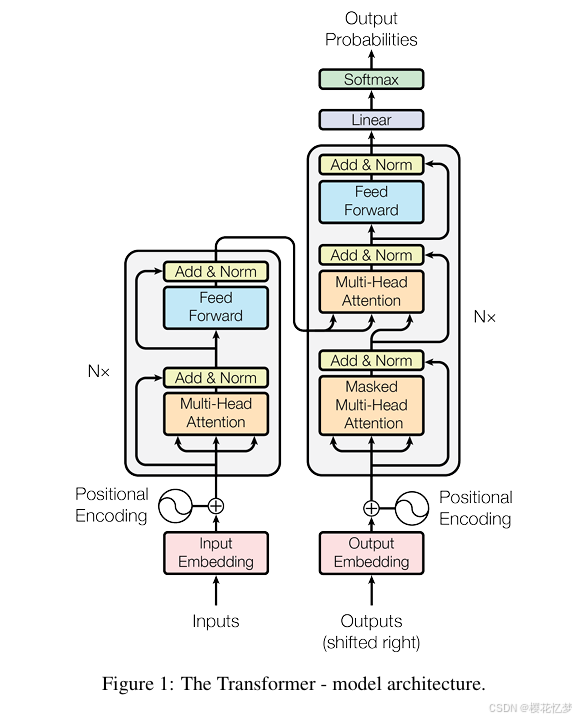
Transformer 模型架构主要包含:编码器Encoder,解码器Decoder,词嵌入Embeddings ,位置编码Positional Encoding,多头注意力Multi-Head-Attention,前馈网络Feed-Forward Networks,残差连接Add&Norm,归一化函数Softmax。
要了解这个结构,就得先知道这个模型的背景:这个原本是用在英德机器翻译的,它的流程是,从左边最下面inputs这里输入英文,再从右边最下面这里输入德文,通过一系列的计算,在右边最上面输出一个预测。
这张图从中间一分为二,左边Nx所指的部分叫编码器,右边Nx所指的部分叫解码器,Nx表示有多少个这样的结构,论文编码器和解码器数量都是6个,表示经过一次编码器后,还要再经过5次后才能输出一个值。
2.2关键组件详解
那我们按照流程来一步一步解释,这个模型,以输入句子 “猫追老鼠” 为例:
1、词嵌入(Embeddings)
作用:将文本变成向量。详细解释:输入文本(英文,中文...都可以),通过词嵌入Embeddings模块,它会将你输入的文本,转换成线性代数中的向量(用设定的规则来转换,将每个词转换为1*n维的数值向量,比如 “猫”这个字就可以转换成→ [0.3, 0.8, -0.1,...],这个向量就表示猫这个词的语义,同理,追也可以变成一个向量[0.3,0.9,0.7,...],老鼠[1.8,2.9,3.3,...]),那现在我们可以认为猫追老鼠这个文本就是一个3*n的矩阵(拼起来)。现在我们得到的是一个矩阵。
2、位置编码(Positional Encoding)
作用:让模型知道词的顺序。详细解释:(比如第 1 个词的位置编码是 [1, 0, 0...],第 2 个词[0, 1, 0...]),第 3个词[0, 0, 1...],那猫追老鼠就是一个3*n的矩阵,然后直接和词嵌入矩阵相加,就可以认为是词嵌入里面算是加入了位置信息了),论文中用正余弦位置编码,pos表示位置,i表示维度的索引,正弦和余弦函数的周期性使得位置编码具有相对位置的敏感性,不同维度的编码可以捕捉不同频率的位置信息。这种方法的优点是理论上可以处理任意长度的序列以及方便计算。现在得到的还是一个矩阵。
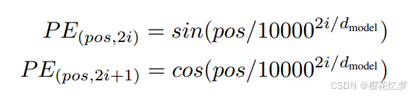
3、注意力机制
每个词生成三个向量:查询(Q)、键(K)、值(V)。
第一步:将现在的这个向量3*n的矩阵,通过不同的线性层(实际上是与不同的n*n的矩阵做乘法),生成Q,K,V(通过线性代数的计算,我们现在知道,QKV实际上都是3*n的矩阵)。
第二步:计算注意力得分,计算公式是![]() ,(这是核心点,因为注意力得分越高,则表示我们对这个更重视,越重视关键的,越忽视没用的,就越能找出有用的内容)。这里我们详细讲一下,Q和K的转置这两个矩阵相乘的意义,我们知道Q和K矩阵,都是词嵌入加上位置编码在通过线性层得到的,它实际上的含义还是猫追老鼠这三个词的意思,这个矩阵的每一行,就是每一个词的含义,(比如Q矩阵和K矩阵的第一行,就是猫这个词的词嵌入),那Q和K的转置相乘,得到一个3*3的矩阵,从线性代数的物理意义上看,3*3矩阵的第一行就是猫与猫的词嵌入做了乘法,猫与追的词嵌入做了乘法,猫与老鼠的词嵌入做了乘法......后面第二行,第三行同理。从实际的意义上看,就是算了每个词与每个词之间的关注度,所以这里被叫自注意力机制(包含了猫与猫这样的关注度),其中dk是维度,除以根号dk是为了放缩注意力得分的范围。现在得到的是一个3*3的矩阵。
,(这是核心点,因为注意力得分越高,则表示我们对这个更重视,越重视关键的,越忽视没用的,就越能找出有用的内容)。这里我们详细讲一下,Q和K的转置这两个矩阵相乘的意义,我们知道Q和K矩阵,都是词嵌入加上位置编码在通过线性层得到的,它实际上的含义还是猫追老鼠这三个词的意思,这个矩阵的每一行,就是每一个词的含义,(比如Q矩阵和K矩阵的第一行,就是猫这个词的词嵌入),那Q和K的转置相乘,得到一个3*3的矩阵,从线性代数的物理意义上看,3*3矩阵的第一行就是猫与猫的词嵌入做了乘法,猫与追的词嵌入做了乘法,猫与老鼠的词嵌入做了乘法......后面第二行,第三行同理。从实际的意义上看,就是算了每个词与每个词之间的关注度,所以这里被叫自注意力机制(包含了猫与猫这样的关注度),其中dk是维度,除以根号dk是为了放缩注意力得分的范围。现在得到的是一个3*3的矩阵。
第三步:把得到的注意力矩阵用 Softmax函数进行归一化,从而得到权重(比如 “猫” 和 “追” 的权重高,说明关系更密切)。softmax函数公式是![]() 。
。
第四步:与V矩阵做乘法,得到真正的注意力得分,![]() ,为什么又要与V相乘呢,我们需要解释一下这里的原理,因为通过softmax函数后,我们得到的是一个权重矩阵,可以认为是通过上面这么复杂的内容后,才知道了,猫追老鼠这几个词,每个词与词之间,到底权重是多少(比如猫与猫0.1,猫与追0.1,猫与老鼠0.8),那知道权重之后,我们与原本的矩阵做乘法就才可以得到每个词与词的得分。
,为什么又要与V相乘呢,我们需要解释一下这里的原理,因为通过softmax函数后,我们得到的是一个权重矩阵,可以认为是通过上面这么复杂的内容后,才知道了,猫追老鼠这几个词,每个词与词之间,到底权重是多少(比如猫与猫0.1,猫与追0.1,猫与老鼠0.8),那知道权重之后,我们与原本的矩阵做乘法就才可以得到每个词与词的得分。
第五步:接着就是多头注意力,实际上刚才的1234四个流程,就是一个注意力头的操作,但是我们会有很多个头,因为每个头关注的点不一样,我们综合很多个头的话,学习到的东西也会不一样,这对结果有好处。所以我们就可以认为上面的注意力得分就是一个头head的结果,我们有很多个头的话,就把它全部拼接起来,![]() ,从而就是大名鼎鼎的多头注意力机制。
,从而就是大名鼎鼎的多头注意力机制。
4、前馈神经网络
对注意力输出的向量做非线性变换(比如激活函数 ReLU),它的目的是增强特征表达。这就很简单了,往前传播呗。
5、残差连接与层归一化
将原始输入与当前层输出相加(残差),再通过 Layer Normalization层归一化稳定训练。这里值得一提的是,大部分的主流神经网络都要包含这种,因为有可能通过某一层注意力后,数据变得特别小,那后续就不行了,所以一般的神经网络都是在下一层输入的时候,本层的输入加上原数的输入,在做下一层的输出。
这就是整个编码器的运算流程。
解码器这边只是多了一个掩码,其余完全和编码器一样。就在注意力机制的这个阶段,当我们得到了Q与K的转置做的乘积之后,我们为了防止后文对前文的影响,所以把这个矩阵的上三角部分,全部重置成0。
2.3 总结
编码器处理阶段
- 输入
- 词嵌入
- 位置编码
- 自注意力机制
- 前馈神经网络
- 残差连接和层归一化
- 多层该结构循环
编码器处理阶段
- 输入
- 词嵌入
- 位置编码
- 自注意力机制(掩码)
- 前馈神经网络
- 残差连接和层归一化
- 交叉注意力机制
- 前馈神经网络
- 残差连接和层归一化
这里值得一提的是交叉注意力,它的核心作用是在两个不同的输入序列或模态之间建立信息交互,使模型能够有选择地关注不同来源的关键信息,从而实现更精准的特征融合或序列生成。
三、Transformer 的优化与变体
3.1 典型改进方向
3.1.1 模型规模扩展
- GPT-3 训练细节:
- 1750 亿参数,96 层 Transformer
- 训练数据:45TB 文本(含书籍、网页、代码)
- 硬件:285,000 个 CPU 内核 + 10,000 个 GPU
3.1.2 注意力机制优化
- Linformer(2020):
- 将注意力复杂度从 O (n²) 降为 O (nk)(k<<n)
- 核心思想:投影矩阵低秩近似
3.1.3 混合架构
- ViT(Vision Transformer):
- 图像分块:将 224x224 图像分成 16x16 patches
- 位置嵌入:学习每个 patch 的位置信息
- 在 ImageNet 上达到 90.7% 准确率(图 3:ViT 架构图)
四、Transformer 的实际应用场景
4.1 自然语言处理
-
文本生成:
- ChatGPT 的对话连贯性优化(Top-K 采样 + 核采样)
- 代码生成:GitHub Copilot 的 92% 代码补全率
-
信息抽取:
- 关系抽取模型(BERT+BiLSTM+CRF)在 ACE2005 数据集的 F1 值 82.3%
4.2 计算机视觉
-
图像分割:
- SegViT 在 ADE20K 数据集的 mIoU 达 56.7%
- 动态 mask 机制提升推理效率 2 倍
-
视频理解:
- TimeSformer 在 Kinetics-400 数据集的准确率 84.7%
4.3 跨模态应用
-
图文生成:
- DALL-E 3 的多模态提示理解(示例:"画一只穿着西装的柴犬在太空喝咖啡")
- 文本到 3D 模型:Stable Diffusion 3D 的早期尝试
-
医疗领域:
- 蛋白质结构预测:AlphaFold2 的 CASP14 准确率 92.4%
- 医学影像报告生成:MedT5 在 CheXpert 数据集的 BLEU 值 45.2
五、挑战与未来方向
局限性尽管Transformer在诸多任务中表现出色,但也存在一些局限性。例如,在处理超长序列时,注意力机制的计算成本仍然较高,可能导致内存和计算资源的瓶颈。此外,模型的可解释性虽然有所增强,但对于复杂的任务和模型结构,仍然难以完全理解其内部的工作原理。
关注我,小武永远免费分享干货

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









